
파스업DIP로 구현하는 현대적 데이터 파이프라인: 프레임워크 적용과 ELT모니터링 대시보드 #4
파스업DIP 개발팀의 spark-batch 프레임워크를 활용해 개발 생산성 50% 향상과 ELT 모니터링 대시보드 구축을 소개합니다. 순수 라이브러리 대비 코드 복잡도 현저히 감소하고 Apache Superset 기반 실시간 운영 모니터링 체계를 구현했습니다.
들어가며
지금까지 파스업DIP로 구현하는 현대적 데이터 파이프라인 시리즈 #1~3에서는 프레임워크 없이 공개된 라이브러리(pyspark, delta-spark, boto3 등)를 활용하여 순수하게 데이터 파이프라인을 구현해왔습니다. 이는 기본 원리를 이해하고 직접 구현해보는 측면에서 매우 중요한 학습 과정이었습니다.
하지만 실제 운영환경에서는 다음과 같은 이유로 프레임워크 적용이 일반적입니다:
- 개발 생산성 향상: 반복적인 코드 작성 최소화
- 코드 품질 및 일관성 유지: 표준화된 개발 패턴 적용
- 유지보수 용이성: 체계적인 구조와 모듈화
- 효율적인 협업: 팀 내 공통 개발 규칙 적용
이번 포스트에서는 파스업 개발팀이 2023~2024년 데이터레이크 구축을 위한 공공 프로젝트에서 제작한 spark-batch 프레임워크를 활용한 구현 예제를 소개하고, 이전 예제와 비교 분석해보겠습니다. 또한 프레임워크에 포함된 ELT 모니터링 기능을 활용한 대시보드 구축 사례도 함께 다루겠습니다.
목차
1. Framework vs. NON-Framework 비교
1.1 spark-batch Framework 적용방법
spark-batch는 개발 후 파이썬 패키지(PYPI)에 공개pip install spark_batch명령어로 라이브러리 설치하여 사용
1.2 소스 코드 비교 대상
Framework 미적용 소스 (이전 블로그 #1, #2, #3):
load_subway_info: 지하철 정보 로드load_subway_passengers: 지하철 승객 데이터 로드load_subway_passengers_time: 시간대별 지하철 승객 데이터 로드
Framework 적용 소스:
f_load_subway_info: 프레임워크 적용 지하철 정보 로드f_load_subway_passengers: 프레임워크 적용 지하철 승객 데이터 로드f_load_subway_passengers_time: 프레임워크 적용 시간대별 승객 데이터 로드
1.3 Framework vs. NON-Framework 상세 비교
NON-Framework 버전: load_subway_passengers
- import 문장 : 필요한 패키지 직접 import
from pyspark.sql import SparkSession
from pyspark.conf import SparkConf
from pyspark.sql.functions import lit, substring, col
from delta.tables import DeltaTable
import os
import psycopg2
import boto3
from botocore.exceptions import ClientError
- spark session 생성 : 코드 복잡도 높고 모든 batch 작업에 공통 적용
def create_spark_session(app_name, notebook_name, notebook_namespace, s3_access_key, s3_secret_key, s3_endpoint):
if is_running_in_jupyter():
conf = SparkConf()
# Spark driver, executor 설정
conf.set("spark.submit.deployMode", "client")
conf.set("spark.executor.instances", "1")
conf.set("spark.executor.memory", "1G")
conf.set("spark.driver.memory", "1G")
conf.set("spark.executor.cores", "1")
conf.set("spark.kubernetes.namespace", notebook_namespace)
...
# s3, delta, postgresql 사용 시 필요한 jar 패키지 설정
jar_list = ",".join([
"org.apache.hadoop:hadoop-common:3.3.4",
"org.apache.hadoop:hadoop-aws:3.3.4",
"com.amazonaws:aws-java-sdk:1.11.655",
"io.delta:delta-spark_2.12:3.3.1",
"org.postgresql:postgresql:42.7.2" # Added for PostgreSQL
])
conf.set("spark.jars.packages", jar_list)
# s3 세팅
conf.set("spark.hadoop.fs.s3a.impl", "org.apache.hadoop.fs.s3a.S3AFileSystem")
conf.set('spark.hadoop.fs.s3a.path.style.access', 'true')
conf.set('spark.hadoop.fs.s3a.connection.ssl.enabled', 'true')
conf.set("spark.hadoop.fs.s3a.aws.credentials.provider", "org.apache.hadoop.fs.s3a.SimpleAWSCredentialsProvider")
conf.set('spark.hadoop.fs.s3a.access.key', s3_access_key)
conf.set('spark.hadoop.fs.s3a.secret.key', s3_secret_key)
conf.set('spark.hadoop.fs.s3a.endpoint', s3_endpoint)
# deltalake 세팅
conf.set("spark.sql.extensions", "io.delta.sql.DeltaSparkSessionExtension")
conf.set("spark.sql.catalog.spark_catalog", "org.apache.spark.sql.delta.catalog.DeltaCatalog")
# --- SparkSession 빌드 ---
spark = SparkSession.builder \
.appName(app_name) \
.master("k8s://https://kubernetes.default.svc.cluster.local:443")\
.config(conf=conf) \
.getOrCreate()
else:
# --- SparkSession 빌드 ---
spark = SparkSession.builder \
.appName(app_name) \
.master("k8s://https://kubernetes.default.svc.cluster.local:443")\
.getOrCreate()
return spark
- 데이터 파이프 라인 : 코드복잡도가 높고 직접 예외처리
def subway_data_append(spark, s3_config, pg_config): #pg_config, pg_table, pg_url, pg_properties, delete_sql, insert_sql):
"""
CSV--> DELTA --> POSTGRESQL 처리하는 메인 파이프라인
"""
pg_url = f"jdbc:postgresql://{pg_config['host']}:{pg_config['port']}/{pg_config['dbname']}"
pg_properties = {
"user": pg_config['user'],
"password": pg_config['password'],
"driver": "org.postgresql.Driver"
}
print(f" bucket name is {s3_config['bucket']}")
csv_source_key = f"datasource/CARD_SUBWAY_MONTH_{WK_YM}.csv"
csv_archive_key = f"archive/CARD_SUBWAY_MONTH_{WK_YM}.csv"
csv_s3_path = f"s3a://{s3_config['bucket']}/{csv_source_key}"
delta_s3_path = f"s3a://{s3_config['bucket']}/deltalake/subway_passengers"
pg_table_name = "subway_passengers"
try:
print(f"\n--- Starting processing for {pg_table_name} during '{WK_YM}' ---")
# --- 단계 1: S3 CSV 읽기 ---
print(f"Reading CSV from {csv_s3_path}...")
# CSV 스키마나 옵션(overwrite, inferSchema...)은 소스 파일에 맞게 조정
csv_df = spark.read.option("header", "true").option("overwriteSchema", "true").csv(csv_s3_path)
# 필요시 yyyymm 컬럼을 추가하거나 기존 컬럼을 확인
csv_df.createOrReplaceTempView("subway_data")
print(f"CSV for {WK_YM} loaded. Count: {csv_df.count()}")
csv_df.show(5)
# --- 단계 2: Delta Lake에 삭제 후 삽입 (Spark SQL 사용) ---
print(f"Deleting old data for {WK_YM} from Delta table: {delta_s3_path}")
if DeltaTable.isDeltaTable(spark, delta_s3_path):
# '사용일자' 컬럼 형식에 맞게 WHERE 조건 수정
print(f" Delta Table {delta_s3_path} 있음")
delete_delta_sql = f"delete from delta.`{delta_s3_path}` where `사용일자` like '{WK_YM}'||'%' "
delta_mode = "append"
try:
spark.sql(delete_delta_sql)
print(f"Deletion from Delta complete. Inserting new data for {WK_YM}...")
except Exception as e:
print(f"Skip on error occurred during Delta DELETE, even though table exists: {e}")
raise # 예상치 못한 오류는 다시 발생시킴
else:
print(f" Delta Table {delta_s3_path} 없음")
delta_mode = "overwrite"
# DataFrame API로 쓰기 (SQL INSERT INTO도 가능하지만, DF API가 S3 쓰기에 더 일반적)
csv_df.write.format("delta").mode(delta_mode).save(delta_s3_path)
print(f"Successfully wrote data to Delta table {delta_s3_path}.")
# --- 단계 3: S3 CSV 파일 이동 ---
print(f"Archiving S3 CSV file...")
move_s3_file(s3_config, csv_source_key, csv_archive_key)
# --- 단계 4: PostgreSQL에 삭제 후 삽입 ---
print(f"Deleting old data for {WK_YM} from PostgreSQL table: {pg_table_name}")
conn = None
cursor = None
conn = psycopg2.connect (
host=pg_config['host'],
port=pg_config['port'],
dbname=pg_config['dbname'],
user=pg_config['user'],
password=pg_config['password'] )
cursor = conn.cursor()
delete_sql = f" delete from {pg_table_name} where use_date like '{WK_YM}'||'%' "
print(f"Executing DELETE query: {delete_sql}")
cursor.execute(delete_sql)
deleted_rows = cursor.rowcount
if cursor: cursor.close()
if conn:
conn.commit()
conn.close()
print(f"Successfully executed DELETE query. {deleted_rows} rows deleted.")
print(f"Inserting data for {WK_YM} into PostgreSQL table: {pg_table_name}")
# 데이터를 가공할 Spark SQL 쿼리
insert_sql = f"""
select `사용일자` use_date
,`노선명` line_no
,`역명` station_name
,cast(`승차총승객수` as int) pass_in
,cast(`하차총승객수` as int) pass_out
,substring(`등록일자`,1,8) reg_date
from delta.`{delta_s3_path}`
where `사용일자` like '{WK_YM}'||'%'
"""
print(insert_sql)
delta_df = spark.sql(insert_sql)
delta_df.write \
.jdbc(url=pg_url,
table=pg_table_name,
mode="append",
properties=pg_properties)
print(f"Successfully wrote data to PostgreSQL table {pg_table_name}.")
print(f"--- Processing for {WK_YM} completed successfully! ---")
except Exception as e:
print(f"An error occurred during processing {WK_YM}: {e}")
import traceback
traceback.print_exc()
Framework 적용 버전: f_load_subway_passengers
- import 문장: spark_batch에서 필요한 기능만 import
from spark_batch.lib.spark_session import get_spark_session
from spark_batch.lib.elt_manager import EltManager
from spark_batch.lib.pxlogger import CustomLogger
from spark_batch.lib.util import toTargetCondition
- spark session 생성과 EltManager 인스턴스 생성만 하면 바로 ELT작업 가능함
spark = get_spark_session(app_name="f_load_subway_passengers",notebook_name="test", notebook_namespace="demo01-kf", \
executor_instances="1", executor_memory="1G", executor_cores="1", driver_memory="1G", driver_cores="1" )
em = EltManager(spark, config_file="config.yaml", domain="life", record_type="mart", record_prefix="hopt")
- 데이터 파이프 라인 : 코드가 단순하며 예외처리는 Framework에서 수행
- load_subway_passengers에 비해 delta.bronze--> delta.gold작업까지 추가함
# csv --> delta.bronze
source_type = "csv1"; source_topic = "paasup"; source_dpath="datasource/life"
target_type = "delta1"; target_topic = "paasup"; target_dpath="bronze/life"
em.init_rsm(source_type, source_topic, source_dpath, target_type, target_topic, target_dpath, chunk_size=500000)
source_objects = ["CARD_SUBWAY_MONTH_{WK_YM}.csv".format(WK_YM=WK_YM)]; target_object = "CARD_SUBWAY_MONTH"
source_inc_query = f"""
select * from CARD_SUBWAY_MONTH
"""
target_condition = f" `사용일자` like '{WK_YM}'||'%' "
source_df, target_df, valid = em.ingest_increment(source_objects, target_object, source_inc_query, target_condition, delemeter=",")
# delta.bronze --> delta.gold (cleansing 혹은 가공)
source_type = "delta1"; source_topic = "paasup"; source_dpath="bronze/life"
target_type = "delta1"; target_topic = "paasup"; target_dpath="gold"
em.init_rsm(source_type, source_topic, source_dpath, target_type, target_topic, target_dpath, chunk_size=500000)
source_objects = ["CARD_SUBWAY_MONTH"]; target_object = "subway_passengers"
source_inc_query = f"""
select `사용일자` use_date
, `노선명` line_no
, `역명` station_name
, `승차총승객수` pass_in
, `하차총승객수` pass_out
, `등록일자` reg_date
from CARD_SUBWAY_MONTH
where `사용일자` like '{WK_YM}'||'%'
"""
target_condition = f"""
use_date like '{WK_YM}'||'%'
"""
source_df, target_df, valid = em.ingest_increment(source_objects, target_object, source_inc_query, target_condition)
# delta.gold --> mart
source_type = "delta1"; source_topic = "paasup"; source_dpath="gold"
target_type = "mart"; target_topic = "postgres"; target_dpath=None
em.init_rsm(source_type, source_topic, source_dpath, target_type, target_topic, target_dpath, chunk_size=500000)
source_objects = ["subway_passengers"]; target_object = "subway_passengers"
source_inc_query = f"""
select use_date
, line_no
, station_name
, cast(pass_in as int) pass_in
, cast(pass_out as int) pass_out
, reg_date
from subway_passengers
where use_date like '{WK_YM}'||'%'
"""
target_condition = f"""
use_date like '{WK_YM}'||'%'
"""
source_df, target_df, valid = em.ingest_increment(source_objects, target_object, source_inc_query, target_condition)
1.3 Framework 적용의 주요 장점
1) 코드 간소화
- SparkSession 관리, 예외 처리, 리소스 정리가 프레임워크에서 자동 처리
- 비즈니스 로직에만 집중 가능
2) 표준화된 구조
- 모든 ELT 작업이 동일한 패턴을 따름
- 새로운 개발자도 쉽게 이해하고 적용 가능
3) 자동 모니터링
- 프레임워크에서 자동 로깅
- 실행 시간, 처리 건수, 오류 정보 자동 수집
4) 설정 기반 개발
- 소스/타겟 설정을 통한 유연한 데이터 처리
- 하드코딩 최소화
2. ELT 결과 모니터링 대시보드
spark-batch 프레임워크의 가장 큰 장점 중 하나는 ELT 작업의 모니터링을 위한 자동 로깅 기능입니다. 개발자가 ELT 기능을 호출할 때마다 작업 결과가 로그 테이블에 자동으로 저장되며, 이를 기반으로 Apache Superset을 활용한 종합 모니터링 대시보드를 구축했습니다.
2.1 대시보드 구성 요소
필터 옵션
- TIME RANGE: ELT 작업 기간 선택
- VALID: 작업 성공/실패 필터링
- DOMAIN: ELT 작업 분류 (타겟의 주제영역별 분류 등으로 ELT작업에서 지정함)
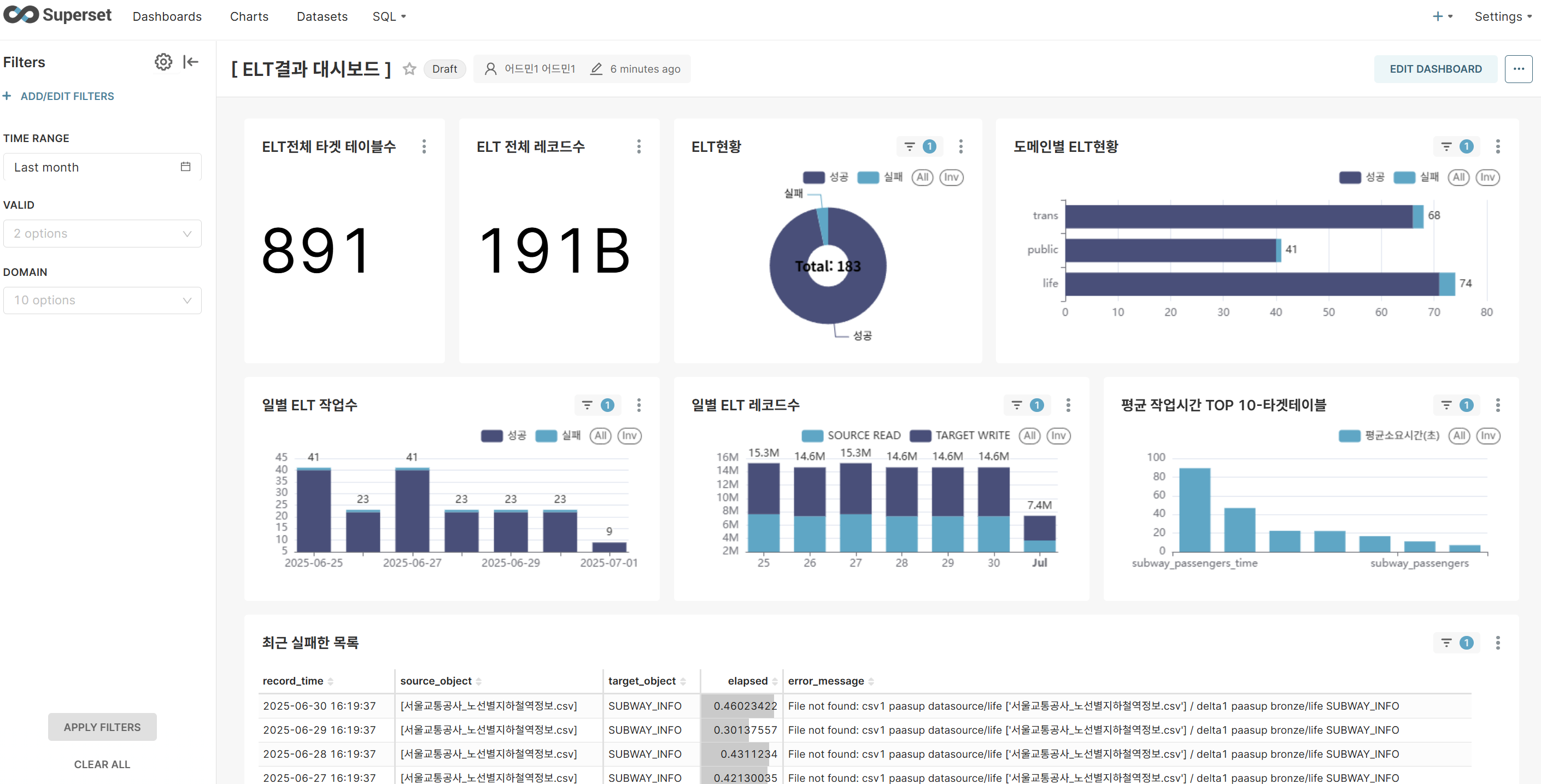
차트 구성
차트 1: ELT전체 타겟 테이블수 (BIG NUMBER)

- 전체 ELT작업에 대한 KPI (Filter 적용하지 않음)
- ELT 타겟 테이블수를 한눈에 파악하여 전체 ELT 작업 부하 분석
차트 2: ELT 전체 레코드수 (BIG NUMBER)

- 전체 ELT작업에 대한 KPI (Filter 적용하지 않음)
- 시스템이 처리하는 데이터 규모 및 비즈니스 임팩트 측정
차트 3: ELT현황 (PIE CHART)
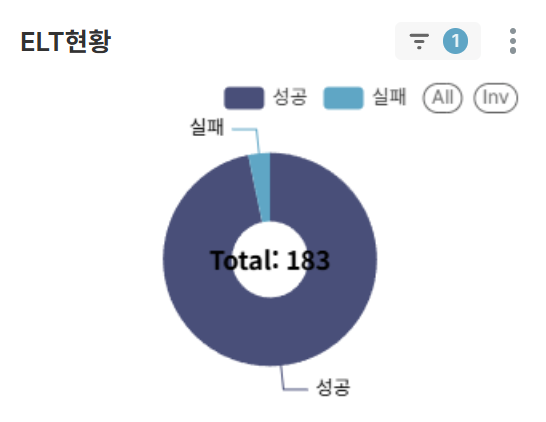
- ELT작업에 대한 성공/실패 건수와 비율을 분석
- 실패 건수가 발생하면 재작업 등의 대응 조치 필요성을 한눈에 파악
차트 4: 도메인별ELT현황 (BAR CHART)
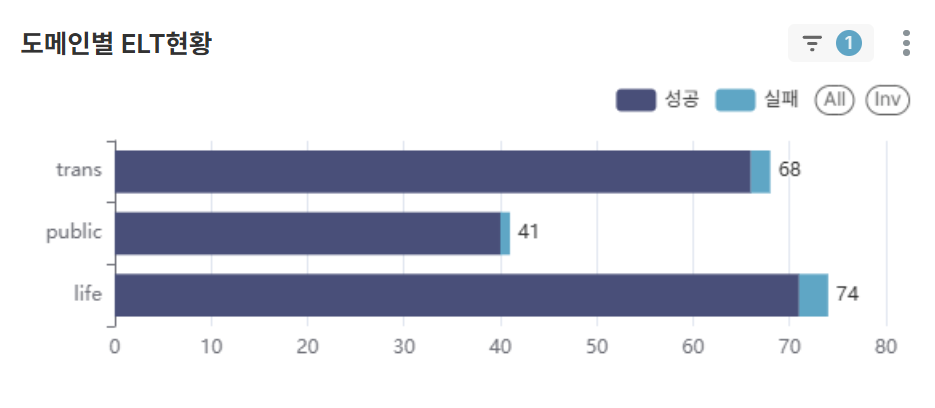
- ELT작업 도메인별로 성공/실패 건수를 한눈에 파악
- 실패 건수가 발생하였을 때 재작업 등의 대응 조치 도메인을 인지
차트 5: 일별ELT 작업수 (BAR CHART)
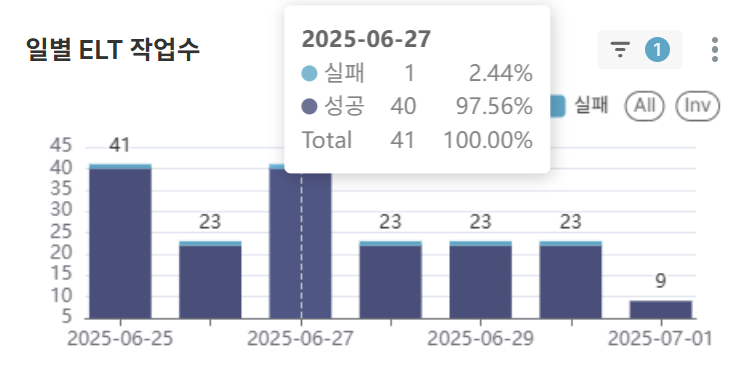
- 일별로 ELT작업 성공/실패 건수를 파악하므로 오류 발생 시점 예측 가능
- 반복적인 실패에 대한 대응 조치 필요성 파악
차트 6: 일별ELT 레코드수 (BAR CHART)
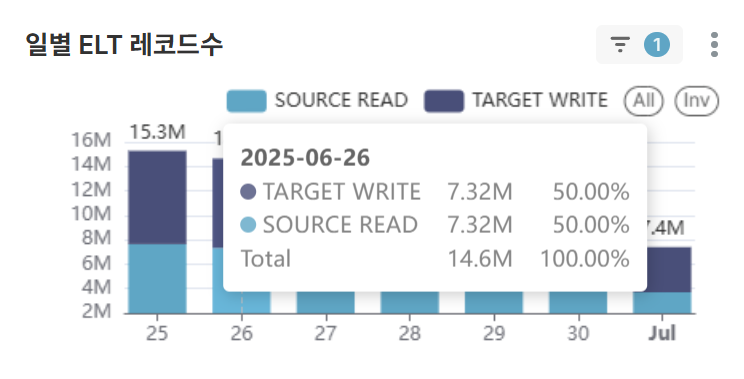
- 소스 데이터 처리 증가 추세 대비 타겟 데이터 처리량 효율성 분석 및 데이터 필터링/변환 비율 모니터링
- 급격한 데이터량 변화 시 업스트림 시스템 상태 점검 및 인프라 용량 계획 수립
차트 7: 최근 실패한 목록 (TABLE)
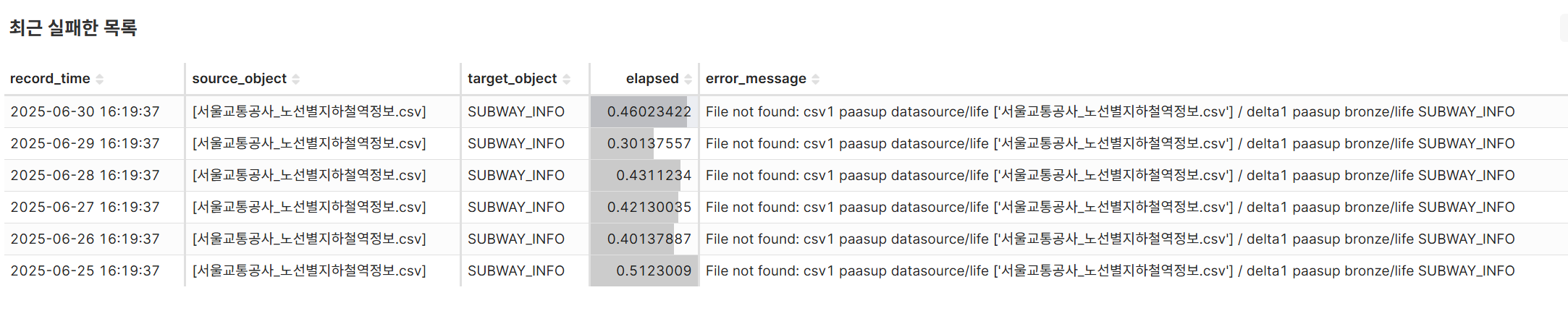
- 작업 시간의 역순으로 에러로그 분석을 통한 해결 방안 도출 및 특정 소스/타겟 객체의 반복적 실패 패턴 식별
- 오류 메시지 유형별 분석으로 시스템 개선 포인트 파악 및 장애 대응 프로세스 개선
2.2 대시보드 활용 효과
1) 실시간 운영 모니터링
- ELT 작업 현황을 실시간으로 파악
- 장애 발생 시 즉시 감지 및 대응 가능
2) 성능 분석
- 작업별 소요시간 분석을 통한 최적화 포인트 식별
- 데이터 처리량 추이를 통한 인프라 리소스 계획 수립
3) 품질 관리
- 성공률 모니터링을 통한 파이프라인 안정성 확보
- 실패 원인 분석을 통한 개선 방안 도출
4) 운영 효율성
- 관리자 및 개발자의 운영 부담 경감
- 데이터 기반 의사결정 지원
3. 프레임워크 도입 시 고려사항
3.1 장점
- 개발 생산성 향상: 반복 코드 제거 및 표준화
- 운영 안정성 강화: 자동 모니터링 및 예외 처리
- 유지보수 용이성: 일관된 구조와 패턴
- 협업 효율성: 팀 내 공통 개발 규칙
3.2 단점 및 주의사항
- 학습 곡선: 프레임워크 이해 및 적응 시간 필요
- 의존성 증가: 프레임워크 변경 시 영향 범위 확대
- 유연성 제한: 특수한 요구사항 대응 시 제약 가능성
3.3 도입 가이드라인
- 팀 규모와 프로젝트 복잡도 고려
- 기존 시스템과의 호환성 검토
- 프레임워크 커스터마이징 방안 수립
- 팀원 교육 및 문서화 계획
마무리
이번 포스트에서는 파스업DIP 시리즈의 연장선에서 spark-batch 프레임워크를 활용한 실무 적용 사례를 살펴봤습니다. 프레임워크 적용을 통해 개발 생산성과 운영 안정성을 크게 향상시킬 수 있었으며, 특히 ELT 모니터링 대시보드를 통한 체계적인 운영 관리가 가능해졌습니다.
실제 운영환경에서는 순수 라이브러리 구현보다는 프레임워크 기반 개발이 더 적합하며, 다음과 같은 효과를 기대할 수 있습니다:
- 개발 시간 단축 (약 50% 이상 감소)
- 코드 품질 향상 (표준화된 패턴 적용)
- 운영 안정성 강화 (자동 모니터링 및 로깅)
- 협업 효율성 증대 (공통 개발 규칙 적용)