
DuckDB: 현대적인 분석용 데이터베이스 가이드
DuckDB는 SQLite의 분석 버전을 지향하는 임베디드 분석 데이터베이스입니다. 별도의 서버 설정 없이 로컬 환경에서 대용량 데이터를 빠르게 분석할 수 있으며, CSV, Parquet, JSON 등 다양한 파일 형식을 직접 쿼리할 수 있습니다. 이 글에서는 DuckDB의 아키텍처부터 설치 방법, 그리고 실무에서 활용할 수 있는 다양한 SQL 예제까지 상세히 다룹니다.

목차
1. 들어가며
DuckDB의 아키텍처와 특장점
DuckDB는 SQLite의 분석 버전을 목표로 개발된 임베디드 분석 데이터베이스입니다. OLAP(Online Analytical Processing) 워크로드에 최적화되어 있으며, 다음과 같은 핵심 아키텍처 특징을 가지고 있습니다.
주요 아키텍처 특징:
- 컬럼 지향 저장(Columnar Storage): 분석 쿼리에 최적화된 컬럼 기반 데이터 저장 방식으로, 특정 컬럼만 읽어 처리 속도를 크게 향상시킵니다.
- 벡터화된 쿼리 엔진(Vectorized Query Engine): 한 번에 여러 행을 처리하는 벡터화 실행으로 CPU 캐시를 효율적으로 활용합니다.
- 임베디드 데이터베이스: 별도의 서버 프로세스 없이 애플리케이션에 직접 통합되어 실행됩니다.
- Zero-Copy 데이터 접근: Apache Arrow와의 통합으로 메모리 복사 없이 데이터를 공유할 수 있습니다.
핵심 특장점:
- 간편한 설치와 사용: 별도의 서버 설정이나 관리가 필요 없습니다.
- 뛰어난 성능: 벤치마크에서 다른 임베디드 데이터베이스 대비 최대 수십 배 빠른 성능을 보입니다.
- 완전한 SQL 지원: 복잡한 분석 쿼리, 윈도우 함수, CTE 등을 모두 지원합니다.
- 다양한 데이터 형식 지원: CSV, Parquet, JSON 등을 직접 쿼리할 수 있습니다.
- Python/R 통합: 데이터 과학 생태계와의 완벽한 통합을 제공합니다.
DuckDB의 데이터 분석 장점
장점:
- 빠른 분석 속도: 컬럼 지향 저장과 벡터화 엔진으로 대용량 데이터 분석이 빠릅니다.
- 메모리 효율성: 자동 메모리 관리와 디스크 스필링으로 메모리를 초과하는 데이터도 처리 가능합니다.
- 간편한 데이터 로드: 파일을 직접 쿼리할 수 있어 ETL 과정을 단순화합니다.
- 표준 SQL 사용: 별도의 문법 학습 없이 기존 SQL 지식을 활용할 수 있습니다.
- 로컬 우선 철학: 클라우드 의존성 없이 로컬 환경에서 모든 작업이 가능합니다.
제약사항:
- OLTP 부적합: 트랜잭션 처리가 많은 애플리케이션에는 적합하지 않습니다.
- 동시 쓰기 제한: 여러 프로세스가 동시에 쓰기를 수행하는 환경에는 적합하지 않습니다.
- 네트워크 기능 부재: 기본적으로 클라이언트-서버 모델을 지원하지 않습니다.
- 인덱스 제한: B-Tree 인덱스 등 전통적인 인덱스 구조는 제한적입니다.
2. DuckDB 설치하기
Windows WSL 환경에서 설치하기
Windows WSL(Windows Subsystem for Linux) 환경에서 DuckDB를 설치하는 방법은 매우 간단합니다.
방법 1: CLI 바이너리 직접 다운로드
# 최신 버전 다운로드
wget https://github.com/duckdb/duckdb/releases/download/v1.1.3/duckdb_cli-linux-amd64.zip
# 압축 해제
unzip duckdb_cli-linux-amd64.zip
# 실행 권한 부여
chmod +x duckdb
# DuckDB 실행
./duckdb
방법 2: Python 패키지로 설치
# pip를 사용한 설치
pip install duckdb
# Python에서 사용
python3
>>> import duckdb
>>> duckdb.sql("SELECT 42 AS answer").show()
설치 확인:
# 버전 확인
./duckdb --version
# 간단한 쿼리 실행 테스트
./duckdb -c "SELECT 'Hello, DuckDB!' AS greeting"
3. DuckDB 활용 예제
examples 사용할 파일 다운로드
예제에 사용된 examples 파일들을 특정 디렉토리(여기서는 /mnt/c/tmp)에 다운 받습니다.
https://github.com/duckdb-in-action/examples
예제 1: USING을 활용한 간결한 JOIN
-- Listing 3.12: USING 절을 사용한 조인 (ON r1.id = r2.id와 동일)
SELECT *
FROM (VALUES (1, 'a1'), (2, 'a2'), (3, 'a3')) l(id, nameA)
JOIN (VALUES (1, 'b1'), (2, 'b2'), (4, 'b4')) r(id, nameB)
USING (id);

설명: USING (id) 구문은 양쪽 테이블에 동일한 이름의 컬럼이 있을 때 사용하는 간결한 조인 방식입니다. ON l.id = r.id와 동일하지만 결과에서 id 컬럼이 중복되지 않습니다.
예제 2: COLUMNS 표현식으로 동적 컬럼 선택
-- 'valid'로 시작하는 모든 컬럼만 선택
SELECT COLUMNS('valid.*')
FROM "/mnt/c/tmp/ch03/prices.csv"
LIMIT 3;

설명: DuckDB의 강력한 기능 중 하나인 COLUMNS 표현식을 사용하면 정규식 패턴으로 컬럼을 동적으로 선택할 수 있습니다. 이는 많은 컬럼을 가진 테이블에서 특정 패턴의 컬럼만 추출할 때 매우 유용합니다.
예제 3: SELECT * 생략 문법
-- FROM 절부터 시작하는 쿼리 (SELECT *가 암묵적으로 적용됨)
FROM "/mnt/c/tmp/ch03/prices.csv"
WHERE COLUMNS('valid.*') BETWEEN '2020-01-01' AND '2021-01-01';
설명: DuckDB는 SELECT *를 생략하고 FROM부터 쿼리를 시작할 수 있는 편리한 문법을 지원합니다. 이는 대화형 데이터 탐색 시 타이핑을 줄여주는 실용적인 기능입니다.
예제 4: BY NAME을 사용한 이름 기반 삽입
-- Listing 3.19: 컬럼 이름으로 매핑하여 데이터 삽입
INSERT INTO systems BY NAME
SELECT DISTINCT
system_id AS id,
system_public_name AS NAME
FROM 'https://oedi-data-lake.s3.amazonaws.com/pvdaq/csv/systems.csv'
ON CONFLICT DO NOTHING;
설명: BY NAME 키워드는 컬럼의 위치가 아닌 이름으로 매핑하여 데이터를 삽입합니다. 소스와 타겟 테이블의 컬럼 순서가 다르거나, 일부 컬럼만 삽입하고 싶을 때 매우 유용합니다. URL에서 직접 CSV를 읽어 삽입할 수 있다는 점도 주목할 만합니다.
예제 5: 네임드 파라미터를 활용한 JSON 읽기
# Listing 3.24: 날짜 형식을 지정하여 JSON 파일 읽기
echo '{"foo": "21.9.1979"}' > 'my.json'
./duckdb -s \
"SELECT * FROM read_json_auto(
'my.json',
dateformat='%d.%M.%Y'
)"

설명: DuckDB는 JSON 파일을 자동으로 스키마를 추론하여 읽을 수 있으며, dateformat 파라미터로 커스텀 날짜 형식을 지정할 수 있습니다. -s 옵션은 단일 명령어를 실행하고 종료하는 스크립트 모드입니다.
예제 6: SUMMARIZE로 빠른 데이터 탐색
-- 데이터의 통계 요약 정보 자동 생성
SUMMARIZE
SELECT read_on, power
FROM '/mnt/c/tmp/readings.csv'
WHERE system_id = 1200;

설명: SUMMARIZE 키워드는 결과 데이터셋의 통계적 요약(평균, 최소값, 최대값, NULL 개수 등)을 자동으로 생성합니다. 데이터 탐색 초기 단계에서 데이터의 분포와 특성을 빠르게 파악하는 데 유용합니다.
예제 7: GROUP BY ROLLUP으로 소계 계산
-- Listing 4.13: ROLLUP을 사용한 계층적 집계 (합계/소계)
SELECT
year(read_on) AS year,
system_id,
count(*),
round(sum(power) / 4 / 1000, 2) AS kWh
FROM '/mnt/c/tmp/readings.csv'
GROUP BY ROLLUP (year, system_id)
ORDER BY year NULLS FIRST, system_id NULLS FIRST;
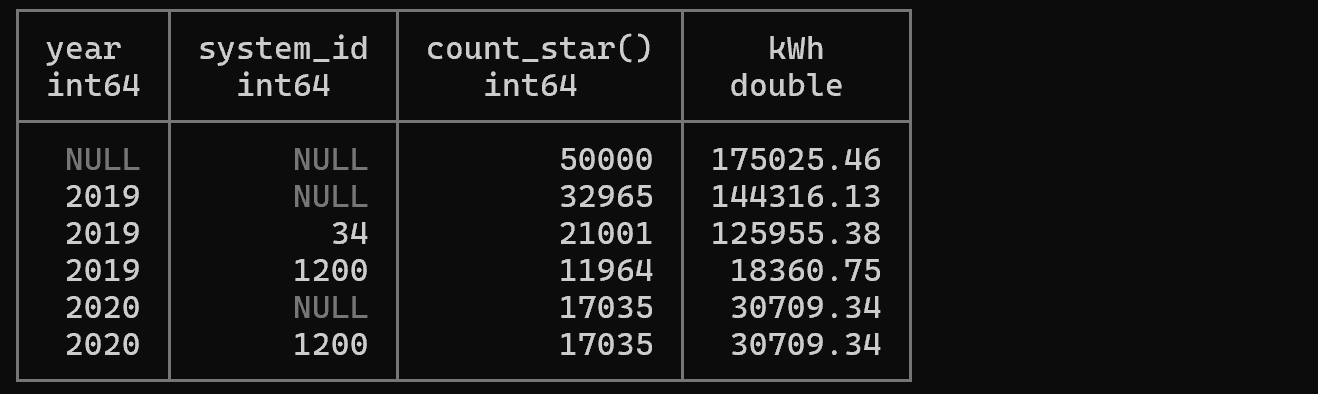
설명: ROLLUP은 계층적 소계를 계산합니다. 이 쿼리는 다음 세 가지 레벨의 집계를 생성합니다:
- 각 (year, system_id) 조합별 집계
- 각 year별 소계 (system_id는 NULL)
- 전체 합계 (year와 system_id 모두 NULL)
보고서나 대시보드에서 계층적 요약이 필요할 때 매우 유용합니다.
예제 8: GROUP BY CUBE로 모든 조합 집계
-- Listing 4.14: CUBE를 사용한 다차원 집계
SELECT
year(read_on) AS year,
system_id,
count(*),
round(sum(power) / 4 / 1000, 2) AS kWh
FROM '/mnt/c/tmp/readings.csv'
GROUP BY CUBE (year, system_id)
ORDER BY year NULLS FIRST, system_id NULLS FIRST;
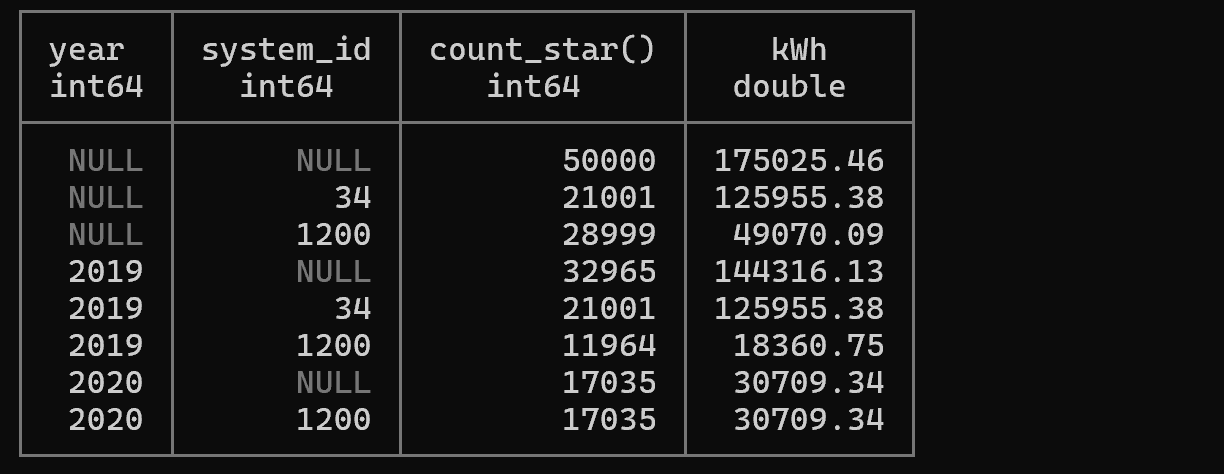
설명: CUBE는 지정된 컬럼들의 모든 가능한 조합에 대한 집계를 생성합니다. 이 쿼리는 다음 네 가지 집계를 생성합니다:
- (year, system_id) - 각 년도와 시스템 조합
- (year, NULL) - 각 년도별 모든 시스템 합계
- (NULL, system_id) - 각 시스템별 모든 년도 합계
- (NULL, NULL) - 전체 합계
OLAP 큐브와 유사한 다차원 분석에 적합합니다.
예제 9: FILTER를 사용한 조건부 집계
-- view 생성
CREATE OR REPLACE VIEW v_power_per_day
AS SELECT system_id,
date_trunc('day', read_on) AS day,
round(sum(power) / 4 / 1000, 2) AS kWh,
FROM '/mnt/c/tmp/readings.csv'
GROUP BY ALL;
-- Listing 4.25: FILTER 절로 조건별 집계 수행 (정적 피봇)
SELECT
system_id,
sum(kWh) FILTER (WHERE year(day) = 2019) AS 'kWh in 2019',
sum(kWh) FILTER (WHERE year(day) = 2020) AS 'kWh in 2020'
FROM v_power_per_day
GROUP BY system_id;
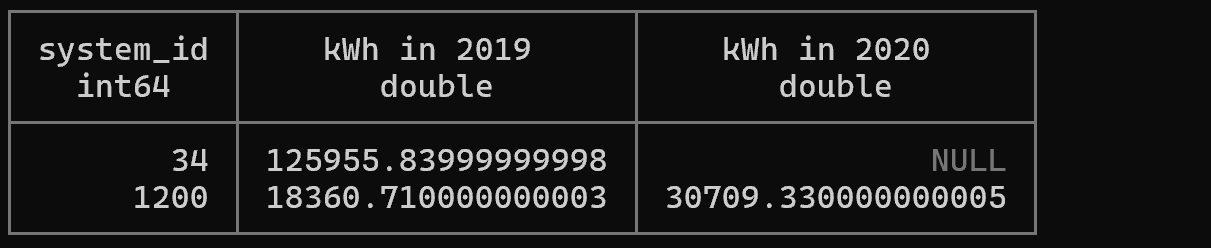
설명: FILTER 절은 각 집계 함수에 개별적으로 조건을 적용할 수 있게 해줍니다. 이는 여러 조건의 집계를 한 번의 쿼리로 수행할 수 있어 성능상 매우 효율적입니다. CASE 문을 사용한 조건부 집계보다 가독성이 좋습니다.
예제 10: PIVOT으로 동적 테이블 변환
-- Listing 4.26: DuckDB의 PIVOT 문을 사용한 동적 피봇
PIVOT (FROM v_power_per_day)
ON year(day)
USING sum(kWh);

설명: PIVOT은 행을 열로 변환하는 강력한 기능입니다. 이 쿼리는 년도별로 컬럼을 생성하고 각 컬럼에 kWh 합계를 계산합니다. 이전 예제의 FILTER 방식보다 간결하며, 동적으로 값의 개수만큼 컬럼을 생성합니다.
예제 11 ASOF JOIN으로 시계열 데이터 결합
-- Listing 4.28: 시간 기반 근사 조인 (가장 최근 값 매칭)
WITH prices AS (
SELECT range AS valid_at, random()*10 AS price
FROM range(
'2023-01-01 01:00:00'::timestamp,
'2023-01-01 02:00:00'::timestamp,
INTERVAL '15 minutes'
)
), sales AS (
SELECT range AS sold_at, random()*10 AS num
FROM range(
'2023-01-01 01:00:00'::timestamp,
'2023-01-01 02:00:00'::timestamp,
INTERVAL '5 minutes'
)
)
SELECT
sold_at,
valid_at AS 'with_price_at',
round(num * price, 2) as price
FROM sales
ASOF JOIN prices ON prices.valid_at <= sales.sold_at;
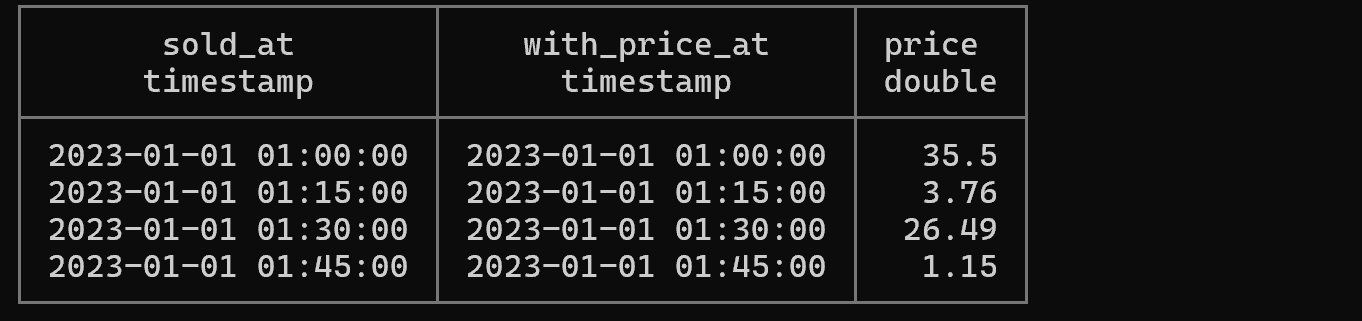
설명: ASOF JOIN은 시계열 데이터에서 매우 유용한 조인 방식입니다. 판매 시점(sold_at)에 대해 그 시점 이전의 가장 최근 가격(valid_at)을 찾아 매칭합니다. 금융 데이터, 센서 데이터 등 시간에 따라 변하는 값을 다룰 때 필수적인 기능입니다.
예제 12: CSV를 Parquet으로 변환 및 최적화
# 대용량 CSV 파일을 압축된 Parquet 형식으로 변환
./duckdb -s "
SET memory_limit='1G';
COPY (
SELECT
* EXCLUDE (player, wikidata_id)
REPLACE (
cast(strptime(ranking_date::VARCHAR, '%Y%m%d') AS DATE) AS ranking_date,
cast(strptime(dob, '%Y%m%d') AS DATE) AS dob
)
FROM '/mnt/c/tmp/ch05/atp/atp_rankings_*.csv' rankings
JOIN (
FROM '/mnt/c/tmp/ch05/atp/atp_players.csv'
) players ON players.player_id = rankings.player
) TO 'atp_rankings.parquet' (
FORMAT PARQUET,
CODEC 'SNAPPY',
ROW_GROUP_SIZE 100000
);"
설명: 이 예제는 DuckDB의 여러 강력한 기능을 보여줍니다:
SET memory_limit: 메모리 사용량 제한 (OOM 방지)EXCLUDE: 특정 컬럼 제외REPLACE: 컬럼 값 변환 (문자열 날짜를 DATE 타입으로)- 와일드카드 패턴(
*.csv)으로 여러 파일 동시 읽기 - Parquet 형식으로 내보내기 (SNAPPY 압축, Row Group 크기 최적화)
이는 데이터 파이프라인에서 CSV를 고성능 포맷으로 변환하는 실용적인 예제입니다.
4. 결론
DuckDB의 데이터 분석 장점 및 제약사항
핵심 장점 요약:
- 탁월한 분석 성능: 컬럼 지향 저장과 벡터화 엔진으로 대용량 데이터 분석이 매우 빠릅니다.
- Zero-ETL 철학: CSV, Parquet, JSON 파일을 직접 쿼리할 수 있어 데이터 파이프라인이 간소화됩니다.
- 개발자 친화적: 표준 SQL 지원과 직관적인 확장 문법으로 학습 곡선이 낮습니다.
- 완전한 임베디드: 별도의 서버나 인프라 없이 애플리케이션에 통합 가능합니다.
- 현대적인 SQL 기능:
PIVOT,ASOF JOIN,COLUMNS표현식 등 강력한 분석 기능을 제공합니다. - 확장성: 메모리를 초과하는 데이터도 디스크 스필링으로 처리 가능합니다.
- 데이터 과학 통합: Python, R과의 완벽한 통합으로 데이터 과학 워크플로우에 자연스럽게 통합됩니다.
고려해야 할 제약사항:
- OLTP 부적합: 트랜잭션 처리나 고빈도 쓰기 작업에는 적합하지 않습니다.
- 동시성 제한: 단일 프로세스 쓰기만 지원하므로 다중 사용자 환경에는 제한적입니다.
- 네트워크 기능 부재: 기본적으로 클라이언트-서버 모델을 지원하지 않습니다.
- 인덱스 제한: 전통적인 B-Tree 인덱스 등은 제한적이며, 컬럼 지향 스캔에 의존합니다.
DuckDB가 적합한 사용 사례:
- 로컬 데이터 분석 및 탐색
- 데이터 과학 프로젝트의 중간 처리 레이어
- ETL 파이프라인의 데이터 변환
- 임베디드 분석 애플리케이션
- 프로토타이핑 및 개발 환경
- CSV/Parquet 파일 기반 데이터 웨어하우스
DuckDB가 부적합한 사용 사례:
- 온라인 트랜잭션 처리(OLTP) 시스템
- 다중 사용자 동시 쓰기가 필요한 애플리케이션
- 클라이언트-서버 아키텍처가 필요한 환경
- 실시간 고빈도 데이터 입력
DuckDB는 "데이터베이스를 위한 SQLite"라는 목표에 충실한 도구로, 분석 워크로드에 최적화된 강력하고 사용하기 쉬운 솔루션입니다. 적절한 사용 사례에서 DuckDB는 개발 생산성과 쿼리 성능 모두에서 탁월한 가치를 제공합니다.