
Modern Data Pipeline Implementation with Paasup DIP #4: Framework Application and ELT Monitoring Dashboard
Introduction
In the previous posts of the PaasUp DIP modern data pipeline series (#1~3), we implemented data pipelines purely using open-source libraries (pyspark, delta-spark, boto3, etc.) without any framework. This was a crucial learning process for understanding basic principles and direct implementation.
However, in actual production environments, framework adoption is common for the following reasons:
- Enhanced Development Productivity: Minimizing repetitive code writing
- Code Quality and Consistency: Applying standardized development patterns
- Improved Maintainability: Systematic structure and modularization
- Efficient Collaboration: Applying common development rules within teams
This post introduces implementation examples using the spark-batch framework developed by the PaasUp development team for public data lake construction projects in 2023~2024, and provides comparative analysis with previous examples. We'll also cover dashboard construction cases utilizing the ELT monitoring features included in the framework.
Table of Contents
- Framework vs. NON-Framework Comparison
- ELT Result Monitoring Dashboard
- Framework Adoption Considerations
- Conclusion
1. Framework vs. NON-Framework Comparison
1.1 spark-batch Framework Application Method
spark-batchis published as a Python package (PyPI) after development- Install and use the library with
pip install spark_batchcommand
1.2 Source Code Comparison Targets
NON-Framework Source (Previous blogs #1, #2, #3):
load_subway_info: Load subway informationload_subway_passengers: Load subway passenger dataload_subway_passengers_time: Load subway passenger data by time period
Framework-Applied Source:
f_load_subway_info: Framework-applied subway information loadingf_load_subway_passengers: Framework-applied subway passenger data loadingf_load_subway_passengers_time: Framework-applied passenger data loading by time period
1.3 Detailed Framework vs. NON-Framework Comparison
NON-Framework Version: load_subway_passengers
- Import statements: Direct import of necessary packages
from pyspark.sql import SparkSession
from pyspark.conf import SparkConf
from pyspark.sql.functions import lit, substring, col
from delta.tables import DeltaTable
import os
import psycopg2
import boto3
from botocore.exceptions import ClientError
- Spark session creation: High code complexity, commonly applied to all batch jobs
def create_spark_session(app_name, notebook_name, notebook_namespace, s3_access_key, s3_secret_key, s3_endpoint):
if is_running_in_jupyter():
conf = SparkConf()
# Spark driver, executor configuration
conf.set("spark.submit.deployMode", "client")
conf.set("spark.executor.instances", "1")
conf.set("spark.executor.memory", "1G")
conf.set("spark.driver.memory", "1G")
conf.set("spark.executor.cores", "1")
conf.set("spark.kubernetes.namespace", notebook_namespace)
...
# JAR packages required for s3, delta, postgresql usage
jar_list = ",".join([
"org.apache.hadoop:hadoop-common:3.3.4",
"org.apache.hadoop:hadoop-aws:3.3.4",
"com.amazonaws:aws-java-sdk:1.11.655",
"io.delta:delta-spark_2.12:3.3.1",
"org.postgresql:postgresql:42.7.2" # Added for PostgreSQL
])
conf.set("spark.jars.packages", jar_list)
# S3 settings
conf.set("spark.hadoop.fs.s3a.impl", "org.apache.hadoop.fs.s3a.S3AFileSystem")
conf.set('spark.hadoop.fs.s3a.path.style.access', 'true')
conf.set('spark.hadoop.fs.s3a.connection.ssl.enabled', 'true')
conf.set("spark.hadoop.fs.s3a.aws.credentials.provider", "org.apache.hadoop.fs.s3a.SimpleAWSCredentialsProvider")
conf.set('spark.hadoop.fs.s3a.access.key', s3_access_key)
conf.set('spark.hadoop.fs.s3a.secret.key', s3_secret_key)
conf.set('spark.hadoop.fs.s3a.endpoint', s3_endpoint)
# Delta Lake settings
conf.set("spark.sql.extensions", "io.delta.sql.DeltaSparkSessionExtension")
conf.set("spark.sql.catalog.spark_catalog", "org.apache.spark.sql.delta.catalog.DeltaCatalog")
# --- SparkSession build ---
spark = SparkSession.builder \
.appName(app_name) \
.master("k8s://https://kubernetes.default.svc.cluster.local:443")\
.config(conf=conf) \
.getOrCreate()
else:
# --- SparkSession build ---
spark = SparkSession.builder \
.appName(app_name) \
.master("k8s://https://kubernetes.default.svc.cluster.local:443")\
.getOrCreate()
return spark
- Data pipeline: High code complexity with direct exception handling
def subway_data_append(spark, s3_config, pg_config):
"""
Main pipeline processing CSV--> DELTA --> POSTGRESQL
"""
pg_url = f"jdbc:postgresql://{pg_config['host']}:{pg_config['port']}/{pg_config['dbname']}"
pg_properties = {
"user": pg_config['user'],
"password": pg_config['password'],
"driver": "org.postgresql.Driver"
}
print(f" bucket name is {s3_config['bucket']}")
csv_source_key = f"datasource/CARD_SUBWAY_MONTH_{WK_YM}.csv"
csv_archive_key = f"archive/CARD_SUBWAY_MONTH_{WK_YM}.csv"
csv_s3_path = f"s3a://{s3_config['bucket']}/{csv_source_key}"
delta_s3_path = f"s3a://{s3_config['bucket']}/deltalake/subway_passengers"
pg_table_name = "subway_passengers"
try:
print(f"\n--- Starting processing for {pg_table_name} during '{WK_YM}' ---")
# --- Step 1: Read S3 CSV ---
print(f"Reading CSV from {csv_s3_path}...")
# CSV schema or options (overwrite, inferSchema...) adjusted to match source file
csv_df = spark.read.option("header", "true").option("overwriteSchema", "true").csv(csv_s3_path)
# Add yyyymm column if needed or check existing columns
csv_df.createOrReplaceTempView("subway_data")
print(f"CSV for {WK_YM} loaded. Count: {csv_df.count()}")
csv_df.show(5)
# --- Step 2: Delete and insert in Delta Lake (using Spark SQL) ---
print(f"Deleting old data for {WK_YM} from Delta table: {delta_s3_path}")
if DeltaTable.isDeltaTable(spark, delta_s3_path):
# Modify WHERE condition to match '사용일자' column format
print(f" Delta Table {delta_s3_path} exists")
delete_delta_sql = f"delete from delta.`{delta_s3_path}` where `사용일자` like '{WK_YM}'||'%' "
delta_mode = "append"
try:
spark.sql(delete_delta_sql)
print(f"Deletion from Delta complete. Inserting new data for {WK_YM}...")
except Exception as e:
print(f"Skip on error occurred during Delta DELETE, even though table exists: {e}")
raise # Re-raise unexpected errors
else:
print(f" Delta Table {delta_s3_path} does not exist")
delta_mode = "overwrite"
# Write using DataFrame API (SQL INSERT INTO also possible, but DF API is more common for S3 writing)
csv_df.write.format("delta").mode(delta_mode).save(delta_s3_path)
print(f"Successfully wrote data to Delta table {delta_s3_path}.")
# --- Step 3: Move S3 CSV file ---
print(f"Archiving S3 CSV file...")
move_s3_file(s3_config, csv_source_key, csv_archive_key)
# --- Step 4: Delete and insert in PostgreSQL ---
print(f"Deleting old data for {WK_YM} from PostgreSQL table: {pg_table_name}")
conn = None
cursor = None
conn = psycopg2.connect (
host=pg_config['host'],
port=pg_config['port'],
dbname=pg_config['dbname'],
user=pg_config['user'],
password=pg_config['password'] )
cursor = conn.cursor()
delete_sql = f" delete from {pg_table_name} where use_date like '{WK_YM}'||'%' "
print(f"Executing DELETE query: {delete_sql}")
cursor.execute(delete_sql)
deleted_rows = cursor.rowcount
if cursor: cursor.close()
if conn:
conn.commit()
conn.close()
print(f"Successfully executed DELETE query. {deleted_rows} rows deleted.")
print(f"Inserting data for {WK_YM} into PostgreSQL table: {pg_table_name}")
# Spark SQL query to process data
insert_sql = f"""
select `사용일자` use_date
,`노선명` line_no
,`역명` station_name
,cast(`승차총승객수` as int) pass_in
,cast(`하차총승객수` as int) pass_out
,substring(`등록일자`,1,8) reg_date
from delta.`{delta_s3_path}`
where `사용일자` like '{WK_YM}'||'%'
"""
print(insert_sql)
delta_df = spark.sql(insert_sql)
delta_df.write \
.jdbc(url=pg_url,
table=pg_table_name,
mode="append",
properties=pg_properties)
print(f"Successfully wrote data to PostgreSQL table {pg_table_name}.")
print(f"--- Processing for {WK_YM} completed successfully! ---")
except Exception as e:
print(f"An error occurred during processing {WK_YM}: {e}")
import traceback
traceback.print_exc()
Framework-Applied Version: f_load_subway_passengers
- Import statements: Import only necessary features from spark_batch
from spark_batch.lib.spark_session import get_spark_session
from spark_batch.lib.elt_manager import EltManager
from spark_batch.lib.pxlogger import CustomLogger
from spark_batch.lib.util import toTargetCondition
- ELT operations possible immediately after spark session creation and EltManager instance creation
spark = get_spark_session(app_name="f_load_subway_passengers",notebook_name="test", notebook_namespace="demo01-kf", \
executor_instances="1", executor_memory="1G", executor_cores="1", driver_memory="1G", driver_cores="1" )
em = EltManager(spark, config_file="config.yaml", domain="life", record_type="mart", record_prefix="hopt")
- Data pipeline: Simple code with exception handling performed by the framework
- Added delta.bronze--> delta.gold processing compared to load_subway_passengers
# csv --> delta.bronze
source_type = "csv1"; source_topic = "paasup"; source_dpath="datasource/life"
target_type = "delta1"; target_topic = "paasup"; target_dpath="bronze/life"
em.init_rsm(source_type, source_topic, source_dpath, target_type, target_topic, target_dpath, chunk_size=500000)
source_objects = ["CARD_SUBWAY_MONTH_{WK_YM}.csv".format(WK_YM=WK_YM)]; target_object = "CARD_SUBWAY_MONTH"
source_inc_query = f"""
select * from CARD_SUBWAY_MONTH
"""
target_condition = f" `사용일자` like '{WK_YM}'||'%' "
source_df, target_df, valid = em.ingest_increment(source_objects, target_object, source_inc_query, target_condition, delemeter=",")
# delta.bronze --> delta.gold (cleansing or processing)
source_type = "delta1"; source_topic = "paasup"; source_dpath="bronze/life"
target_type = "delta1"; target_topic = "paasup"; target_dpath="gold"
em.init_rsm(source_type, source_topic, source_dpath, target_type, target_topic, target_dpath, chunk_size=500000)
source_objects = ["CARD_SUBWAY_MONTH"]; target_object = "subway_passengers"
source_inc_query = f"""
select `사용일자` use_date
, `노선명` line_no
, `역명` station_name
, `승차총승객수` pass_in
, `하차총승객수` pass_out
, `등록일자` reg_date
from CARD_SUBWAY_MONTH
where `사용일자` like '{WK_YM}'||'%'
"""
target_condition = f"""
use_date like '{WK_YM}'||'%'
"""
source_df, target_df, valid = em.ingest_increment(source_objects, target_object, source_inc_query, target_condition)
# delta.gold --> mart
source_type = "delta1"; source_topic = "paasup"; source_dpath="gold"
target_type = "mart"; target_topic = "postgres"; target_dpath=None
em.init_rsm(source_type, source_topic, source_dpath, target_type, target_topic, target_dpath, chunk_size=500000)
source_objects = ["subway_passengers"]; target_object = "subway_passengers"
source_inc_query = f"""
select use_date
, line_no
, station_name
, cast(pass_in as int) pass_in
, cast(pass_out as int) pass_out
, reg_date
from subway_passengers
where use_date like '{WK_YM}'||'%'
"""
target_condition = f"""
use_date like '{WK_YM}'||'%'
"""
source_df, target_df, valid = em.ingest_increment(source_objects, target_object, source_inc_query, target_condition)
1.3 Key Advantages of Framework Application
1) Code Simplification
- SparkSession management, exception handling, and resource cleanup automatically handled by the framework
- Focus possible on business logic only
2) Standardized Structure
- All ELT operations follow the same pattern
- Easy for new developers to understand and apply
3) Automatic Monitoring
- Automatic logging by the framework
- Automatic collection of execution time, processing count, and error information
4) Configuration-Based Development
- Flexible data processing through source/target configuration
- Minimized hard-coding
2. ELT Result Monitoring Dashboard
One of the biggest advantages of the spark-batch framework is the automatic logging feature for ELT operation monitoring. Every time developers call ELT functions, operation results are automatically saved to log tables, based on which we built a comprehensive monitoring dashboard using Apache Superset.
2.1 Dashboard Components
Filter Options
- TIME RANGE: ELT operation period selection
- VALID: Success/failure filtering for operations
- DOMAIN: ELT operation classification (classified by target subject area, etc., specified in ELT operations)
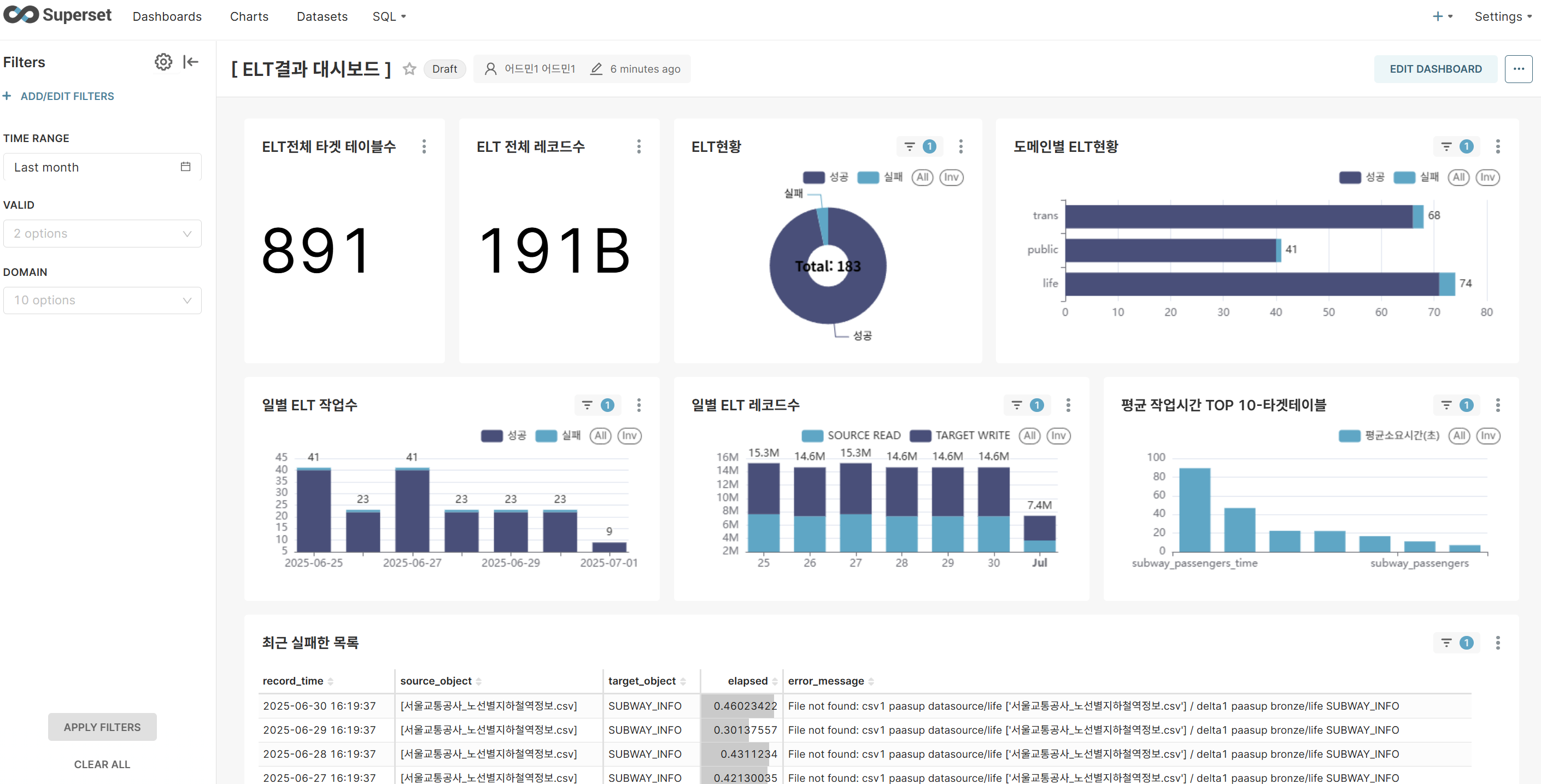
Chart Configuration
Chart 1: Total ELT Target Tables (BIG NUMBER)

- KPI for all ELT operations (filters not applied)
- Analyze overall ELT operation load by understanding the number of ELT target tables at a glance
Chart 2: Total ELT Records (BIG NUMBER)

- KPI for all ELT operations (filters not applied)
- Measure data scale and business impact processed by the system
Chart 3: ELT Status (PIE CHART)
- Analyze success/failure counts and ratios for ELT operations
- When failures occur, immediately identify the need for response measures like rework
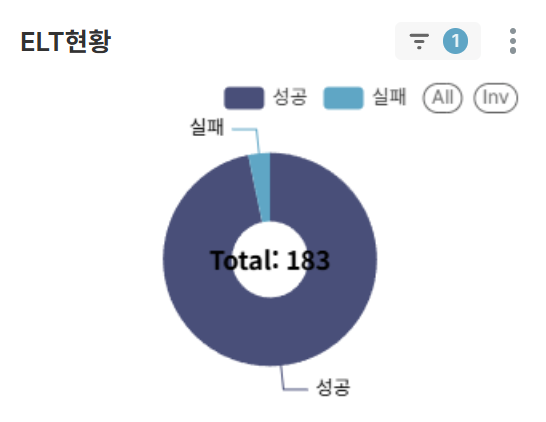
Chart 4: ELT Status by Domain (BAR CHART)
- Understand success/failure counts by ELT operation domain at a glance
- Identify domains requiring response measures like rework when failures occur
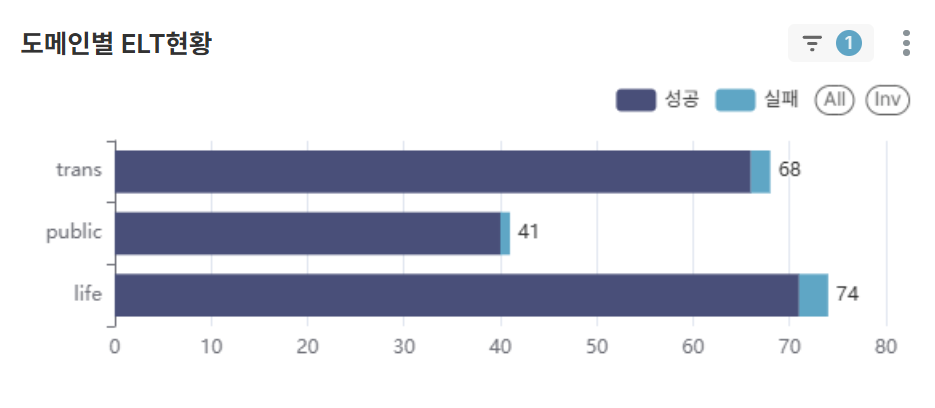
Chart 5: Daily ELT Operations (BAR CHART)
- Monitor daily ELT operation success/failure counts to predict error occurrence timing
- Identify the need for response measures to repetitive failures
Chart 6: Daily ELT Records (BAR CHART)
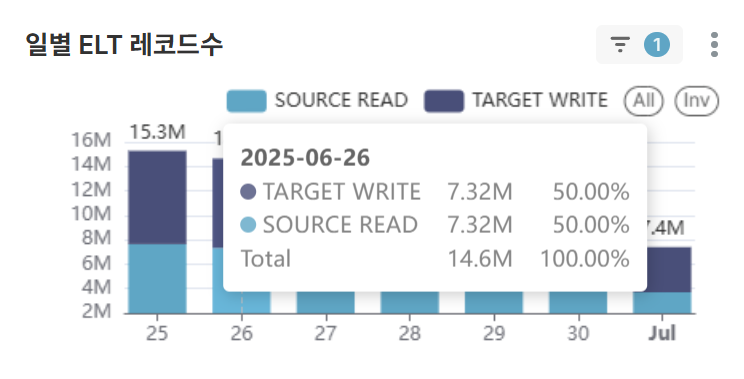
- Analyze target data processing efficiency against source data processing increase trends and monitor data filtering/transformation ratios
- Check upstream system status and establish infrastructure capacity planning when sudden data volume changes occur
Chart 7: Recent Failure List (TABLE)
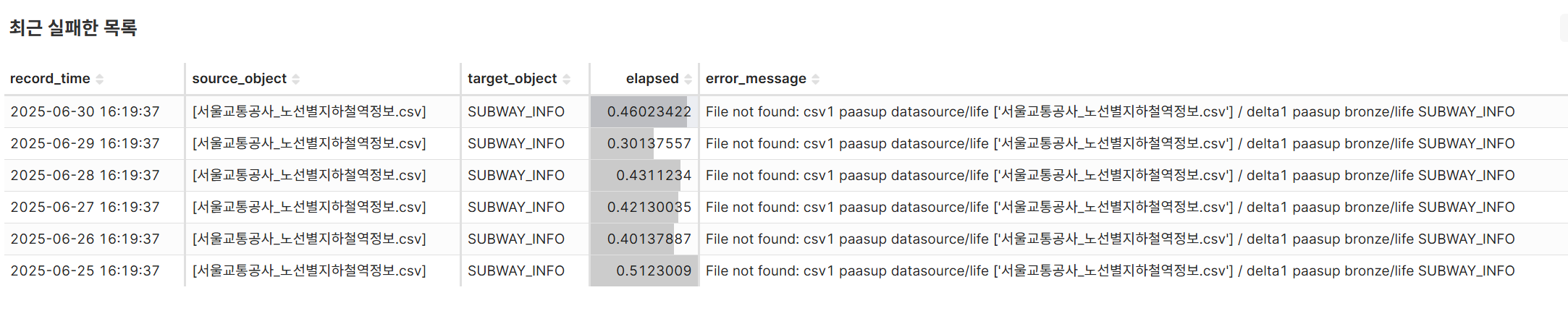
- Derive solutions through error log analysis in reverse chronological order and identify repetitive failure patterns for specific source/target objects
- Identify system improvement points through error message type analysis and improve failure response processes
2.2 Dashboard Utilization Effects
1) Real-time Operation Monitoring
- Real-time understanding of ELT operation status
- Immediate detection and response possible when failures occur
2) Performance Analysis
- Identify optimization points through operation-specific time consumption analysis
- Establish infrastructure resource planning through data processing volume trends
3) Quality Management
- Ensure pipeline stability through success rate monitoring
- Derive improvement measures through failure cause analysis
4) Operational Efficiency
- Reduce operational burden on administrators and developers
- Support data-driven decision making
3. Framework Adoption Considerations
3.1 Advantages
- Enhanced Development Productivity: Elimination of repetitive code and standardization
- Strengthened Operational Stability: Automatic monitoring and exception handling
- Improved Maintainability: Consistent structure and patterns
- Enhanced Collaboration Efficiency: Common development rules within teams
3.2 Disadvantages and Precautions
- Learning Curve: Time required to understand and adapt to the framework
- Increased Dependencies: Expanded impact scope when framework changes
- Limited Flexibility: Potential constraints when addressing special requirements
3.3 Adoption Guidelines
- Consider team size and project complexity
- Review compatibility with existing systems
- Establish framework customization plans
- Plan team member training and documentation
Conclusion
This post examined practical application cases using the spark-batch framework as an extension of the PaasUp DIP series. Through framework application, we were able to significantly improve development productivity and operational stability, with systematic operational management particularly enabled through ELT monitoring dashboards.
Framework-based development is more suitable than pure library implementation in actual operating environments, with the following expected effects:
- Development time reduction (approximately 50% or more decrease)
- Code quality improvement (standardized pattern application)
- Enhanced operational stability (automatic monitoring and logging)
- Increased collaboration efficiency (common development rule application)