
Modern Data Pipeline Implementation with PaasupDIP: Subway User Statistics Analysis Project #1
This blog introduces a project using the PAASUP DIP to implement a modern data pipeline that processes and analyzes over 10 years of Seoul subway ridership data through Apache Spark, Delta Lake, and PostgreSQL, combined with Apache Superset dashboards for multi-dimensional data visualization.
Seoul Subway Usage Analysis Project
Introduction
In the first part of this series , the subway of modern cities is one of the most important public transportation systems. By analyzing the usage patterns of subways used by countless citizens daily, we can understand the flow of the city and citizens' lifestyle patterns.
This project aims to collect and analyze subway ridership data by line and day to derive meaningful insights. Through this analysis, we will provide results that can be utilized in various fields such as transportation policy development, commercial area analysis, and urban planning.
1. Project Overview
2. Data Visualization
3. Project Environment Setup
4. Data Pipeline Design and Implementation
5. Project Results and Implications
Project Overview
Objective: Building a comprehensive analysis dashboard utilizing subway ridership statistics
Data Sources
- Subway Ridership Statistics (10 years and 4 months of data, Source: Public Data Portal)
- Subway Station Information (Source: Public Data Portal)
Technology Stack:
- Data Processing: Apache Spark
- Data Storage: Delta Lake, PostgreSQL
- Visualization: Apache Superset
- Development Environment: Jupyter Notebook
- Platform: DIP Portal
Data Visualization
Data visualization is a key element that helps us intuitively understand complex data. In this project, we implemented 3 dashboards using Apache Superset.
Dashboard 1: Station-wise Ridership Trends
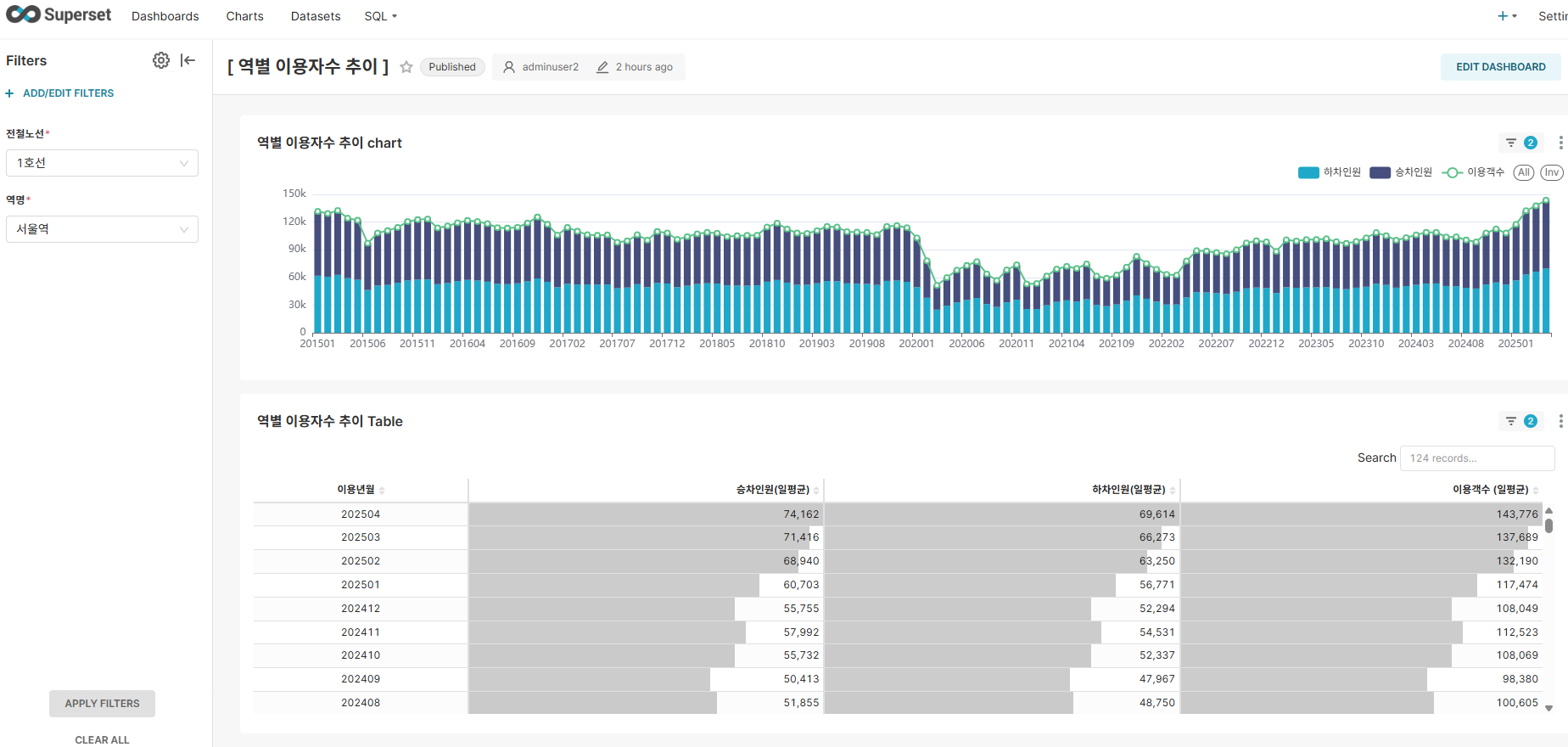
Key Features:
- Time Series Analysis: Monthly ridership trend visualization
- Dynamic Filters: Dynamic filtering by line and station
- Interaction: Detailed analysis through drill-down
Key Insights:
- Sharp decline in ridership from early 2020 due to COVID-19 impact, with low ridership continuing until 2022
- Gradual increase in ridership from late 2022, with stable usage patterns established after 2023
- Confirmed seasonal characteristics with regular minor fluctuations
Dashboard 2: Daily Average Ridership by Line
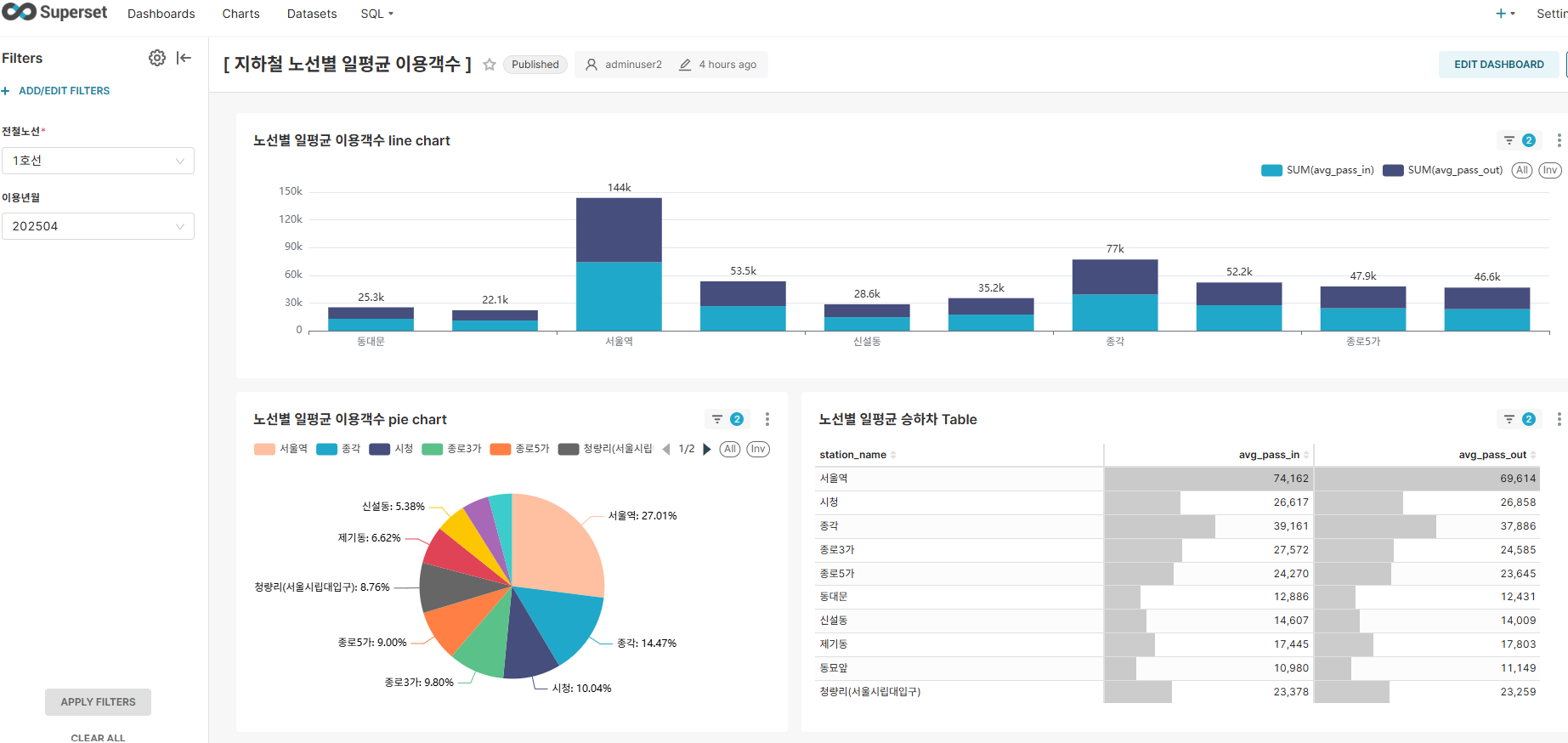
Key Features:
- Density Analysis: Overview of ridership density by line
- Dynamic Filters: Filtering by line and usage month
- Ranking Analysis: Dynamic station ranking sorting capability
Key Insights:
- Confirmed downtown-concentrated transportation usage patterns such as Seoul Station on Line 1 and Gangnam Station on Line 2
- Clear ridership gap between major transfer stations and regular stations
- Confirmed normal subway usage patterns with similar boarding and alighting passenger numbers at most stations
Dashboard 3: Ridership by Day of Week
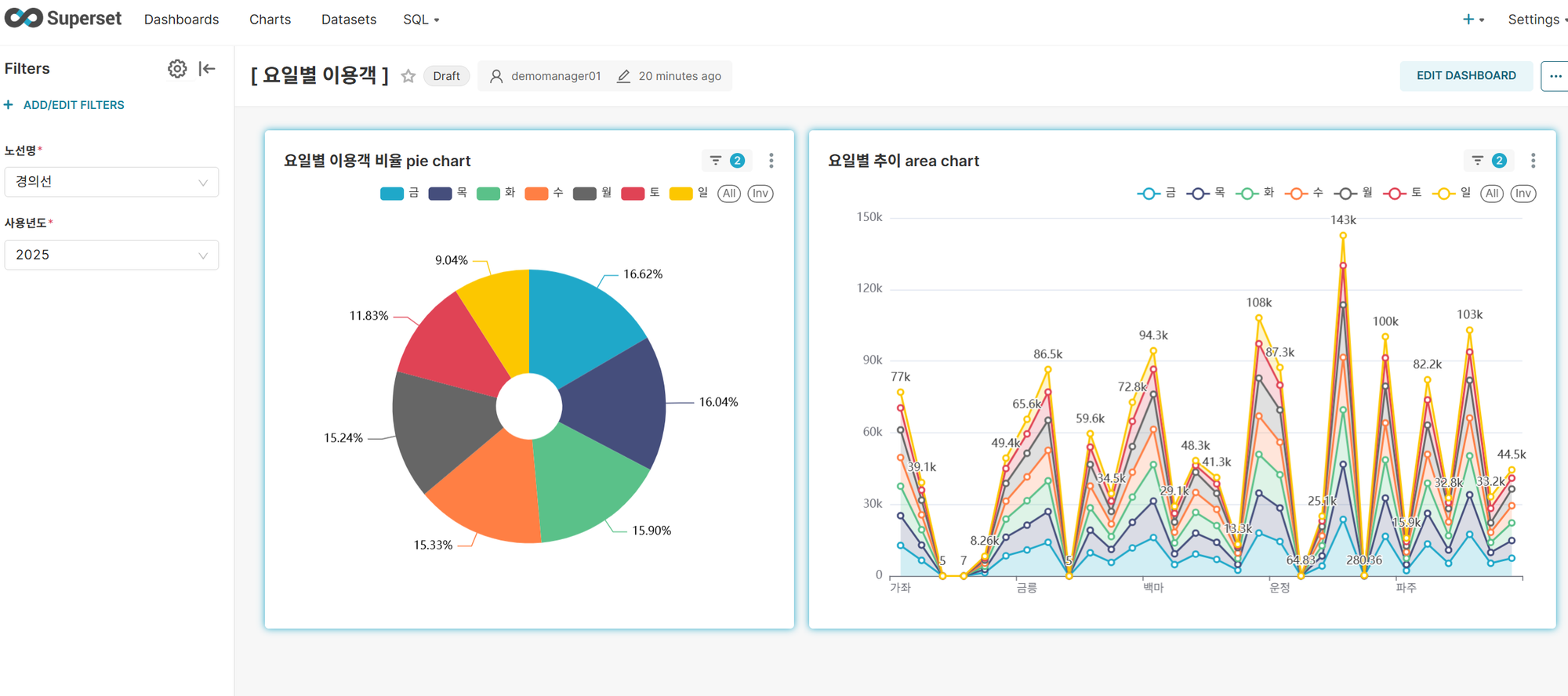
Key Features:
- Density Analysis: Overview of ridership ratios by day of week, by line and station
- Dynamic Filters: Filtering by line and usage year
- Ranking Analysis: Sorting by day of week ranking
- Other: Time-based analysis would be possible if raw data included usage hours, but only daily data is available, making hourly analysis impossible
Key Insights:
- Friday shows the highest usage rate among weekdays, with other weekdays showing even distribution (TGIF phenomenon)
- Weekday vs Weekend gap: Weekend (Saturday/Sunday) usage rates are significantly lower than weekdays, confirming commuting/school-centered usage patterns
- Minimal Monday blues effect: Similar levels to Tuesday
Project Environment Setup
This project can build all necessary environments with simple operations through the DIP (Data Intelligence Platform) portal.
Required Service Catalog
- Kubeflow: Workflow management linked with Jupyter Notebook
- PostgreSQL: Data storage and management
- Apache Superset: Data visualization and dashboard
Step-by-Step Environment Setup Guide
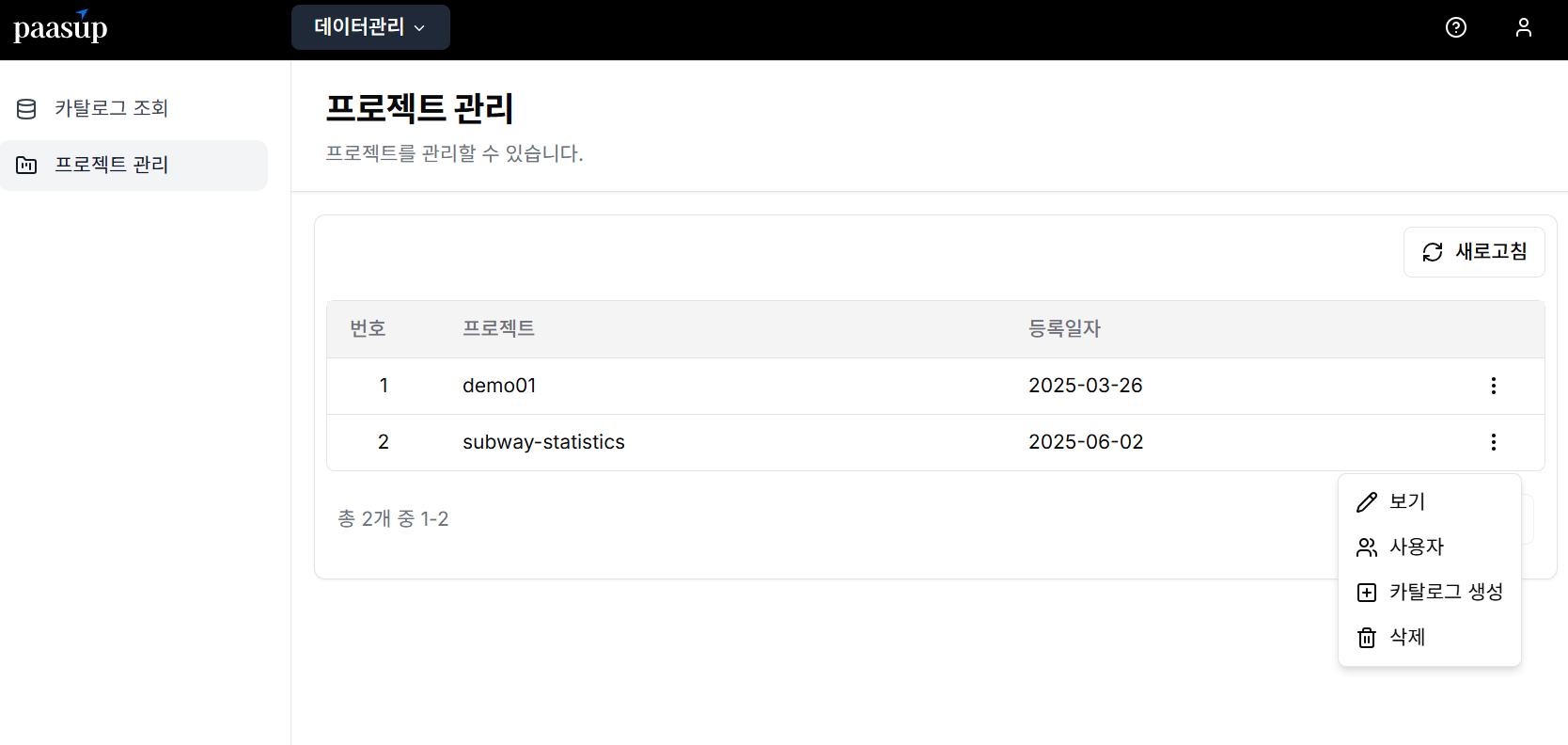
Step 1: Login and Project Selection
DIP administrator first creates the project and manager account. After logging in with the created account, view the project list assigned to the manager and select the catalog creation menu.
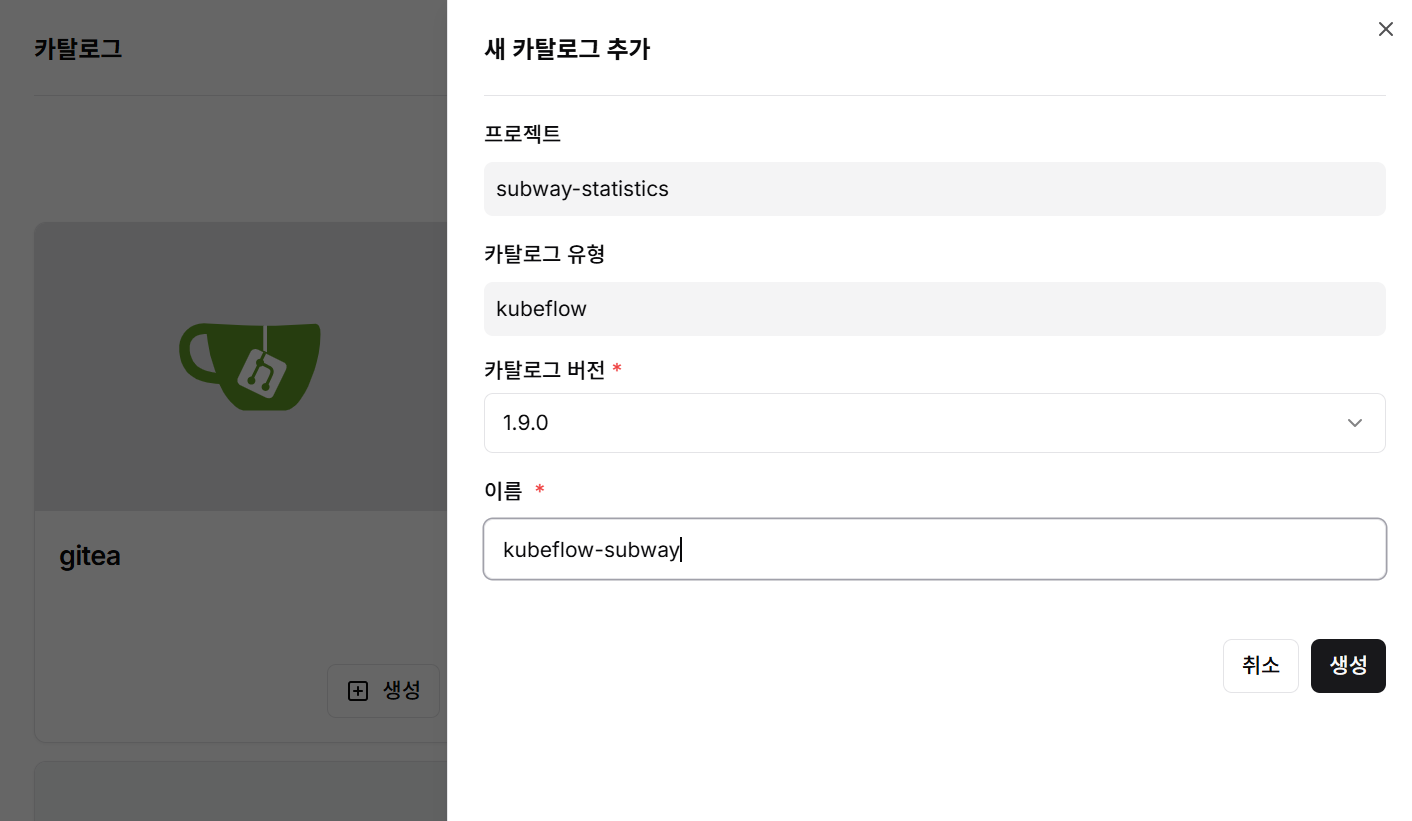
Step 2: Kubeflow Catalog Creation
- Select Kubeflow from the catalog creation menu
- Enter catalog version and name
- Click create button to generate catalog
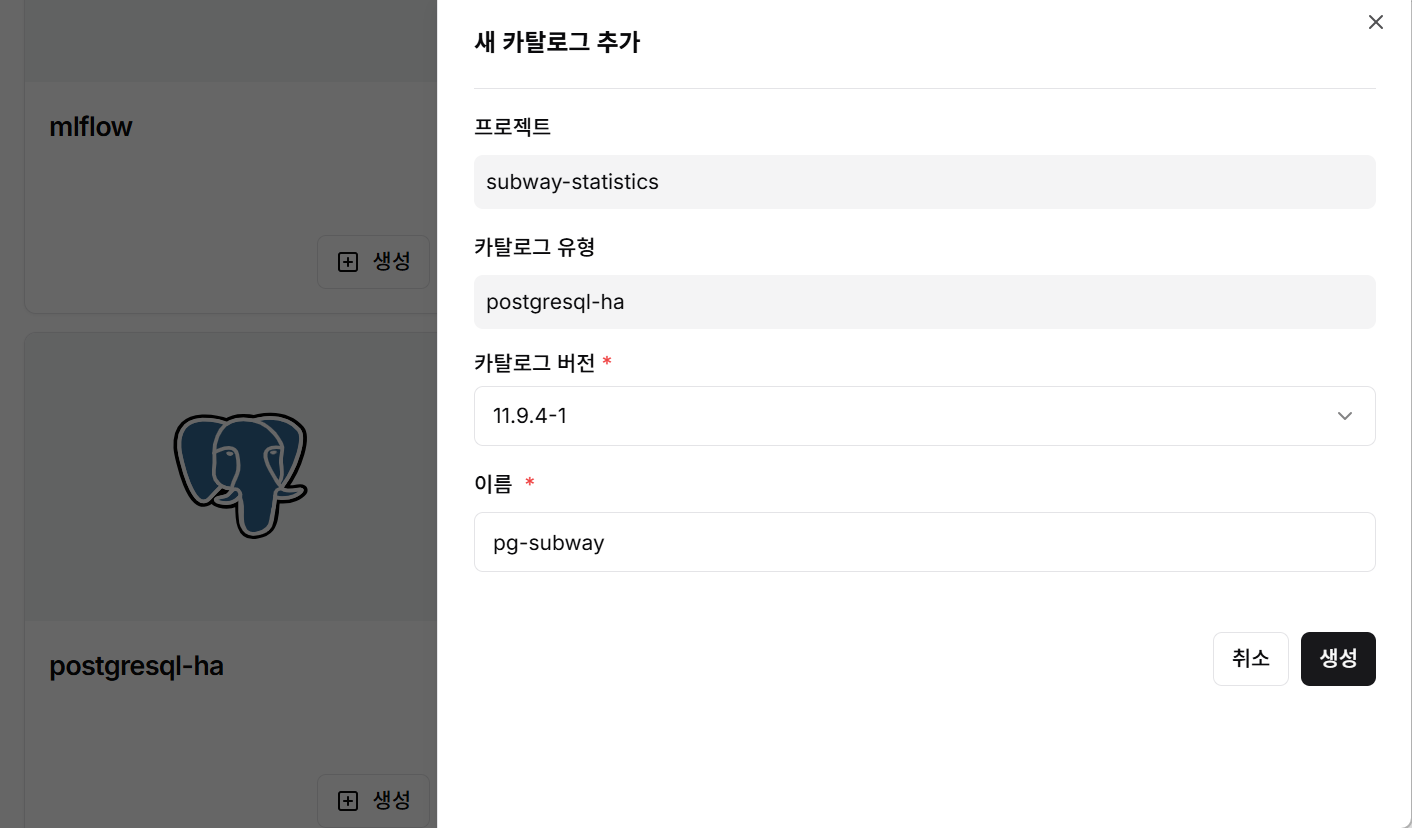
Step 3: PostgreSQL Catalog Creation
- Select PostgreSQL catalog
- Enter catalog version and name
- Click create button to build database environment
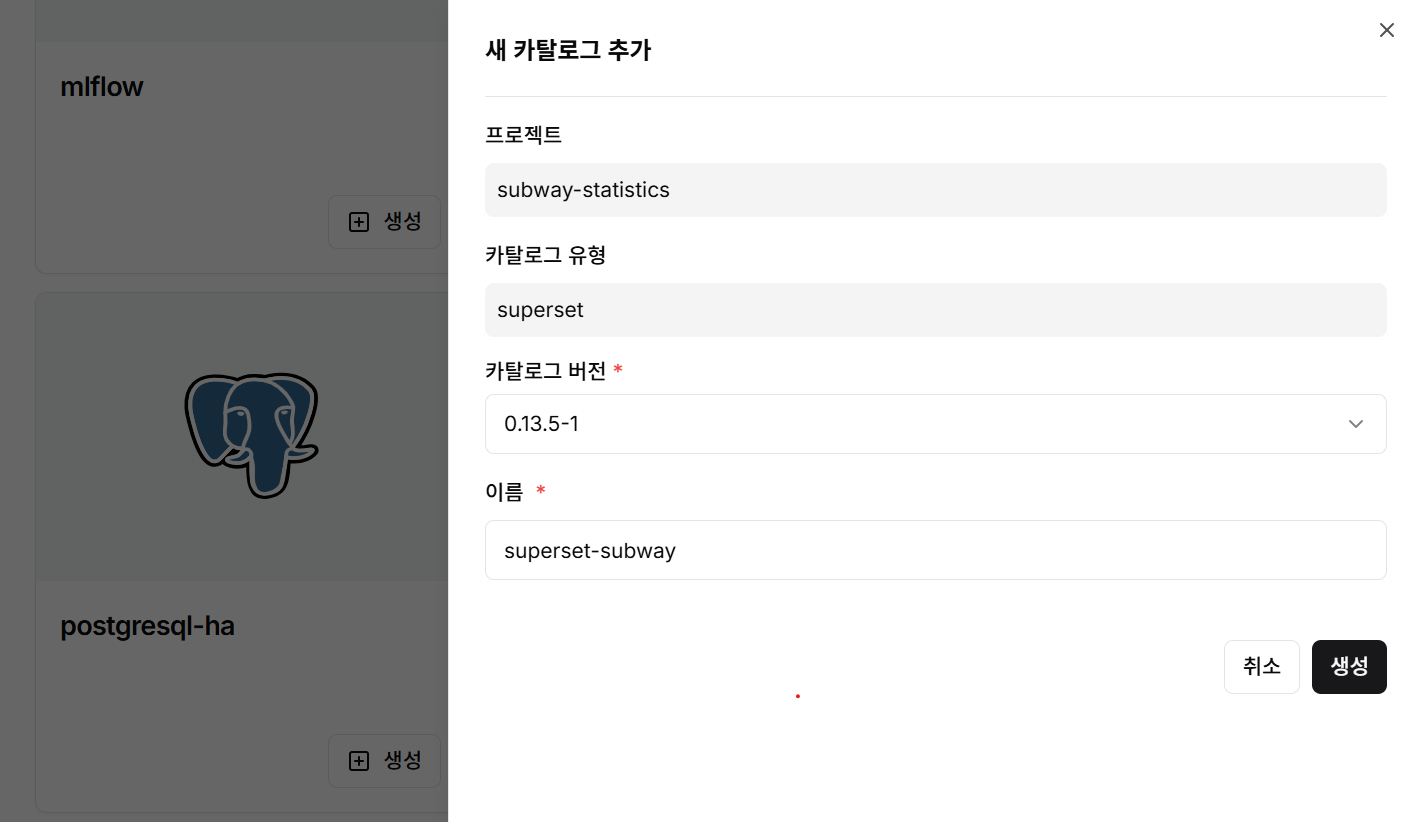
Step 4: Superset Catalog Creation
- Select Apache Superset catalog
- Enter catalog version and name
- Click create button to build visualization environment
Step 5: Catalog Status Verification
In the catalog inquiry screen, you can monitor the deployment status and service status of each catalog created by project unit in real-time.
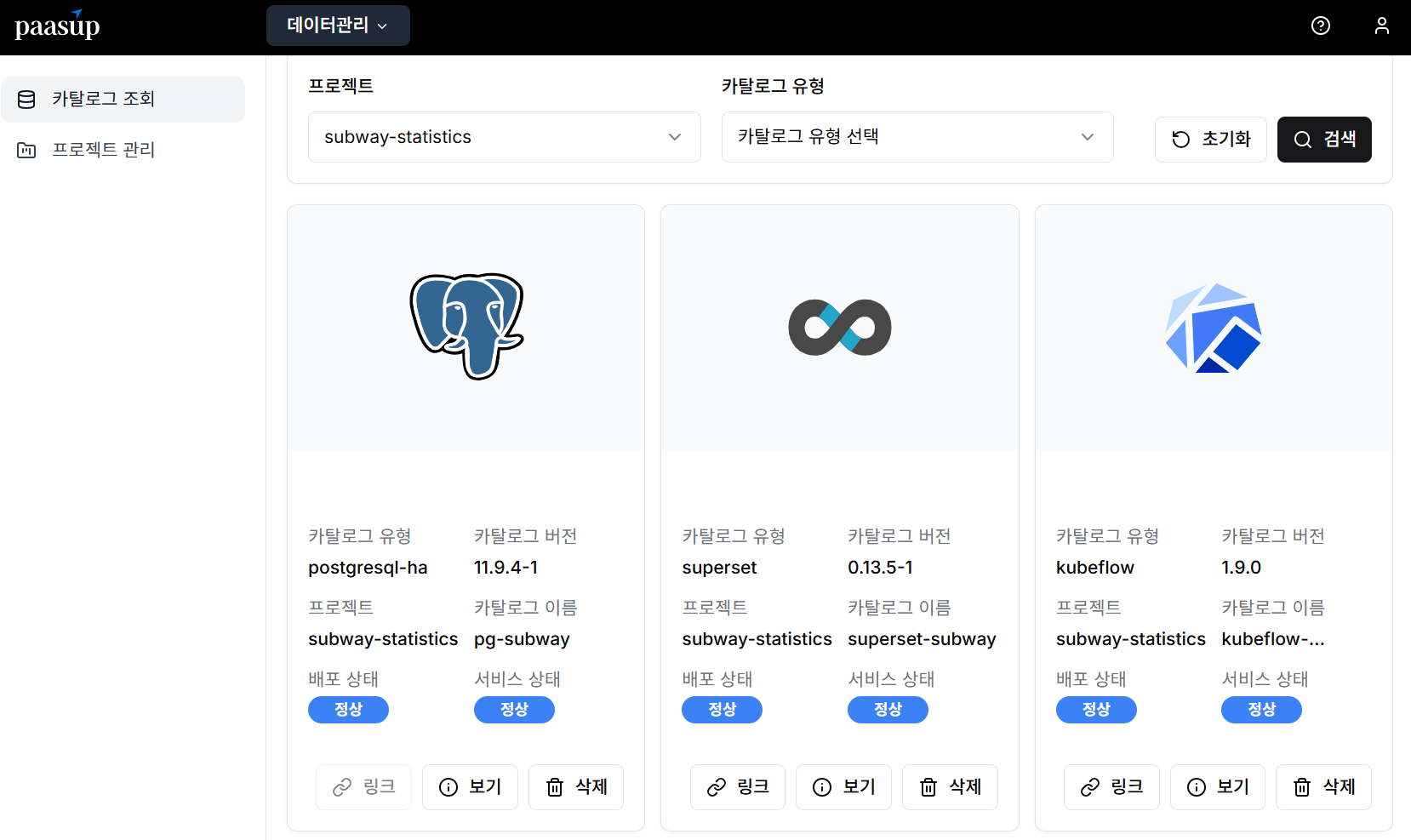
Step 6: PostgreSQL Connection Information Verification
The pg-host and pg-port information for accessing PostgreSQL from applications can be found in the detailed information screen of the corresponding catalog.

Step 7: Jupyter Notebook Environment Creation
To build a JupyterLab environment for Python code development, create a notebook instance through the Kubeflow service link.
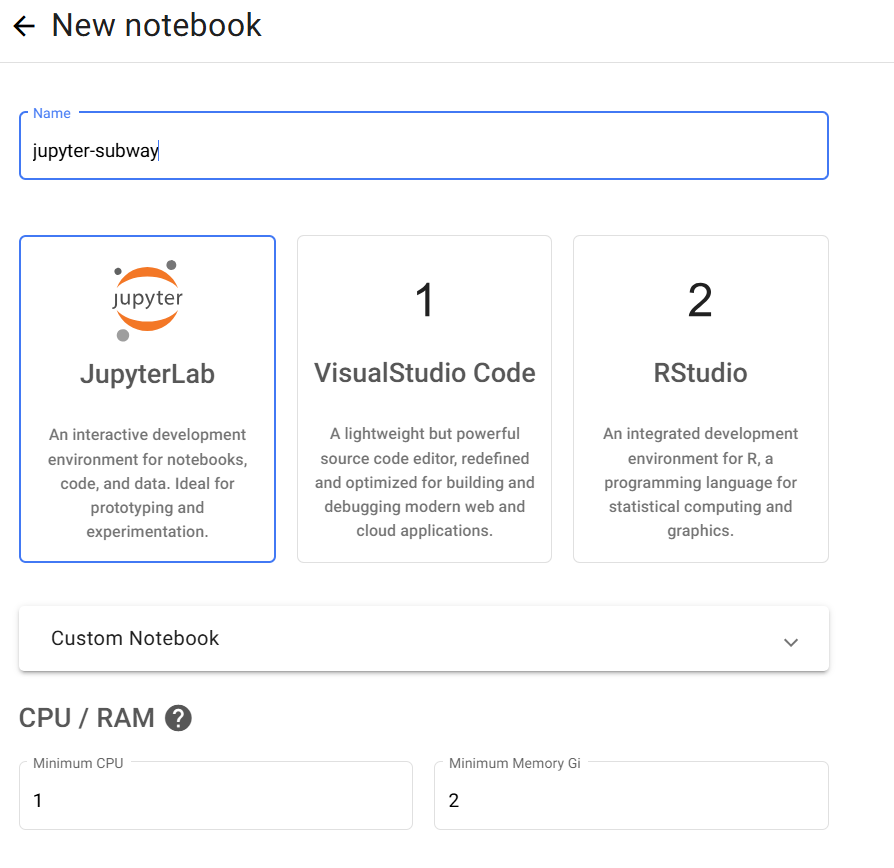
Step 8: Development Environment Access
Clicking the Connect link in Jupyter Notebook provides access to an environment where you can develop necessary applications using Python code.
Data Pipeline Design and Implementation
Step 1: Data Collection and Preprocessing
The raw data in CSV format collected from the Public Data Portal had the following characteristics:
- Data Scale: Daily aggregated data for 10 years and 4 months
- Source Data Information:
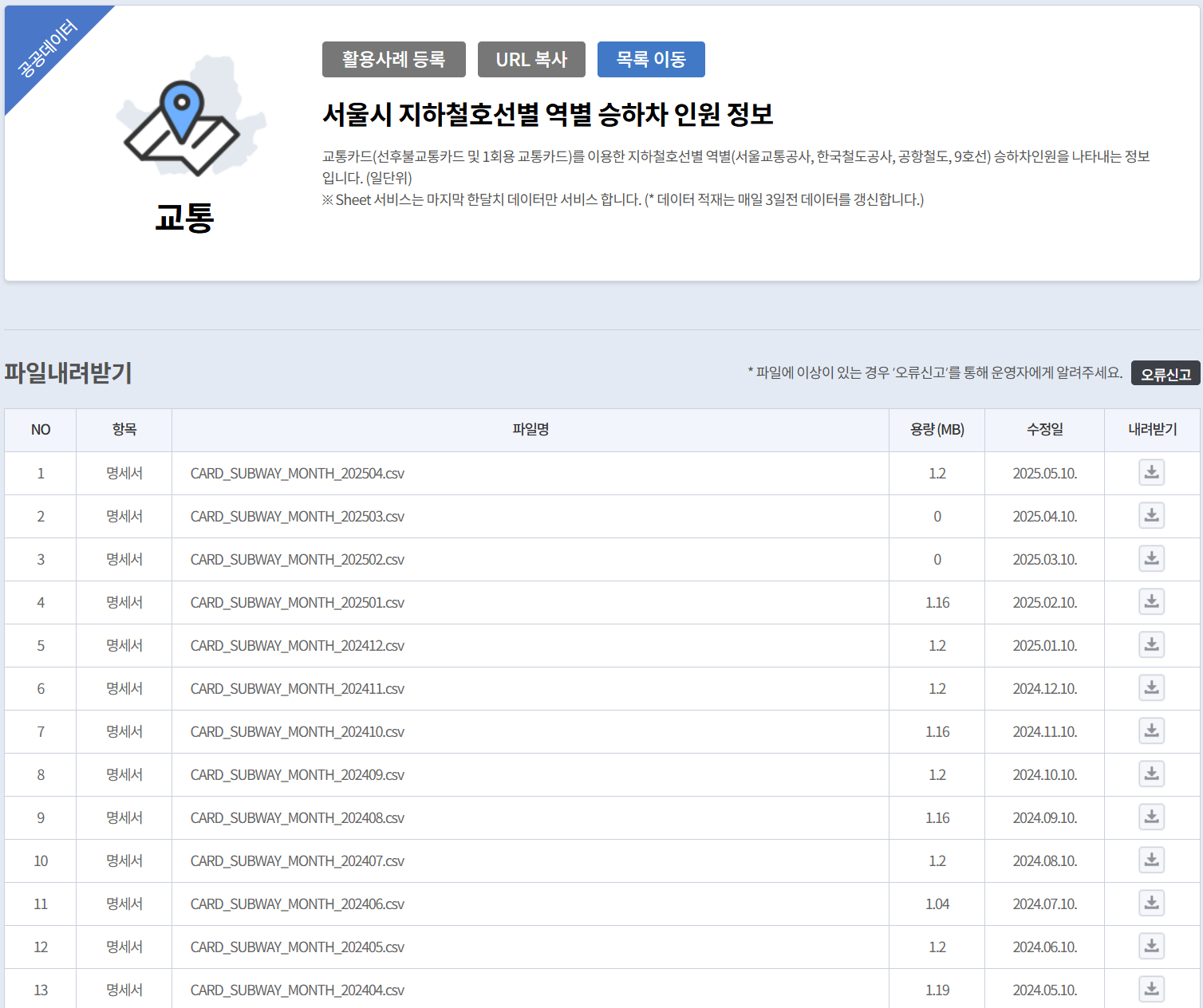
- Boarding/alighting passenger information by line/station/day (CARD_SUBWAY_MONTH_{WK_YM}.csv) - all files
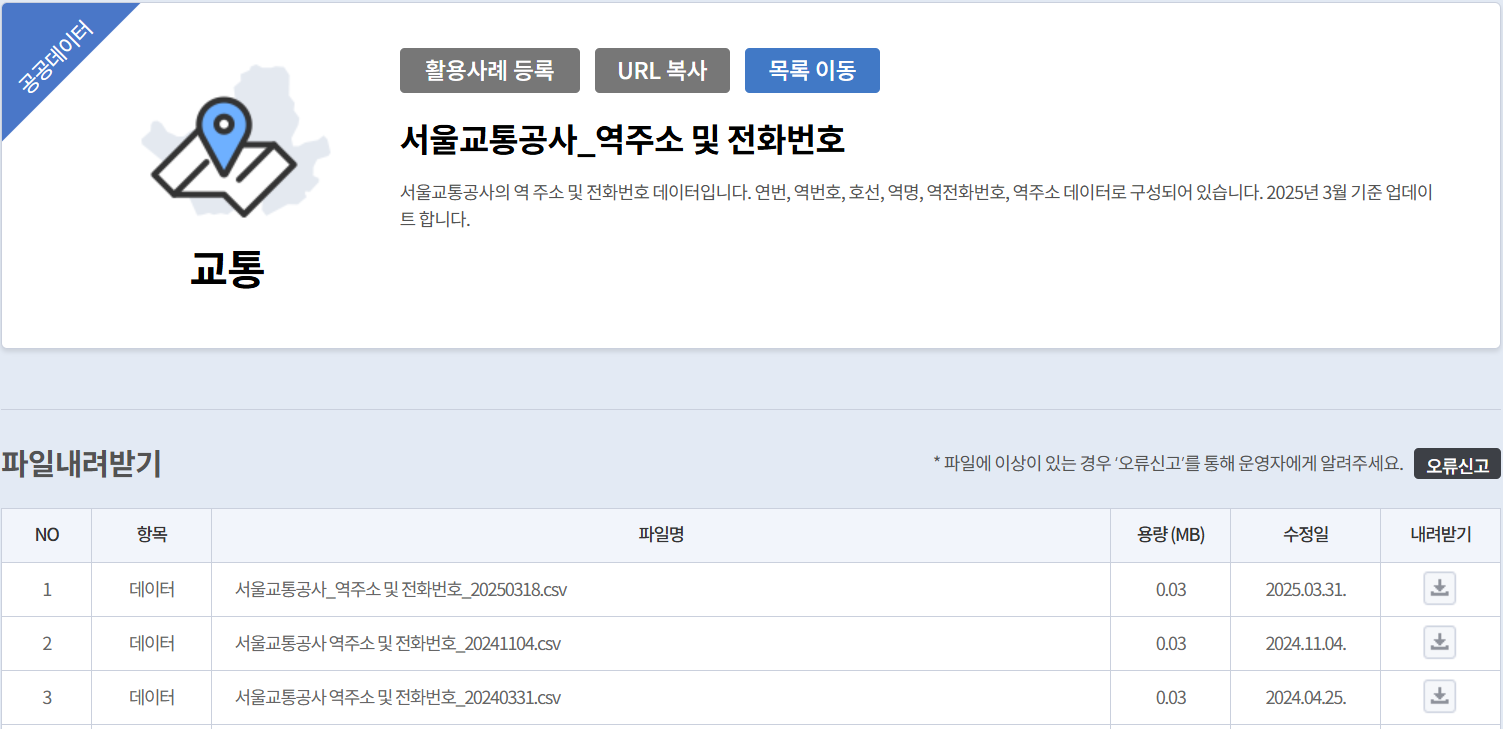
- Subway station information (Seoul Transportation Corporation_Subway Station Information by Line.csv) - 1 final file
- Boarding/alighting passenger information by line/station/day (CARD_SUBWAY_MONTH_{WK_YM}.csv) - all files
- Data Quality Issues:
- Inconsistent line names and station names between the two source datasets
- Occasional Korean character corruption: resolved by saving as UTF-8 CSV in Excel
- Spark errors when special characters exist in the first row (labels): resolved by removing special characters before saving
Step 2: PostgreSQL Data Mart Model Creation
Configured optimized PostgreSQL data model for analysis:
-- Create subway passenger information table
CREATE TABLE subway_passengers (
use_date varchar(8) not null, -- Usage date
line_no varchar(100) not NULL, -- Line name
station_name varchar(100) not NULL, -- Station name
pass_in numeric(13) NULL, -- Boarding passengers
pass_out numeric(13) NULL, -- Alighting passengers
reg_date varchar(8) null -- Registration date
);
create index subway_passengers_idk1 on subway_passengers (use_date, line_no, station_name);
-- Create subway station information table
CREATE TABLE subway_info (
station_name varchar(100) not NULL, -- Station name
line_no varchar(100) not NULL, -- Line name
station_cd varchar(10), -- Station code (for sorting)
station_cd_external varchar(10), -- Station code (external)
station_ename varchar(100), -- Station name (English)
station_cname varchar(100), -- Station name (Chinese)
station_jname varchar(100) -- Station name (Japanese)
);
create index subway_info_idk1 on subway_info (station_name, line_no, station_cd);
Step 3: Spark-based Data Transformation (CSV → Delta → PostgreSQL)
Using DIP's Spark cluster, we performed the following data transformation tasks:
load_subway_passengers.ipynb: Subway passenger information data transformation
- Import necessary libraries
from pyspark.sql import SparkSession
from pyspark.conf import SparkConf
from pyspark.sql.functions import lit, substring, col
from delta.tables import DeltaTable
import os
from dotenv import load_dotenv
import psycopg2
import boto3
from botocore.exceptions import ClientError
- Spark Session creation function: Common Library
def create_spark_session(app_name, notebook_name, notebook_namespace, s3_access_key, s3_secret_key, s3_endpoint):
conf = SparkConf()
# Spark driver, executor configuration
conf.set("spark.submit.deployMode", "client")
conf.set("spark.executor.instances", "1")
# Omitted for brevity...
# JAR packages required for S3, Delta, PostgreSQL usage
jar_list = ",".join([
"org.apache.hadoop:hadoop-common:3.3.4",
"org.apache.hadoop:hadoop-aws:3.3.4",
"com.amazonaws:aws-java-sdk:1.11.655",
"io.delta:delta-spark_2.12:3.3.1",
"org.postgresql:postgresql:42.7.2"
])
conf.set("spark.jars.packages", jar_list)
# Omitted for brevity...
# Build SparkSession
spark = SparkSession.builder \
.appName(app_name) \
.config(conf=conf) \
.getOrCreate()
return spark
- Function to save CSV to Delta and move S3 CSV file: Common Library
def move_s3_file(s3_config, source_key, dest_key):
"""
Move files within S3 using boto3 (copy then delete).
"""
s3_client = boto3.client(
's3',
aws_access_key_id=s3_config['access_key'],
aws_secret_access_key=s3_config['secret_key'],
endpoint_url=s3_config['endpoint'],
verify=False # May be needed when using self-signed certificates
)
try:
copy_source = {'Bucket': s3_config['bucket'], 'Key': source_key}
print(f"Copying S3 object from {source_key} to {dest_key}...")
s3_client.copy_object(CopySource=copy_source, Bucket=s3_config['bucket'], Key=dest_key)
print(f"Deleting source S3 object: {source_key}...")
s3_client.delete_object(Bucket=s3_config['bucket'], Key=source_key)
print(f"Successfully moved {source_key} to {dest_key}.")
return True
except ClientError as e:
print(f"Error moving S3 file: {e}")
return False
except Exception as e:
print(f"An unexpected error occurred during S3 move: {e}")
return False
- Main data processing function
Implemented for incremental loading (Append) and reprocessing capability since data source files (CSV) are monthly units
def subway_data_append(spark, s3_config, pg_config):
"""
Main pipeline processing CSV --> DELTA --> POSTGRESQL
"""
pg_url = f"jdbc:postgresql://{pg_config['host']}:{pg_config['port']}/{pg_config['dbname']}"
pg_properties = {
"user": pg_config['user'],
"password": pg_config['password'],
"driver": "org.postgresql.Driver"
}
print(f" bucket name is {s3_config['bucket']}")
csv_source_key = f"datasource/CARD_SUBWAY_MONTH_{WK_YM}.csv"
csv_archive_key = f"archive/CARD_SUBWAY_MONTH_{WK_YM}.csv"
csv_s3_path = f"s3a://{s3_config['bucket']}/{csv_source_key}"
delta_s3_path = f"s3a://{s3_config['bucket']}/{s3_config['delta_path']}"
try:
print(f"\n--- Starting processing for {pg_config['table']} during '{WK_YM}' ---")
# Step 1: Read S3 CSV
print(f"Reading CSV from {csv_s3_path}...")
csv_df = spark.read.option("header", "true").option("overwriteSchema", "true").csv(csv_s3_path)
csv_df.createOrReplaceTempView("subway_data")
print(f"CSV for {WK_YM} loaded. Count: {csv_df.count()}")
csv_df.show(5)
# Step 2: Delete and insert to Delta Lake (using Spark SQL)
print(f"Deleting old data for {WK_YM} from Delta table: {delta_s3_path}")
if DeltaTable.isDeltaTable(spark, delta_s3_path):
print(f" Delta Table {delta_s3_path} exists")
delete_delta_sql = f"delete from delta.`{delta_s3_path}` where `사용일자` like '{WK_YM}'||'%' "
delta_mode = "append"
try:
spark.sql(delete_delta_sql)
print(f"Deletion from Delta complete. Inserting new data for {WK_YM}...")
except Exception as e:
print(f"Skip on error occurred during Delta DELETE, even though table exists: {e}")
raise
else:
print(f" Delta Table {delta_s3_path} does not exist")
delta_mode = "overwrite"
# Write using DataFrame API
csv_df.write.format("delta").mode(delta_mode).save(delta_s3_path)
print(f"Successfully wrote data to Delta table {delta_s3_path}.")
# Step 3: Move S3 CSV file
print(f"Archiving S3 CSV file...")
move_s3_file(s3_config, csv_source_key, csv_archive_key)
# Step 4: Delete and insert to PostgreSQL
pg_table_name = pg_config['table']
print(f"Deleting old data for {WK_YM} from PostgreSQL table: {pg_table_name}")
conn = None
cursor = None
conn = psycopg2.connect(
host=pg_config['host'],
port=pg_config['port'],
dbname=pg_config['dbname'],
user=pg_config['user'],
password=pg_config['password']
)
cursor = conn.cursor()
delete_sql = f" delete from {pg_table_name} where use_date like '{WK_YM}'||'%' "
print(f"Executing DELETE query: {delete_sql}")
cursor.execute(delete_sql)
deleted_rows = cursor.rowcount
if cursor: cursor.close()
if conn:
conn.commit()
conn.close()
print(f"Successfully executed DELETE query. {deleted_rows} rows deleted.")
print(f"Inserting data for {WK_YM} into PostgreSQL table: {pg_table_name}")
# Spark SQL query to process data
insert_sql = f"""
select `사용일자` use_date
,`노선명` line_no
,`역명` station_name
,cast(`승차총승객수` as int) pass_in
,cast(`하차총승객수` as int) pass_out
,substring(`등록일자`,1,8) reg_date
from delta.`{delta_s3_path}`
where `사용일자` like '{WK_YM}'||'%'
"""
print(insert_sql)
delta_df = spark.sql(insert_sql)
delta_df.write \
.jdbc(url=pg_url,
table=pg_table_name,
mode="append",
properties=pg_properties)
print(f"Successfully wrote data to PostgreSQL table {pg_table_name}.")
print(f"--- Processing for {WK_YM} completed successfully! ---")
except Exception as e:
print(f"An error occurred during processing {WK_YM}: {e}")
import traceback
traceback.print_exc()
- Main execution block
# Main execution block
if __name__ == "__main__":
# Read environment variables from .env file in Pod
dotenv_path = './config/.env'
load_dotenv(dotenv_path=dotenv_path)
# APP configuration variables
APP_NAME = 'load_subway_passengers'
NOTEBOOK_NAME = "test"
NOTEBOOK_NAMESPACE = "demo01-kf"
S3_CONFIG = {
"access_key": os.getenv("S3_ACCESS_KEY"),
"secret_key": os.getenv("S3_SECRET_KEY"),
"endpoint": os.getenv("S3_ENDPOINT_URL"),
"bucket": os.getenv("S3_BUCKET_NAME"),
"delta_path": "deltalake/subway_passengers" # Delta target table path in S3 bucket
}
PG_CONFIG = {
"host": os.getenv("PG_HOST"),
"port": os.getenv("PG_PORT", "5432"), # Default value 5432
"dbname": os.getenv("PG_DB"),
"user": os.getenv("PG_USER"),
"password": os.getenv("PG_PASSWORD"),
"table": "subway_passengers" # PostgreSQL target table name
}
# Create SparkSession
spark = create_spark_session(
app_name=APP_NAME,
notebook_name=NOTEBOOK_NAME,
notebook_namespace=NOTEBOOK_NAMESPACE,
s3_access_key=S3_CONFIG['access_key'],
s3_secret_key=S3_CONFIG['secret_key'],
s3_endpoint=S3_CONFIG['endpoint']
)
# Execute data processing
subway_data_append(spark, S3_CONFIG, PG_CONFIG)
# Stop SparkSession
spark.stop()
print("Spark session stopped.")
load_subway_info.ipynb: Subway station information data transformation
- Import necessary libraries: Same as above
- Spark Session creation function: Common Library
- Function to save CSV to Delta and move S3 CSV file: Common Library
- Main data processing function: Overwrite since it's master information
def subway_info_overwrite(spark, s3_config, pg_config):
"""
Main pipeline processing CSV --> DELTA --> POSTGRESQL
"""
pg_url = f"jdbc:postgresql://{pg_config['host']}:{pg_config['port']}/{pg_config['dbname']}"
pg_properties = {
"user": pg_config['user'],
"password": pg_config['password'],
"driver": "org.postgresql.Driver"
}
print(f" bucket name is {s3_config['bucket']}")
csv_source_key = f"datasource/서울교통공사_노선별 지하철역 정보.csv"
csv_archive_key = f"archive/서울교통공사_노선별 지하철역 정보.csv"
csv_s3_path = f"s3a://{s3_config['bucket']}/{csv_source_key}"
delta_s3_path = f"s3a://{s3_config['bucket']}/{s3_config['delta_path']}"
try:
print(f"\n--- Starting processing for {pg_config['table']} ---")
# Step 1: Read S3 CSV
print(f"Reading CSV from {csv_s3_path}...")
csv_df = spark.read.option("header", "true").option("overwriteSchema", "true").csv(csv_s3_path)
csv_df.createOrReplaceTempView("subway_info")
csv_df.show(5)
print(f"CSV loaded. Count: {csv_df.count()}")
# Step 2: Save to Delta Lake (using Spark SQL)
csv_df.write.format("delta").mode("overwrite").save(delta_s3_path)
print(f"Successfully wrote data to Delta table {delta_s3_path}.")
# Step 3: Move S3 CSV file
print(f"Archiving S3 CSV file...")
move_s3_file(s3_config, csv_source_key, csv_archive_key)
# Step 4: Delete and insert to PostgreSQL
pg_table_name = pg_config['table']
print(f"Inserting data into PostgreSQL table: {pg_table_name}")
# Spark SQL query to process data
insert_sql = f"""
select `전철역명` station_name
,`전철역코드` station_cd
,`전철명명_영문` station_ename
,`전철명명_중문` station_cname
,`전철명명_일문` station_jname
,`외부코드` station_cd_external
, case when substring(`호선`,1,1) = '0' then substring(`호선`,2,length(`호선`)-1)
when `호선` = '공항철도' then '공항철도 1호선'
when `호선` = '수인분당선' then '수인선'
when `호선` = '신분당선' then '분당선'
when `호선` = '우이신설경전철' then '우이신설선'
else `호선` end line_no
from delta.`{delta_s3_path}`
"""
print(insert_sql)
delta_df = spark.sql(insert_sql)
delta_df.write \
.jdbc(url=pg_url,
table=pg_table_name,
mode="overwrite",
properties=pg_properties)
print(f"Successfully wrote data to PostgreSQL table {pg_table_name}.")
print("--- Processing completed successfully! ---")
except Exception as e:
print(f"An error occurred during processing: {e}")
import traceback
traceback.print_exc()
- Main execution block
# Main execution block
if __name__ == "__main__":
# Read environment variables from .env file in Pod
dotenv_path = './config/.env'
load_dotenv(dotenv_path=dotenv_path)
# APP configuration variables
APP_NAME = 'load_subway_info'
NOTEBOOK_NAME = "test"
NOTEBOOK_NAMESPACE = "demo01-kf"
S3_CONFIG = {
"access_key": os.getenv("S3_ACCESS_KEY"),
"secret_key": os.getenv("S3_SECRET_KEY"),
"endpoint": os.getenv("S3_ENDPOINT_URL"),
"bucket": os.getenv("S3_BUCKET_NAME"),
"delta_path": "deltalake/subway_info" # Delta target table path in S3 bucket
}
PG_CONFIG = {
"host": os.getenv("PG_HOST"),
"port": os.getenv("PG_PORT", "5432"), # Default value 5432
"dbname": os.getenv("PG_DB"),
"user": os.getenv("PG_USER"),
"password": os.getenv("PG_PASSWORD"),
"table": "subway_info" # PostgreSQL target table name
}
# Create SparkSession
spark = create_spark_session(
app_name=APP_NAME,
notebook_name=NOTEBOOK_NAME,
notebook_namespace=NOTEBOOK_NAMESPACE,
s3_access_key=S3_CONFIG['access_key'],
s3_secret_key=S3_CONFIG['secret_key'],
s3_endpoint=S3_CONFIG['endpoint']
)
# Execute data processing
subway_info_overwrite(spark, S3_CONFIG, PG_CONFIG)
# Stop SparkSession
spark.stop()
print("Spark session stopped.")
Key Cleansing Tasks:
- Column Name Standardization: Changed Korean labels to English columns when transferring from Delta to PostgreSQL to ensure system compatibility
- Data Consistency: Resolved inconsistencies between subway ridership data and subway station information data
- Station name standardization (handling spaces and special characters)
- Line name unification (consistent notation)
- Data Type Optimization: Appropriate data type conversion for numeric columns
Project Results and Implications
Key Analysis Results
1. Usage Patterns by Line
- Lines 2 and 9 show the highest usage rates
- Lines centered around Gangnam-gu recorded relatively high ridership
- Steady increase in usage rates for metropolitan lines such as Bundang Line and Gyeongui Line
2. Station-specific Usage Characteristics
- Major commercial hub stations like Gangnam, Hongik University, and Konkuk University stations recorded the highest usage rates
- Transfer stations showed 2-3 times higher ridership compared to single-line stations
- Confirmed stable usage patterns for stations near residential areas
3. Period-wise Trend Analysis
- Overall 10-15% increase in ridership over the past 3 years
- Temporary decrease in 2020-2021 due to COVID-19 impact followed by rapid recovery
- Seasonally higher ridership in spring and fall
4. Day-of-week Usage Characteristics
- Weekend (Saturday-Sunday) ridership decreased by about 25-30% compared to weekdays (Monday-Friday)
- Friday recorded the highest usage rate among weekdays, reflecting weekend leisure activity patterns
- Monday showed slightly lower usage rates compared to other weekdays
Business Insights
Transportation Policy Perspective
- Need for differentiated operational strategies considering usage rate gaps between lines
- Prioritization of infrastructure expansion centered on major transfer stations
- Exploration of flexible train scheduling reflecting day-of-week patterns
Commercial Area Analysis Perspective
- Evaluation of commercial potential using floating population data by station area
- Analysis of correlations between day-of-week usage patterns and sales by business type
- Objective indicators for new store location selection
Urban Planning Perspective
- Assessment of development potential in areas around high-usage lines
- Exploration of urban regeneration and revitalization plans for low-usage sections
- Data-based evidence for determining transportation infrastructure investment priorities
Technical Achievements
Platform Utilization Effects
- Rapid environment setup through DIP portal (80% time reduction compared to previous methods)
- Improved operational efficiency with Kubeflow-based automated pipelines
- Quick monitoring dashboard construction using Superset
Scalability Assurance
- Foundation for integrated analysis with other transportation data (bus, taxi, etc.)
- Expandable to real-time streaming data processing architecture
- Preparation for predictive analysis through machine learning model application
Future Development Directions
Short-term Plans
- Analysis of commuting patterns through hourly data acquisition
- Expansion of detailed station-wise analysis and strengthening regional characteristic analysis
- Addition of detailed seasonal and monthly trend analysis
Medium to Long-term Plans
- Correlation analysis with external factors such as weather and events
- Construction of ridership prediction system using AI/ML models
- Development of policy simulation and decision support systems
Conclusion
Through this project, we confirmed that subway usage data is an important indicator for understanding urban lifestyle patterns and economic activities beyond simple transportation information. By utilizing the integrated environment of the DIP portal, we were able to build an advanced data analysis system while minimizing technical complexity.
These analysis results ultimately provide meaningful data-based insights that can contribute to improving citizens' quality of life and creating a better urban environment.