
Building a Text Curation Pipeline with NeMo Curator
This guide uses NVIDIA NeMo Curator to build high-quality datasets for LLMs. It's a hands-on walk-through of a text curation pipeline—from cleaning and deduplication to language labeling—for preparing large-scale data quickly and reliably.

Table of Contents
- Introduction: Why Data Curation?
- What is NeMo Curator?
- NeMo Curator's Processing Flow
- Setting Up Your Environment
- Hands-on: Preprocessing 100 HTML Documents
- Results Analysis
- Introduction to Advanced NeMo Curator Features
- Conclusion
1. Introduction: Why Data Curation?
The performance of large language models (LLMs) depends just as much on data quality as it does on the model architecture. When training data contains a lot of unnecessary or redundant information, the model gets confused by noise instead of learning important patterns. This significantly degrades training performance, especially for tasks that require sophisticated reasoning, such as translation, QA, and generative AI.
Simply gathering a lot of data isn't enough. You need to sift out only the meaningful text for training, remove duplicates, and ensure a good balance of different languages and domains. NeMo Curator is the tool that supports this process in a systematic and scalable way. With GPU acceleration, Dask-based parallel processing, and a modular pipeline, it can quickly and reliably clean billions of documents.
In this post, we'll explore the core functions of NeMo Curator and use a practical text curation example with real test data to help you understand its basic usage and processing flow.
2. What is NeMo Curator?
NeMo Curator is an open-source data curation framework developed by NVIDIA. It automatically cleans, filters, deduplicates, and labels raw data, preparing it into a dataset suitable for LLM training.
Key Features
- Multimodal Support: It can process not only text but also images and videos, making it suitable for preparing data for multimodal model training.
- GPU-Accelerated Processing: Provides a 10-100x speedup compared to CPUs, thanks to its RAPIDS/cuDF backend.
- Large-Scale Distributed Processing: Utilizes Dask to parallelize the processing of hundreds of millions to billions of documents.
- MLOps Friendly: Integrates seamlessly with tools like Kubeflow, KServe, and Slurm, making it ideal for production environments.
- Flexible Modularity: Allows you to build your desired pipeline by combining standard operators (e.g., Modify, ScoreFilter, Sequential).
3. NeMo Curator's Processing Flow
The core of NeMo Curator lies in its modular processing stages, with each step supporting Dask-based distributed execution. Here is a typical pipeline flow for text data.
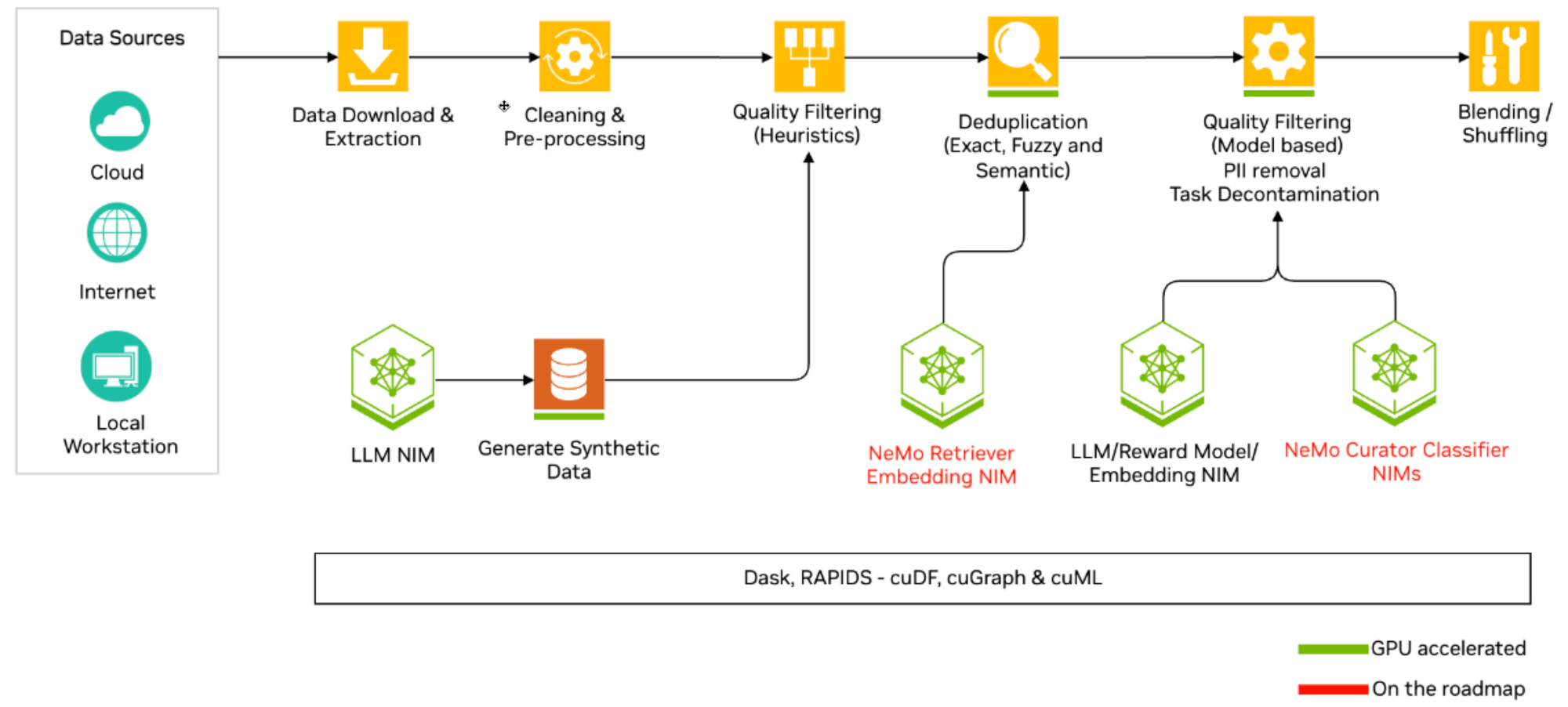
| Stage | Purpose |
|---|---|
| 1. Data Ingestion | Gathers raw text from various sources and converts it into the NeMo Curator format. |
| 2. Cleaning | Removes unnecessary noise like HTML tags, URLs, and special characters to standardize the text. |
| 3. Quality Filtering | Filters out low-quality data that can interfere with training, such as short or meaningless repetitive documents. |
| 4. Deduplication | Finds and removes identical or similar documents to prevent the model from learning repetitive information. |
| 5. Language Identification | Identifies the language of documents, providing a basis for training multilingual models. |
| 6. Special Handling | Separates or processes specific types of documents, such as code or synthetic data. |
| 7. Saving and Sharding | Divides and saves the final cleaned data in a format suitable for training. |
Each stage is defined by a standardized operator, and checkpointing allows for tracking and resuming from intermediate results.
4. Setting Up Your Environment
4.1 System Requirements
To use the text curation modules of NeMo Curator, you need to meet the following requirements:
Mandatory Requirements:
- OS: Ubuntu 22.04/20.04 (recommended)
- Python: 3.10 or 3.12 (Python 3.11 is not supported)
- Memory: 16GB+ RAM for basic text processing
Optional Requirements:
- GPU: NVIDIA GPU with 16GB+ VRAM (for GPU-accelerated tasks)
- Optional for most text modules
- Required for all image modules
- Provides a 10-100x speedup for processing
4.2 Installation Options
NeMo Curator supports three installation methods:
- PyPI: For quick installation and testing.
- Source Build: If you need the latest development version.
- Container: Ensures stable execution, ideal for production deployment.
# Download the container
docker pull nvcr.io/nvidia/nemo-curator:25.07
# Run in a CPU environment
docker run -it --rm nvcr.io/nvidia/nemo-curator:25.07
# Run the container with GPU support
docker run --gpus all -it --rm nvcr.io/nvidia/nemo-curator:25.07
# Custom installation inside the container (if needed)
pip uninstall nemo-curator
rm -r /opt/NeMo-Curator
git clone https://github.com/NVIDIA/NeMo-Curator.git /opt/NeMo-Curator
pip install --extra-index-url https://pypi.nvidia.com "/opt/NeMo-Curator[all]"
5. Hands-on: Preprocessing 100 HTML Documents
5.1 Test Data Generation Script
To clearly demonstrate the effect of each stage of the NeMo Curator pipeline, we've created a Python script that generates 100 HTML documents with specific characteristics. This script creates a total of 100 HTML files in the custom_data/html/ folder.
※ Script File Attached: create_data_sample.py
Data Characteristics:
- General Documents: Ordinary Korean/English text like weather reports, announcements, and recipes.
- Short Documents: Short sentences like "Confirmed," "Approved" (targets for quality filtering).
- Exact Duplicate Documents: Text identical to other documents (targets for deduplication).
- Code Documents: Content containing code from Python, SQL, JavaScript, etc. (targets for special handling).
- URL-Containing Documents: Documents with URLs in the body (targets for cleaning).
Key Script Parameters:
You can adjust the ratio of the generated data by modifying the script's main parameters.
TOTAL: Total number of documents to generate.SHORT_RATE: Ratio of short documents.EXACT_DUP_RATE: Ratio of exact duplicate documents.CODE_RATE: Ratio of code documents.EN_RATE: Ratio of English documents.URL_RATE: Ratio of URL-containing documents.
The data generated by this script will be used as input for the NeMo Curator pipeline, effectively showing how each stage works.
Example of a Generated HTML File:
<!DOCTYPE html>
<html><head>
<meta charset="UTF-8"><meta name="source_id" content="doc0001">
</head><body><div class="content">
프로젝트 현황 - 웹사이트 리뉴얼<br><br>프로젝트명: 웹사이트 리뉴얼<br>진행률: 75%<br>담당팀: 개발팀<br>마일스톤: 배포 완료<br>이슈사항: 일정 지연<br>다음 단계: 사용자 교육<br><br>참고링크: https://github.com/nvidia/NeMo-Curator
</div></body></html>
5.2 Loading Custom Data
To process local HTML files in NeMo Curator, we implement custom loaders (DocumentDownloader / DocumentIterator / DocumentExtractor):
from pathlib import Path
import hashlib
from bs4 import BeautifulSoup
from nemo_curator.download.doc_builder import (
DocumentDownloader, DocumentIterator, DocumentExtractor
)
# Create Custom Downloader:
class LocalFileDownloader(DocumentDownloader):
"""A downloader that reads files from the local file system."""
def download(self, url: str) -> str:
"""Returns the local file path as is."""
p = Path(url)
if not p.exists():
raise FileNotFoundError(f"{url} not found")
return str(p)
# Create Custom Iterator:
class HTMLFileIterator(DocumentIterator):
"""Iterates a single HTML file as one document."""
def iterate(self, file_path: str):
with open(file_path, "r", encoding="utf-8") as f:
html = f.read()
yield {"url": Path(file_path).as_posix()}, html # (metadata, content)
# Create Custom Extractor:
class SimpleHTMLExtractor(DocumentExtractor):
def extract(self, content: str):
"""Converts HTML to text and creates id/metadata."""
soup = BeautifulSoup(content, "html.parser")
text = soup.get_text(separator="\n").strip()
uid = hashlib.md5(text.encode("utf-8")).hexdigest()[:12]
return {
"text": text,
"id": uid,
"metadata": {"source_type": "local_html"},
}
Data Loading Execution Code:
from nemo_curator import get_client
from nemo_curator.download import download_and_extract
from dask import dataframe as dd
def load_custom_data():
# Initialize Dask client
client = get_client(cluster_type="cpu")
# Collect HTML files
root = Path("./custom_data/html")
exts = {".html"}
# Can extend to {".html", ".htm", ".md", ".txt"} etc. if needed
urls = [p.as_posix() for p in root.rglob("*")
if p.is_file() and p.suffix.lower() in exts]
if not urls:
raise SystemExit(f"No input files found under: {root}")
tmp_dir = Path("./.curator_cache")
output_paths = [str(tmp_dir / Path(u).stem) for u in urls]
# Download and extract documents
ds = download_and_extract(
urls=urls,
output_paths=output_paths,
downloader=LocalFileDownloader(),
iterator=HTMLFileIterator(),
extractor=SimpleHTMLExtractor(),
output_format={"text": str, "id": str, "metadata": object},
output_type="jsonl",
keep_raw_download=True,
force_download=False,
)
# Add a file_name column for per-file saving
names = [Path(u).stem for u in urls] # Input basenames
ds.df = ds.df.repartition(npartitions=len(urls))
ds.df = dd.concat([
ds.df.get_partition(i).assign(file_name=nm + ".jsonl")
for i, nm in enumerate(names)
])
# Save processed data
outdir = Path("./custom_data/processed")
outdir.mkdir(parents=True, exist_ok=True)
ds.to_json(output_path=str(outdir), write_to_filename=True, keep_filename_column=False)
if __name__ == "__main__":
load_custom_data()
5.3 Building the Text Curation Pipeline
Now, we'll combine the NeMo Curator modules to build the actual curation pipeline:
Load input data -> Cleaning -> Quality Filtering -> Deduplication -> Language Identification -> Separate Code Documents -> Final Save
Step 0: Pre-configuration
from nemo_curator import get_client, Sequential, Modify, ScoreFilter, ExactDuplicates
from nemo_curator.datasets import DocumentDataset
from nemo_curator.modifiers import UnicodeReformatter, NewlineNormalizer, UrlRemover
from nemo_curator.filters import (
WordCountFilter,
FastTextLangId,
NumberOfLinesOfCodeFilter,
AlphaFilter
)
from nemo_curator.utils.file_utils import get_all_files_paths_under
from dask import dataframe as dd
from pathlib import Path
import hashlib, re
import datetime
# ===== Settings =====
INPUT = "./custom_data/processed"
OUTDIR = Path("./custom_data/outputs/final")
MIN_WORDS = 8 # Minimum word count filter
SAVE_INTERMEDIATE = True # Whether to save intermediate results
# Generate a run tag (checkpoint folder name)
RUN_TAG = datetime.datetime.now().strftime("%Y%m%d-%H%M%S")
CKPT_ROOT = Path("./custom_data/outputs") / RUN_TAG
CKPT_ROOT.mkdir(parents=True, exist_ok=True)
def ckpt(ds, name):
"""Function to save intermediate results"""
if SAVE_INTERMEDIATE:
p = CKPT_ROOT / name
p.mkdir(parents=True, exist_ok=True)
ds.to_json(str(p))
print(f"Checkpoint saved: {p}")
# Initialize Dask client
client = get_client(cluster_type="cpu")
print("Dask client initialization complete")
Data Loading
# Step 0: Load input data
files = get_all_files_paths_under(INPUT, keep_extensions="jsonl")
files = [f for f in files if Path(f).stat().st_size > 0] # Exclude empty files
if not files:
raise SystemExit("No non-empty .jsonl files found under ./custom_data/processed")
ds = DocumentDataset.read_json(
files,
files_per_partition=1,
blocksize=None,
input_meta={"text": str, "id": str, "metadata": object, "url": str},
)
# Explicitly fix dtypes (for stability)
ds.df = ds.df.astype({
"text":"object",
"id":"object",
"metadata":"object",
"url":"object"
})
print(f"[Initial Load] {ds.df.shape[0].compute()} documents")
Step 1: Cleaning
Removes broken unicode, unnecessary spaces, URLs, etc., to standardize the text.
# Step 1: Cleaning
clean = Sequential([
Modify(UnicodeReformatter()), # Fix Unicode encoding issues
Modify(NewlineNormalizer()), # Standardize newlines
Modify(UrlRemover()), # Remove URLs
])
# Apply the cleaning pipeline
ds = clean(ds)
print(f"[After Cleaning] {ds.df.shape[0].compute()} documents")
def _tkey_series(s):
return s.fillna("").map(lambda t: hashlib.md5(t.encode("utf-8")).hexdigest()[:16],
meta=("tkey","object"))
# Generate a unique key based on text (for deduplication and tracking)
base = ds.df.assign(id=ds.df["id"].fillna(""), _tkey=_tkey_series(ds.df["text"]))
missing = (base["id"] == "")
ds.df = base.assign(id = base["id"].mask(missing, "auto_" + base["_tkey"])).persist()
# Repartition data (consolidate into 1 partition for small data)
ds.df = ds.df.repartition(npartitions=1).persist()
#ckpt(ds, "01_clean") # Save results
Step 2: Quality Filtering
Removes documents that are too short (fewer than 8 words).
# Step 2: Quality Filtering (Remove short documents)
ds = ScoreFilter(WordCountFilter(min_words=MIN_WORDS), text_field="text")(ds)
print(f"[After Quality Filter] {ds.df.shape[0].compute()} documents (min {MIN_WORDS} words)")
ds.df = ds.df.persist()
#ckpt(ds, "02_quality") # Save results
Step 3: Exact Deduplication
Removes duplicate data with identical content.
# Step 3: Exact Deduplication
dedup = ExactDuplicates(
text_field="text", # Remove rows with identical text content
perform_removal=True
)
ds = dedup(ds)
print(f"[After Deduplication] {ds.df.shape[0].compute()} documents")
ds.df = ds.df.persist()
#ckpt(ds, "03_dedup_exact") # Save results
Step 4: Language Identification
Identifies the language of the documents and adds labels like 'KO' or 'EN'.
Important: Before using this module, you must download the fastText language identification model file (
lid.176.bin) from the official fastText repository.
# Step 4: Language Identification
# Note: The lid.176.bin file must be in the current directory
if "text" not in set(ds.df.columns):
ds.df = ds.df.assign(text="")
else:
ds.df = ds.df.assign(text=ds.df["text"].fillna("").astype("object"))
ds.df = ds.df.persist()
ds.df = ds.df.assign(_lang_obj=None).persist()
# Write fastText scores/labels
ds = ScoreFilter(
FastTextLangId(model_path="./lid.176.bin", min_langid_score=0.0),
text_field="text",
score_field="_lang_obj", # Temporary column
score_type="object",
)(ds)
# Normalize temporary column to language code
def _to_lang_code(v):
def _norm(code):
if isinstance(code, str) and code.startswith("__label__"):
code = code.replace("__label__", "")
return code.upper() if isinstance(code, str) else "UNK"
if isinstance(v, (list, tuple)) and len(v) >= 2:
return _norm(v[1])
if isinstance(v, dict):
return _norm(v.get("language") or v.get("lang") or v.get("code"))
return "UNK"
ds.df = ds.df.assign(
language = ds.df["_lang_obj"].map_partitions(
lambda s: s.apply(_to_lang_code),
meta=("language", "object"),
)
).persist()
# Drop temporary column
def _drop_tmp(pdf):
if "_lang_obj" in pdf.columns:
return pdf.drop(columns=["_lang_obj"])
return pdf
meta = ds.df._meta
if "_lang_obj" in meta.columns:
meta = meta.drop(columns=["_lang_obj"])
ds.df = ds.df.map_partitions(_drop_tmp, meta=meta).persist()
#ckpt(ds, "04_lang_identification") # Save results
Step 5: Special Handling
Separates code from general text documents. We use NumberOfLinesOfCodeFilter and AlphaFilter to identify code.
# Step 5: Separate code documents and general text documents
# Identify code documents
code_filter = Sequential([
ScoreFilter(NumberOfLinesOfCodeFilter(min_lines=5, max_lines=2000),
text_field="text", score_field="line_count"),
ScoreFilter(AlphaFilter(min_alpha_ratio=0.2),
text_field="text", score_field="alpha_ratio"),
])
ds_code_only = code_filter(DocumentDataset(ds.df))
n_code = ds_code_only.df.shape[0].compute()
print(f"[Code Documents] {n_code} documents")
# Keep only non-code documents (anti-join)
code_keys = set(ds_code_only.df["_tkey"].compute())
non_code_mask = ds.df["_tkey"].map_partitions(lambda s: ~s.isin(code_keys),
meta=("_tkey","bool"))
ds_non_code = DocumentDataset(ds.df[non_code_mask]).persist()
ds_non_code.df = ds_non_code.df.reset_index(drop=True).persist()
print(f"[Non-Code Documents] {ds_non_code.df.shape[0].compute()} documents")
#ckpt(ds_code_only, "05_code_only") # Save if needed
#ckpt(ds_non_code, "05_non_code_only") # Save results
ds = ds_non_code
Final Result Saving
Saves the final data, which has gone through all pipeline stages, in jsonl format.
# Save final data
OUTDIR.mkdir(parents=True, exist_ok=True)
dd.to_json(
ds.df,
str(OUTDIR / "shard-*.jsonl"),
orient="records",
lines=True,
force_ascii=False,
)
print(f"[done] saved to {OUTDIR.resolve()}")
6. Results Analysis
In this hands-on session, we processed 100 test documents through the NeMo Curator pipeline and saw how data quality improved at each stage.
Stage-by-Stage Processing Results
The table below shows how the document count changed at each curation stage.
| Processing Stage | Document Count | Removed Document Type |
|---|---|---|
| Initial Load | 100 | - |
| After Cleaning | 100 | - (URL removal, text normalization) |
| After Quality Filter | 92 | Short documents (less than 8 words) |
| After Deduplication | 68 | Documents with identical text |
| After Language ID | 68 | - (Language labels added) |
| After Code Separation | 52 | Documents containing code blocks |
Quality Improvement Analysis
The results show that 48% of the unnecessary data (48 out of 100 raw documents) was removed. This directly contributes to higher training efficiency and improved model performance.
Removing Noise and Low-Quality Data
NeMo Curator uses quality filtering to weed out documents that are too short to provide meaningful information for training, like "Notice\nComplete #917." The cleaning stage also standardizes the text by removing noise like unnecessary URLs (https://...) embedded in the body.
- Example of a removed short document: Less than 8 words, not meaningful for LLM training.
{
"id":"add7ebc1d8e0",
"metadata":{"source_type":"local_html"},
"text":"Notice\nComplete #917",
"url":"custom_data\/html\/doc0083.html",
"_tkey":"add7ebc1d8e0f602"
}
Minimizing Redundant Data
24 documents with identical content were filtered out by the Exact Deduplication module. This prevents the inefficiency of the model repeatedly training on the same information.
- Example of a removed duplicate document: Already exists with the same text content.
{
"id":"0a978b18f514",
"metadata":{"source_type":"local_html"},
"text":"Weekly Report - {dept}\nDepartment: 개발팀\\nWeek of 2025-08-27\\n\\npage views increased by 18%.\\nTeam: 정민호\\nNext review: 2025-09-15\\nAction items: 문서 검토",
"url":"custom_data\/html\/doc0010.html",
"_tkey":"0a978b18f5141477"
}
Systematic Document Classification
Language identification automatically added a KO label to Korean documents and an EN label to English documents. This metadata is highly useful for training multilingual models or splitting datasets by language.
- Example of data after language labeling: The
languagefield is added.
{
"id":"8fc72a0702db",
"metadata":{"source_type":"local_html"},
"text":"서울 날씨 - {region}\n오늘(2025-08-04) 부산은 맑고 강한 바람입니다. 기온은 25도이며, 습도가 높게 예상됩니다.",
"url":"custom_data\/html\/doc0052.html",
"_tkey":"8fc72a0702db8f29",
"language":"KO"
}
Additionally, we accurately identified and separated documents containing code using NumberOfLinesOfCodeFilter and AlphaFilter. This separated code can be used for a dedicated code training dataset or excluded from general text training, allowing you to manage data quality according to your dataset's purpose.
- Example of a separated code document: Classified as a code document due to 5+ lines of code and an appropriate alphabet ratio.
{
"id":"aa006c3804ae",
"metadata":{"source_type":"local_html"},
"text":"Python Web Scraping\n```python\n# Web scraping utilities\nimport requests\nfrom bs4 import BeautifulSoup\nimport time\ndef scrape_data(url):\n # Set headers to avoid blocking\n headers = {'User-Agent': 'Mozilla\/5.0 (compatible)'}\n response = requests.get(url, headers=headers)\n if response.status_code == 200:\n # Parse HTML content\n soup = BeautifulSoup(response.content, 'html.parser')\n titles = soup.find_all('h1')\n return [title.text.strip() for title in titles]\n return []\ndef batch_scrape(urls):\n # Scrape multiple URLs with delay\n results = []\n for url in urls:\n data = scrape_data(url)\n results.extend(data)\n time.sleep(1) # Rate limiting\n return results\n```",
"url":"custom_data\/html\/doc0023.html",
"_tkey":"aa006c3804aee757",
"language":"EN",
"line_count":25,
"alpha_ratio":0.6430517711
}
7. Introduction to Advanced NeMo Curator Features
Beyond simple text cleaning, NeMo Curator offers enterprise-grade curation features for large-scale datasets. In this section, we'll briefly introduce some of its key advanced capabilities.
GPU-Accelerated Processing
NeMo Curator leverages RAPIDS cuDF to boost data processing speed by 10-100x compared to CPUs. This GPU acceleration allows for rapid parallel processing of billions of documents, drastically reducing the time required to prepare large LLM training datasets.
Fuzzy Deduplication
Instead of just removing documents with identical content, NeMo Curator uses techniques like MinHash to find and remove similar documents. This is especially useful for web-scraped data, where many documents might be redundant but have slight variations, preventing the model from repeatedly learning similar information.
PII Removal
It provides features to automatically detect and remove sensitive Personally Identifiable Information (PII) such as email addresses, phone numbers, and social security numbers. This is an essential function for ensuring data privacy and compliance.
Domain-Specific Quality Evaluation
In addition to general quality filters, NeMo Curator offers specialized quality evaluation modules for specific domains (e.g., medical, legal, technical). This allows you to select high-quality documents that are appropriate for a particular field, for example, by assessing the density of domain-specific terminology.
Checkpointing and Data Lineage
The framework supports a checkpointing feature that saves intermediate results at each stage, allowing you to resume work at any time. It also includes a data lineage feature that logs the history of all processing stages, ensuring transparency and making it easy to manage data provenance and processing steps for reproducibility and compliance.
8. Conclusion
NeMo Curator is more than just a data cleaning tool; it's an enterprise-grade data curation platform that offers the following value:
- Scalability and Performance: Its distributed architecture and GPU acceleration can handle billions of documents, enabling stable processing of large-scale tasks.
- Modularity and Flexibility: The plug-in filter system allows for domain-specific customization and easy integration into existing MLOps workflows.
- Quality and Reliability: Verified heuristics and ML-based filters ensure data quality and support traceable data lineage management.
Data is the raw material of AI, but unrefined raw material can be toxic. NeMo Curator is a powerful tool that systematically and scalably solves these data quality problems. The pipeline you experienced in this hands-on session is only a fraction of what NeMo Curator can do; its true value is realized in real production environments with billions of documents.
With NeMo Curator, we hope you can spend less time worrying about data quality for your AI projects and focus solely on innovating with models and algorithms.