
Evaluating LLMs with NeMo Evaluator: An End-to-End Guide from Standard Benchmarks to Custom Datasets
This guide shows how to use NVIDIA NeMo Evaluator in a PAASUP DIP environment. It covers the end-to-end process of evaluating LLMs connected via an NIM Proxy, using both standard benchmarks and custom data, from setup to result interpretation.
Table of Contents
- Introduction
- Prerequisites: Environment Setup and Configuration
- Standard Benchmark Evaluation (LM Evaluation Harness): GSM8K Example
- Custom Evaluation: Using Your Own Data
- Guide to Effective Evaluation
- Conclusion
1. Introduction
In the development of Large Language Models (LLMs), objective performance evaluation is a critical step. To compare performance before and after fine-tuning, benchmark different models, and validate a model before deployment, a systematic evaluation methodology is essential. It's not enough to rely on the subjective feeling that "the model seems to be working well." You must identify a model's strengths and weaknesses using quantifiable metrics.
NVIDIA NeMo Evaluator is a powerful tool designed to solve this problem. It connects to an OpenAI-compatible endpoint, allowing you to handle both standard and custom evaluations within a consistent workflow. This standardizes and automates repetitive, complex evaluation tasks.
This guide will walk you through the step-by-step process of systematically evaluating an LLM using NeMo Evaluator in a PAASUP DIP environment.
Core Value of NeMo Evaluator
- Standardized Evaluation Process: NeMo Evaluator standardizes the evaluation process with a
Config → Target → Jobstructure, ensuring a consistent procedure across teams and guaranteeing the reproducibility of experimental results. - Rich Built-in Benchmarks: Based on the LM Evaluation Harness, it provides immediate access to over 40 standard benchmarks, including GSM8K, MMLU, HellaSwag, and IFEval.
- Easy Model Integration: By designating an OpenAI-compatible endpoint (like NIM Proxy) as a Target, you can start evaluating a model instantly without any additional configuration.
- Production-Friendly: It offers job-level status management, API-based result retrieval, and easy integration into CI/CD pipelines.
NeMo Evaluator connects to OpenAI-compatible endpoints like NIM Proxy to run LM Evaluation Harness benchmarks and custom data evaluations in a consistent three-step process (Config → Target → Job). The results can be retrieved via API or downloaded as files, which is useful for managing reproducible experiments.
Understanding the Architecture
[Submit Evaluation job] POST /v1/evaluation/jobs
│
▼
[NeMo Evaluator API] ← Manages Eval Configs/Targets · Schedules runs
│
▼
[Model Inference Backend] ──► OpenAI-compatible /v1/chat/completions
│ └─ Endpoint/Prompt/Parameter for each model
└─ Gathers results · Generates report
▼
Retrieve results (API/Download)
Evaluation Workflow Summary
- (Optional) Upload custom dataset to the NeMo Data Store (NDS).
- Create an Evaluation Config in NeMo Evaluator (benchmark/parameters/tokenizer, etc.).
- Register the evaluation target Evaluation Target (model/endpoint).
- Submit the Evaluation Job → (a) Load data → (b) Run model inference → Aggregate results/generate report.
- Review the results.
Note This guide is a practical tutorial to understand the usage of NeMo Evaluator and the evaluation process, not a document for establishing official performance rankings. The scores shown are for workflow verification; for production use, you should conduct evaluations with a larger dataset and fixed settings.
2. Prerequisites: Environment Setup and Configuration
This tutorial assumes you have a NeMo Microservices environment deployed and accessible. In the PAASUP DIP environment, you can easily deploy NeMo Microservices by creating a catalog.
※ Note: A Hugging Face token may be required for some benchmarks or tokenizer usage.
2.1 DIP Environment Setup
[Step 1] Log in and Select a Project
- Objective: Access the environment with a pre-created project and manager account.
- Method: Log in with the manager account → Check the project list → Select the catalog creation menu.
[Step 2] Create a NeMo Catalog
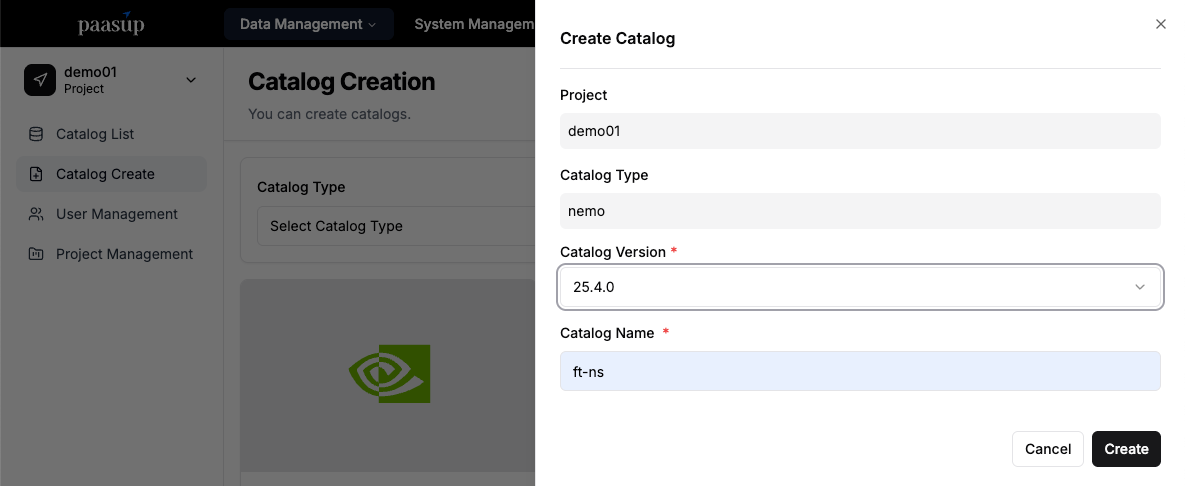
- Objective: Create a project-specific NeMo microservices namespace (NS) and prepare for NeMo integration.
- Method: Select the catalog creation menu → Choose
nemo→ Enter version and name → Click the create button. - A project-specific NS in the format
project-name-catalog-nameis created.- Example: Project Name:
demo01, Catalog Name:eval→ Namespace:demo01-eval.
- Example: Project Name:
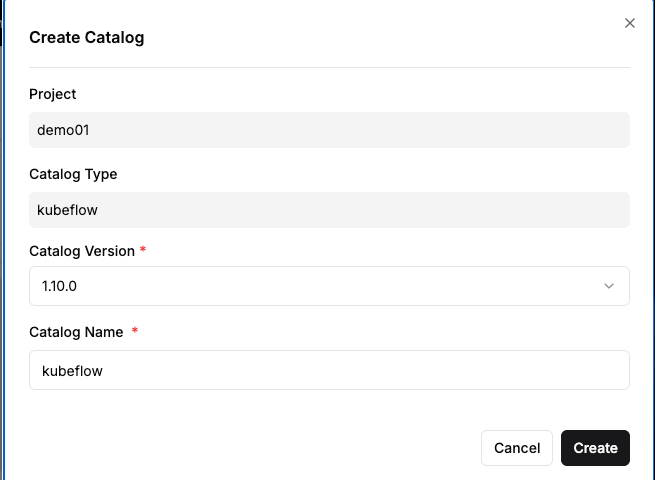
[Step 3] Create a Kubeflow Catalog
- Objective: Create a Kubeflow environment for running Jupyter Notebooks.
- Method: Select the catalog creation menu → Choose
Kubeflow→ Enter version and name → Click the create button.
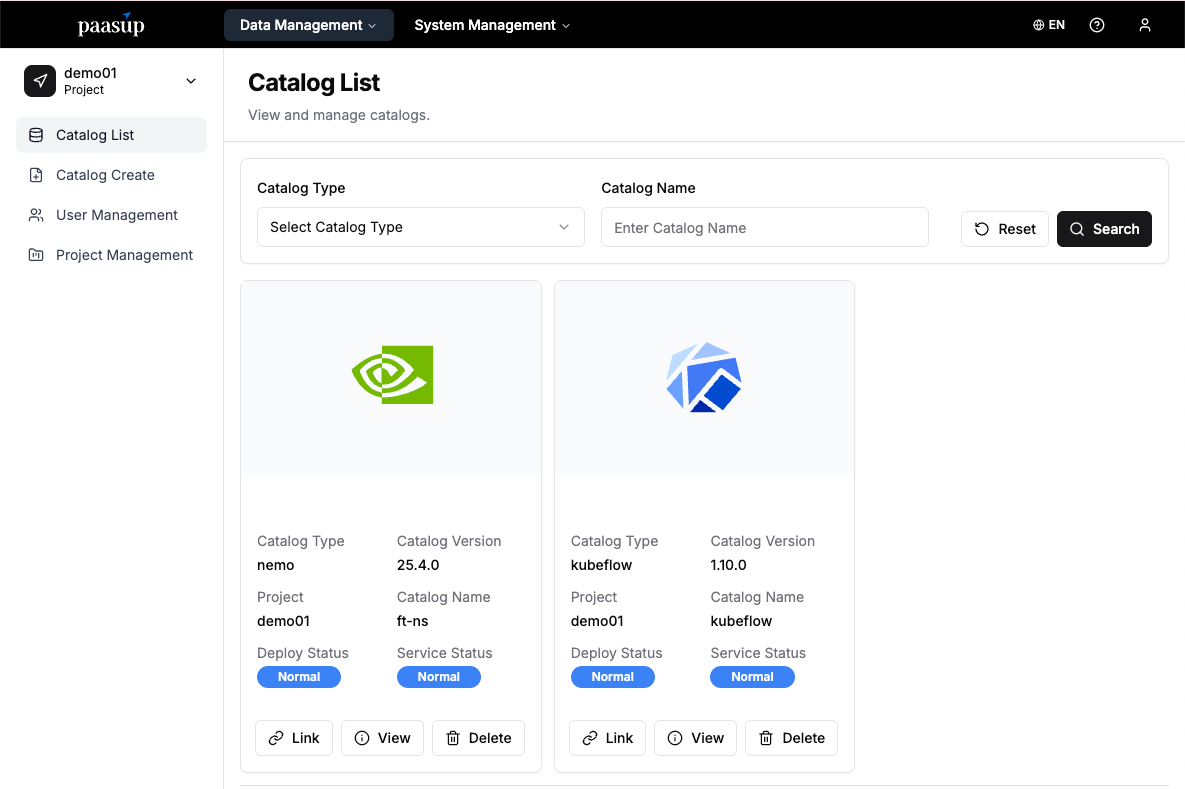
[Step 4] Check Catalog Status
- Objective: Monitor the deployment and service status of the created catalogs.
- Method: Check the catalog list page to monitor the status.
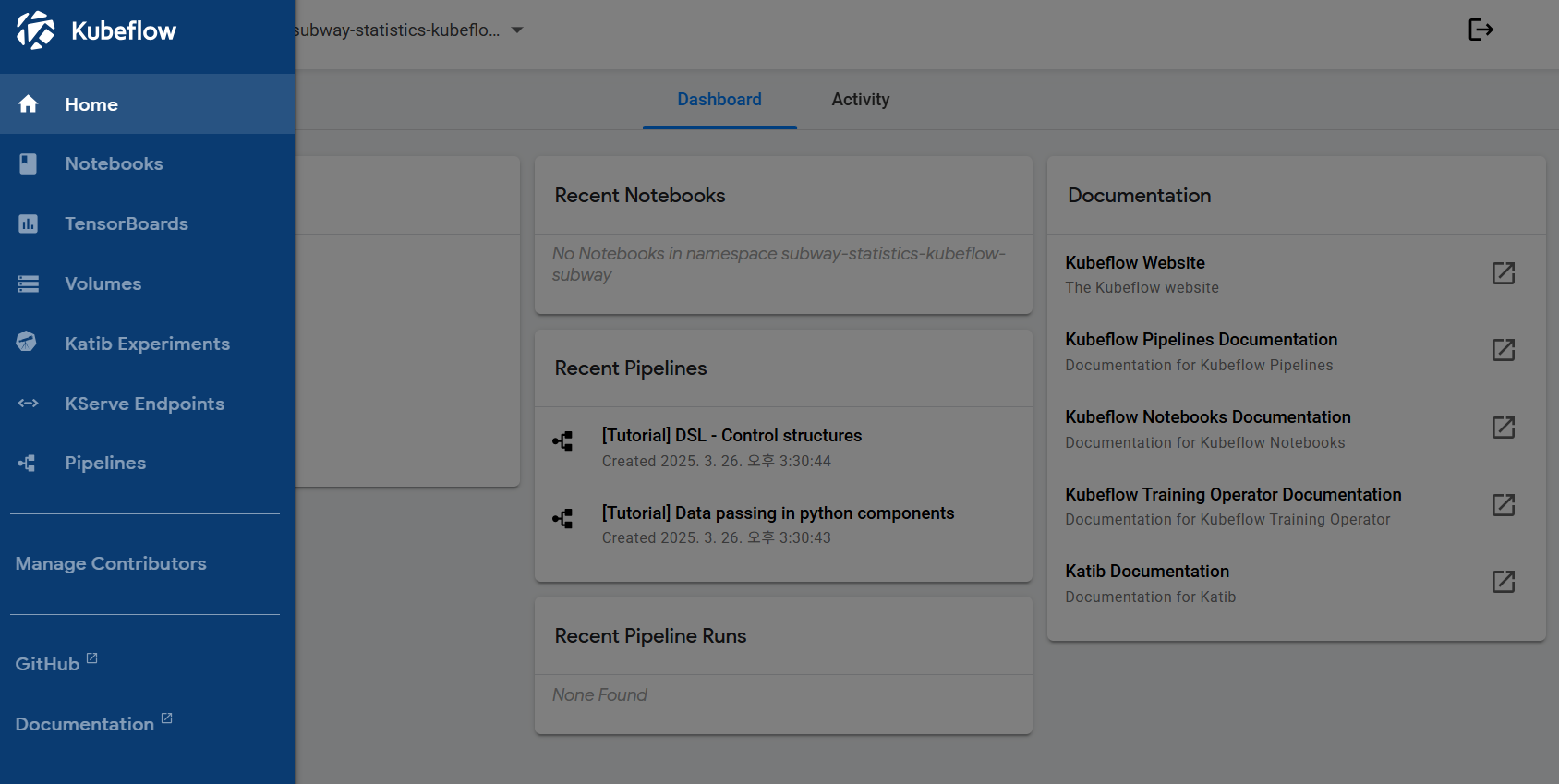
[Step 5] Create a Jupyter Notebook Environment
- Objective: Prepare the Python code execution environment.
- Method: Click the Kubeflow service link → Create a notebook instance.
[Step 6] Access the Development Environment
- Objective: Connect to the created Notebook to run code.
- Method: Click the Connect button → Access JupyterLab.
2.2 Environment Configuration
Install the necessary packages and set the endpoints and tokens as environment variables.
Install Required Packages:
!pip install -q huggingface_hub requests
Set Endpoints & Tokens (Environment Variables):
import os, json, requests
from pprint import pprint
# Set endpoints
NDS_URL = "[https://data-store-nemo.gke.paasup.io](https://data-store-nemo.gke.paasup.io)" # Data Store
NEMO_URL = "[https://nemo-nemo.gke.paasup.io](https://nemo-nemo.gke.paasup.io)" # Customizer, Entity Store, Evaluator, Guardrails
NIM_URL = "[https://nim-nemo.gke.paasup.io](https://nim-nemo.gke.paasup.io)" # NIM Proxy
NMS_NAMESPACE = "nemo-eval-tutorial"
# Set API keys
HF_TOKEN = "YOUR_HuggingFace_TOKEN" # Enter HuggingFace token
NVIDIA_API_KEY = "YOUR_NGC_API_KEY" # Enter NGC API key
# Configure API endpoints
target_url = f"{NEMO_URL}/v1/evaluation/targets"
config_url = f"{NEMO_URL}/v1/evaluation/configs"
job_url = f"{NEMO_URL}/v1/evaluation/jobs"
llm_chat_completion_url = f"{NIM_URL}/v1/chat/completions"
2.3 (Optional) NIM Deployment: Prepare the Model for Evaluation
If the NIM service for your model isn't deployed, you need to deploy it yourself. The following is an example of deploying the llama-3.2-3b-instruct model by calling the NeMo Deployment API.
※ Note: In PAASUP DIP, you can also easily deploy the target model by creating a NIM catalog.
url = f"{NEMO_URL}/v1/deployment/model-deployments"
payload = {
"name": "llama-3.2-3b-instruct",
"namespace": "meta",
"config": {
"model": "meta/llama-3.2-3b-instruct",
"nim_deployment": {
"image_name": "nvcr.io/nim/meta/llama-3.2-3b-instruct",
"image_tag": "1.10.1",
"pvc_size": "25Gi",
"gpu": 1,
"additional_envs": {
"NIM_GUIDED_DECODING_BACKEND": "outlines",
"NGC_API_KEY": NVIDIA_API_KEY,
},
"tolerations": [
{
"key": "[nvidia.com/gpu](https://nvidia.com/gpu)",
"operator": "Equal",
"value": "present",
"effect": "NoSchedule"
}
]
}
}
}
headers = {
"accept": "application/json",
"Content-Type": "application/json",
}
resp = requests.post(url, headers=headers, json=payload)
resp.raise_for_status()
print("Create deployment response:")
print(json.dumps(resp.json(), indent=2))
3. Standard Benchmark Evaluation (LM Evaluation Harness): GSM8K Example
NeMo Evaluator runs standard benchmarks like GSM8K, MMLU, and IFEval through the LM Evaluation Harness backend. Here, we'll use the GSM8K benchmark, which measures a model's math problem-solving ability, as an example.
3.1 Create an Evaluation Config
Create the evaluation configuration for the GSM8K benchmark.
payload = {
"type": "gsm8k",
"name": "gsm8k-chat-config",
"namespace": NMS_NAMESPACE,
"params": {
"temperature": 0.00001,
"top_p": 0.00001,
"max_tokens": 256,
"stop": ["<|eot|>"],
"extra": {
"num_fewshot": 8,
"batch_size": 16,
"bootstrap_iters": 100000,
"dataset_seed": 42,
"use_greedy": True,
"top_k": 1,
"hf_token": HF_TOKEN,
"tokenizer_backend": "hf",
"tokenizer": "meta-llama/llama-3.2-3B-Instruct",
"apply_chat_template": True,
"fewshot_as_multiturn": True
}
}
}
headers = {
"accept": "application/json",
"Content-Type": "application/json"
}
resp = requests.post(config_url, json=payload, headers=headers)
pprint(resp.json())
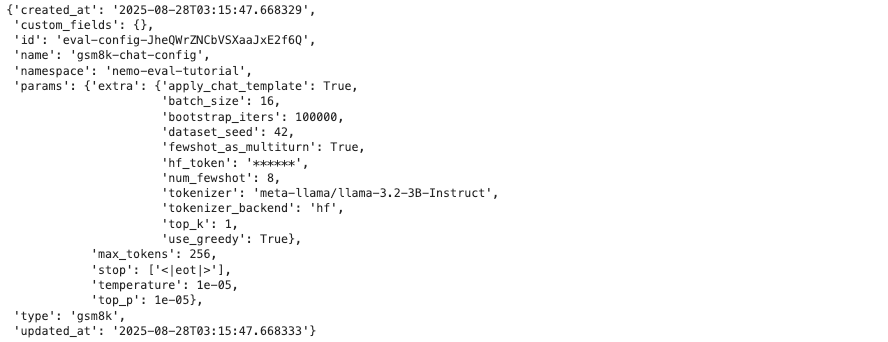
Key Parameter Descriptions:
-
num_fewshot: The number of example problems to provide to the model. -
apply_chat_template: Applies the appropriate template for chat-style models. -
use_greedy: Uses deterministic decoding (improves reproducibility).
3.2 Register an Evaluation Target
Register the endpoint of the model to be evaluated as a Target. The NIM Proxy provides the OpenAI-compatible /v1/chat/completions endpoint.
payload = {
"type": "model",
"name": "llama-chat-target",
"namespace": NMS_NAMESPACE,
"model": {
"api_endpoint": {
"url": llm_chat_completion_url ,
"model_id": "meta/llama-3.2-3b-instruct",
"format": "openai"
}
}
}
resp = requests.post(target_url, json=payload, headers=headers)
pprint(resp.json())
3.3 Execute the Evaluation Job
Now, let's start the actual evaluation.
# Create Job
payload = {
"namespace": NMS_NAMESPACE,
"target": f"{NMS_NAMESPACE}/llama-chat-target",
"config": f"{NMS_NAMESPACE}/gsm8k-chat-config"
}
resp = requests.post(job_url, json=payload, headers=headers)
gsm8k_eval_job_id = resp.json()["id"]
pprint(resp.json())
Confirming the Job ID:
print(gsm8k_eval_job_id)
3.4 Check the Results
After the job is complete, check the evaluation results.
# Check job status
resp = requests.get(f"{NEMO_URL}/v1/evaluation/jobs/{gsm8k_eval_job_id}/status")
pprint(resp.json())
# Retrieve results (after the job is complete)
resp = requests.get(f"{NEMO_URL}/v1/evaluation/jobs/{gsm8k_eval_job_id}/results")
pprint(resp.json()['tasks']['exact_match'])
pprint(resp.json()['tasks']['exact_match_stderr'])
Example Results:
{'metrics': {'exact_match': {'scores': {'gsm8k-metric_ranking-1': {'value': 0.7278241091736164},
'gsm8k-metric_ranking-3': {'value': 0.7573919636087946}}}}}
{'metrics': {'exact_match_stderr': {'scores': {'gsm8k-metric_ranking-2': {'value': 0.012259714035164541},
'gsm8k-metric_ranking-4': {'value': 0.011807426004596852}}}}}

Result Metric Descriptions:
-
exact_match: Represents the proportion of the model's responses that exactly match the ground truth. The value is between 0 and 1, where a value closer to 1 indicates higher model accuracy. This is a key performance indicator for benchmarks with clear, single correct answers, like GSM8K. -
exact_match_stderr: Refers to the bootstrap standard error. This indicates the statistical reliability of the evaluation score. A smaller value suggests that the evaluation score is more stable and the experiment is highly reproducible.
3.5 (Alternative) Using the NeMo Microservices SDK
You can perform the same evaluation more concisely using Python code with the NeMo Microservices SDK.
Initialize the NeMo Microservices SDK Client
!pip install nemo-microservices
from nemo_microservices import NeMoMicroservices
# Initialize NeMo Microservices SDK client
nemo_client = NeMoMicroservices(
base_url=NEMO_URL,
inference_base_url=NIM_URL,
)
Create Evaluation Config, Target, and Job
# Create Evaluation Config
print("Creating evaluation config...")
eval_config = nemo_client.evaluation.configs.create(
type="gsm8k",
name="gsm8k-chat-config",
namespace=NMS_NAMESPACE,
params={...} # Same as above
)
print("Config created:", eval_config)
# Create Evaluation Target
print("\nCreating evaluation target...")
eval_target = nemo_client.evaluation.targets.create(
type="model",
name="llama-chat-target",
namespace=NMS_NAMESPACE,
model={
"api_endpoint": {
"url": f"{NIM_URL}/v1/chat/completions",
"model_id": "meta/llama-3.2-3b-instruct",
"format": "openai"
}
}
)
print("Target created:", eval_target)
# Execute Evaluation Job
print("\nCreating and starting evaluation job...")
eval_job = nemo_client.evaluation.jobs.create(
config=f"{NMS_NAMESPACE}/gsm8k-chat-config",
target=f"{NMS_NAMESPACE}/llama-chat-target"
)
print("Evaluation job created:")
pprint(eval_job)
Check Job Status and Retrieve Results
# Check job status
job_id = eval_job.id
print(f"\nJob ID: {job_id}")
print(f"Status: {eval_job.status}")
# Check results (after the job is complete)
job = nemo_client.evaluation.jobs.retrieve(job_id)
print(f"Results: {job.status}")
4. Custom Evaluation: Using Your Own Data
In addition to standard benchmarks, you can evaluate models with data specialized for your specific use case. Here, we cover three types of custom evaluations.
4.1 Data Store Configuration
The Data Store provides a Hugging Face-compatible API (/v1/hf) that allows you to manage datasets consistently using the HF SDK, even in a local environment.
def setup_dataset_repo(hf_api, namespace, dataset_name, entity_host):
repo_id = f"{namespace}/{dataset_name}"
# Create the repo in datastore
hf_api.create_repo(repo_id, repo_type="dataset", exist_ok=True)
# Register dataset in entity store
entity_store_url = f"{entity_host}/v1/datasets"
payload = {
"name": dataset_name,
"namespace": namespace,
"files_url": f"hf://datasets/{repo_id}",
}
resp = requests.post(entity_store_url, json=payload)
assert resp.status_code in (200, 201, 409, 422), \
f"Unexpected response from Entity Store creating dataset: {resp.status_code}"
return repo_id
from huggingface_hub import HfApi
hf_api = HfApi(endpoint=f"{NDS_URL}/v1/hf", token="")
4.2 Similarity Metrics Evaluation
This evaluation measures the semantic similarity between the model's response and a reference answer. This guide uses data from inputs.jsonl.
Data Format (inputs.jsonl):
{
"prompt": "Generate a concise, engaging title for the following legal question...",
"ideal_response": "What constitutes \"doing business in a jurisdiction?\"",
"category": "summarization"
}
Important: You must configure the Config to match the data format you intend to use. In the example above, we used the prompt, ideal_response, and category fields.
# First, copy the data to the ./eval_data/similarity_metrics_data path for evaluation.
# set up dataset repo
DATASET_NAME = "similarity_eval"
repo_id = setup_dataset_repo(hf_api, NMS_NAMESPACE, DATASET_NAME, NEMO_URL)
# upload dataset
hf_api.upload_file(path_or_fileobj=os.path.join("./eval_data/similarity_metrics_data", "inputs.jsonl"),
path_in_repo="similarity_metrics/inputs.jsonl",
repo_id=repo_id,
repo_type='dataset',
)
# Create Evaluation Config
payload = {
"type": "similarity_metrics",
"name": "similarity-configuration",
"namespace": NMS_NAMESPACE,
"params": {
"max_tokens": 200,
"temperature": 0.7,
"extra": {
"top_k": 20
}
},
"tasks": {
"my-similarity-metrics-task": {
"type": "default",
"dataset": {
"files_url": f"hf://datasets/{NMS_NAMESPACE}/{DATASET_NAME}/similarity_metrics/inputs.jsonl",
},
"metrics": {
"accuracy": {"type": "accuracy"},
"bleu": {"type": "bleu"},
"rouge": {"type": "rouge"},
"em": {"type": "em"},
"f1": {"type": "f1"}
}
}
}
}
headers = {
"accept": "application/json",
"Content-Type": "application/json"
}
resp = requests.post(config_url, json=payload, headers=headers)
pprint(resp.json())
# Execute Evaluation Job (reusing the existing Target)
payload = {
"namespace": NMS_NAMESPACE,
"target": f"{NMS_NAMESPACE}/llama-chat-target",
"config": f"{NMS_NAMESPACE}/similarity-configuration"
}
resp = requests.post(job_url, json=payload, headers=headers)
similarity_eval_job_id = resp.json()["id"]
print(f"Similarity Evaluation Job ID: {similarity_eval_job_id}")
Example Results:
{'metrics': {'accuracy': {'scores': {'accuracy': {'value': 0.0}}},
'bleu': {'scores': {'bleu_score': {'value': 0.05173803611625177}}},
'em': {'scores': {'em': {'value': 0.0}}},
'f1': {'scores': {'f1': {'value': 0.12767470937400338}}},
'rouge': {'scores': {'rouge_1_score': {'value': 0.16589508703646286},
'rouge_2_score': {'value': 0.041384897021262586},
'rouge_3_score': {'value': 0.012798291518797661},
'rouge_L_score': {'value': 0.13521365193481227}}}}}
Result Metric Descriptions:
-
accuracy: Measures the proportion of the model's responses that are an exact string match to the ground truth. This score can be low for text generation models since they rarely produce a perfect, identical response. -
bleu_score: Measures the n-gram overlap between the model's response and the reference. It's primarily used for evaluating machine translation models, with values between 0 and 1. A higher score indicates greater similarity to the reference. -
em: Denotes the exact string matching rate. -
f1: Calculates the harmonic mean of precision and recall to determine how well the model's response contains the essential words from the ground truth. It's useful for evaluating the substantive completeness of the answer. -
rouge: A metric primarily used for evaluating text summarization performance. It measures how well the model's response includes the information from the reference. ROUGE-1 (unigram), ROUGE-2 (bigram), and ROUGE-L (longest common subsequence) measure similarity in different ways.
4.3 Tool Calling Evaluation
This evaluates whether the model's selection of a tool (function name/arguments) matches the specification. This guide uses data from aiva_tool_call.jsonl.
Data Format (aiva_tool_call.jsonl):
{
"messages": [
{
"role": "user",
"content": "Find the area of a triangle with a base of 10 units and height of 5 units."
}
],
"tools": [
{
"type": "function",
"function": {
"name": "calculate_triangle_area",
"description": "Calculate the area of a triangle given its base and height.",
"parameters": {
"type": "object",
"properties": {
"base": {"type": "integer", "description": "The base of the triangle."},
"height": {"type": "integer", "description": "The height of the triangle."}
},
"required": ["base", "height"]
}
}
}
],
"tool_calls": [
{
"function": {
"name": "calculate_triangle_area",
"arguments": {"base": 10, "height": 5, "unit": "units"}
}
}
]
}
Important: You must adjust the Config to match the structure of your Tool Calling data. For example, if you use different field names like user_query, available_functions, and expected_calls, you would need to change {{item.messages}} in the Config template to {{item.user_query}}, and so on.
config_payload = {
"type": "custom",
"namespace": NMS_NAMESPACE,
"name": "tool-call-eval-config",
"tasks": {
"custom-tool-calling": {
"type": "chat-completion",
"dataset": {
"files_url": f"hf://datasets/{NMS_NAMESPACE}/{DATASET_NAME}/aiva_tool_call.jsonl",
},
"params": {
"template": {
"messages": "{{ item.messages | tojson}}",
"tools": "{{ item.tools | tojson }}",
"tool_choice": "auto"
}
},
"metrics": {
"tool-calling-accuracy": {
"type": "tool-calling",
"params": {"tool_calls_ground_truth": "{{ item.tool_calls | tojson }}"}
}
}
}
}
}
headers = {
"accept": "application/json",
"Content-Type": "application/json"
}
resp = requests.post(config_url, json=config_payload, headers=headers)
pprint(resp.json())
Example Results:
{'tool-calling-accuracy': {'scores': {'function_name_accuracy': {'stats': {'count': 10,
'mean': 0.7,
'sum': 7.0},
'value': 0.7},
'function_name_and_args_accuracy': {'stats': {'count': 10,
'mean': 0.0,
'sum': 0.0},
'value': 0.0}}}}
Result Metric Descriptions:
-
function_name_accuracy: The proportion of times the model called the correct function name. This metric evaluates whether the model chose the appropriate tool based on the user's intent. -
function_name_and_args_accuracy: The proportion of times the model called the correct function name and accurately provided all required arguments. This metric evaluates whether the model fully understood the tool's usage and correctly extracted the necessary information.
4.4 LLM-as-a-Judge Evaluation
For evaluations where there are no multiple-choice answers, such as for quality and faithfulness, you can use another LLM as a "judge" to assess subjective quality. This guide uses data from math_dataset.csv.
Data Format (math_dataset.csv):
| id | question | answer | reference_answer |
|---|---|---|---|
| 0 | What is 4+8? | 12 | The answer is 12 |
| 1 | Square root of 144? | 12 | The answer is 12 |
Important: You must configure the Config to match the column names in your CSV. For example, if you use column names like query, expected_output, and ground_truth, you would change {{item.question}} to {{item.query}}, {{item.reference_answer}} to {{item.ground_truth}}, etc.
payload = {
"type": "custom",
"namespace": NMS_NAMESPACE,
"name": "custom_llm_as_judge_config",
"tasks": {
"qa": {
"type": "completion",
"params": {
"template": {
"messages": [{
"role": "system",
"content": "You are a helpful, respectful and honest assistant. \nAnswers the following question as briefly as you can.\n."
},
{
"role": "user",
"content": "Answer very briefly (no explanation) this question: {{item.question}}"
}]
}
},
"metrics": {
"accuracy": {
"type": "string-check",
"params": {
"check": [
"{{sample.output_text}}",
"contains",
"{{item.answer}}"
]
}
},
"bleu": {
"type": "bleu",
"params": {
"references": [
"{{item.reference_answer}}"
]
}
},
"accuracy-llm-judge": {
"type": "llm-judge",
"params": {
"model": {
"api_endpoint": {
"url": "[https://integrate.api.nvidia.com/v1/chat/completions](https://integrate.api.nvidia.com/v1/chat/completions)",
"model_id": "meta/llama-3.3-70b-instruct",
"api_key": NVIDIA_API_KEY
}
},
"template": {
"messages": [
{
"role": "system",
"content": "Your task is to evaluate the semantic similarity between two responses."
},
{
"role": "user",
"content": (
"Respond in the following format SIMILARITY: 4. "
"The similarity should be a score between 0 and 10.\n\n"
"RESPONSE 1: {{item.reference_answer}}\n\n"
"RESPONSE 2: {{sample.output_text}}.\n\n"
)
}
]
},
"scores": {
"similarity": {
"type": "int",
"parser": {
"type": "regex",
"pattern": "SIMILARITY: (\\d)"
}
}
}
}
}
},
"dataset": {
"files_url": f"hf://datasets/{NMS_NAMESPACE}/{DATASET_NAME}/llm_as_judge/math_dataset.csv"
}
}
}
}
headers = {
"accept": "application/json",
"Content-Type": "application/json"
}
resp = requests.post(config_url, json=payload, headers=headers)
pprint(resp.json())
Key Configuration Points:
-
{{item.question}}: Refers to the 'question' column in the CSV. -
{{item.answer}}: Refers to the 'answer' column in the CSV. -
{{item.reference_answer}}: Refers to the 'reference_answer' column in the CSV. -
{{sample.output_text}}: The actual response from the model. -
This example uses the
llama-3.3-70b-instructmodel hosted onbuild.nvidia.comas the judge model.
Example Results:
{'metrics': {'accuracy': {'scores': {'string-check': {'stats': {'count': 4,
'mean': 1.0,
'sum': 4.0},
'value': 1.0}}},
'accuracy-llm-judge': {'scores': {'similarity': {'stats': {'count': 4,
'mean': 1.0,
'sum': 4.0},
'value': 1.0}}},
'bleu': {'scores': {'corpus': {'value': 0.0},
'sentence': {'stats': {'count': 4,
'mean': 4.9787068367863965,
'sum': 19.914827347145586},
'value': 4.9787068367863965}}}}}
Result Metric Descriptions:
-
string-check: A simple True/False evaluation that checks if the model's response contains a specific string. -
similarity: The score given by the judge model (LLM-as-a-Judge) for the semantic similarity between the target model's response and the ground truth. This is a powerful metric for objectively quantifying subjective quality. -
bleu: A metric that can also be used in LLM-as-a-Judge evaluations to check how similarly the generated text is expressed compared to the reference.
5. Guide to Effective Evaluation
5.1 Choose Benchmarks that Match Your Evaluation Goal
-
Verifying Foundational Capabilities: To check a new model's overall performance, start with MMLU (multi-discipline knowledge) and HellaSwag (commonsense reasoning). If mathematical reasoning is crucial, use the GSM8K and MATH benchmarks.
-
Verifying Specific Use Cases: For coding assistant development, use HumanEval, MBPP. For building safe services, use TruthfulQA, RealToxicityPrompts. For command-following ability, use IFEval.
5.2 Data Quality Management
-
Using Standard Benchmarks: Maintain consistent evaluation conditions to enable comparison with other research results. It is important to consistently manage hyperparameters such as the number of few-shot examples and temperature values.
-
Preparing Custom Data: Create data that reflects real-world scenarios, select unbiased and balanced samples, and ensure the accuracy and consistency of ground truth labels.
5.3 Interpreting and Leveraging Results
-
Statistical Reliability: Run evaluations multiple times to confirm stability and report the standard error to indicate the uncertainty of the results.
-
Comparative Analysis: Measure performance differences from a baseline model, track performance changes before and after fine-tuning, and compare the strengths and weaknesses of different models.
5.4 Considerations for Practical Application
-
Match the Evaluation Environment: Perform evaluations under the same conditions as the actual service environment and monitor response time and resource usage.
-
Continuous Monitoring: Run regular evaluations every time the model is updated to detect issues like performance degradation or increased bias early on.
6. Conclusion
You have now completed an end-to-end walkthrough of evaluating an LLM with NeMo Evaluator. You have experienced the powerful capabilities it offers, from standard benchmarks to custom data and advanced evaluation techniques like LLM-as-a-Judge.
This guide goes beyond simple tool usage to emphasize the importance of building a systematic LLM evaluation methodology. Model development doesn't end with a single fine-tuning run. Continuous performance monitoring and multi-faceted evaluation are essential to unlock a model's full potential.
The PAASUP DIP environment is the optimal platform to easily deploy NeMo Microservices and follow all the practical steps in this guide. You can now use NeMo Evaluator to quantify your model's performance and add reliability to your development process. Build better LLM solutions through systematic evaluation and take your AI projects to the next level.