
Understanding StarRocks Architecture
StarRocks is an analytical database with a simple FE/BE architecture offering two modes: Shared-nothing (local storage, high performance) and Shared-data (object storage, cost-efficient). It provides excellent MPP performance and seamless horizontal scaling without external dependencies.
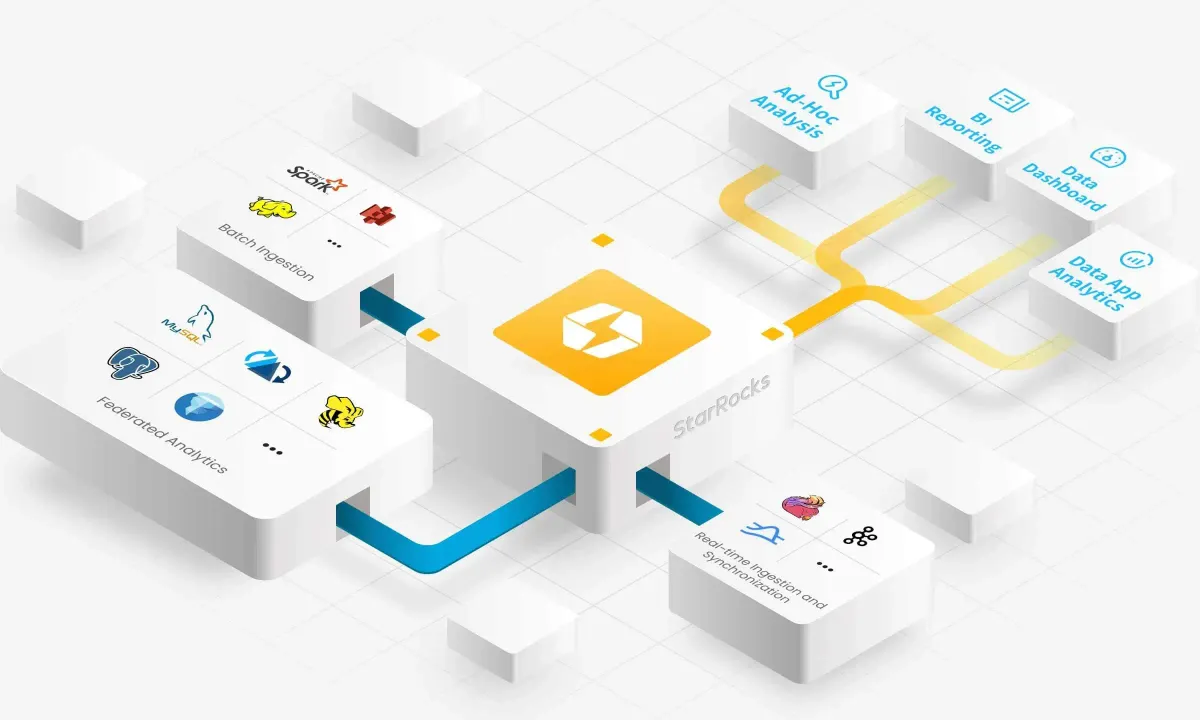
1. Introduction to StarRocks
Why StarRocks?
StarRocks has been gaining attention in the data analytics market recently. What's the reason behind this?
StarRocks is an analytical database that pursues both simplicity and performance simultaneously. It delivers exceptional performance without complex external dependencies and enables horizontal scaling without operational downtime, which are its most distinctive features.
Core Features and Advantages
🎯 Simple Architecture
- Composed of only two types of components: FE(Frontend) + BE(Backend)/CN(Compute Nodes)
- Independent system with no external component dependencies
⚡ Exceptional Performance
- Large-scale data processing with MPP (Massively Parallel Processing) architecture
- Optimized query performance through direct local data access
🔧 Flexible Scalability
- Horizontal scaling without operational downtime
- Support for two deployment modes based on environment
2. Basic Architecture Structure
StarRocks' architecture is surprisingly simple. It consists of only three types of components.
FE (Frontend) - The Brain
Main Roles:
- 📊 Metadata Management: Store and manage metadata in memory using BDB JE
- 🔗 Client Connection: Receive and process user requests
- 📋 Query Planning: Analyze SQL and generate execution plans
- ⚖️ Scheduling: Distribute tasks to BE/CN nodes
High Availability Structure:
- Leader: Performs actual metadata modification operations
- Follower: Synchronized with Leader, can replace Leader in case of failure
- Observer: Read-only for query load balancing
FE nodes use the Raft protocol to elect leaders and synchronize data.
BE/CN - The Actual Workers
BE (Backend) - Shared-nothing Mode
- 💾 Data Storage: Store data in local storage
- ⚙️ SQL Execution: Execute actual queries based on FE's plans
- 🔄 Data Replication: Ensure high availability through MPP structure
CN (Compute Nodes) - Shared-data Mode
- 🧮 Computation Only: Perform computations without data storage
- 📦 Cache Management: Cache frequently used data locally
- 🚀 Fast Scaling: Very fast addition/removal due to stateless nature
3. Complete Comparison: Shared-nothing vs Shared-data
One of StarRocks' biggest features is the ability to choose the optimal architecture based on the environment.
Shared-nothing: The Power of Local Storage
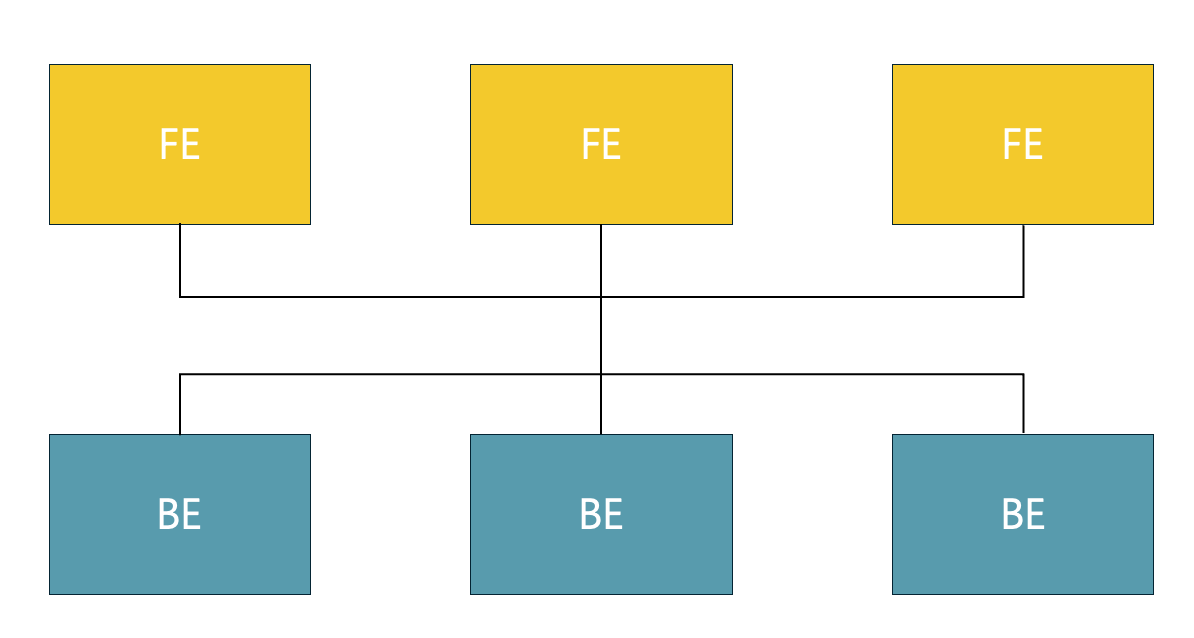
Structure:
- BE nodes store data in local storage
- Each node directly processes queries independently
Advantages:
- ⚡ Ultra-fast Queries: Maximum performance through direct local data access
- 🛡️ Stability: Data replication and high availability through MPP structure
- 🎯 Real-time Processing: Optimized for low-latency query processing
Suitable Situations:
- When real-time dashboards or OLAP queries are critical
- Environments requiring minimal network latency
- Predictable workload patterns
Shared-data: Cloud-Native Flexibility
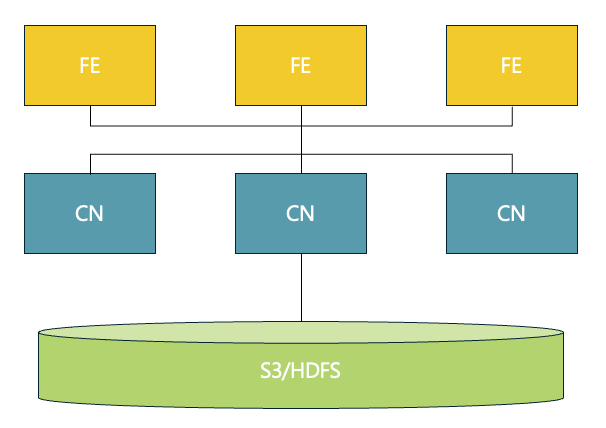
Structure:
- Uses object storage (AWS S3, GCS, Azure Blob, MinIO, etc.) or HDFS as storage
- CN nodes handle only caching and computation
Core Technology - Multi-tier Cache System:
Memory Cache → Local Disk Cache → Remote Object Storage
↑ ↑ ↑
Hot data Warm data Cold data
- Hot data: Direct access from memory (maximum performance)
- Warm data: Access from local disk cache (fast performance)
- Cold data: Load from object storage then cache (progressive performance improvement)
Advantages:
- 💰 Cost Reduction: Utilize inexpensive object storage
- 🔄 Resource Isolation: Independent scaling of computing and storage
- 🚀 Fast Scaling: Very fast CN node addition/removal
- ☁️ Cloud-friendly: Optimized for cloud-native environments
Suitable Situations:
- When cost efficiency is important in cloud environments
- Environments with unpredictable workloads
- When storage and computing need to be scaled independently
When to Choose Which Mode?
| Comparison Item | Shared-nothing | Shared-data |
|---|---|---|
| Performance | ⭐⭐⭐⭐⭐ (Maximum) | ⭐⭐⭐⭐ (Excellent when cache hits) |
| Cost | ⭐⭐⭐ (Medium) | ⭐⭐⭐⭐⭐ (Very Low) |
| Scalability | ⭐⭐⭐ (Data redistribution required) | ⭐⭐⭐⭐⭐ (Instant scaling) |
| Operational Complexity | ⭐⭐⭐⭐ (Simple) | ⭐⭐⭐ (Cache management required) |
| Cloud Friendliness | ⭐⭐⭐ (Average) | ⭐⭐⭐⭐⭐ (Optimal) |
Selection Guide:
Choose Shared-nothing when:
- 🎯 Real-time dashboards or low-latency queries are core requirements
- 📊 Predictable workload patterns
- 🏢 On-premises environments or dedicated infrastructure
Choose Shared-data when:
- ☁️ Cost efficiency is important in cloud environments
- 📈 Workloads are rapidly changing or unpredictable
- 🔄 Storage and computing need to be scaled independently
Conclusion
StarRocks' architecture demonstrates power within simplicity. Through two deployment modes, it provides optimal solutions for various environments and requirements.
In the next Part 2, we'll learn step-by-step how to actually deploy StarRocks in a Kubernetes environment. Connect theory to practice and experience the true value of StarRocks!