
PAASUP DIP로 구축하는 엔터프라이즈 LLM 서빙 가이드: vllm #1
PAASUP DIP 플랫폼에서 vLLM 백엔드 기반으로 KServe를 활용해 엔터프라이즈 LLM 서빙 환경을 구축하고, OpenWebUI와 Flowise를 통해 프로그래밍부터 노코드 웹 인터페이스까지 다양한 AI 서비스 운영법을 제시하는 실전 가이드입니다.
목차
- 개요
- 테스트 환경 준비: Kubeflow Jupyter Notebook 배포
- KServe 배포하기
- 엔드포인트 확인 및 설정
- Jupyter Notebook을 통한 추론 테스트
- OpenWebUI를 통한 웹 인터페이스 구축
- Flowise를 활용한 노코드 AI 워크플로우
- 마무리
1. 개요
엔터프라이즈 환경에서 LLM 서비스를 안정적으로 운영하려면 복잡한 Kubernetes 설정, MLOps 파이프라인 구축, 다양한 인터페이스 개발 등 많은 기술적 과제를 해결해야 합니다.
PAASUP DIP(Data Intelligence Platform)는 이러한 복잡성을 해결하여 클릭 몇 번만으로 프로덕션 수준의 AI/ML 워크플로우를 구축할 수 있게 해주는 데이터 인텔리전스 플랫폼입니다.
이 글에서는 DIP로 KServe 기반 LLM 서빙 환경을 구축하고, 이를 다양한 인터페이스에서 활용하는 방법을 알아보겠습니다:
구성 요소
- KServe: Kubernetes 네이티브 모델 서빙 플랫폼으로 안정적인 LLM 배포
- Jupyter Notebook: Python 코드를 이용한 API 호출 및 테스트 환경
- OpenWebUI: ChatGPT 스타일의 사용자 친화적인 웹 채팅 인터페이스
- Flowise: 드래그 앤 드롭 방식의 노코드 AI 워크플로우 구성 도구
핵심 장점
OpenAI 호환 API: KServe가 제공하는 OpenAI 호환 엔드포인트 덕분에 기존 OpenAI SDK와 다양한 도구를 수정 없이 그대로 활용할 수 있습니다.
2. 테스트 환경 준비: Kubeflow Jupyter Notebook 배포
KServe로 배포한 모델의 동작을 검증하기 위해 먼저 API 호출 환경을 준비하겠습니다. DIP의 Kubeflow 카탈로그를 활용하면 복잡한 설정 없이 Jupyter Notebook 환경을 손쉽게 구성할 수 있습니다.
2.1 Jupyter Notebook 환경 생성
Step 1: DIP 접속 및 프로젝트 선택
- PAASUP DIP에 매니저 계정으로 로그인
- 프로젝트 리스트에서 대상 프로젝트 선택
- 카탈로그 생성 메뉴로 이동
Step 2: Kubeflow 카탈로그 생성
- 카탈로그 생성 메뉴에서 Kubeflow 선택
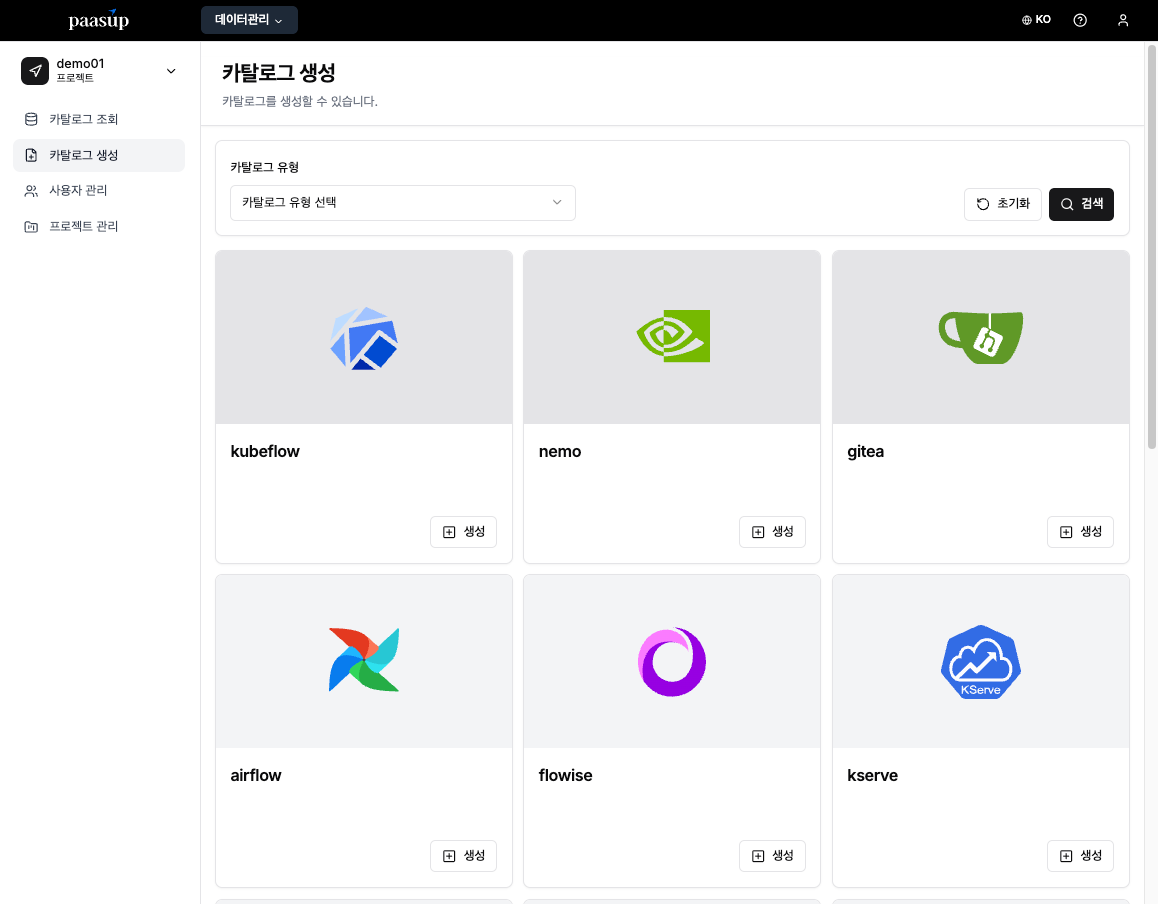
- 카탈로그 버전과 구분 가능한 이름 입력
- 생성 버튼 클릭
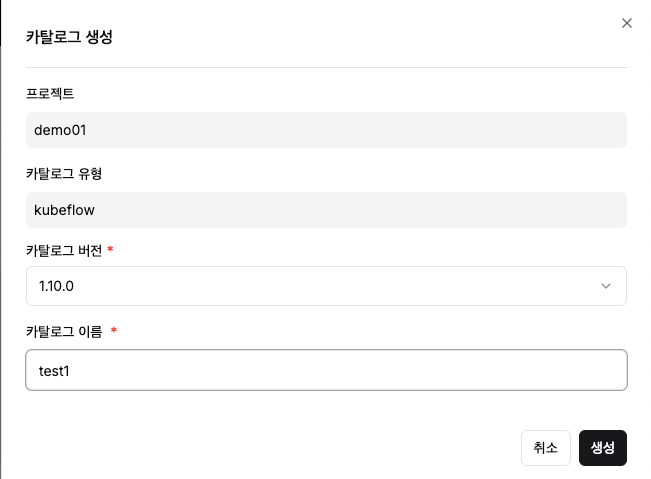
Step 3: 카탈로그 상태 확인
- 카탈로그 조회 화면에서 배포가 완료될 때까지 상태 모니터링
- 배포 상태/서비스 상태가 정상으로 변경될 때까지 대기
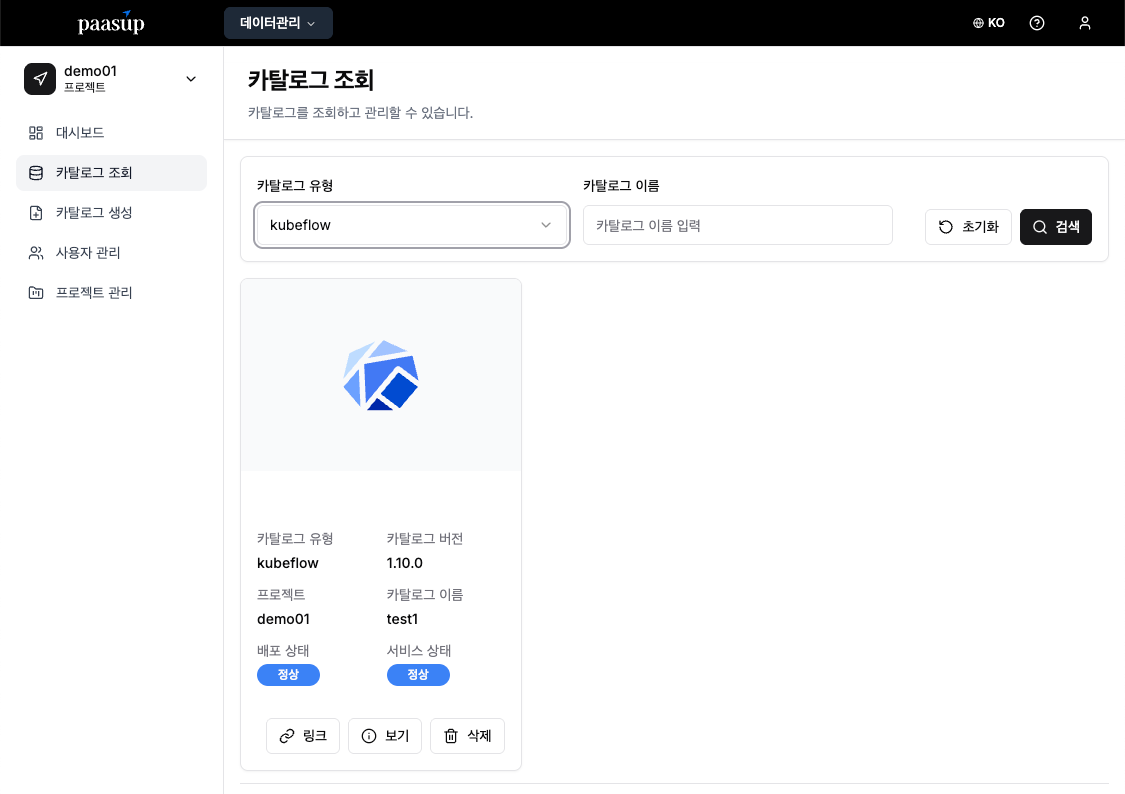
Step 4: Jupyter Notebook 인스턴스 생성
- 배포 완료된 Kubeflow 서비스 링크를 클릭하여 대시보드 접속
- Notebooks 메뉴에서 새로운 노트북 인스턴스 생성
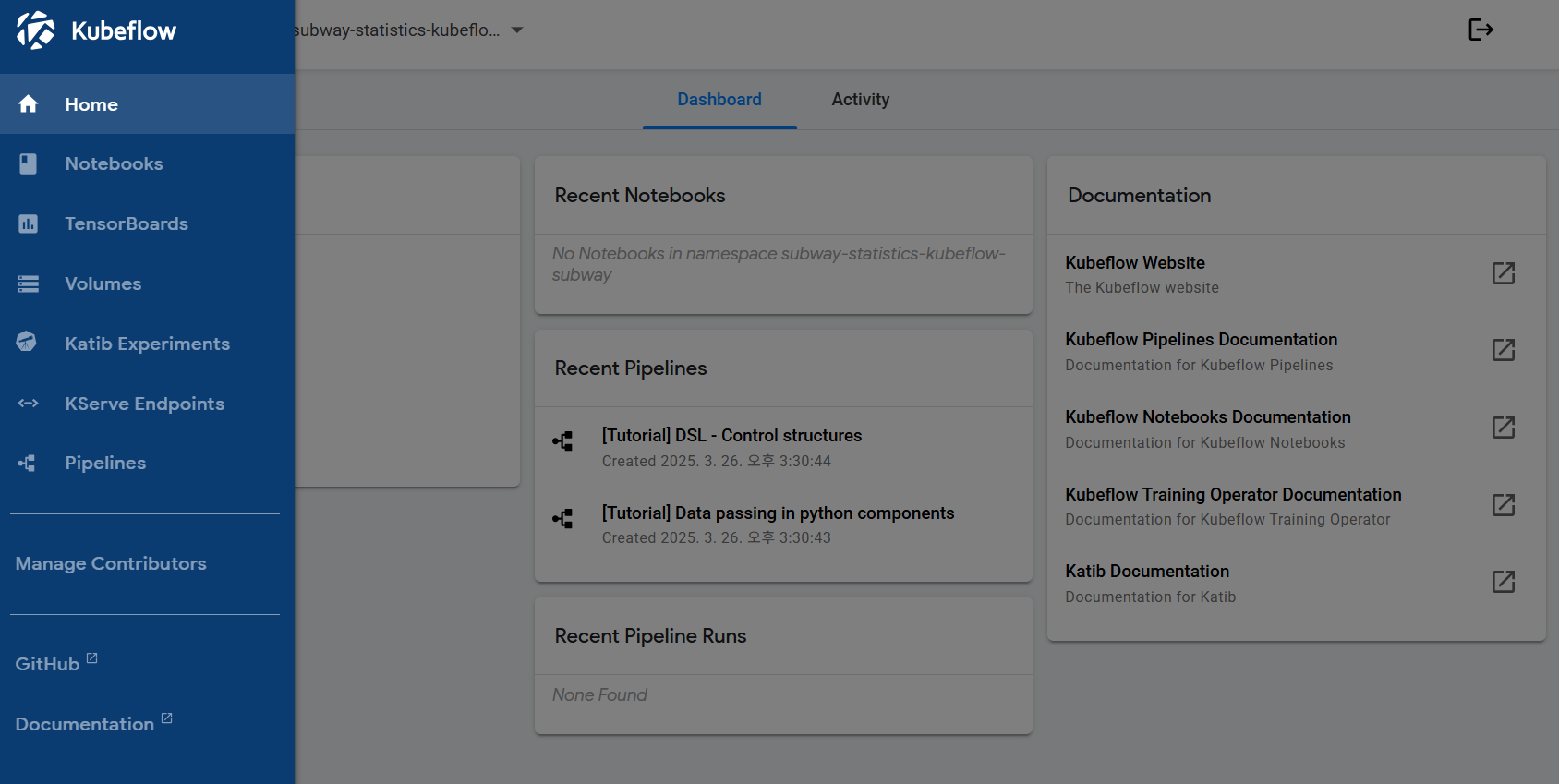
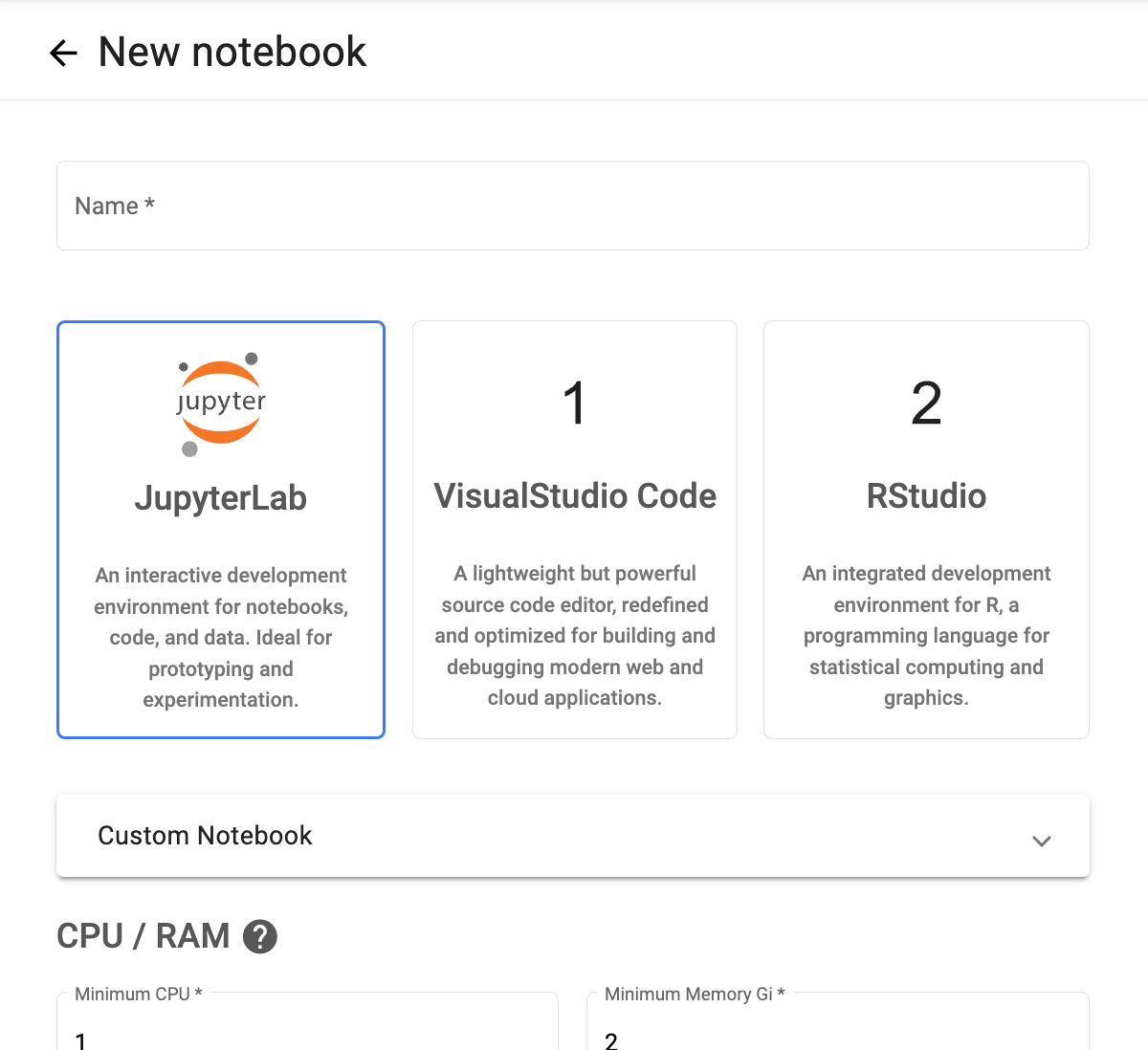
- 생성 완료 후 Connect 버튼으로 Jupyter Notebook 접속 준비 완료
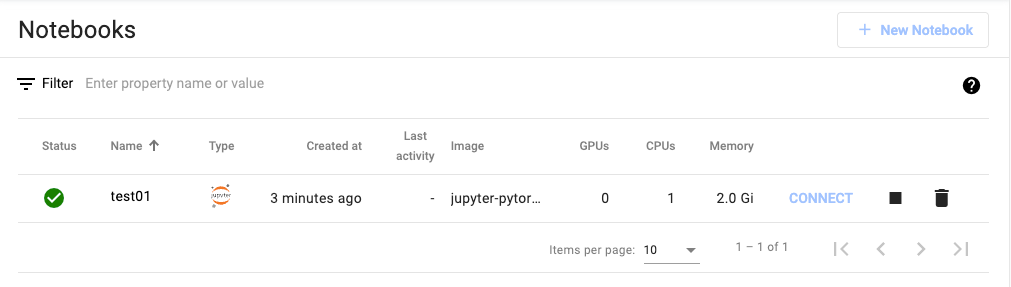
※ 참고: 이 Notebook은 KServe 배포 완료 후 API 테스트에 활용됩니다.
3. KServe 배포하기
3.1 KServe 아키텍처 개요
KServe는 Kubernetes 네이티브 모델 서빙 플랫폼으로, 다양한 추론 백엔드를 지원합니다. PAASUP DIP에서는 LLM 서빙을 위해 vLLM을 기본 백엔드로 사용합니다.
vLLM 백엔드의 장점:
- 메모리 효율성: PagedAttention 기술로 메모리 사용량 최적화
- 높은 처리량: 동적 배치 처리로 다중 요청을 효율적 처리
- OpenAI 호환성: 표준 OpenAI API 형식으로 일관된 인터페이스 제공
3.2 KServe 카탈로그 생성
Step 1: 카탈로그 선택
- 카탈로그 생성 메뉴에서 KServe 카탈로그 선택
- '생성' 버튼 클릭
Step 2: 기본 정보 입력
- 카탈로그 버전: 버전 선택
- 카탈로그 이름: 구분 가능한 이름 입력 (예:
llama32-serving)
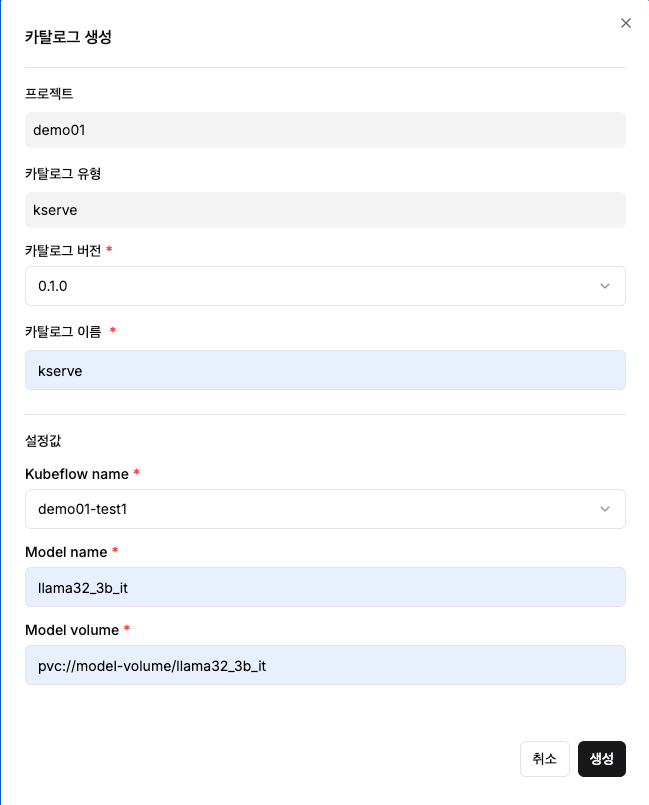
Step 3: 모델 서빙 설정
다음 필수 설정값들을 입력합니다:
- Kubeflow name: 앞에서 생성한 Kubeflow 선택
- Model name: 서빙할 모델명 지정 (예:
llama32_3b_it)- 이 값은 나중에 API 호출 시
model파라미터로 사용됩니다
- 이 값은 나중에 API 호출 시
- Model volume: 모델 저장된 볼륨 경로 지정 (예:
pvc://model-volume/llama32_3b_it)- 해당 경로에 모델 파일들이 사전에 업로드되어 있어야 합니다
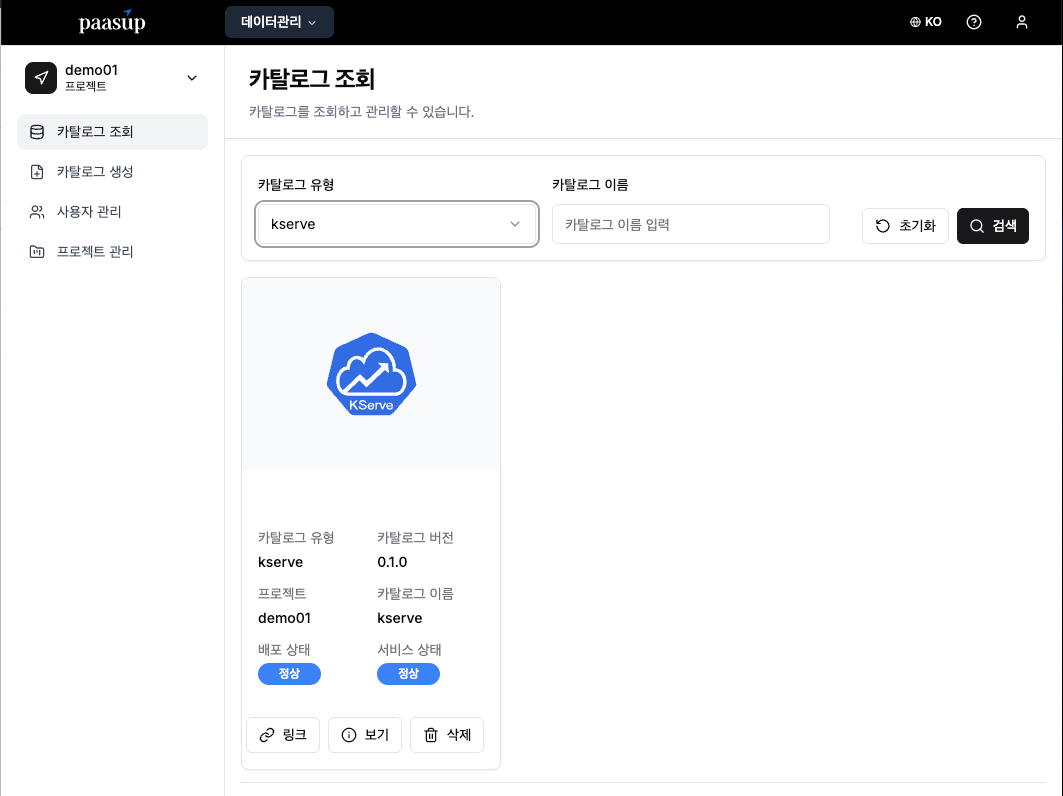
3.3 배포 상태 확인
카탈로그 생성 후 배포 진행상황을 모니터링합니다.
- 카탈로그 목록에서 생성한 KServe 카탈로그 확인
- 배포 상태/서비스 상태가 정상으로 변경될 때까지 대기
4. 엔드포인트 확인 및 설정
KServe 배포 완료 후 DIP는 클러스터 외부 접근용 URL(External URL)과 클러스터 내부 접근용 URL(Cluster-local URL) 두 가지 접근 방식을 제공합니다.
4.1 KServe 엔드포인트 정보 확인
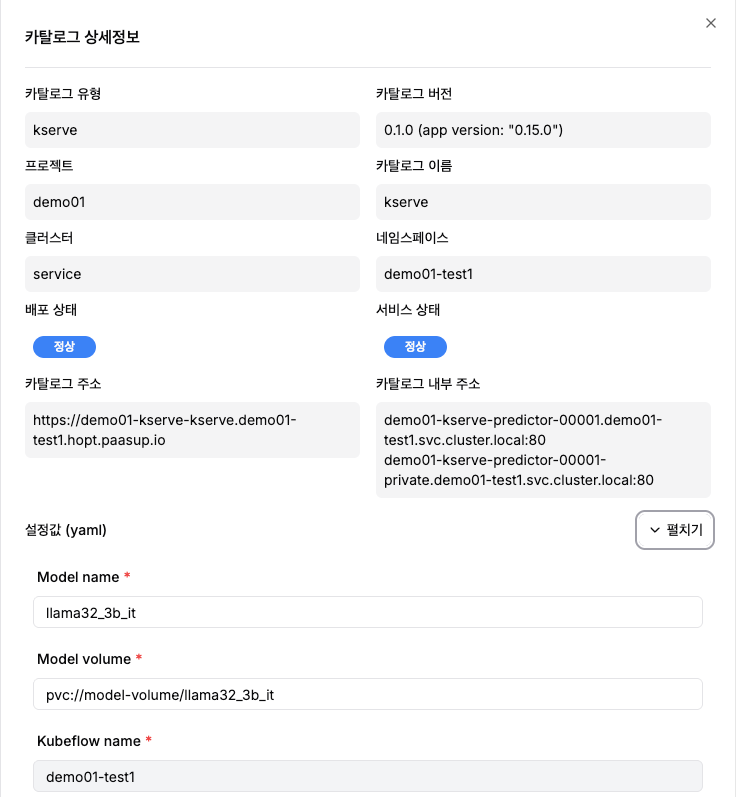
방법 1: DIP 카탈로그 상세정보에서 확인
- KServe 카탈로그 상세 페이지 접속
- 카탈로그 주소 또는 카탈로그 내부 주소 확인
- 예시 URL:
- 클러스터 외부 접근용:
https://demo01-kserve-kserve.demo01-test1.hopt.paasup.io - 클러스터 내부 접근용:
http://demo01-kserve-predictor-00001.demo01-test1.svc.cluster.local:80
- 클러스터 외부 접근용:
- 예시 URL:
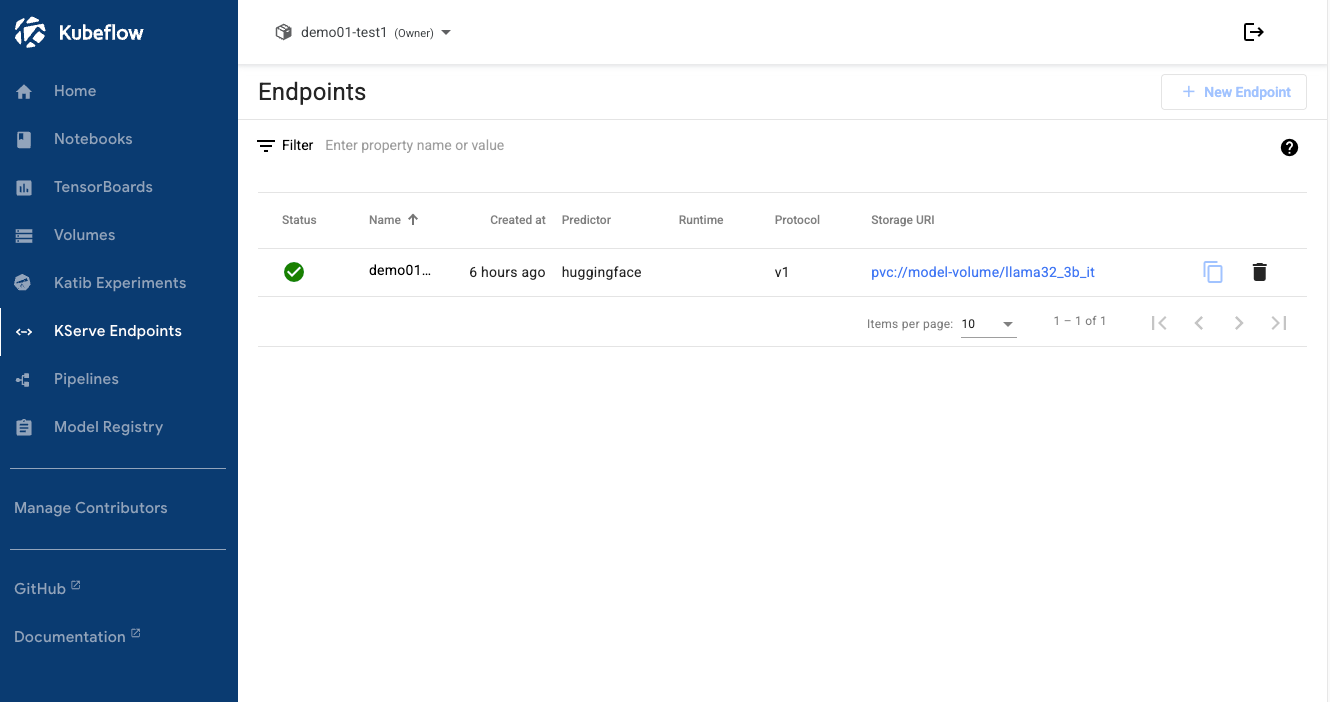
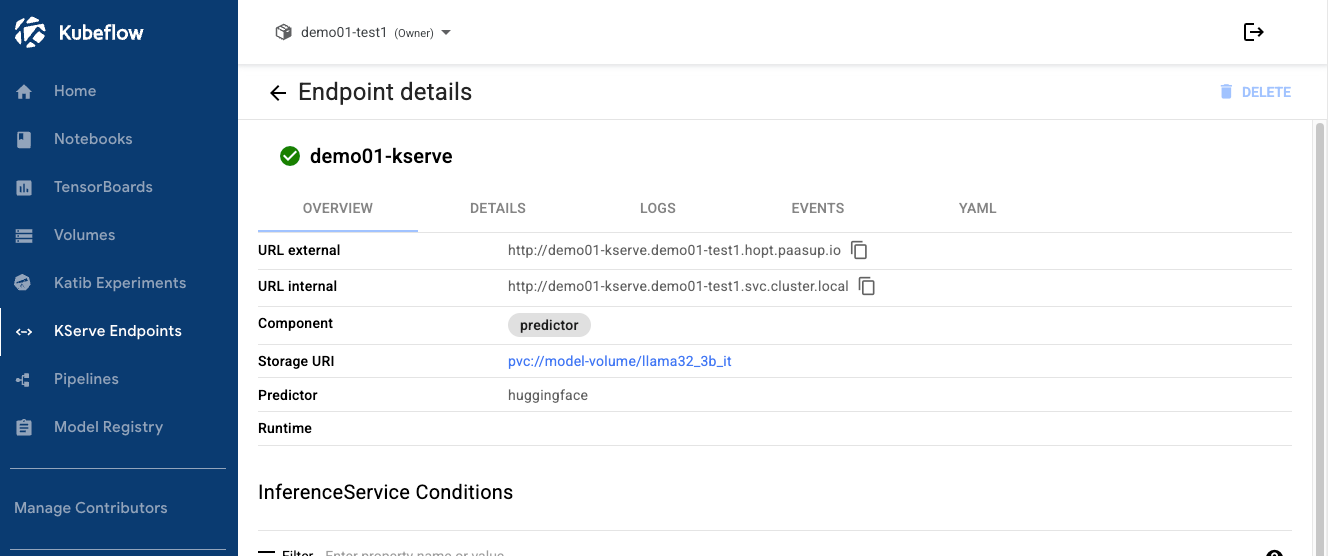
방법 2: Kubeflow Dashboard에서 확인
- Kubeflow Dashboard → KServe 메뉴
- 배포된 모델의 URL internal 확인
- 클러스터 내부 접근용:
http://demo01-kserve.demo01-test1.svc.cluster.local
- 클러스터 내부 접근용:
※ 참고:모든 엔드포인트는 동일한 OpenAI 호환 API(/openai/v1)를 제공하므로, 네트워크 환경이나 프록시 설정에 따라 접근 가능한 URL을 선택하면 됩니다.5. Jupyter Notebook을 통한 추론 테스트
5.1 JupyterLab 접속
- 앞에서 생성한 Jupyter Notebook 인스턴스의 Connect 버튼 클릭
- JupyterLab 환경 접속 후 새 Python 노트북 생성
- 필요한 라이브러리 설치:
!pip install openai
5.2 OpenAI 호환 API를 통한 추론 테스트
KServe의 가장 큰 장점 중 하나는 OpenAI API와 호환되는 엔드포인트를 제공한다는 점입니다. 덕분에 openai 라이브러리와 같이 널리 사용되는 클라이언트 코드를 수정 없이 그대로 활용할 수 있습니다.
- 예시 코드
from openai import OpenAI
# KServe 엔드포인트 설정
# 클러스터 외부 접근 시 (HTTPS):
# base_url="https://demo01-kserve-kserve.demo01-test1.hopt.paasup.io/openai/v1"
# 클러스터 내부 접근 시:
base_url = "http://demo01-kserve-predictor-00001.demo01-test1.svc.cluster.local:80/openai/v1"
client = OpenAI(
base_url = base_url,
api_key = "dummy-key" # 인증이 비활성화된 환경에서는 임의 값 사용
)
# LLM에 전달할 메시지 구성
messages = [
{"role": "system", "content": "Please answer concisely and clearly."},
{"role": "user", "content": "지름이 10인 원의 넓이를 π를 사용하여 나타내면?"}
]
# 응답 생성
completion = client.chat.completions.create(
model="llama32_3b_it", # Model name
messages=messages,
temperature=0.5,
top_p=1,
max_tokens=1024,
stream=True # 실시간으로 응답을 받아오기 위해 스트리밍 활성화
)
# 응답 출력
for chunk in completion:
if chunk.choices[0].delta.content is not None:
print(chunk.choices[0].delta.content, end="")

6. OpenWebUI를 통한 웹 인터페이스 구축
OpenWebUI는 ChatGPT와 유사한 UX(대화형 UI)를 제공하는 오픈소스 웹 인터페이스로, 비개발자도 쉽게 LLM을 사용할 수 있게 해줍니다.
6.1 OpenWebUI 카탈로그 배포
Step 1: OpenWebUI 카탈로그 생성
- 카탈로그 생성 메뉴 → OpenWebUI 선택
- 버전 및 이름 입력 후 생성
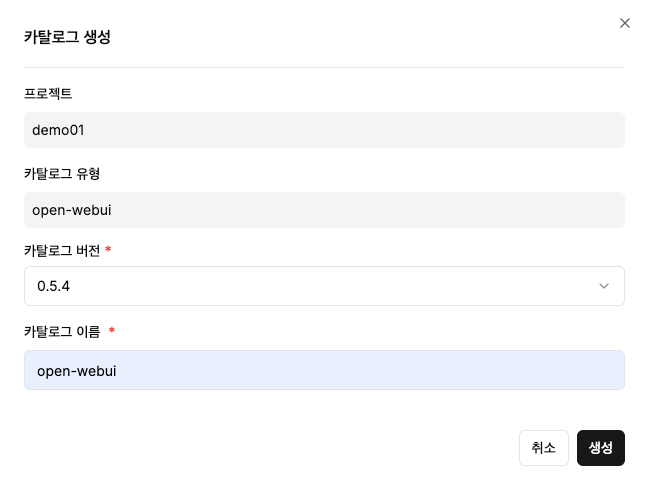
Step 2: 배포 완료 확인
- 카탈로그 배포 상태/서비스 상태가 정상으로 변경될 때까지 대기
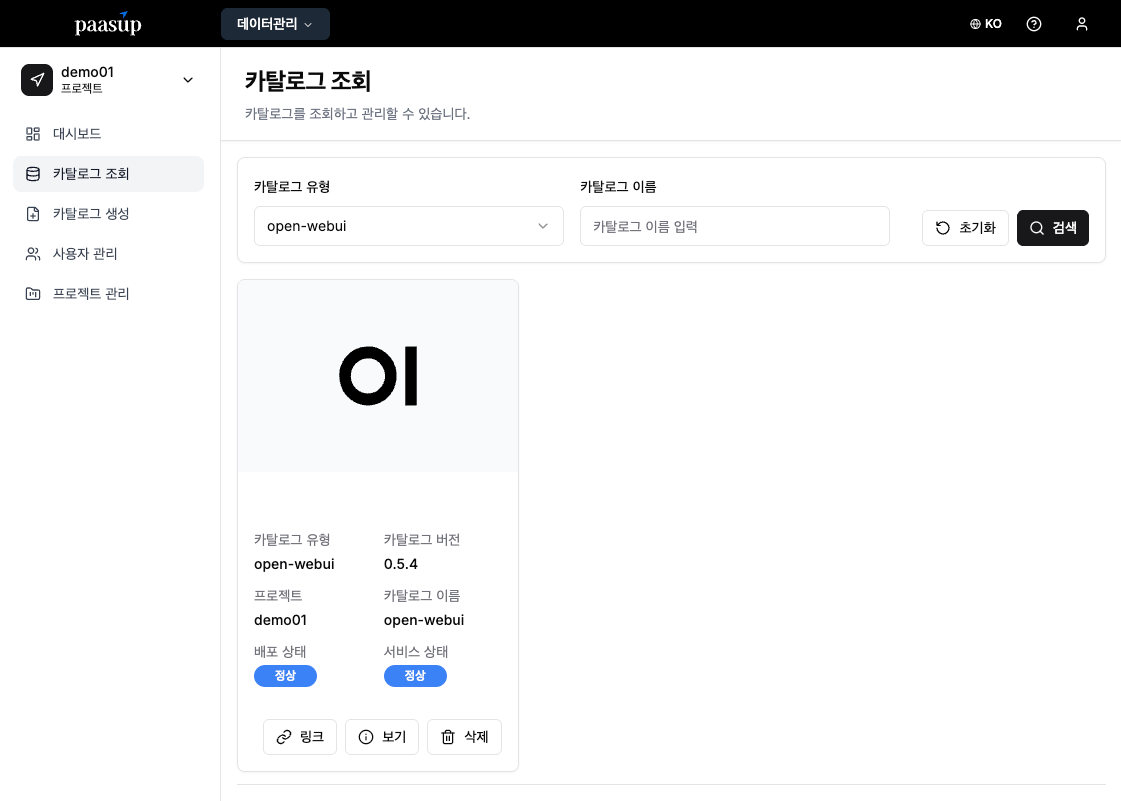
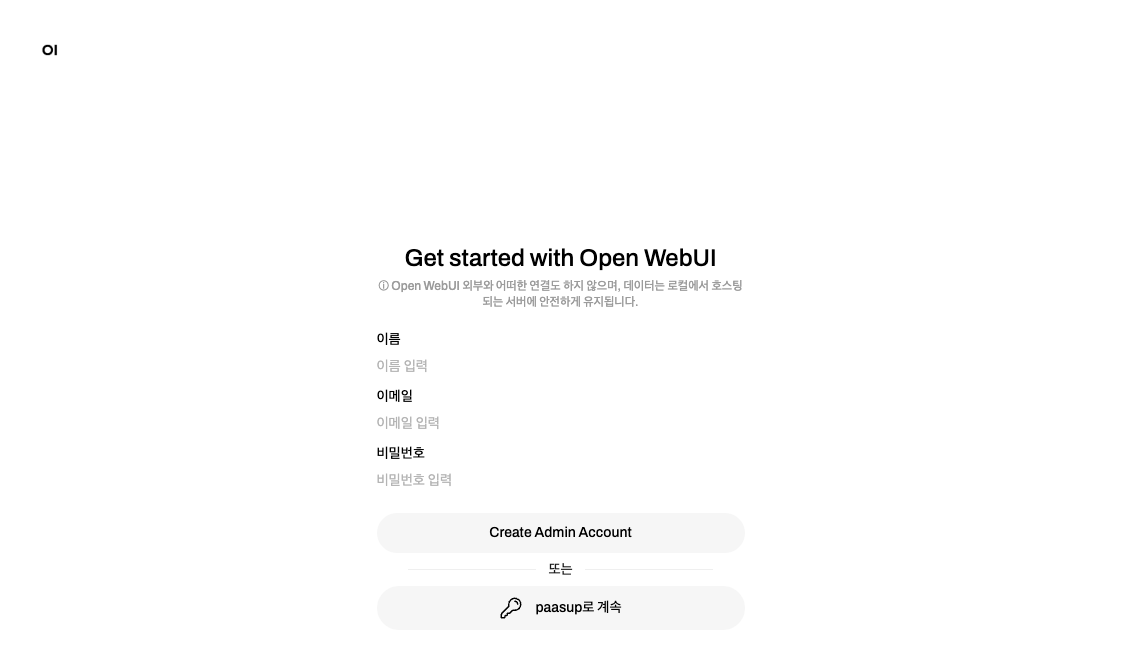
6.2 OpenWebUI 초기 설정
Step 1: 최초 접속 및 계정 생성
- OpenWebUI 서비스 링크 접속
- 최초 접속 시 관리자 계정 생성 화면 표시
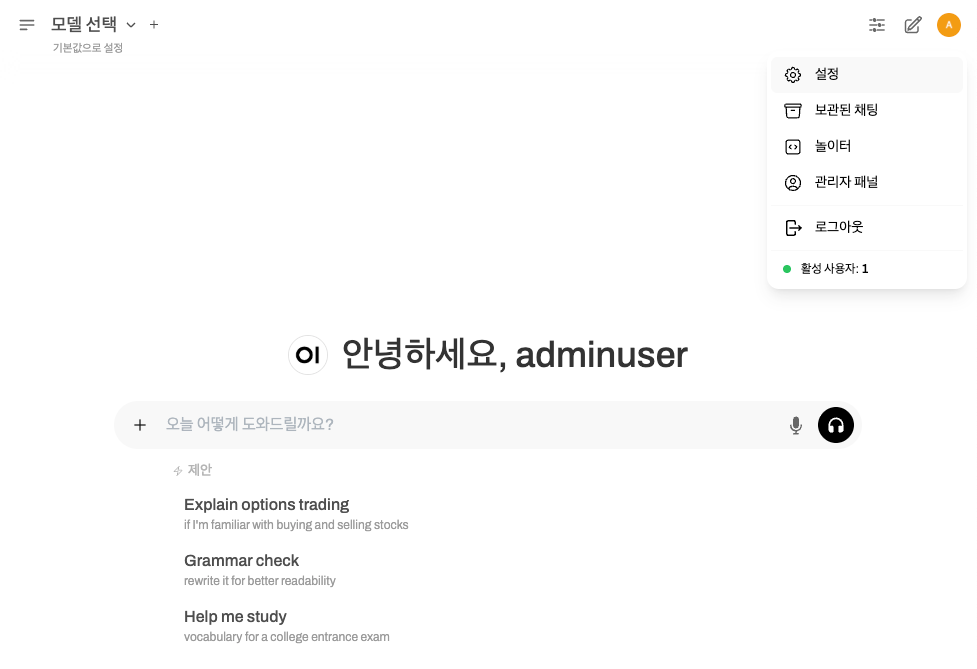
- 이름, 이메일 주소, 비밀번호를 설정하여 관리자 계정 생성
Step 2: 관리자 패널 접속
- 우측 상단 사용자 프로필 아이콘 클릭
- 관리자 패널 메뉴 선택
6.3 KServe 엔드포인트 연결 설정
Step 1: 연결 설정 메뉴 접속
- 상단 설정 탭 → 좌측 메뉴에서 연결 선택
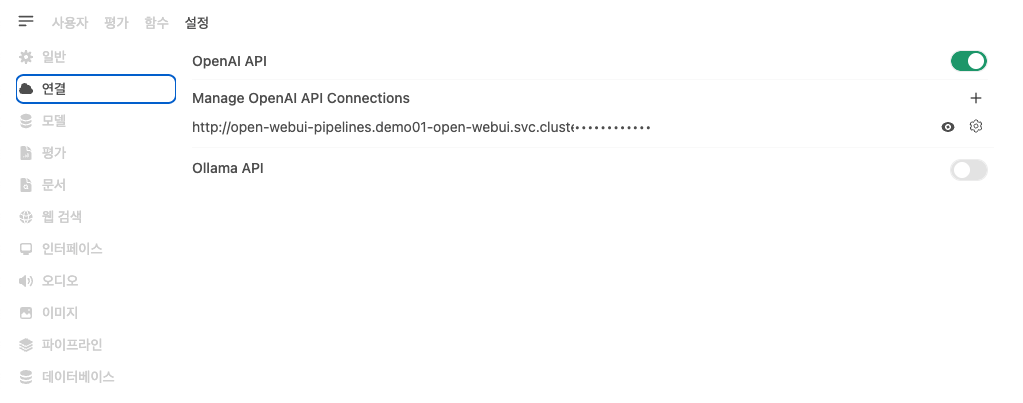
Step 2: OpenAI API 연결 추가
- OpenAI API 섹션의 '+' 버튼 클릭
- 연결 정보 입력:
- URL:
{KServe 엔드포인트}/openai/v1- 클러스터 외부 접근용:
https://demo01-kserve-kserve.demo01-test1.hopt.paasup.io/openai/v1 - 클러스터 내부 접근용:
http://demo01-kserve-predictor-00001.demo01-test1.svc.cluster.local:80/openai/v1 - 클러스터 내부 접근용:
http://demo01-kserve.demo01-test1.svc.cluster.local/openai/v1
- 클러스터 외부 접근용:
- API Key:
dummy-key(인증 비활성화 환경에서는 임의 값 입력) - Model: KServe 배포시 설정한 모델명 (예:
llama32_3b_it)
- 저장 버튼 클릭하여 설정 완료
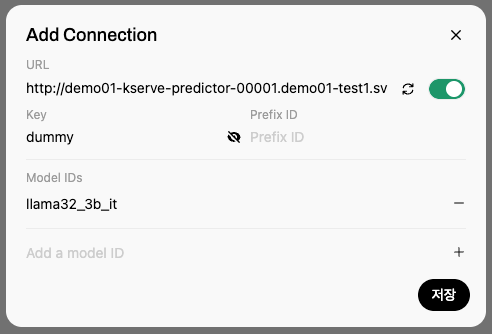
6.4 웹 인터페이스를 통한 모델 테스트
Step 1: 모델 선택
- OpenWebUI 메인 화면에서 연결한 모델 선택
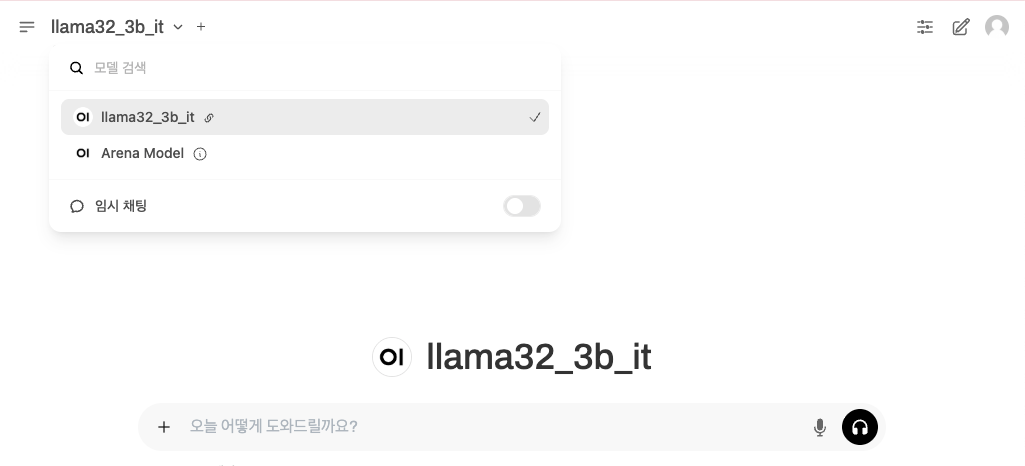
Step 2: 대화 테스트
- 채팅창에 질문 입력하여 응답 확인
입력 예시: 세 연속된 짝수의 합이 48일 때, 세 수를 구하세요.

이처럼 코딩 없이도 스트리밍 응답, 대화 히스토리 관리, 다중 사용자 접속 등 프로덕션 수준의 기능을 갖춘 AI 챗봇을 즉시 구축할 수 있습니다.
7. Flowise를 활용한 노코드 AI 워크플로우
Flowise는 시각적 노드 기반 인터페이스를 통해 복잡한 AI 워크플로우를 코딩 없이 구성할 수 있게 해주는 도구입니다. 특히 RAG(Retrieval-Augmented Generation) 시스템이나 다단계 AI 프로세스 구축에 유용합니다.
7.1 Flowise 카탈로그 배포
Step 1: Flowise 카탈로그 생성
- 카탈로그 생성 메뉴 → Flowise 선택
- 버전 및 이름 입력 후 생성
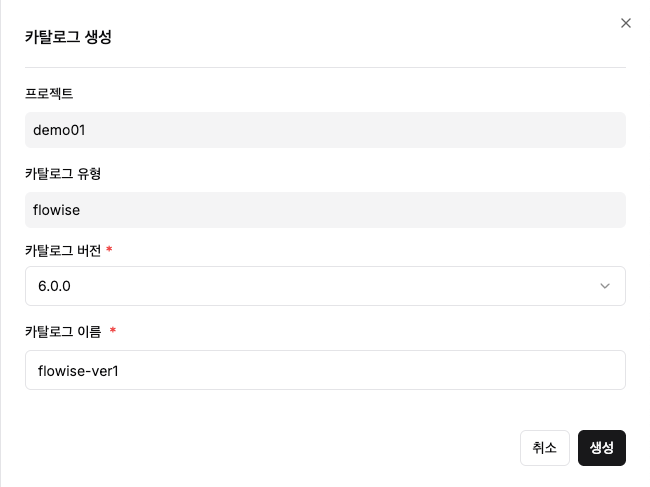
Step 2: 배포 상태 확인
- 카탈로그 배포 상태/서비스 상태가 정상으로 변경될 때까지 대기
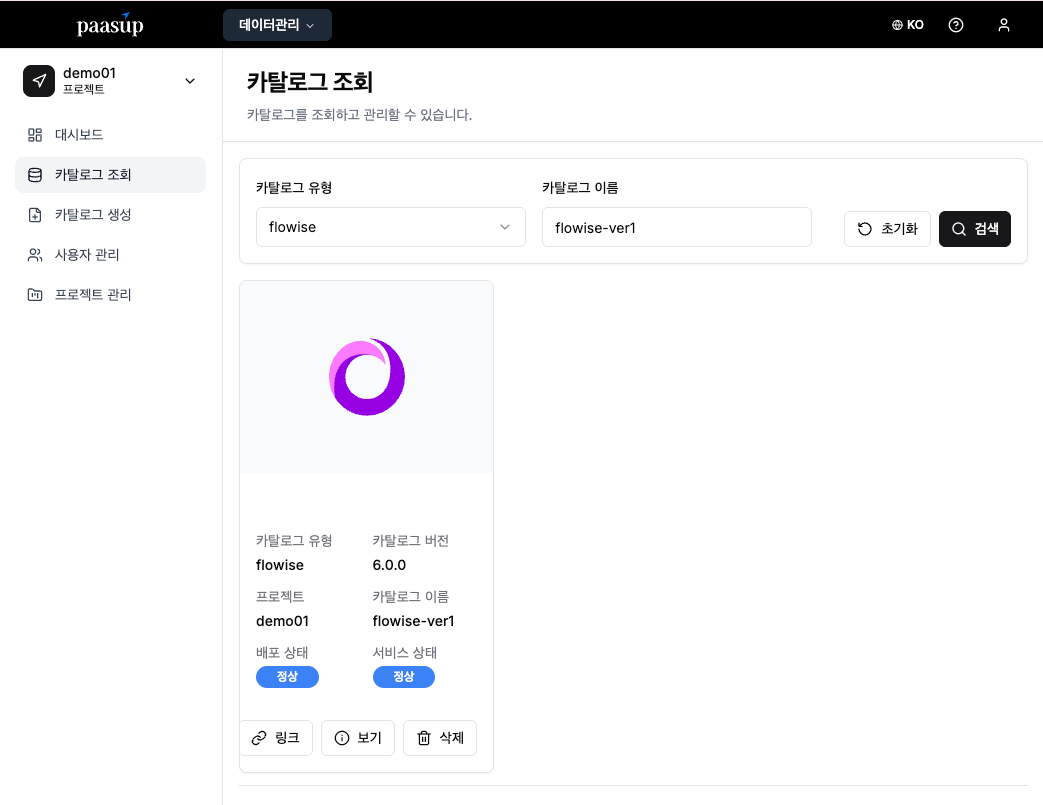
7.2 기본 Chatflow 구성
Step 1: 새로운 Chatflow 생성
- 좌측 Chatflows 메뉴 → Add New 버튼 클릭
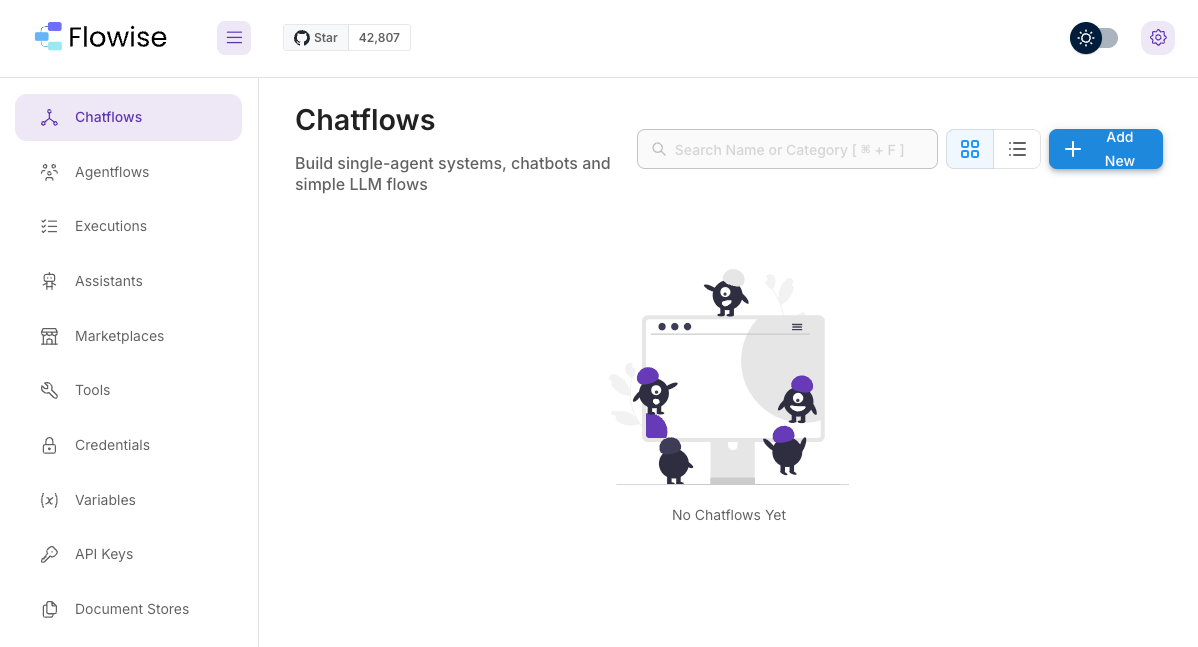
Step 2: 노드 추가
캔버스의 '+' 버튼을 클릭하여 다음 노드들을 추가합니다:
- ChatLocalAI: LLM 모델과의 연결을 담당하는 핵심 노드
- Buffer Memory: 대화 맥락 유지를 위한 메모리 관리
- Conversation Chain: 전체 대화 플로우를 조율하는 체인 관리자
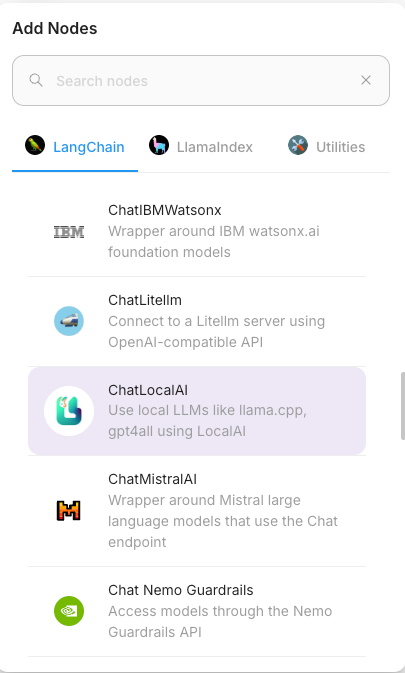
Step 3: 노드 연결 구성
드래그 앤 드롭으로 노드들을 논리적으로 연결합니다.:
- ChatLocalAI ↔ Conversation Chain (Chat Model 역할)
- Buffer Memory ↔ Conversation Chain (Memory 역할)
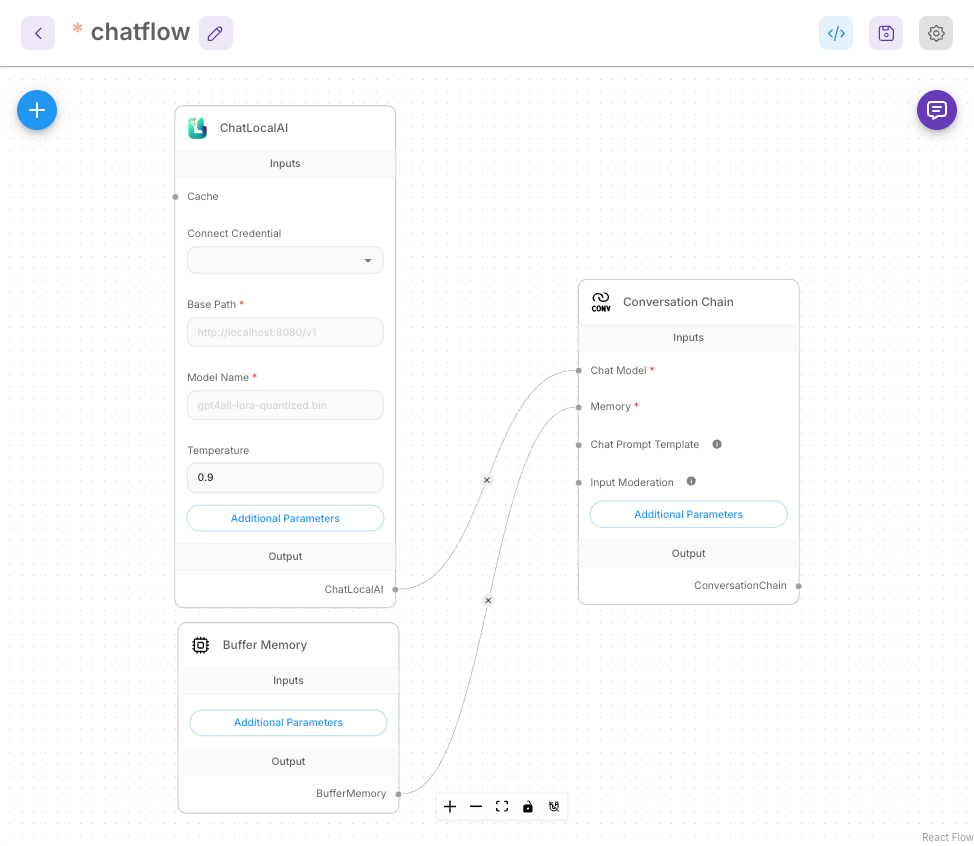
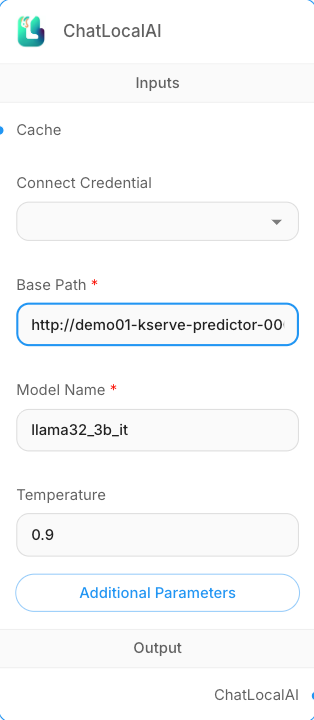
Step 4: ChatLocalAI 노드 설정
- Base Path:
{KServe 엔드포인트}/openai/v1- 클러스터 외부 접근용:
https://demo01-kserve-kserve.demo01-test1.hopt.paasup.io/openai/v1 - 클러스터 내부 접근용:
http://demo01-kserve-predictor-00001.demo01-test1.svc.cluster.local:80/openai/v1 - 클러스터 내부 접근용:
http://demo01-kserve.demo01-test1.svc.cluster.local/openai/v1
- 클러스터 외부 접근용:
- Model Name: KServe 배포시 설정한 모델명 (예:
llama32_3b_it)
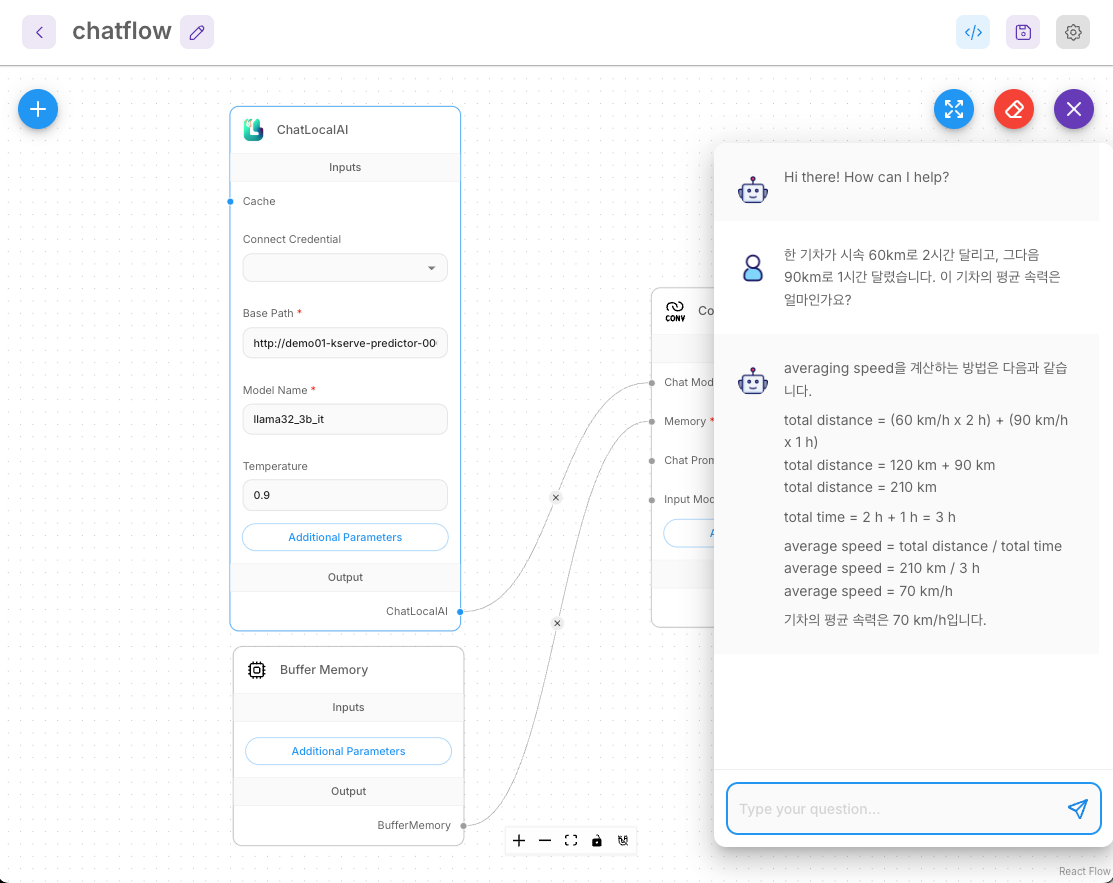
7.3 워크플로우 테스트 및 활용
기본 대화 테스트:
입력 예시: 한 기차가 시속 60km로 2시간 달리고, 그다음 90km로 1시간 달렸습니다. 이 기차의 평균 속력은 얼마인가요?
8. 마무리
PAASUP DIP를 활용하면 복잡한 Kubernetes 설정이나 MLOps 파이프라인 구축 부담 없이 엔터프라이즈급 LLM 서비스를 빠르게 구축할 수 있습니다.
접근 방법별 특징
| 인터페이스 | 장점 | 적합한 사용자/사례 |
|---|---|---|
| Jupyter Notebook | - 프로그래밍 방식의 세밀한 제어 - API 직접 호출 및 커스터마이징 - 자동화 가능 |
- 개발자 - 데이터 과학자 |
| OpenWebUI | - ChatGPT 스타일 UX - 멀티 유저 지원 |
- 일반 사용자 - 팀용 AI 챗봇 |
| Flowise | - 드래그 앤 드롭 방식 - 노코드 워크플로우 - RAG/멀티스텝 프로세스 구성 |
- 비개발자 - 업무 자동화 |
활용 팁
- 모델 성능 최적화: 배포 후
temperature,top_p등 하이퍼파라미터를 조정하여 최적의 응답 품질을 찾아보세요. - 리소스 모니터링: DIP의 모니터링 기능을 활용하여 CPU, 메모리 사용량을 지속적으로 확인하세요.
- 오토스케일링 활용: 트래픽 증가 시, KServe의 오토스케일링 기능을 활성화하여 수요에 따라 자동으로 Pod 수를 조절할 수 있습니다.
PAASUP DIP의 카탈로그 시스템을 활용하면 여러분의 조직에 맞는 LLM 서비스를 효율적으로 구축하고 운영할 수 있습니다. 이 가이드가 여러분의 AI 프로젝트에 좋은 출발점이 되기를 바랍니다.