
NeMo Curator로 텍스트 큐레이션 파이프라인 구축하기
이 가이드는 NVIDIA NeMo Curator를 활용해 대규모 언어 모델(LLM) 학습에 필요한 고품질 데이터셋을 구축하는 방법을 다룹니다. 우리는 간단한 테스트 예시를 해 데이터 수집부터 클리닝, 중복 제거, 언어 라벨링까지, 체계적인 텍스트 큐레이션 파이프라인을 구축하고 실행하는 엔드투엔드 절차를 실습 중심으로 정리했습니다.

목차
- 서론: 왜 데이터 큐레이션인가?
- NeMo Curator란?
- NeMo Curator의 처리 흐름
- 실습 환경 준비
- 실습: 100개 HTML 문서 전처리하기
- 결과 분석
- NeMo Curator의 고급 기능 소개
- 결론
1. 서론: 왜 데이터 큐레이션인가?
대규모 언어 모델(LLM)의 성능은 모델 아키텍처만큼이나 데이터 품질에 크게 좌우됩니다. 학습 데이터에 불필요하거나 중복된 정보가 많으면, 모델은 중요한 패턴을 학습하기보다 잡음(noise)에 혼란을 느끼게 됩니다. 이는 특히 번역, QA, 생성형 AI처럼 정교한 추론이 필요한 작업에서 학습 성능을 크게 떨어뜨립니다.
데이터를 많이 모으는 것만으로는 충분하지 않습니다. 학습에 의미 있는 텍스트만 추려내고, 중복을 제거하며, 다양한 언어와 도메인 균형을 확보해야 합니다. 이를 체계적이고 확장 가능한 방식으로 지원하는 도구가 바로 NeMo Curator입니다. GPU 가속, Dask 기반 병렬 처리, 모듈형 파이프라인을 통해 수십억 문서까지 빠르고 안정적으로 정제할 수 있습니다.
이번 글에서는 NeMo Curator의 핵심 기능과 함께, 실제 테스트 데이터를 이용한 텍스트 큐레이션 실습 예시를 통해 기본 사용법과 처리 흐름을 이해해 보겠습니다.
2. NeMo Curator란?
NeMo Curator는 NVIDIA가 개발한 오픈소스 데이터 큐레이션 프레임워크입니다. 원시 데이터를 자동 정제, 필터링, 중복 제거, 라벨링하여 LLM 학습에 적합한 데이터셋으로 가공합니다.
주요 특징
- 멀티모달 지원: 텍스트뿐 아니라 이미지, 비디오까지 처리 가능해 멀티모달 모델 학습 데이터 준비에 유리합니다.
- GPU 가속 처리: RAPIDS/cuDF 기반으로 CPU 대비 10~100배 속도 향상을 제공합니다.
- 대규모 분산 처리: Dask를 활용해 수억~수십억 문서를 병렬로 처리할 수 있습니다.
- MLOps 친화적: Kubeflow, KServe, Slurm 등과 자연스럽게 통합되어 프로덕션 환경에 적합합니다.
- 유연한 모듈화: 표준 연산자(Modify, ScoreFilter, Sequential 등)를 조합해 원하는 파이프라인을 구성할 수 있습니다.
3. NeMo Curator의 처리 흐름
NeMo Curator의 핵심은 모듈화된 처리 단계에 있으며, 각 단계는 Dask 기반의 분산 실행을 지원합니다. 다음은 텍스트 기준의 일반적인 파이프라인 흐름입니다.
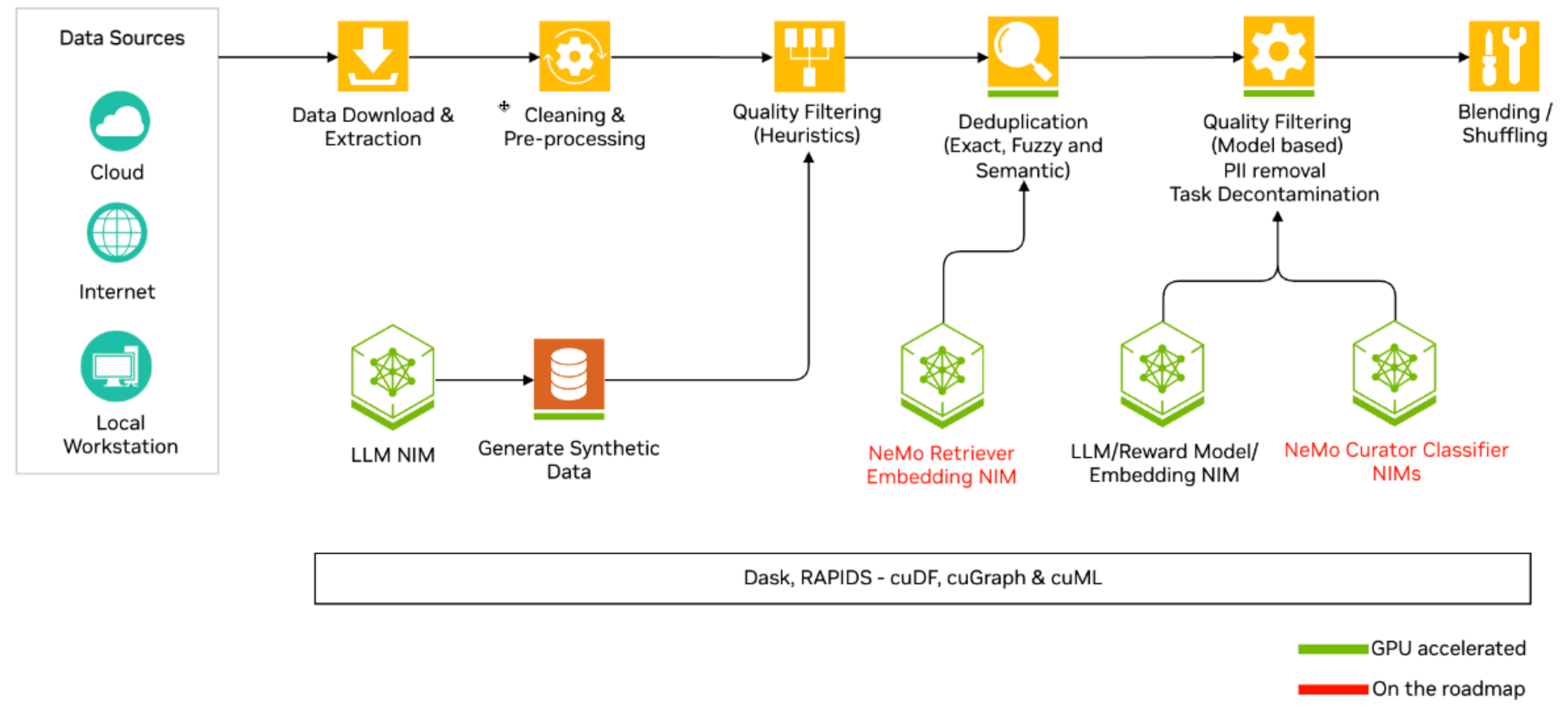
| 단계 | 목적 |
|---|---|
| 1. 데이터 수집 | 다양한 소스에서 원시 텍스트를 가져와 NeMo Curator의 형식으로 변환 |
| 2. 클리닝 | HTML 태그, URL, 특수 문자 등 불필요한 노이즈를 제거하여 텍스트를 표준화 |
| 3. 품질 필터링 | 짧은 문서, 의미 없는 반복 문장 등 학습에 방해가 되는 저품질 데이터를 걸러냄 |
| 4. 중복 제거 | 동일하거나 유사한 문서를 찾아 제거하여 모델이 반복 학습하는 것을 방지 |
| 5. 언어 라벨링 | 문서의 언어를 식별하여 다국어 모델 학습을 위한 기반을 마련 |
| 6. 특수 처리 | 코드, 합성 데이터 등 특정 유형의 문서를 따로 분리하거나 가공 |
| 7. 저장 및 셰이딩 | 최종 정제된 데이터를 학습에 적합한 형식으로 분할하여 저장 |
각 단계는 표준화된 연산자로 정의되며, 체크포인트 저장을 통해 중간 결과 추적과 복원도 지원합니다.
4. 실습 환경 준비
4.1 시스템 요구사항
NeMo Curator의 텍스트 큐레이션 모듈을 사용하려면 다음 요구사항을 충족해야 합니다:
필수 요구사항:
- OS: Ubuntu 22.04/20.04 (권장)
- Python: 3.10 또는 3.12(Python 3.11은 지원되지 않음)
- Memory: 기본 텍스트 처리를 위한 16GB+ RAM
선택적 요구사항:
- GPU: NVIDIA GPU with 16GB+ VRAM (GPU 가속 작업용)
- 대부분의 텍스트 모듈에서는 선택사항
- 모든 이미지 모듈에서는 필수
- GPU 가속 시 처리 속도 10-100배 향상
4.2 설치 옵션
NeMo Curator는 3가지 설치 방식을 지원합니다:
- PyPI: 빠른 설치 및 테스트용
- 소스 빌드: 최신 개발 버전 필요 시
- 컨테이너: 안정적인 실행을 보장하여 프로덕션 배포에 이상적
# 컨테이너 다운로드
docker pull nvcr.io/nvidia/nemo-curator:25.07
# CPU 환경에서 실행
docker run -it --rm nvcr.io/nvidia/nemo-curator:25.07
# GPU 지원과 함께 컨테이너 실행
docker run --gpus all -it --rm nvcr.io/nvidia/nemo-curator:25.07
# 컨테이너 내부에서 커스텀 설치 (필요시)
pip uninstall nemo-curator
rm -r /opt/NeMo-Curator
git clone https://github.com/NVIDIA/NeMo-Curator.git /opt/NeMo-Curator
pip install --extra-index-url https://pypi.nvidia.com "/opt/NeMo-Curator[all]"
5. 실습: 100개 HTML 문서 전처리하기
5.1 테스트 데이터 생성 스크립트
NeMo Curator 파이프라인의 각 단계별 효과를 명확하게 보여주기 위해, 다음과 같은 특징을 가진 HTML 문서 100개를 생성하는 Python 스크립트를 작성했습니다. 이 스크립트는 custom_data/html/ 폴더에 총 100개의 HTML 파일을 만듭니다.
※ 스크립트 파일: create_data_sample.py
데이터 특징:
- 일반 문서: 날씨, 공지사항, 레시피 등 평범한 한국어/영어 텍스트
- 짧은 문서: "확인 완료", "승인"과 같은 짧은 문장 (품질 필터링 대상)
- 완전 중복 문서: 다른 문서와 동일한 텍스트 (중복 제거 대상)
- 코드 문서: 파이썬, SQL, 자바스크립트 등 코드 내용 (특수 처리 대상)
- URL 포함 문서: 본문에 URL이 포함된 문서 (클리닝 대상)
스크립트 주요 파라미터:
스크립트의 주요 파라미터를 수정하여 생성될 데이터의 비율을 조절할 수 있습니다.
- TOTAL: 총 생성할 문서 수
- SHORT_RATE: 짧은 문서 비율
- EXACT_DUP_RATE: 완전 중복 문서 비율
- CODE_RATE: 코드 문서 비율
- EN_RATE: 영어 문서 비율
- URL_RATE: URL 포함 문서 비율
이 스크립트를 통해 생성된 데이터는 이후 NeMo Curator 파이프라인의 입력으로 사용되어, 각 단계가 어떻게 작동하는지 효과적으로 보여주는 역할을 합니다.
생성된 HTML 파일 예시:
<!DOCTYPE html>
<html><head>
<meta charset="UTF-8"><meta name="source_id" content="doc0001">
</head><body><div class="content">
프로젝트 현황 - 웹사이트 리뉴얼<br><br>프로젝트명: 웹사이트 리뉴얼<br>진행률: 75%<br>담당팀: 개발팀<br>마일스톤: 배포 완료<br>이슈사항: 일정 지연<br>다음 단계: 사용자 교육<br><br>참고링크: https://github.com/nvidia/NeMo-Curator
</div></body></html>
5.2 커스텀 데이터 로딩
NeMo Curator에서 로컬 HTML 파일을 처리하기 위해 커스텀 로더(DocumentDownloader / DocumentIterator / DocumentExtractor)를 직접 구현합니다:
from pathlib import Path
import hashlib
from bs4 import BeautifulSoup
from nemo_curator.download.doc_builder import (
DocumentDownloader, DocumentIterator, DocumentExtractor
)
# Create Custom Downloader:
class LocalFileDownloader(DocumentDownloader):
"""로컬 파일 시스템에서 파일을 읽어오는 다운로더"""
def download(self, url: str) -> str:
"""로컬 파일 경로를 그대로 반환"""
p = Path(url)
if not p.exists():
raise FileNotFoundError(f"{url} not found")
return str(p)
# Create Custom Iterator:
class HTMLFileIterator(DocumentIterator):
"""단일 HTML 파일을 하나의 문서로 이터레이션"""
def iterate(self, file_path: str):
with open(file_path, "r", encoding="utf-8") as f:
html = f.read()
yield {"url": Path(file_path).as_posix()}, html # (metadata, content)
# Create Custom Extractor:
class SimpleHTMLExtractor(DocumentExtractor):
def extract(self, content: str):
"""HTML을 텍스트로 변환하고 id/metadata를 구성"""
soup = BeautifulSoup(content, "html.parser")
text = soup.get_text(separator="\n").strip()
uid = hashlib.md5(text.encode("utf-8")).hexdigest()[:12]
return {
"text": text,
"id": uid,
"metadata": {"source_type": "local_html"},
}
데이터 로딩 실행 코드:
from nemo_curator import get_client
from nemo_curator.download import download_and_extract
from dask import dataframe as dd
def load_custom_data():
# Dask 클라이언트 초기화
client = get_client(cluster_type="cpu")
# HTML 파일 수집
root = Path("./custom_data/html")
exts = {".html"}
# 필요시 {".html", ".htm", ".md", ".txt"} 등으로 확장
urls = [p.as_posix() for p in root.rglob("*")
if p.is_file() and p.suffix.lower() in exts]
if not urls:
raise SystemExit(f"No input files found under: {root}")
tmp_dir = Path("./.curator_cache")
output_paths = [str(tmp_dir / Path(u).stem) for u in urls]
# 문서 다운로드 및 추출
ds = download_and_extract(
urls=urls,
output_paths=output_paths,
downloader=LocalFileDownloader(),
iterator=HTMLFileIterator(),
extractor=SimpleHTMLExtractor(),
output_format={"text": str, "id": str, "metadata": object},
output_type="jsonl",
keep_raw_download=True,
force_download=False,
)
# file_name 컬럼을 추가하여 파일별 저장 준비
names = [Path(u).stem for u in urls] # 입력 basename들
ds.df = ds.df.repartition(npartitions=len(urls))
ds.df = dd.concat([
ds.df.get_partition(i).assign(file_name=nm + ".jsonl")
for i, nm in enumerate(names)
])
# 처리된 데이터 저장
outdir = Path("./custom_data/processed")
outdir.mkdir(parents=True, exist_ok=True)
ds.to_json(output_path=str(outdir), write_to_filename=True, keep_filename_column=False)
if __name__ == "__main__":
load_custom_data()
5.3 텍스트 큐레이션 파이프라인 구축
이제 NeMo Curator의 모듈들을 조합하여 실제 큐레이션 파이프라인을 구축합니다:
입력 데이터 로드 -> 클리닝 -> 품질 필터링 -> 중복 제거 -> 언어 라벨링 -> 코드 문서 분리 -> 최종 저장
0단계: 사전 설정
from nemo_curator import get_client, Sequential, Modify, ScoreFilter, ExactDuplicates
from nemo_curator.datasets import DocumentDataset
from nemo_curator.modifiers import UnicodeReformatter, NewlineNormalizer, UrlRemover
from nemo_curator.filters import (
WordCountFilter,
FastTextLangId,
NumberOfLinesOfCodeFilter,
AlphaFilter
)
from nemo_curator.utils.file_utils import get_all_files_paths_under
from dask import dataframe as dd
from pathlib import Path
import hashlib, re
import datetime
# ===== 설정 =====
INPUT = "./custom_data/processed"
OUTDIR = Path("./custom_data/outputs/final")
MIN_WORDS = 8 # 최소 단어 수 필터
SAVE_INTERMEDIATE = True # 중간 결과 저장 여부
# 실행 태그 생성 (체크포인트 폴더명)
RUN_TAG = datetime.datetime.now().strftime("%Y%m%d-%H%M%S")
CKPT_ROOT = Path("./custom_data/outputs") / RUN_TAG
CKPT_ROOT.mkdir(parents=True, exist_ok=True)
def ckpt(ds, name):
"""중간 결과 저장 함수"""
if SAVE_INTERMEDIATE:
p = CKPT_ROOT / name
p.mkdir(parents=True, exist_ok=True)
ds.to_json(str(p))
print(f"체크포인트 저장: {p}")
# Dask 클라이언트 초기화
client = get_client(cluster_type="cpu")
print("Dask 클라이언트 초기화 완료")
데이터 로드
# 0단계: 입력 데이터 로드
files = get_all_files_paths_under(INPUT, keep_extensions="jsonl")
files = [f for f in files if Path(f).stat().st_size > 0] # 빈 파일 제외
if not files:
raise SystemExit("No non-empty .jsonl files found under ./custom_data/processed")
ds = DocumentDataset.read_json(
files,
files_per_partition=1,
blocksize=None,
input_meta={"text": str, "id": str, "metadata": object, "url": str},
)
# dtype 명시적 고정 (안정성 확보)
ds.df = ds.df.astype({
"text":"object",
"id":"object",
"metadata":"object",
"url":"object"
})
print(f"[초기 로드] {ds.df.shape[0].compute()}개 문서")
1단계: 클리닝 (Cleaning)
깨진 유니코드, 불필요한 공백, URL 등을 제거하여 텍스트를 표준화합니다.
# 1단계: 클리닝
clean = Sequential([
Modify(UnicodeReformatter()), # Fix Unicode encoding issues
Modify(NewlineNormalizer()), # Standardize newlines
Modify(UrlRemover()), # Remove URLs
])
# Apply the cleaning pipeline
ds = clean(ds)
print(f"[클리닝 후] {ds.df.shape[0].compute()}개 문서")
def _tkey_series(s):
return s.fillna("").map(lambda t: hashlib.md5(t.encode("utf-8")).hexdigest()[:16],
meta=("tkey","object"))
# 텍스트 기반 고유 키 생성 (중복 방지 및 추적용)
base = ds.df.assign(id=ds.df["id"].fillna(""), _tkey=_tkey_series(ds.df["text"]))
missing = (base["id"] == "")
ds.df = base.assign(id = base["id"].mask(missing, "auto_" + base["_tkey"])).persist()
# 데이터 재파티션 (소규모 데이터이므로 1개 파티션으로 통합)
ds.df = ds.df.repartition(npartitions=1).persist()
#ckpt(ds, "01_clean") # 결과 저장
2단계: 품질 필터링 (Quality Filtering)
내용이 너무 짧은 문서(8단어 미만)를 제거합니다.
# 2단계: 품질 필터링 (짧은 문서 제거)
ds = ScoreFilter(WordCountFilter(min_words=MIN_WORDS), text_field="text")(ds)
print(f"[품질 필터 후] {ds.df.shape[0].compute()}개 문서 (최소 {MIN_WORDS}단어)")
ds.df = ds.df.persist()
#ckpt(ds, "02_quality") # 결과 저장
3단계: 정확한 중복 제거 (Exact Deduplication)
본문이 완전히 동일한 중복 데이터를 제거합니다.
# 3단계: 정확한 중복 제거
dedup = ExactDuplicates(
text_field="text", # 본문이 완전히 같은 행 제거
perform_removal=True
)
ds = dedup(ds)
print(f"[중복 제거 후] {ds.df.shape[0].compute()}개 문서")
ds.df = ds.df.persist()
#ckpt(ds, "03_dedup_exact") # 결과 저장
4단계: 언어 라벨링 (Language Identification)
문서의 언어를 식별하여 'KO' 또는 'EN'과 같은 라벨을 추가합니다.
중요: 이 모듈을 사용하기 전에 공식 fastText 저장소에서 fastText 언어 식별 모델 파일(
lid.176.bin)을 다운로드해야 합니다.
# 4단계: 언어 라벨링
# 주의: lid.176.bin 파일이 현재 디렉토리에 있어야 함
if "text" not in set(ds.df.columns):
ds.df = ds.df.assign(text="")
else:
ds.df = ds.df.assign(text=ds.df["text"].fillna("").astype("object"))
ds.df = ds.df.persist()
ds.df = ds.df.assign(_lang_obj=None).persist()
# fastText 점수/라벨 쓰기
ds = ScoreFilter(
FastTextLangId(model_path="./lid.176.bin", min_langid_score=0.0),
text_field="text",
score_field="_lang_obj", # 임시 컬럼
score_type="object",
)(ds)
# 임시 컬럼 -> 언어 코드 정규화
def _to_lang_code(v):
def _norm(code):
if isinstance(code, str) and code.startswith("__label__"):
code = code.replace("__label__", "")
return code.upper() if isinstance(code, str) else "UNK"
if isinstance(v, (list, tuple)) and len(v) >= 2:
return _norm(v[1])
if isinstance(v, dict):
return _norm(v.get("language") or v.get("lang") or v.get("code"))
return "UNK"
ds.df = ds.df.assign(
language = ds.df["_lang_obj"].map_partitions(
lambda s: s.apply(_to_lang_code),
meta=("language", "object"),
)
).persist()
# 임시 컬럼 삭제
def _drop_tmp(pdf):
if "_lang_obj" in pdf.columns:
return pdf.drop(columns=["_lang_obj"])
return pdf
meta = ds.df._meta
if "_lang_obj" in meta.columns:
meta = meta.drop(columns=["_lang_obj"])
ds.df = ds.df.map_partitions(_drop_tmp, meta=meta).persist()
#ckpt(ds, "04_lang_identification") # 결과 저장
5단계: 특수 처리 (Special Handling)
코드와 일반 텍스트 문서를 분리합니다. NumberOfLinesOfCodeFilter와 AlphaFilter를 사용하여 코드를 식별합니다.
# 5단계: 코드 문서와 일반 텍스트 문서 분리
# 코드 문서 식별
code_filter = Sequential([
ScoreFilter(NumberOfLinesOfCodeFilter(min_lines=5, max_lines=2000),
text_field="text", score_field="line_count"),
ScoreFilter(AlphaFilter(min_alpha_ratio=0.2),
text_field="text", score_field="alpha_ratio"),
])
ds_code_only = code_filter(DocumentDataset(ds.df))
n_code = ds_code_only.df.shape[0].compute()
print(f"[코드 문서] {n_code}개")
# 비코드 문서만 남기기 (안티조인)
code_keys = set(ds_code_only.df["_tkey"].compute())
non_code_mask = ds.df["_tkey"].map_partitions(lambda s: ~s.isin(code_keys),
meta=("_tkey","bool"))
ds_non_code = DocumentDataset(ds.df[non_code_mask]).persist()
ds_non_code.df = ds_non_code.df.reset_index(drop=True).persist()
print(f"[비코드 문서]" {ds_non_code.df.shape[0].compute()}개")
#ckpt(ds_code_only, "05_code_only") # 필요하면 저장
#ckpt(ds_non_code, "05_non_code_only") # 결과 저장
ds = ds_non_code
최종 결과 저장
모든 파이프라인 단계를 거친 최종 데이터를 jsonl 형식으로 저장합니다.
# 최종 데이터 저장
OUTDIR.mkdir(parents=True, exist_ok=True)
dd.to_json(
ds.df,
str(OUTDIR / "shard-*.jsonl"),
orient="records",
lines=True,
force_ascii=False,
)
print(f"[done] saved to {OUTDIR.resolve()}")
6. 결과 분석
이번 실습에서는 100개의 테스트 문서를 NeMo Curator 파이프라인으로 처리하며, 데이터 품질이 어떻게 향상되는지 단계별로 확인했습니다.
단계별 처리 결과
아래 표는 각 큐레이션 단계별로 문서 수가 어떻게 변화했는지 보여줍니다.
| 처리 단계 | 문서 수 | 제거된 문서 유형 |
|---|---|---|
| 초기 로드 | 100개 | - |
| 클리닝 후 | 100개 | - (URL 제거, 텍스트 정규화) |
| 품질 필터 후 | 92개 | 8단어 미만 짧은 문서 |
| 중복 제거 후 | 68개 | 동일 텍스트 중복 문서 |
| 언어 식별 후 | 68개 | - (언어 라벨 추가) |
| 코드 분리 후 | 52개 | 코드 블록 포함 문서 |
품질 향상 효과 분석
실습 결과, 100개의 원시 문서 중 48%에 해당하는 불필요한 데이터가 제거되었습니다. 이는 학습 효율을 높이고 모델 성능을 개선하는 데 직접적으로 기여합니다.
노이즈 및 저품질 데이터 제거
NeMo Curator는 품질 필터링을 통해 "Notice\nComplete #917"과 같이 내용이 짧아 학습에 유의미한 정보를 제공하지 않는 문서를 걸러냅니다. 또한, 클리닝 단계를 통해 본문에 포함된 불필요한 URL(https://...)과 같은 노이즈를 제거하여 텍스트를 표준화합니다.
- 제거된 짧은 문서 예시: 8단어 미만으로 언어 모델 학습에 유의미한 정보를 제공하지 않음
{
"id":"add7ebc1d8e0",
"metadata":{"source_type":"local_html"},
"text":"Notice\nComplete #917",
"url":"custom_data\/html\/doc0083.html",
"_tkey":"add7ebc1d8e0f602"
}
중복 데이터 최소화
내용이 완전히 동일한 문서 24개가 정확한 중복 제거(Exact Deduplication) 모듈로 걸러졌습니다. 이를 통해 모델이 동일한 정보를 반복적으로 학습하는 비효율을 방지할 수 있습니다.
- 제거된 중복 문서 예시: 동일한 텍스트 내용을 가진 문서가 이미 존재하여 중복 제거됨
{
"id":"0a978b18f514",
"metadata":{"source_type":"local_html"},
"text":"Weekly Report - {dept}\nDepartment: 개발팀\\nWeek of 2025-08-27\\n\\npage views increased by 18%.\\nTeam: 정민호\\nNext review: 2025-09-15\\nAction items: 문서 검토",
"url":"custom_data\/html\/doc0010.html",
"_tkey":"0a978b18f5141477"
}
체계적인 문서 분류
언어 라벨링을 통해 한국어 문서에는 KO 라벨이, 영어 문서에는 EN 라벨이 자동으로 추가되었습니다. 이러한 메타데이터는 다국어 모델 학습이나 언어별 데이터셋 분리에 매우 유용합니다.
- 언어 라벨링 후 데이터 예시:
language필드 추가
{
"id":"8fc72a0702db",
"metadata":{"source_type":"local_html"},
"text":"서울 날씨 - {region}\n오늘(2025-08-04) 부산은 맑고 강한 바람입니다. 기온은 25도이며, 습도가 높게 예상됩니다.",
"url":"custom_data\/html\/doc0052.html",
"_tkey":"8fc72a0702db8f29",
"language":"KO"
}
또한, NumberOfLinesOfCodeFilter와 AlphaFilter를 사용하여 코드가 포함된 문서를 정확하게 식별하고 분리했습니다. 이렇게 분리된 코드는 별도의 코드 학습 데이터셋으로 활용하거나, 일반 텍스트 학습에서 제외할 수 있어 데이터셋의 목적에 맞게 품질을 관리할 수 있습니다.
- 분리된 코드 문서 예시: 5줄 이상의 코드 라인과 적절한 알파벳 비율로 코드 문서로 분류
{
"id":"aa006c3804ae",
"metadata":{"source_type":"local_html"},
"text":"Python Web Scraping\n```python\n# Web scraping utilities\nimport requests\nfrom bs4 import BeautifulSoup\nimport time\ndef scrape_data(url):\n # Set headers to avoid blocking\n headers = {'User-Agent': 'Mozilla\/5.0 (compatible)'}\n response = requests.get(url, headers=headers)\n if response.status_code == 200:\n # Parse HTML content\n soup = BeautifulSoup(response.content, 'html.parser')\n titles = soup.find_all('h1')\n return [title.text.strip() for title in titles]\n return []\ndef batch_scrape(urls):\n # Scrape multiple URLs with delay\n results = []\n for url in urls:\n data = scrape_data(url)\n results.extend(data)\n time.sleep(1) # Rate limiting\n return results\n```",
"url":"custom_data\/html\/doc0023.html",
"_tkey":"aa006c3804aee757",
"language":"EN",
"line_count":25,
"alpha_ratio":0.6430517711
}
7. NeMo Curator의 고급 기능 소개
NeMo Curator는 단순한 텍스트 정제를 넘어, 대규모 데이터셋을 위한 엔터프라이즈급 큐레이션 기능을 제공합니다. 이 섹션에서는 NeMo Curator의 주요 고급 기능들을 간략하게 소개합니다.
GPU 가속 처리
NeMo Curator는 RAPIDS cuDF를 활용해 데이터 처리 속도를 CPU 대비 10~100배까지 향상시킵니다. 이 GPU 가속 덕분에 수십억 개의 문서도 빠르게 병렬 처리할 수 있어, 대규모 LLM 학습 데이터셋 준비 시간을 획기적으로 단축할 수 있습니다.
퍼지 중복 제거 (Fuzzy Deduplication)
단순히 내용이 완전히 같은 문서를 제거하는 것을 넘어, MinHash와 같은 기술을 이용해 내용이 유사한 문서를 찾아 제거합니다. 이는 웹 스크래핑 데이터처럼 내용이 약간씩 변형된 중복 문서가 많은 경우에 특히 유용하며, 모델이 비슷한 정보를 반복 학습하는 것을 방지합니다.
개인정보 제거 (PII Removal)
이메일 주소, 전화번호, 주민등록번호와 같은 민감한 개인정보(PII)를 자동으로 탐지하고 제거하는 기능을 제공합니다. 이는 데이터셋의 개인정보 보호와 규정 준수에 필수적인 기능입니다.
도메인별 품질 평가
NeMo Curator는 일반적인 품질 필터 외에도 특정 도메인(예: 의료, 법률, 기술)에 특화된 품질 평가 모듈을 제공합니다. 이를 통해 도메인 전문 용어의 밀도 등을 기준으로 해당 분야에 적합한 고품질 문서를 선별할 수 있습니다.
체크포인트·계보 추적
단계별로 중간 결과를 저장하고, 언제든지 작업을 재개할 수 있는 체크포인트 기능을 지원합니다. 또한, 모든 처리 단계의 이력을 기록하는 데이터 라인리지(Data Lineage) 기능을 통해 데이터의 출처와 가공 과정을 투명하게 관리하여, 재현성과 규정 준수를 강화할 수 있습니다.
8. 결론
NeMo Curator는 단순한 데이터 정제 도구를 넘어 엔터프라이즈급 데이터 큐레이션 플랫폼으로서 다음과 같은 가치를 제공합니다.
- 확장성과 성능: 수십억 문서를 처리할 수 있는 분산 아키텍처와 GPU 가속을 통해 대규모 작업을 안정적으로 수행합니다.
- 모듈화와 유연성: 플러그인 방식의 필터 시스템은 도메인별 커스터마이제이션을 가능하게 하며, 기존 MLOps 워크플로우에 쉽게 통합됩니다.
- 품질과 신뢰성: 검증된 휴리스틱과 ML 기반 필터는 데이터 품질을 보장하고, 추적 가능한 데이터 계보 관리를 지원합니다.
데이터는 AI의 원료이지만, 정제되지 않은 원료는 오히려 독이 될 수 있습니다. NeMo Curator는 이러한 데이터 품질 문제를 체계적이고 확장 가능한 방식으로 해결하는 강력한 도구입니다. 이번 실습을 통해 경험한 파이프라인은 NeMo Curator 기능의 일부에 불과하며, 진정한 가치는 수십억 문서 규모의 실제 프로덕션 환경에서 발휘됩니다.
NeMo Curator와 함께 여러분의 AI 프로젝트에서 데이터 품질 때문에 고민하는 시간을 줄이고, 오직 모델과 알고리즘의 혁신에만 집중할 수 있기를 바랍니다.