NeMo Evaluator로 LLM 평가하기: 표준 벤치마크부터 커스텀까지 엔드투엔드 가이드
이번 가이드는 PAASUP DIP 환경에서 NVIDIA NeMo Evaluator를 활용해 OpenAI 호환 엔드포인트(NIM Proxy) 에 연결하고, 표준 벤치마크(LM Evaluation Harness)와 커스텀 데이터로 LLM을 일관된 절차로 평가하는 방법을 다룹니다. 설정 → 타깃 등록 → 실행 → 결과 해석까지 엔드투엔드 흐름을 실습 중심으로 정리했습니다.
목차
- 들어가며
- Prerequisites: 환경 구성 및 설정
- 표준 벤치마크 평가 (LM Evaluation Harness): GSM8K 예시
- Custom 평가: 사용자 정의 데이터로 평가하기
- 효과적인 평가를 위한 가이드
- 마치며
1. 들어가며
LLM(Large Language Model) 개발에서 모델의 성능을 객관적으로 평가하는 것은 매우 중요한 과정입니다. 파인튜닝 전후의 성능 비교, 서로 다른 모델 간의 벤치마크 비교, 그리고 실제 서비스에 적용하기 전의 검증 과정에서는 체계적인 평가 방법론이 필수적입니다. 단순히 "모델이 잘 동작하는 것 같다"는 느낌적인 평가를 넘어, 수치화된 지표로 모델의 강점과 약점을 파악해야 합니다.
NVIDIA NeMo Evaluator는 이러한 문제를 해결하기 위한 강력한 도구입니다. OpenAI 호환 엔드포인트에 연결하여 표준 벤치마크부터 커스텀 평가까지 일관된 워크플로우로 처리할 수 있어, 반복적이고 복잡한 평가 작업을 표준화하고 자동화합니다.
이 가이드는 PAASUP DIP 환경에서 NeMo Evaluator를 활용해 LLM을 체계적으로 평가하는 방법을 단계별로 살펴보겠습니다.
NeMo Evaluator의 핵심 가치
- 표준화된 평가 프로세스: NeMo Evaluator는
Config → Target → Job구조로 평가 과정을 표준화하여, 팀 간 동일한 절차를 유지하고 실험 결과의 재현성을 보장합니다. - 풍부한 내장 벤치마크: LM Evaluation Harness 기반으로 GSM8K, MMLU, HellaSwag, IFEval 등 40개 이상의 표준 벤치마크를 즉시 사용할 수 있습니다.
- 간편한 모델 연동: OpenAI 호환 엔드포인트(NIM Proxy 등)를 Target으로 지정하면 별도 설정 없이 즉시 평가가 가능합니다.
- 운영 환경 친화적: Job 단위의 상태 관리, API 기반 결과 조회, CI/CD 파이프라인 통합 용이성을 제공합니다.
NeMo Evaluator는 NIM Proxy와 같은 OpenAI 호환 엔드포인트에 연결하여 LM Evaluation Harness 벤치마크와 커스텀 데이터 평가를 일관된 3단계(Config → Target → Job)로 실행하게 해줍니다. 결과는 API로 조회하거나 파일로 내려받아 재현 가능한 실험 관리에 유리합니다.
아키텍처 이해하기
[Evaluation job 제출] POST /v1/evaluation/jobs
│
▼
[NeMo Evaluator API] ← 평가 Config/Target 관리 · 실행 스케줄링
│
▼
[모델 추론 백엔드] ──► OpenAI 호환 /v1/chat/completions
│ └─ 모델별 엔드포인트/프롬프트/파라미터
└─ 결과 집계 · 리포트 생성
▼
결과 조회(API/다운로드)
Evaluation 워크플로우 요약
- (선택) 커스텀 데이터셋을 NeMo Data Store(NDS) 에 업로드
- NeMo Evaluator에서 Evaluation Config 생성 (벤치마크/파라미터/토크나이저 등)
- 평가 대상 Evaluation Target(모델/엔드포인트) 등록
- Evaluation Job 제출 → (a) 데이터 로딩 → (b) 모델 추론 → 결과 집계/리포트 생성
- 결과 검토
Note
이 가이드는 실제 성능 순위를 가리기 위한 문서가 아니라, NeMo Evaluator 사용법과 평가 프로세스를 이해하기 위한 실습용 가이드입니다. 본문에 등장하는 점수는 워크플로우 검증 예시이며, 프로덕션에서는 더 큰 데이터셋과 고정된 설정으로 별도 평가해야 합니다.
2. Prerequisites: 환경 구성 및 설정
이 튜토리얼은 NeMo Microservices가 배포되어 있고 접근 가능한 환경을 전제로 합니다. PAASUP DIP에서는 카탈로그를 생성하여 손쉽게 NeMo Microservices를 배포할 수 있습니다.
※ 참고: 일부 벤치마크나 토크나이저 사용 시 Hugging Face 토큰이 필요할 수 있습니다.
2.1 DIP 환경 구성
[1단계] 로그인 및 프로젝트 선택
- 목표: 사전 생성된 프로젝트와 매니저 계정으로 환경 접속
- 방법: 매니저 계정 로그인 → 프로젝트 리스트 확인 → 카탈로그 생성 메뉴 선택
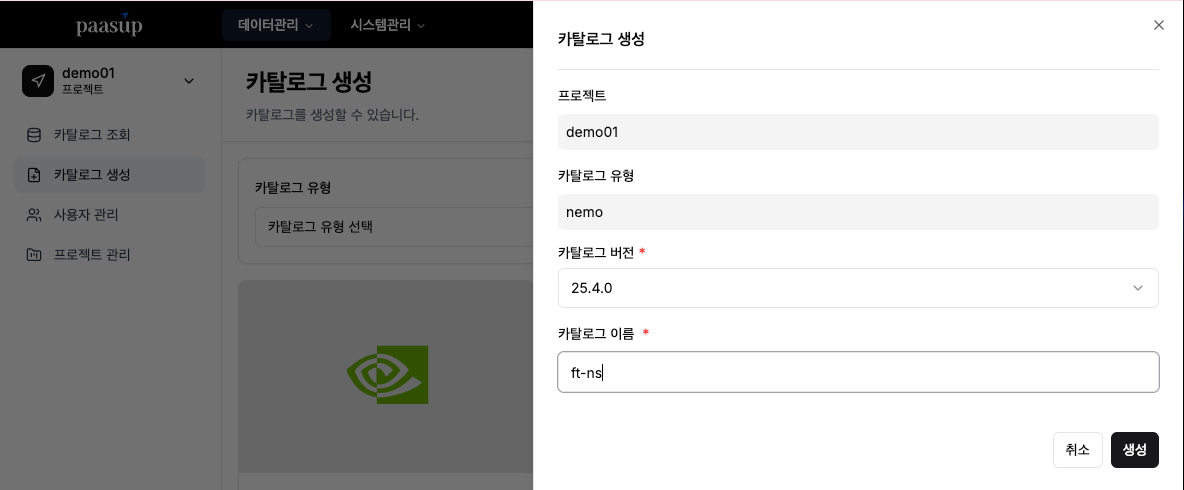
[2단계] NeMo 카탈로그 생성
- 목표: 프로젝트 전용 NeMo microservices 네임스페이스(NS) 생성 및 NeMo 연동 준비
- 방법: 카탈로그 생성 메뉴 → nemo 선택 → 버전·이름 입력 → 생성 버튼 클릭
프로젝트명-카탈로그이름형태의 프로젝트 전용 NS 생성- 예) 프로젝트명:
demo01, 카탈로그이름:eval→ 네임스페이스:demo01-eval
- 예) 프로젝트명:
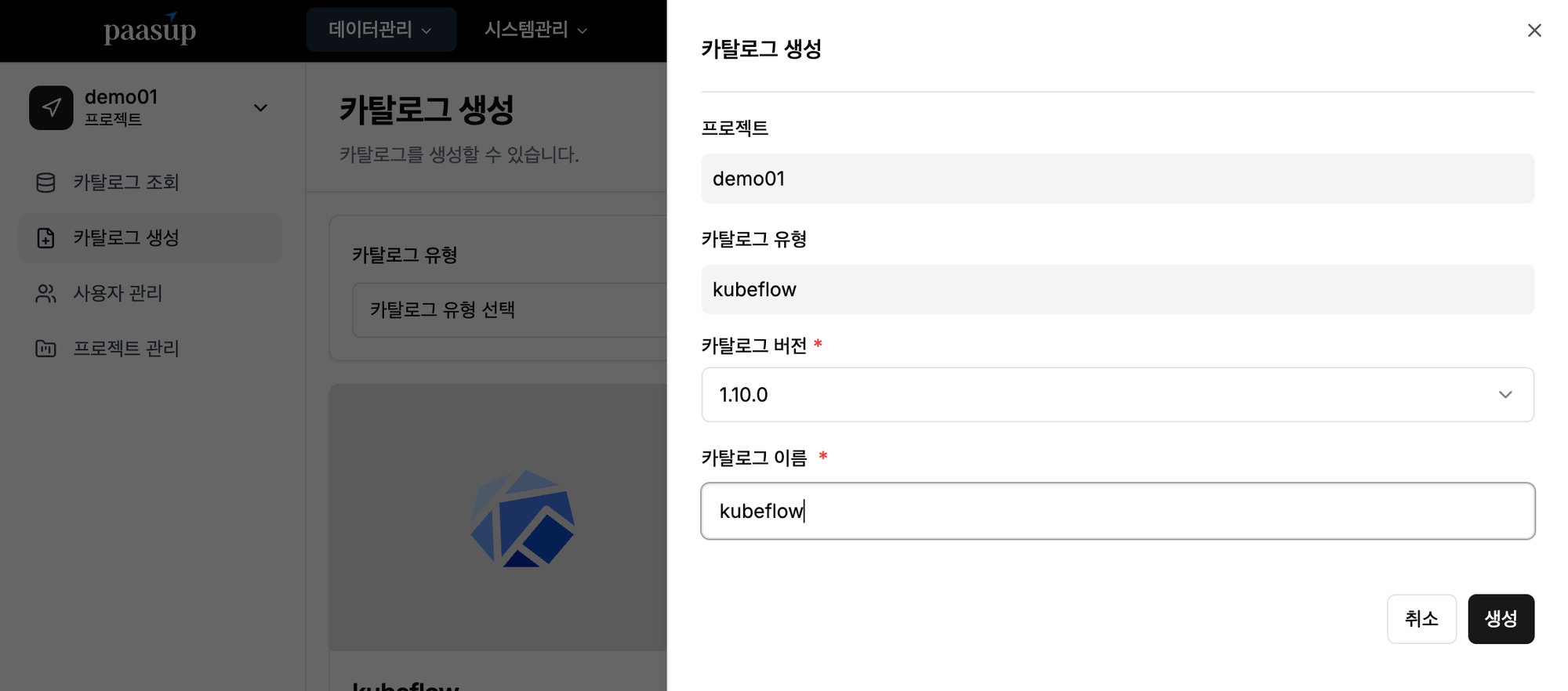
[3단계] Kubeflow 카탈로그 생성
- 목표: Jupyter Notebook 실행을 위한 Kubeflow 환경 생성
- 방법: 카탈로그 생성 메뉴 → Kubeflow 선택 → 버전·이름 입력 → 생성 버튼 클릭
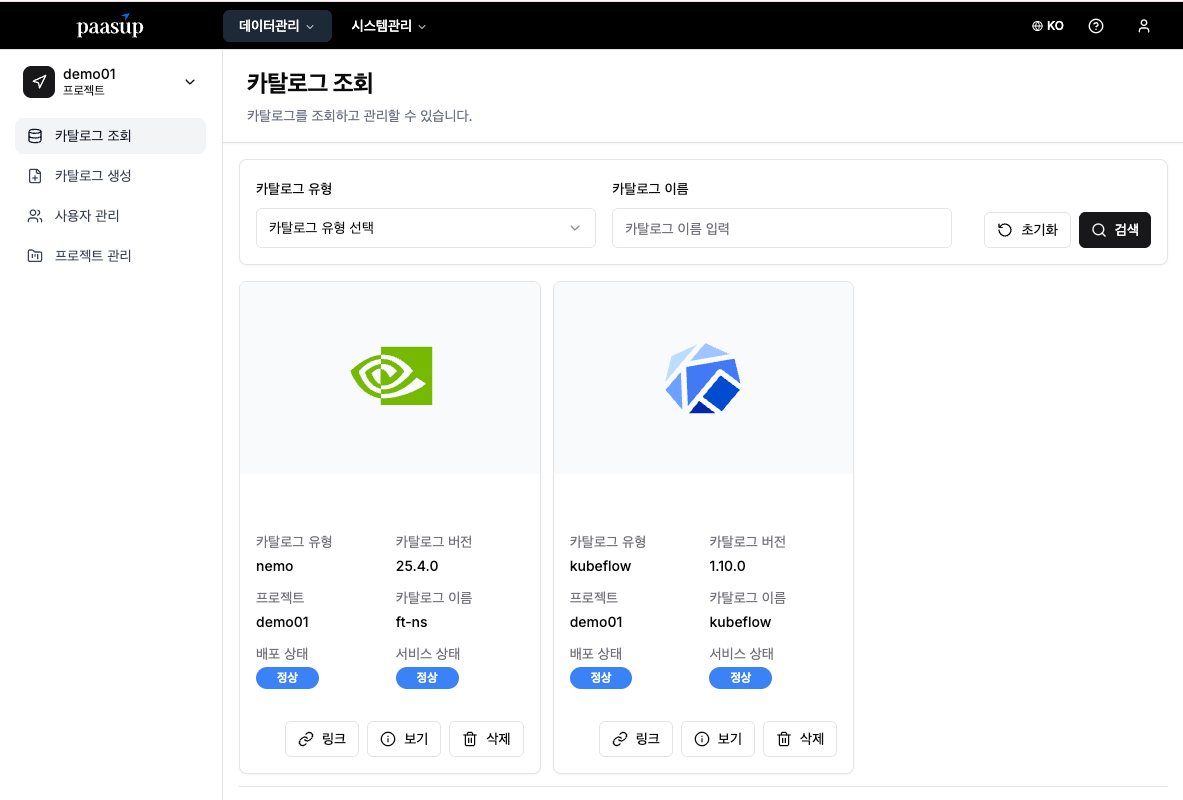
[4단계] 카탈로그 상태 확인
- 목표: 생성된 카탈로그의 배포 및 서비스 상태 확인
- 방법: 카탈로그 조회 화면에서 상태 모니터링
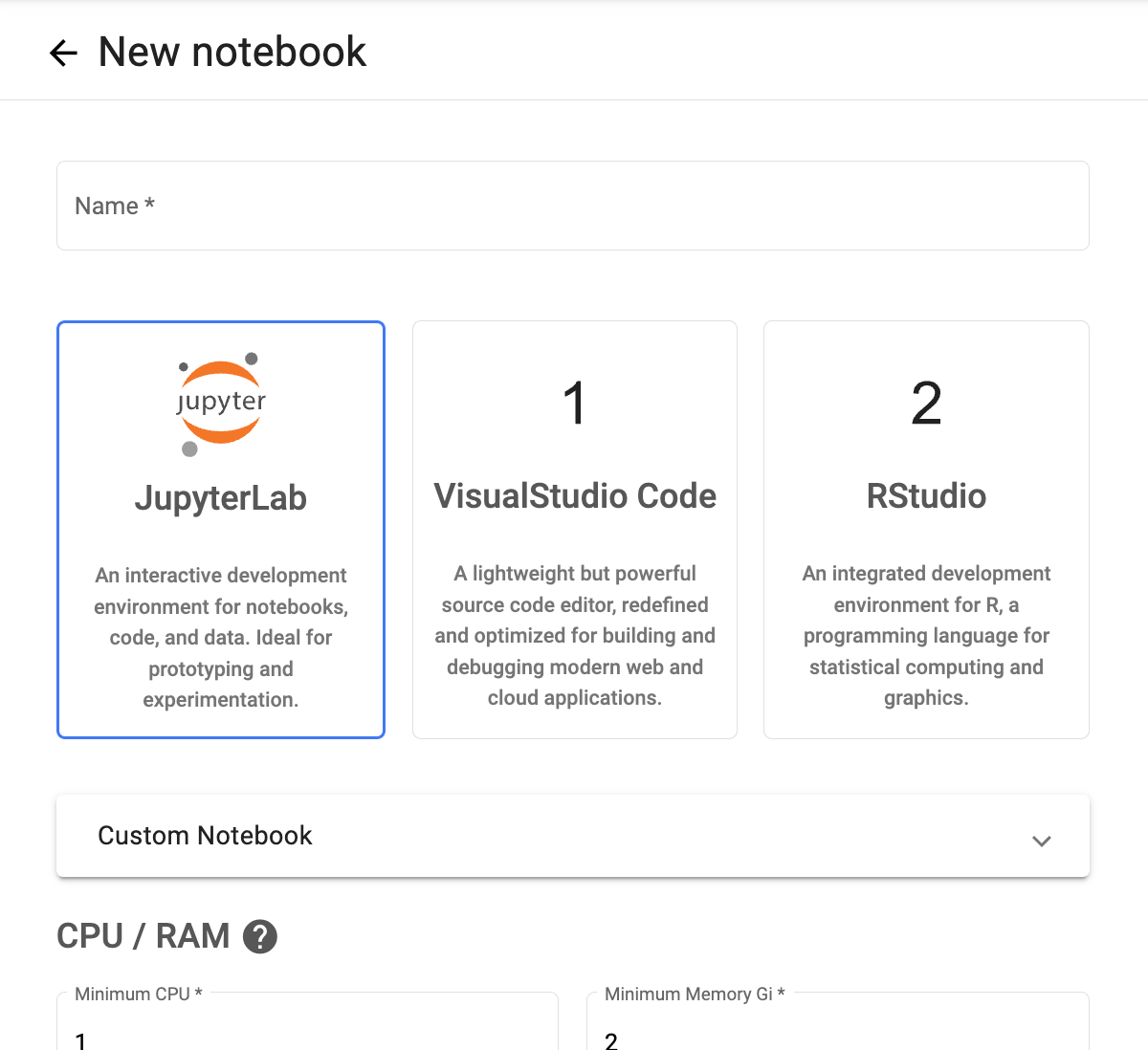
[5단계] Jupyter Notebook 환경 생성
- 목표: Python 코드 실행 환경 준비
- 방법: Kubeflow 서비스 링크 클릭 → 노트북 인스턴스 생성
[6단계] 개발 환경 접속
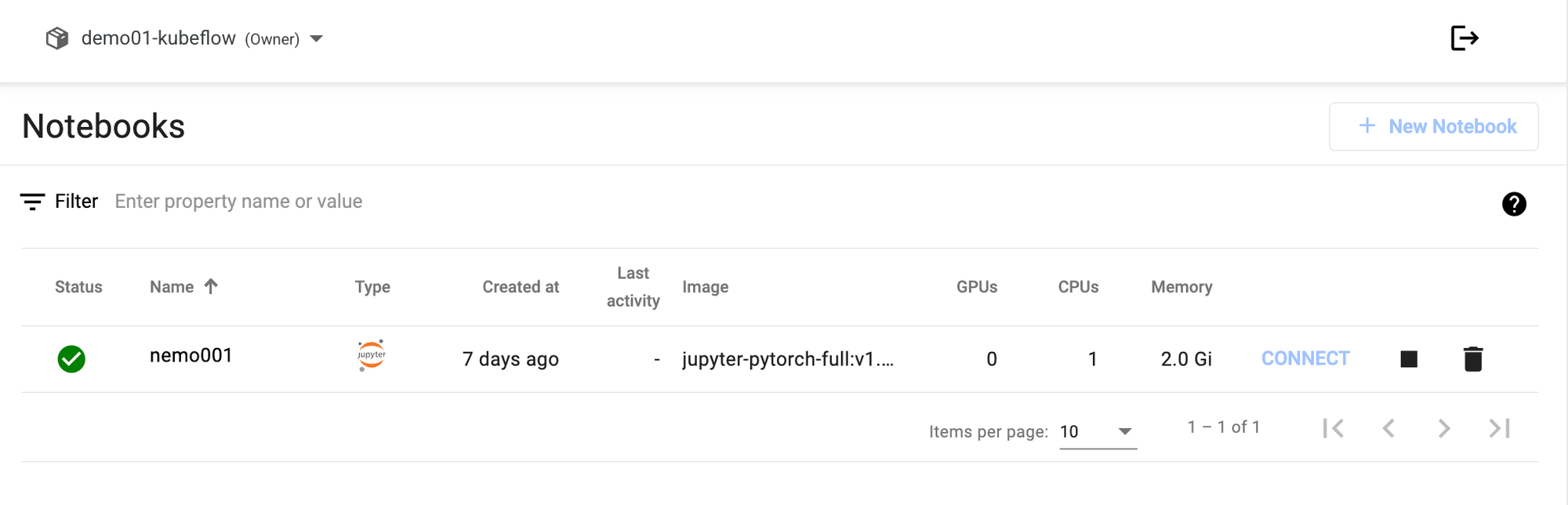
- 목표: 생성된 Notebook에 접속하여 코드 실행
- 방법: Connect 버튼 클릭 → JupyterLab 접속
2.2 환경 설정
필요 패키지를 설치하고 엔드포인트와 토큰을 환경 변수로 설정합니다.
필요 패키지 설치:
!pip install -q huggingface_hub requests
엔드포인트 & 토큰(환경변수) 설정:
import os, json, requests
from pprint import pprint
# 엔드포인트 설정
NDS_URL = "https://data-store-nemo.gke.paasup.io" # Data Store
NEMO_URL = "https://nemo-nemo.gke.paasup.io" # Customizer, Entity Store, Evaluator, Guardrails
NIM_URL = "https://nim-nemo.gke.paasup.io" # NIM Proxy
NMS_NAMESPACE = "nemo-eval-tutorial"
# API 키 설정
HF_TOKEN = "YOUR_HuggingFace_TOKEN" # HuggingFace 토큰 입력
NVIDIA_API_KEY = "YOUR_NGC_API_KEY" # NGC API 키 입력
# API 엔드포인트 구성
target_url = f"{NEMO_URL}/v1/evaluation/targets"
config_url = f"{NEMO_URL}/v1/evaluation/configs"
job_url = f"{NEMO_URL}/v1/evaluation/jobs"
llm_chat_completion_url = f"{NIM_URL}/v1/chat/completions"
2.3 (선택) NIM 배포: 평가 대상 모델 준비
모델의 NIM 서비스가 배포되지 않은 경우, 직접 배포해야 합니다. 아래는 NeMo Deployment API를 호출하여 llama-3.2-3b-instruct 모델을 배포하는 예시입니다.
※ 참고: PAASUP DIP에서 NIM 카탈로그를 생성하여 손쉽게 평가 대상 모델을 배포할 수도 있습니다.
url = f"{NEMO_URL}/v1/deployment/model-deployments"
payload = {
"name": "llama-3.2-3b-instruct",
"namespace": "meta",
"config": {
"model": "meta/llama-3.2-3b-instruct",
"nim_deployment": {
"image_name": "nvcr.io/nim/meta/llama-3.2-3b-instruct",
"image_tag": "1.10.1",
"pvc_size": "25Gi",
"gpu": 1,
"additional_envs": {
"NIM_GUIDED_DECODING_BACKEND": "outlines",
"NGC_API_KEY": NVIDIA_API_KEY,
},
"tolerations": [
{
"key": "nvidia.com/gpu",
"operator": "Equal",
"value": "present",
"effect": "NoSchedule"
}
]
}
}
}
headers = {
"accept": "application/json",
"Content-Type": "application/json",
}
resp = requests.post(url, headers=headers, json=payload)
resp.raise_for_status()
print("Create deployment response:")
print(json.dumps(resp.json(), indent=2))
3. 표준 벤치마크 평가 (LM Evaluation Harness): GSM8K 예시
NeMo Evaluator는 LM Evaluation Harness 백엔드를 통해 GSM8K, MMLU, IFEval 등 표준 벤치마크를 실행합니다. 여기서는 수학 문제 해결 능력을 측정하는 GSM8K 벤치마크를 예시로 진행합니다.
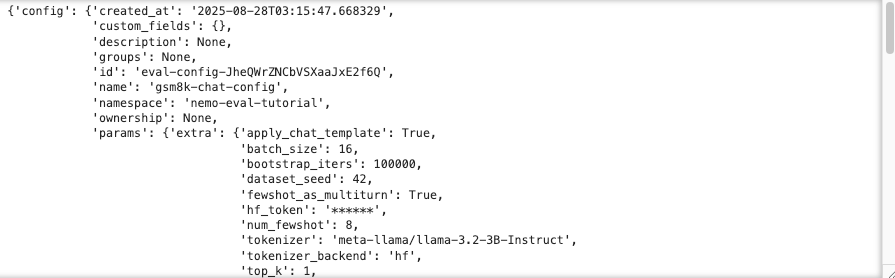
3.1 Evaluation Config 생성
GSM8K 벤치마크를 위한 평가 설정을 생성합니다.
payload = {
"type": "gsm8k",
"name": "gsm8k-chat-config",
"namespace": NMS_NAMESPACE,
"params": {
"temperature": 0.00001,
"top_p": 0.00001,
"max_tokens": 256,
"stop": ["<|eot|>"],
"extra": {
"num_fewshot": 8,
"batch_size": 16,
"bootstrap_iters": 100000,
"dataset_seed": 42,
"use_greedy": True,
"top_k": 1,
"hf_token": HF_TOKEN,
"tokenizer_backend": "hf",
"tokenizer": "meta-llama/llama-3.2-3B-Instruct",
"apply_chat_template": True,
"fewshot_as_multiturn": True
}
}
}
headers = {
"accept": "application/json",
"Content-Type": "application/json"
}
resp = requests.post(config_url, json=payload, headers=headers)
pprint(resp.json())
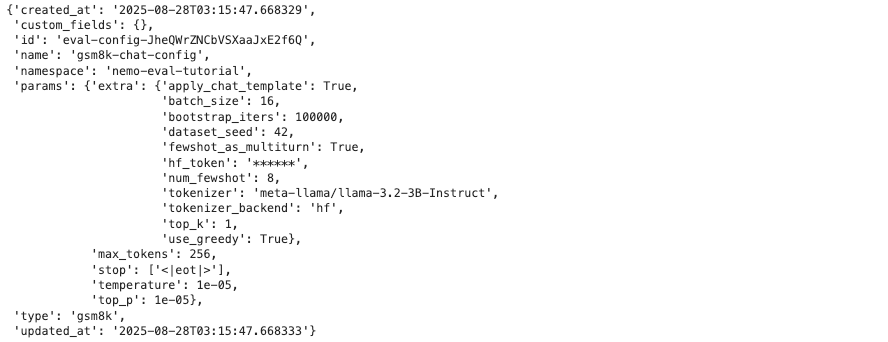
주요 파라미터 설명:
num_fewshot: 모델에게 제공할 예시 문제 개수apply_chat_template: Chat 형태 모델의 경우 적절한 템플릿 적용use_greedy: 확정적 디코딩 사용 (재현성 향상)
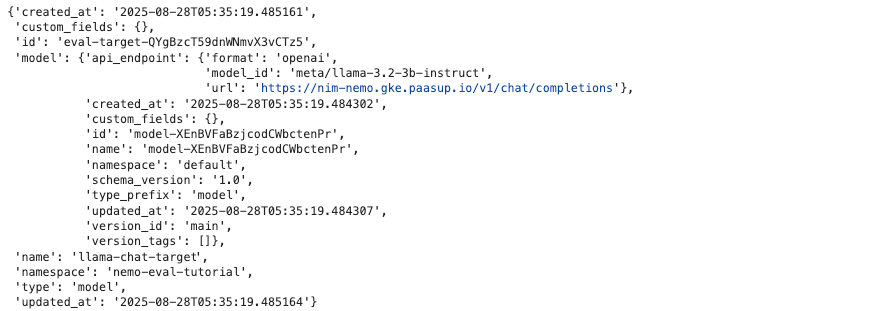
3.2 Evaluation Target 등록
평가할 모델의 엔드포인트를 Target으로 등록합니다. NIM Proxy는 OpenAI 호환 /v1/chat/completions 엔드포인트를 제공합니다.
payload = {
"type": "model",
"name": "llama-chat-target",
"namespace": NMS_NAMESPACE,
"model": {
"api_endpoint": {
"url": llm_chat_completion_url ,
"model_id": "meta/llama-3.2-3b-instruct",
"format": "openai"
}
}
}
resp = requests.post(target_url, json=payload, headers=headers)
pprint(resp.json())
3.3 Evaluation Job 실행
이제 실제 평가를 시작합니다.
# Job 생성
payload = {
"namespace": NMS_NAMESPACE,
"target": f"{NMS_NAMESPACE}/llama-chat-target",
"config": f"{NMS_NAMESPACE}/gsm8k-chat-config"
}
resp = requests.post(job_url, json=payload, headers=headers)
gsm8k_eval_job_id = resp.json()["id"]
pprint(resp.json())
Job ID 확인:
print(gsm8k_eval_job_id)
3.4 결과 확인
작업 완료 후 평가 결과를 확인합니다.
# 작업 상태 확인
resp = requests.get(f"{NEMO_URL}/v1/evaluation/jobs/{gsm8k_eval_job_id}/status")
pprint(resp.json())
# 결과 조회 (작업 완료 후)
resp = requests.get(f"{NEMO_URL}/v1/evaluation/jobs/{gsm8k_eval_job_id}/results")
pprint(resp.json()['tasks']['exact_match'])
pprint(resp.json()['tasks']['exact_match_stderr'])
결과 예시:
{'metrics': {'exact_match': {'scores': {'gsm8k-metric_ranking-1': {'value': 0.7278241091736164},
'gsm8k-metric_ranking-3': {'value': 0.7573919636087946}}}}}
{'metrics': {'exact_match_stderr': {'scores': {'gsm8k-metric_ranking-2': {'value': 0.012259714035164541},
'gsm8k-metric_ranking-4': {'value': 0.011807426004596852}}}}}

결과 지표 설명:
exact_match: 모델의 응답이 정답과 완전히 일치하는 비율을 나타냅니다. 0부터 1 사이의 값으로, 1에 가까울수록 모델의 정확도가 높다는 것을 의미합니다. GSM8K와 같은 정답이 명확한 벤치마크에서 핵심적인 성능 지표입니다.exact_match_stderr: 부트스트랩 표준오차(Standard Error) 를 의미합니다. 이는 평가 점수가 통계적으로 얼마나 신뢰할 수 있는지를 나타냅니다. 이 값이 작을수록 평가 점수가 안정적이며, 실험의 재현성이 높다고 볼 수 있습니다.
3.5 (대안) NeMo Microservices SDK 활용
NeMo Microservices SDK를 사용하면 동일한 평가를 Python 코드로 더 간결하게 실행할 수 있습니다.
NeMo Microservices SDK 클라이언트 초기화
!pip install nemo-microservices
from nemo_microservices import NeMoMicroservices
# Initialize NeMo Microservices SDK client
nemo_client = NeMoMicroservices(
base_url=NEMO_URL,
inference_base_url=NIM_URL,
)
Evaluation Config, Target, Job 생성
# Evaluation Config 생성
print("Creating evaluation config...")
eval_config = nemo_client.evaluation.configs.create(
type="gsm8k",
name="gsm8k-chat-config",
namespace=NMS_NAMESPACE,
params={...} # 위와 동일
)
print("Config created:", eval_config)
# Evaluation Target 생성
print("\nCreating evaluation target...")
eval_target = nemo_client.evaluation.targets.create(
type="model",
name="llama-chat-target",
namespace=NMS_NAMESPACE,
model={
"api_endpoint": {
"url": f"{NIM_URL}/v1/chat/completions",
"model_id": "meta/llama-3.2-3b-instruct",
"format": "openai"
}
}
)
print("Target created:", eval_target)
# Evaluation Job 실행
print("\nCreating and starting evaluation job...")
eval_job = nemo_client.evaluation.jobs.create(
config=f"{NMS_NAMESPACE}/gsm8k-chat-config",
target=f"{NMS_NAMESPACE}/llama-chat-target"
)
print("Evaluation job created:")
pprint(eval_job)
작업 상태 확인 및 결과 조회
# 작업 상태 확인
job_id = eval_job.id
print(f"\nJob ID: {job_id}")
print(f"Status: {eval_job.status}")
# 결과 확인 (작업 완료 후)
job = nemo_client.evaluation.jobs.retrieve(job_id)
print(f"Results: {job.status}")
4. Custom 평가: 사용자 정의 데이터로 평가하기
표준 벤치마크 외에도 실제 업무에 특화된 데이터로 평가할 수 있습니다. 여기서는 세 가지 평가 유형을 다룹니다.
4.1 Data Store 설정
Data Store는 Hugging Face 호환 API(/v1/hf)를 제공하여 로컬 환경에서도 HF SDK로 데이터셋을 일관되게 관리할 수 있습니다.
def setup_dataset_repo(hf_api, namespace, dataset_name, entity_host):
repo_id = f"{namespace}/{dataset_name}"
# Create the repo in datastore
hf_api.create_repo(repo_id, repo_type="dataset", exist_ok=True)
# Register dataset in entity store
entity_store_url = f"{entity_host}/v1/datasets"
payload = {
"name": dataset_name,
"namespace": namespace,
"files_url": f"hf://datasets/{repo_id}",
}
resp = requests.post(entity_store_url, json=payload)
assert resp.status_code in (200, 201, 409, 422), \
f"Unexpected response from Entity Store creating dataset: {resp.status_code}"
return repo_id
from huggingface_hub import HfApi
hf_api = HfApi(endpoint=f"{NDS_URL}/v1/hf", token="")
4.2 Similarity Metrics 평가
모델 답변이 기준 문장과 의미적으로 얼마나 유사한지 응답의 유사도를 측정하는 평가입니다. 이 가이드에서는 inputs.jsonl 데이터를 사용합니다.
데이터 형식(inputs.jsonl)
{
"prompt": "Generate a concise, engaging title for the following legal question...",
"ideal_response": "What constitutes \"doing business in a jurisdiction?\"",
"category": "summarization"
}
중요: 실제 사용 시에는 사용하려는 데이터 형식에 맞춰 Config를 구성해야 합니다. 위 예시에서는 prompt, ideal_response, category 필드를 사용했습니다.
# 평가를 위해 사전에 데이터를 ./eval_data/similarity_metrics_data 경로에 복사합니다.
# set up dataset repo
DATASET_NAME = "similarity_eval"
repo_id = setup_dataset_repo(hf_api, NMS_NAMESPACE, DATASET_NAME, NEMO_URL)
# upload dataset
hf_api.upload_file(path_or_fileobj=os.path.join("./eval_data/similarity_metrics_data", "inputs.jsonl"),
path_in_repo="similarity_metrics/inputs.jsonl",
repo_id=repo_id,
repo_type='dataset',
)
# Evaluation Config 생성
payload = {
"type": "similarity_metrics",
"name": "similarity-configuration",
"namespace": NMS_NAMESPACE,
"params": {
"max_tokens": 200,
"temperature": 0.7,
"extra": {
"top_k": 20
}
},
"tasks": {
"my-similarity-metrics-task": {
"type": "default",
"dataset": {
"files_url": f"hf://datasets/{NMS_NAMESPACE}/{DATASET_NAME}/similarity_metrics/inputs.jsonl",
},
"metrics": {
"accuracy": {"type": "accuracy"},
"bleu": {"type": "bleu"},
"rouge": {"type": "rouge"},
"em": {"type": "em"},
"f1": {"type": "f1"}
}
}
}
}
headers = {
"accept": "application/json",
"Content-Type": "application/json"
}
resp = requests.post(config_url, json=payload, headers=headers)
pprint(resp.json())
# Evaluation Job 실행 (기존 Target 재사용)
payload = {
"namespace": NMS_NAMESPACE,
"target": f"{NMS_NAMESPACE}/llama-chat-target",
"config": f"{NMS_NAMESPACE}/similarity-configuration"
}
resp = requests.post(job_url, json=payload, headers=headers)
similarity_eval_job_id = resp.json()["id"]
print(f"Similarity 평가 Job ID: {similarity_eval_job_id}")
결과 예시:
{'metrics': {'accuracy': {'scores': {'accuracy': {'value': 0.0}}},
'bleu': {'scores': {'bleu_score': {'value': 0.05173803611625177}}},
'em': {'scores': {'em': {'value': 0.0}}},
'f1': {'scores': {'f1': {'value': 0.12767470937400338}}},
'rouge': {'scores': {'rouge_1_score': {'value': 0.16589508703646286},
'rouge_2_score': {'value': 0.041384897021262586},
'rouge_3_score': {'value': 0.012798291518797661},
'rouge_L_score': {'value': 0.13521365193481227}}}}}
결과 지표 설명:
accuracy: 모델의 응답이 정답과 문자열로 완전히 일치하는 비율입니다. 텍스트 생성 모델의 특성상 정답과 완벽히 동일한 응답을 내놓는 경우가 드물어 일반적으로 낮은 점수가 나올 수 있습니다.bleu_score: 모델 응답과 정답 간의 단어 중복도를 측정합니다. 주로 기계 번역 모델 평가에 사용되며, 0에서 1 사이의 값으로 점수가 높을수록 참조 문장과 유사함을 나타냅니다.em: 정확한 문자열 매칭 비율을 나타냅니다.f1: 모델 응답이 정답의 핵심 단어를 얼마나 포함하고 있는지를 정밀도(Precision)와 재현율(Recall)의 조화평균으로 계산합니다. 답변의 내용적 충실도를 평가하는 데 유용합니다.rouge: 주로 텍스트 요약 성능을 평가하는 데 사용되는 지표입니다. 모델 응답이 정답의 정보를 얼마나 잘 포함하고 있는지를 측정하며, ROUGE-1(단어), ROUGE-2(두 단어), ROUGE-L(가장 긴 공통 부분 문자열) 등 다양한 방식으로 유사도를 측정합니다.
4.3 Tool Calling 평가
모델의 도구(함수명/인자) 선택이 사양에 맞게 호출되는지 평가합니다. 이 가이드에서는 aiva_tool_call.jsonl 데이터를 사용합니다.
**데이터 형식(aiva_tool_call.jsonl): **
{
"messages": [
{
"role": "user",
"content": "Find the area of a triangle with a base of 10 units and height of 5 units."
}
],
"tools": [
{
"type": "function",
"function": {
"name": "calculate_triangle_area",
"description": "Calculate the area of a triangle given its base and height.",
"parameters": {
"type": "object",
"properties": {
"base": {"type": "integer", "description": "The base of the triangle."},
"height": {"type": "integer", "description": "The height of the triangle."}
},
"required": ["base", "height"]
}
}
}
],
"tool_calls": [
{
"function": {
"name": "calculate_triangle_area",
"arguments": {"base": 10, "height": 5, "unit": "units"}
}
}
]
}
중요: 실제로는 사용하려는 Tool Calling 데이터 구조에 맞춰 Config를 조정해야 합니다. 예를 들어 user_query, available_functions, expected_calls 등 다른 필드명을 사용한다면, Config 템플릿의 {{item.messages}} 부분을 {{item.user_query}}로 변경해야 합니다.
config_payload = {
"type": "custom",
"namespace": NMS_NAMESPACE,
"name": "tool-call-eval-config",
"tasks": {
"custom-tool-calling": {
"type": "chat-completion",
"dataset": {
"files_url": f"hf://datasets/{NMS_NAMESPACE}/{DATASET_NAME}/aiva_tool_call.jsonl",
},
"params": {
"template": {
"messages": "{{ item.messages | tojson}}",
"tools": "{{ item.tools | tojson }}",
"tool_choice": "auto"
}
},
"metrics": {
"tool-calling-accuracy": {
"type": "tool-calling",
"params": {"tool_calls_ground_truth": "{{ item.tool_calls | tojson }}"}
}
}
}
}
}
headers = {
"accept": "application/json",
"Content-Type": "application/json"
}
resp = requests.post(config_url, json=config_payload, headers=headers)
pprint(resp.json())
결과 예시:
{'tool-calling-accuracy': {'scores': {'function_name_accuracy': {'stats': {'count': 10,
'mean': 0.7,
'sum': 7.0},
'value': 0.7},
'function_name_and_args_accuracy': {'stats': {'count': 10,
'mean': 0.0,
'sum': 0.0},
'value': 0.0}}}}
결과 지표 설명:
function_name_accuracy: 모델이 올바른 함수명을 호출한 비율입니다. 이는 사용자의 의도에 맞춰 적절한 도구를 선택했는지를 평가하는 지표입니다.function_name_and_args_accuracy: 모델이 올바른 함수명과 함께 모든 필수 인자(arguments)를 정확하게 전달한 비율입니다. 이 지표는 모델이 도구의 사용법을 완전히 이해하고 필요한 정보를 정확히 추출했는지 평가하는 데 사용됩니다.
4.4 LLM-as-Judge 평가
객관식 정답이 없고, 품질/충실도를 사람 대신 LLM으로 심사할 때, 다른 LLM을 심사 모델로 사용하여 주관적 품질을 평가합니다. 이 가이드에서는 math_dataset.csv 데이터를 사용합니다.
데이터 형식(math_dataset.csv):
| id | question | answer | reference_answer |
|---|---|---|---|
| 0 | What is 4+8? | 12 | The answer is 12 |
| 1 | Square root of 144? | 12 | The answer is 12 |
중요: 실제로는 사용하려는 CSV 컬럼명에 맞춰 Config를 설정해야 합니다. 예를 들어 query, expected_output, ground_truth 등의 컬럼명을 사용한다면, 아래 Config에서 {{item.question}}을 {{item.query}}로, {{item.reference_answer}}를 {{item.ground_truth}}로 변경해야 합니다.
payload = {
"type": "custom",
"namespace": NMS_NAMESPACE,
"name": "custom_llm_as_judge_config",
"tasks": {
"qa": {
"type": "completion",
"params": {
"template": {
"messages": [{
"role": "system",
"content": "You are a helpful, respectful and honest assistant. \nAnswers the following question as briefly as you can.\n."
},
{
"role": "user",
"content": "Answer very briefly (no explanation) this question: {{item.question}}"
}]
}
},
"metrics": {
"accuracy": {
"type": "string-check",
"params": {
"check": [
"{{sample.output_text}}",
"contains",
"{{item.answer}}"
]
}
},
"bleu": {
"type": "bleu",
"params": {
"references": [
"{{item.reference_answer}}"
]
}
},
"accuracy-llm-judge": {
"type": "llm-judge",
"params": {
"model": {
"api_endpoint": {
"url": "https://integrate.api.nvidia.com/v1/chat/completions",
"model_id": "meta/llama-3.3-70b-instruct",
"api_key": NVIDIA_API_KEY
}
},
"template": {
"messages": [
{
"role": "system",
"content": "Your task is to evaluate the semantic similarity between two responses."
},
{
"role": "user",
"content": (
"Respond in the following format SIMILARITY: 4. "
"The similarity should be a score between 0 and 10.\n\n"
"RESPONSE 1: {{item.reference_answer}}\n\n"
"RESPONSE 2: {{sample.output_text}}.\n\n"
)
}
]
},
"scores": {
"similarity": {
"type": "int",
"parser": {
"type": "regex",
"pattern": "SIMILARITY: (\\d)"
}
}
}
}
}
},
"dataset": {
"files_url": f"hf://datasets/{NMS_NAMESPACE}/{DATASET_NAME}/llm_as_judge/math_dataset.csv"
}
}
}
}
headers = {
"accept": "application/json",
"Content-Type": "application/json"
}
resp = requests.post(config_url, json=payload, headers=headers)
pprint(resp.json())
주요 설정 포인트:
{{item.question}}: CSV의 'question' 컬럼 참조{{item.answer}}: CSV의 'answer' 컬럼 참조{{item.reference_answer}}: CSV의 'reference_answer' 컬럼 참조{{sample.output_text}}: 모델의 실제 응답- 이 예시에서는 build.nvidia.com에서 호스팅되는 llama-3.3-70b-instruct 모델을 심사 모델로 사용
결과 예시:
{'metrics': {'accuracy': {'scores': {'string-check': {'stats': {'count': 4,
'mean': 1.0,
'sum': 4.0},
'value': 1.0}}},
'accuracy-llm-judge': {'scores': {'similarity': {'stats': {'count': 4,
'mean': 1.0,
'sum': 4.0},
'value': 1.0}}},
'bleu': {'scores': {'corpus': {'value': 0.0},
'sentence': {'stats': {'count': 4,
'mean': 4.9787068367863965,
'sum': 19.914827347145586},
'value': 4.9787068367863965}}}}}
결과 지표 설명:
string-check: 모델의 응답에 특정 문자열이 포함되었는지 확인하는 간단한 True/False 기반의 평가입니다.similarity: 심사 모델(LLM-as-Judge)이 평가 대상 모델의 응답과 정답 간의 의미적 유사성을 평가하여 매긴 점수입니다. 주관적인 품질 평가를 객관화할 수 있는 강력한 지표입니다.bleu: LLM 심사 평가에서도 사용될 수 있는 지표로, 생성된 텍스트가 정답과 얼마나 유사하게 표현되었는지 확인하는 데 사용됩니다.
5. 효과적인 평가를 위한 가이드
5.1 평가 목적에 맞는 벤치마크 선택
- 기본 능력 검증: 새로운 모델의 전반적인 성능을 확인할 때는 MMLU(다학제 지식)와 HellaSwag(상식 추론)를 먼저 실행합니다. 수학적 사고력이 중요하다면 GSM8K와 MATH 벤치마크를 활용하세요.
- 특정 용도 검증: 코딩 어시스턴트 개발 시에는 HumanEval, MBPP를, 안전한 서비스 구축 시에는 TruthfulQA, RealToxicityPrompts를, 명령어 수행 능력 확인에는 IFEval을 사용합니다.
5.2 데이터 품질 관리
- 표준 벤치마크 사용 시: 평가 조건을 동일하게 유지하여 다른 연구 결과와 비교 가능하도록 설정합니다. few-shot 예시 개수, 온도값 등 하이퍼파라미터를 일관되게 관리하는 것이 중요합니다.
- 커스텀 데이터 준비 시: 실제 사용 시나리오를 반영한 데이터로 구성하고, 편향되지 않은 균형 잡힌 샘플을 선택하며, 정답 레이블의 정확성과 일관성을 확보해야 합니다.
5.3 결과 해석과 활용
- 통계적 신뢰성: 단일 실행보다는 여러 번 실행하여 안정성을 확인하고, 표준오차를 함께 보고하여 결과의 불확실성을 표현합니다.
- 비교 분석: 베이스라인 모델과의 성능 차이를 측정하고, 파인튜닝 전후 성능 변화를 추적하며, 여러 모델 간의 강점과 약점을 비교 분석합니다.
5.4 실무 적용 고려사항
- 평가 환경 일치: 실제 서비스 환경과 동일한 조건에서 평가를 수행하고, 응답 시간과 리소스 사용량도 함께 모니터링합니다.
- 지속적인 모니터링: 모델 업데이트 시마다 정기적인 평가를 실행하여 성능 저하나 편향성 증가 등의 문제를 조기에 발견해야 합니다.
6. 마치며
지금까지 NeMo Evaluator를 활용해 LLM을 평가하는 엔드투엔드 과정을 살펴보았습니다. 표준 벤치마크부터 사용자 정의 데이터, 그리고 LLM-as-Judge와 같은 고급 평가 기법까지, NeMo Evaluator가 제공하는 강력한 기능들을 직접 경험해 보셨을 것입니다.
이 가이드는 단순한 도구 사용법을 넘어, 체계적인 LLM 평가 방법론을 구축하는 중요성을 강조합니다. 모델 개발은 한 번의 파인튜닝으로 끝나지 않습니다. 지속적인 성능 모니터링과 다양한 관점에서의 평가를 통해 모델의 잠재력을 최대한 끌어올려야 합니다.
PAASUP DIP 환경은 NeMo Microservices를 손쉽게 배포하고, 이 가이드의 모든 실습 과정을 따라 해볼 수 있는 최적의 환경을 제공합니다. 이제 여러분은 NeMo Evaluator를 활용하여 모델의 성능을 정량화하고, 개발 프로세스에 신뢰성을 더할 수 있습니다. 체계적인 평가를 통해 더 나은 LLM 솔루션을 구축하고, 여러분의 AI 프로젝트를 한 단계 더 발전시켜 보세요.