
NeMo Framework와 NeMo Microservices 개요
대규모 AI 모델 개발부터 배포까지 모든 과정을 지원하는 NVIDIA NeMo 플랫폼의 완전 가이드를 소개합니다. 연구용 NeMo Framework와 엔터프라이즈용 NeMo Microservices의 차이점과 파스업DIP에서의 실제 활용 방법을 알아보세요.
들어가며
AI 기술의 급속한 발전과 함께, 대규모 언어 모델(LLM)과 멀티모달 AI 모델의 개발 및 운영이 기업과 연구기관의 핵심 관심사로 떠올랐습니다. 하지만 이러한 모델들을 실제 프로덕션 환경에서 안정적으로 개발하고 배포하기 위해서는 강력한 플랫폼이 필요합니다.
NVIDIA는 이러한 요구에 부응하여 NeMo라는 포괄적인 AI 플랫폼을 선보였습니다. NeMo는 연구자부터 엔터프라이즈 개발팀까지 모든 사용자의 요구를 충족시키는 두 가지 핵심 구성 요소로 나뉩니다:
- NeMo Framework: 모델 개발과 실험을 위한 오픈소스 개발 환경
- NeMo Microservices: 프로덕션 배포를 위한 엔터프라이즈 플랫폼
이번 시리즈에서는 NeMo 플랫폼의 전반적인 소개부터 파스업DIP에서의 실제 활용 예시까지 다뤄보겠습니다.
NeMo Framework vs NeMo Microservices: 핵심 차이점
두 플랫폼의 주요 특징을 한눈에 비교해보면 다음과 같습니다:
| 구분 | NeMo Framework | NeMo Microservices |
|---|---|---|
| 목적 | 모델 연구 개발 및 커스텀 아키텍처 구현 | 엔터프라이즈급 모델 커스터마이징 및 운영 |
| 주요 사용자 | 연구자, ML 엔지니어 | 앱 개발자, 엔터프라이즈 배포팀 |
| 개발 방식 | Python 기반 라이브러리 | REST/gRPC 기반 마이크로서비스 |
| 실행 환경 | Jupyter, Python 스크립트 | Docker, Kubernetes |
| 활용 예시 | 학습 스크립트 실행, 실험 | 챗봇 /chat, 문서요약 /summarize API |
| 출시 상태 | 오픈소스 (GitHub) | 2025년 4월 정식 출시 (GA) |
NeMo Framework: 연구자와 개발자를 위한 커스텀 AI 모델 개발 환경
플랫폼 개요
NeMo Framework는 PyTorch 기반의 오픈소스 개발 플랫폼으로, 다양한 AI 모델을 커스텀하게 개발할 수 있도록 설계되었습니다. GitHub에서 무료로 제공되며, 연구 목적부터 초기 프로토타이핑까지 광범위하게 활용 가능합니다.
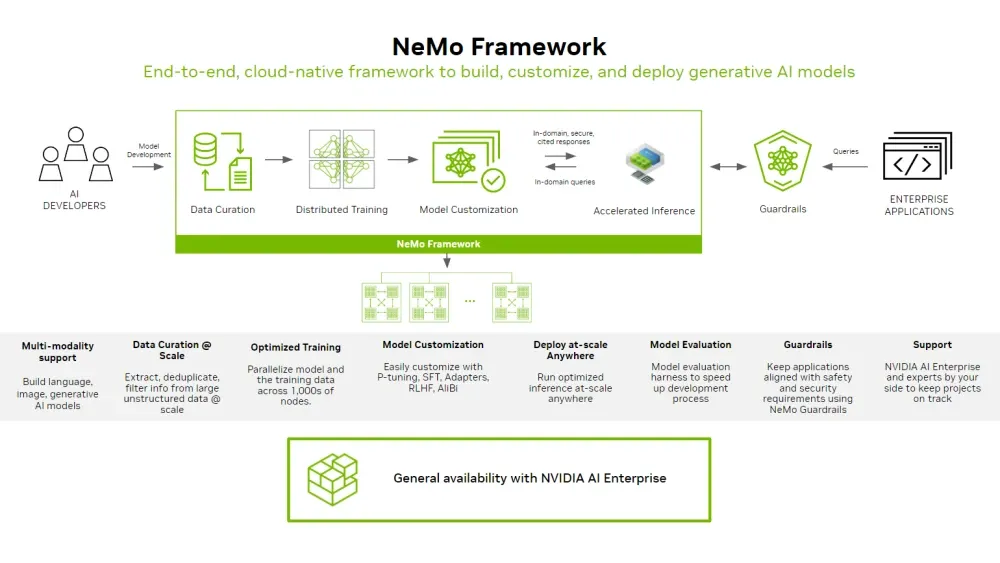
이미지 출처: NVIDIA NeMo Framework
2025년 NeMo Framework 2.0 주요 업데이트
NeMo 2.0 릴리즈는 API에 중요한 변경 사항을 도입하고 새로운 라이브러리인 NeMo Run을 선보였습니다. 주요 업데이트 사항은 다음과 같습니다:
NVIDIA Cosmos 지원
NeMo Framework는 이제 NVIDIA Cosmos 컬렉션의 세계 기초 모델들의 훈련과 커스터마이징을 지원합니다. Cosmos는 텍스트 입력을 기반으로 다양한 modality(예: 비디오, 오디오, 이미지)를 생성할 수 있는 멀티모달 생성 모델을 지원합니다.
통합 컨테이너 환경
NeMo Framework는 이제 대규모 언어 모델(LLM), 멀티모달(MM), 자동 음성 인식(ASR), 텍스트-투-스피치(TTS)를 단일 통합 컨테이너에서 지원합니다.
최적화된 성능
Megatron-style tensor/sequence/ pipeline 병렬화 및 FlashAttention 기반 어텐션 최적화 기법을 적용하여 고급 생성 AI 모델 훈련을 위한 최적의 성능을 제공합니다.
지원 모델 컬렉션
NeMo Framework는 컬렉션 기반 아키텍처를 통해 다음과 같은 AI 모델들을 지원합니다:
NLP (Natural Language Processing)
- 대규모 언어 모델 (LLM)
- 텍스트 분류, 감정 분석
- 질의응답 시스템
- Llama, Mistral, Gemma 시리즈 모델
ASR (Automatic Speech Recognition)
- 다국어 음성 인식
- 실시간 STT (Speech-to-Text)
- 노이즈 제거 기능
- AED 멀티태스크 모델 (Canary)
TTS (Text-to-Speech)
- 자연스러운 음성 합성
- 다양한 보코더 지원
- 스피커 적응 기능
Multimodal
- 이미지-텍스트 연동 모델
- 비디오-텍스트 처리
- 멀티모달 생성 AI
- Cosmos 비디오 파운데이션 모델
최신 기술 지원
NeMo Framework는 대규모 AI 모델 학습의 효율성을 높이는 최신 기술들을 제공합니다:
FSDP (Fully Sharded Data Parallel) 메모리 효율적인 분산 학습을 통해 대규모 AI 모델 훈련의 효율성을 개선합니다
MoE (Mixture of Experts) 전문가 혼합 기반 LLM 아키텍처를 지원하여 모델 성능을 향상시킵니다
고성능 데이터 처리 NeMo Curator는 고처리량 데이터 큐레이션, 효율적인 멀티모달 데이터 로딩 기능, 확장 가능한 모델 훈련, 그리고 병렬화된 인프레임워크 추론을 포함합니다
실제 사용 예시
LLM 모델 활용
# mistral_7b_instruct 모델을 커스텀 데이터로 파인튜닝하는 예시
import nemo_run as run
from nemo.collections.llm import api
data_config = {
"train_ds": {"file_path": "train.jsonl"},
"validation_ds": {"file_path": "val.jsonl"}
}
trainer_config = {
"max_steps": 1000,
"val_check_interval": 100,
"devices": 1,
"accelerator": "gpu"
}
# Recipe: 파인튜닝에 필요한 설정 정의
recipe = run.Partial(
api.finetune,
model="mistral_7b_instruct",
data=data_config,
trainer=trainer_config,
optim={"lr": 1e-5}
)
# 정의된 Recipe 실행
run.run(recipe)
음성 인식 (ASR) 활용
# 사전 훈련된 QuartzNet 모델로 음성 파일을 텍스트로 변환하는 예시
import nemo_run as run
from nemo.collections.asr import api
# 음성 인식을 위한 Recipe 정의
asr_recipe = run.Partial(
api.transcribe,
model="stt_en_quartznet15x5",
audio_files=["audio_file.wav"],
output_dir="./transcriptions"
)
# 음성 인식 Recipe 실행
transcription_results = run.run(asr_recipe)
# --- 또는 NeMo Run 라이브러리 없이 직접 API를 사용하는 경우 ---
from nemo.collections.asr.api import transcribe
# transcribe 함수를 직접 호출하여 음성 인식 수행
results = transcribe(
model="stt_en_quartznet15x5",
audio_files=["audio_file.wav"]
)
음성 합성 (TTS) 활용
# 사전 훈련된 FastPitch 모델로 텍스트를 음성 파일로 변환하는 예시
import nemo_run as run
from nemo.collections.tts import api
# 음성 합성을 위한 Recipe 정의
tts_recipe = run.Partial(
api.synthesize,
model="tts_en_fastpitch",
text="Hello, this is NeMo TTS!",
output_dir="./audio_output"
)
# 음성 합성 Recipe 실행
audio_output = run.run(tts_recipe)
# --- 또는 NeMo Run 라이브러리 없이 직접 API를 사용하는 경우 ---
from nemo.collections.tts.api import synthesize
# synthesize 함수를 직접 호출하여 음성 합성 수행
audio = synthesize(
model="tts_en_fastpitch",
text="Hello, this is NeMo TTS!",
output_format="wav"
)
NeMo Microservices: 엔터프라이즈급 AI 모델 운영 플랫폼
플랫폼 개요
2025년 4월 정식 출시된 NeMo Microservices는 엔터프라이즈 환경에서 대규모 AI 모델을 안정적으로 배포하고 운영할 수 있도록 설계된 플랫폼입니다. REST API 기반 마이크로서비스 아키텍처를 통해 Kubernetes에서의 확장성과 관리 용이성을 제공합니다.
NeMo Microservices는 NeMo Framework나 Hugging Face에서 직접 학습한 모델을 배포하는 구조가 아닙니다. 대신, NVIDIA API Catalog에 등록된 NIM 기반 사전 최적화 모델을 선택한 후, 해당 모델을 사용자 도메인에 맞게 커스터마이징(예: SFT, LoRA)하고, 결과 모델은 NIM 형태로 다시 패키징되어 배포됩니다.
이를 통해 기업은 NVIDIA의 고성능 모델을 신뢰성 있게 도메인 특화하여 활용할 수 있습니다.
핵심 구성 요소
NeMo Microservices는 기업이 AI 모델을 대규모로 파인튜닝, 평가, 보안 및 배포할 수 있도록 하는 모듈형 프로덕션 중심 도구입니다. 세 가지 핵심 구성 요소는 다음과 같습니다:
NeMo Customizer
- AI 모델의 파인튜닝 및 커스터마이징
- LoRA, QLoRA 등 효율적인 학습 기법 지원
- 자동화된 하이퍼파라미터 튜닝
NeMo Evaluator
- 모델 성능 체계적 평가
- 벤치마킹 및 A/B 테스트
- 지속적인 모델 개선 지원
NeMo Guardrails
- AI 모델 안전성 보장
- 윤리적 AI 사용 환경 구축
- 거버넌스 및 컴플라이언스 관리
추가 마이크로서비스 구성 요소
NeMo Microservices 플랫폼은 다음과 같은 추가 구성 요소들을 포함합니다:
NVIDIA NeMo Data Store
- NeMo 마이크로서비스 플랫폼의 기본 파일 저장소 솔루션
- Hugging Face Hub 클라이언트(HfApi)와 호환되는 API 제공
NVIDIA NeMo Entity Store
- 네임스페이스, 프로젝트, 데이터셋, 모델 등 일반적인 엔터티 관리 도구
NVIDIA NeMo Deployment Management
- Kubernetes 클러스터에서 NIM 배포 API 제공
- NIM Operator 마이크로서비스를 통한 관리
NVIDIA NeMo NIM Proxy
- 모든 배포된 NIM에 대한 추론 작업 접근을 위한 통합 엔드포인트
데이터 플라이휠 아키텍처
NeMo Microservices의 핵심 강점 중 하나는 데이터 플라이휠 아키텍처입니다. 이는 모델 배포 후에도 다음과 같은 순환 구조를 통해 지속적인 최적화를 가능하게 합니다:
- 실시간 데이터 수집 → 사용자 피드백 및 모델 성능 데이터 수집
- 데이터 분석 → 수집된 데이터를 통한 모델 성능 분석
- 모델 개선 → 분석 결과를 바탕으로 한 모델 재학습
- 배포 및 모니터링 → 개선된 모델의 프로덕션 배포
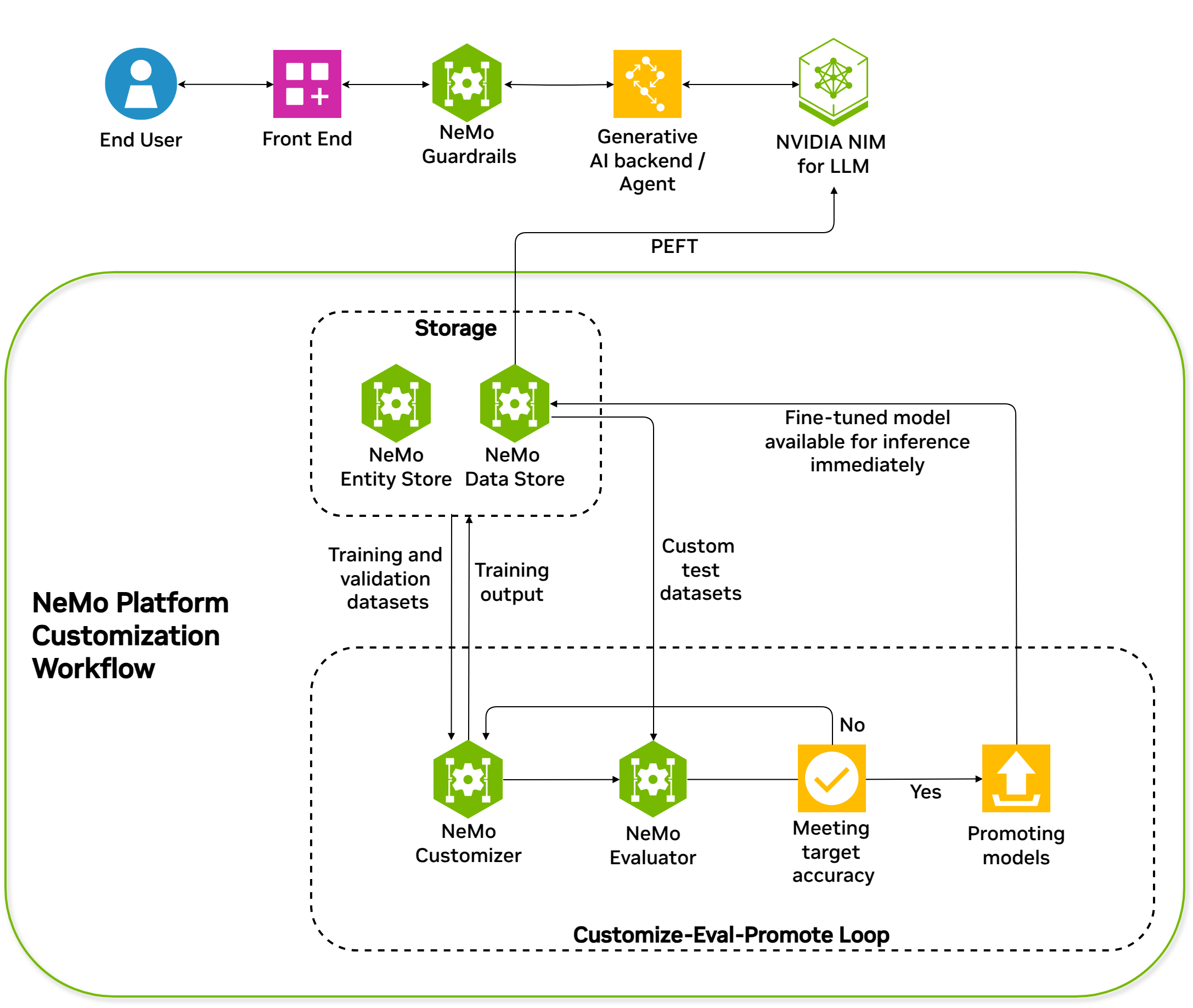
이미지 출처: NVIDIA NeMo Framework
실제 사용 예시
모델 파인튜닝 작업 요청
import requests
# 설정 정보
NMS_NAMESPACE = "your_org_namespace"
BASE_MODEL = "llama-3-8b-instruct"
DATASET_NAME = "your_custom_dataset"
NEMO_URL = "YOUR_NEMO_MICROSERVICES_ENDPOINT"
# 파인튜닝 파라미터 설정
training_params = {
"name": "llama-3-8b-instruct-sft-lora",
"output_model": f"{NMS_NAMESPACE}/llama-3-8b-instruct-sft-lora-model",
"config": BASE_MODEL,
"dataset": {"name": DATASET_NAME, "namespace": NMS_NAMESPACE},
"hyperparameters": {
"training_type": "sft", # Supervised Fine-Tuning
"finetuning_type": "lora", # LoRA 방식
"epochs": 2,
"batch_size": 16,
"learning_rate": 0.0001,
"lora": {
"adapter_dim": 32,
"adapter_dropout": 0.1
}
}
}
# API 요청 전송
response = requests.post(
f"{NEMO_URL}/v1/customization/jobs",
json=training_params
)
모델 평가 작업
# 모델 성능 평가 요청
evaluation_params = {
"model_name": "llama-3-8b-instruct-sft-lora",
"evaluation_dataset": "benchmark_dataset",
"metrics": ["accuracy", "bleu", "rouge"],
"evaluation_type": "automated"
}
eval_response = requests.post(
f"{NEMO_URL}/v1/evaluation/jobs",
json=evaluation_params
)
NIM과의 관계
NeMo Microservices는 NIM(NVIDIA Inference Microservices) 과 상호 보완적인 역할을 수행합니다:
NIM의 역할
- 추론 특화: 최적화된 모델 서빙에 집중
- 성능 최적화: TensorRT를 통한 추론 성능 극대화
- 빠른 배포: 사전 최적화된 모델의 즉시 배포
NeMo Microservices의 역할
- 모델 개선: 데이터 준비, 학습, 평가에 집중
- 커스터마이징: 기존 모델의 도메인 특화 적응
- 안전성 관리: 모델 거버넌스 및 안전성 보장
현재 NeMo Microservices는 주로 NVIDIA API Catalog에 등록된 NIM 기반 모델들과의 연동에 최적화되어 있으며, 다음과 같은 워크플로우를 통해 구현됩니다:
- 베이스 모델 선택 → NVIDIA API Catalog에서 NIM 지원 모델 선택
- 커스터마이징 → NeMo Microservices를 통한 도메인 특화 파인튜닝
- 배포 → 커스터마이징된 모델의 NIM 기반 프로덕션 배포
- 운영 → 지속적인 모니터링 및 개선
파스업DIP 플랫폼에서의 NeMo 활용
DIP 플랫폼에서의 NeMo 지원
파스업DIP(Data Intelligence Platform) 플랫폼에서는 NeMo Framework와 NeMo Microservices를 모두 활용할 수 있습니다.
NeMo Framework 활용
- DIP 플랫폼의 Jupyter 환경에서 NeMo Framework 2.0 라이브러리 사용
- Recipe 기반 접근 방식으로 대규모 언어 모델, 음성 인식, 음성 합성 모델 파인튜닝
- 커스텀 AI 모델 개발 및 프로토타이핑
NeMo Microservices 활용
- DIP 플랫폼에서 제공되는 NeMo Microservices 활용
- 모델 커스터마이징(파인튜닝), 평가, 거버넌스 기능 활용
- 커스터마이징된 모델은 NIM을 통해 프로덕션 배포
실제 활용 시나리오
시나리오 1: 고객 서비스 챗봇 개발
# NeMo Framework 2.0으로 모델 파인튜닝
import nemo_run as run
from nemo.collections.llm import api
data_config = {
"train_ds": {"file_path": "train.jsonl"},
"validation_ds": {"file_path": "val.jsonl"}
}
trainer_config = {
"max_steps": 1000,
"val_check_interval": 100,
"devices": 1,
"accelerator": "gpu"
}
# Recipe 기반 파인튜닝 설정
recipe = run.Partial(
api.finetune,
model="mistral_7b_instruct",
data=data_config,
trainer=trainer_config
)
# 파인튜닝 실행
run.run(recipe)
# NeMo Microservices로 프로덕션용 파인튜닝
import requests
training_params = {
"name": "customer-service-bot",
"config": "llama-3-8b-instruct",
"dataset": {"name": "customer_service_data", "namespace": "company_ns"},
"hyperparameters": {
"training_type": "sft",
"finetuning_type": "lora",
"epochs": 2
}
}
# 파인튜닝 작업 실행
response = requests.post(f"{NEMO_URL}/v1/customization/jobs", json=training_params)
# 커스터마이징된 모델은 이후 NIM을 통해 배포
시나리오 2: 음성 인식 시스템
# DIP 플랫폼에서 NeMo Framework 2.0으로 ASR 모델 파인튜닝
import nemo_run as run
from nemo.collections.asr import api
data_config = {
"train_ds": {"file_path": "train.jsonl"},
"validation_ds": {"file_path": "val.jsonl"}
}
trainer_config = {
"max_steps": 1000,
"val_check_interval": 100,
"devices": 1,
"accelerator": "gpu"
}
# ASR 모델 파인튜닝 recipe 설정
asr_recipe = run.Partial(
api.finetune,
model="stt_en_conformer_ctc_small",
data=data_config,
trainer=trainer_config
)
# 파인튜닝 실행
run.run(asr_recipe)
# 파인튜닝 결과를 바탕으로 NeMo Microservices를 통한 추가 커스터마이징
기업 도입 시 고려사항
개발 환경 선택
- 연구 및 프로토타이핑: NeMo Framework 활용
- 프로덕션 배포: NeMo Microservices + NIM 조합
운영 효율성
- DIP 플랫폼의 통합 환경에서 개발부터 배포까지 일관된 워크플로우
- 컨테이너 기반 마이크로서비스 아키텍처로 확장 가능한 운영
- 자동화된 MLOps 파이프라인 구축 가능
마무리
이번 글에서는 AI 모델의 개발부터 운영까지, 전체 라이프사이클을 아우르는 NVIDIA NeMo 플랫폼을 살펴보았습니다. NeMo는 모델 개발과 운영을 각각 최적화한 두 가지 핵심 솔루션을 제공합니다.
- NeMo Framework는 연구자와 ML 엔지니어가 로컬 환경에서 모델을 자유롭게 실험하고 커스터마이징할 수 있는 강력한 Python 라이브러리입니다.
- NeMo Microservices는 학습된 모델을 프로덕션 환경에 안정적으로 배포하고, 체계적으로 평가하며, 거버넌스를 관리해야 하는 엔터프라이즈 개발팀을 위한 통합 플랫폼입니다.
파스업DIP(Data Intelligence Platform) 는 이 두 가지 솔루션을 모두 활용할 수 있는 통합 환경을 제공합니다. 사용자는 개발 목적에 따라 Jupyter 환경에서 NeMo Framework를 사용하거나, 카탈로그를 통해 NeMo Microservices의 기능을 활용할 수 있습니다.
2025년 현재, NeMo Framework 2.0의 강력한 기능과 정식 출시된 NeMo Microservices는 기업이 AI를 성공적으로 도입하기 위한 가장 확실한 선택지 중 하나가 되었습니다.
✅ 요약 정리
- 🧪 NeMo Framework: 연구/실험 중심 모델 개발 및 파인튜닝
- 🏭 NeMo Microservices: 기업용 모델 커스터마이징, 평가, 운영 관리
- 🔗 파스업DIP: 두 플랫폼을 통합한 엔드투엔드 AI 운영 환경
다음 편에서는 파스업DIP 환경 에서 NeMo Framework를 활용한 모델 파인튜닝 실제 예시와, NeMo Microservices를 이용한 모델 커스터마이징 및 평가 예시를 각각 자세히 살펴보겠습니다.