
NeMo Framework and NeMo Microservices: A Comprehensive Overview
Comprehensive guide to NVIDIA NeMo platform supporting the entire AI model lifecycle from development to deployment. Discover the differences between research-focused NeMo Framework and enterprise-grade NeMo Microservices, plus real-world implementation in PaaS-UP DIP platform.
Introduction
The rapid advancement of AI technology has made developing and operating large language models (LLMs) and multimodal AI models a core priority for enterprises and research institutions. However, deploying these models reliably in production environments requires robust, enterprise-grade platforms.
NVIDIA has addressed this need with NeMo, a comprehensive AI platform that serves users across the entire spectrum—from researchers to enterprise development teams. NeMo consists of two core components:
- NeMo Framework: An open-source development environment for model research and experimentation
- NeMo Microservices: An enterprise platform for production deployment and operations
This series will cover everything from an introduction to the NeMo platform to practical implementation examples on the PAASUP DIP platform.
NeMo Framework vs NeMo Microservices: Key Differences
Here's a side-by-side comparison of the main features of both platforms:
| Category | NeMo Framework | NeMo Microservices |
|---|---|---|
| Purpose | Model research, development & custom architecture implementation | Enterprise-grade model customization & operations |
| Primary Users | Researchers, ML Engineers | Application developers, Enterprise deployment teams |
| Development Approach | Python-based library | REST/gRPC-based microservices |
| Runtime Environment | Jupyter, Python scripts | Docker, Kubernetes |
| Use Case Examples | Training script execution, experimentation | Chatbot /chat, Document summarization /summarize APIs |
| Release Status | Open source (GitHub) | Generally Available (April 2025) |
NeMo Framework: Custom AI Model Development for Researchers and Developers
Platform Overview
NeMo Framework is a PyTorch-based open-source development platform designed for custom AI model development across various domains. Available freely on GitHub, it supports everything from research projects to initial prototyping.
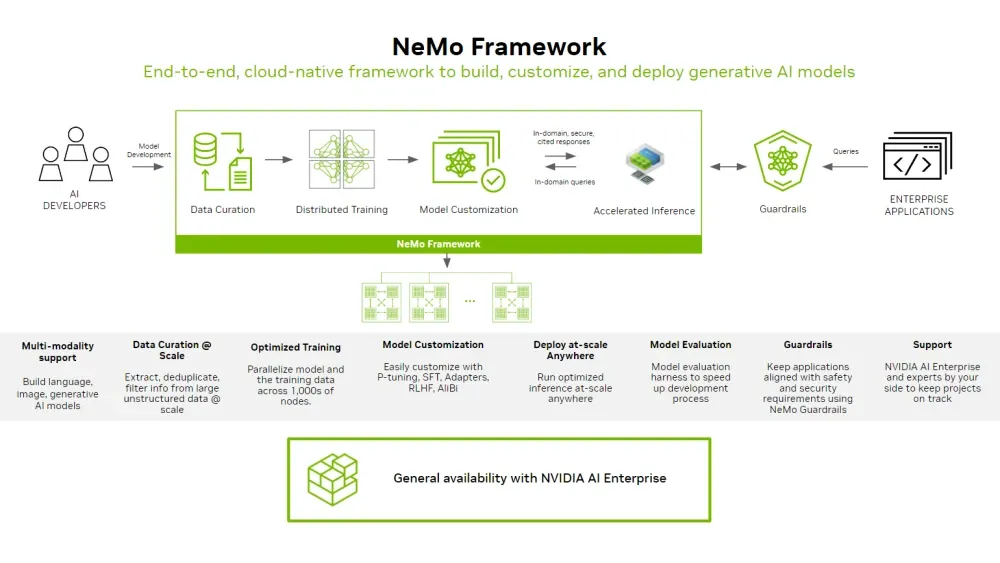
Image source: NVIDIA NeMo Framework
NeMo Framework 2.0: Major 2025 Updates
The NeMo 2.0 release introduced significant API changes and unveiled NeMo Run, a new workflow management library. Key updates include:
NVIDIA Cosmos Integration
NeMo Framework now supports training and customization of world foundation models from the NVIDIA Cosmos collection. Cosmos enables multimodal generative models that can generate various modalities (video, audio, images) from text inputs.
Unified Container Environment
NeMo Framework now consolidates Large Language Models (LLM), Multimodal (MM), Automatic Speech Recognition (ASR), and Text-to-Speech (TTS) capabilities within a single unified container.
Performance Optimizations
The framework delivers optimal performance for advanced generative AI model training through Megatron-style tensor/sequence/pipeline parallelization and FlashAttention-based attention optimizations.
Supported Model Collections
NeMo Framework supports various AI models through its collection-based architecture:
NLP (Natural Language Processing)
- Large Language Models (LLMs)
- Text classification and sentiment analysis
- Question-answering systems
- Llama, Mistral, Gemma series models
ASR (Automatic Speech Recognition)
- Multilingual speech recognition
- Real-time Speech-to-Text (STT)
- Noise reduction capabilities
- AED multitask models (Canary)
TTS (Text-to-Speech)
- Natural speech synthesis
- Multiple vocoder support
- Speaker adaptation features
Multimodal
- Image-text integration models
- Video-text processing
- Multimodal generative AI
- Cosmos video foundation models
Advanced Technology Support
NeMo Framework incorporates cutting-edge technologies for efficient large-scale AI model training:
FSDP (Fully Sharded Data Parallel) enables memory-efficient distributed learning, improving training efficiency for large-scale AI models.
MoE (Mixture of Experts) supports expert mixture-based LLM architectures to enhance model performance.
High-Performance Data Processing through NeMo Curator, which includes high-throughput data curation, efficient multimodal data loading, scalable model training, and parallelized inference infrastructure.
Practical Implementation Examples
LLM Model Fine-tuning
# Fine-tuning mistral_7b_instruct model with custom data
import nemo_run as run
from nemo.collections.llm import api
data_config = {
"train_ds": {"file_path": "train.jsonl"},
"validation_ds": {"file_path": "val.jsonl"}
}
trainer_config = {
"max_steps": 1000,
"val_check_interval": 100,
"devices": 1,
"accelerator": "gpu"
}
# Recipe: Define fine-tuning configuration
recipe = run.Partial(
api.finetune,
model="mistral_7b_instruct",
data=data_config,
trainer=trainer_config,
optim={"lr": 1e-5}
)
# Execute the recipe
run.run(recipe)
Automatic Speech Recognition (ASR) Implementation
# Converting audio files to text using pre-trained QuartzNet model
import nemo_run as run
from nemo.collections.asr import api
# Define speech recognition recipe
asr_recipe = run.Partial(
api.transcribe,
model="stt_en_quartznet15x5",
audio_files=["audio_file.wav"],
output_dir="./transcriptions"
)
# Execute speech recognition
transcription_results = run.run(asr_recipe)
# Alternative: Direct API usage without NeMo Run
from nemo.collections.asr.api import transcribe
results = transcribe(
model="stt_en_quartznet15x5",
audio_files=["audio_file.wav"]
)
Text-to-Speech (TTS) Implementation
# Converting text to audio using pre-trained FastPitch model
import nemo_run as run
from nemo.collections.tts import api
# Define speech synthesis recipe
tts_recipe = run.Partial(
api.synthesize,
model="tts_en_fastpitch",
text="Hello, this is NeMo TTS!",
output_dir="./audio_output"
)
# Execute speech synthesis
audio_output = run.run(tts_recipe)
# Alternative: Direct API usage
from nemo.collections.tts.api import synthesize
audio = synthesize(
model="tts_en_fastpitch",
text="Hello, this is NeMo TTS!",
output_format="wav"
)
NeMo Microservices: Enterprise-Grade AI Model Operations Platform
Platform Overview
Released as Generally Available in April 2025, NeMo Microservices is designed for stable deployment and operation of large-scale AI models in enterprise environments. It provides scalability and management capabilities in Kubernetes through a REST API-based microservices architecture.
Unlike traditional approaches, NeMo Microservices doesn't deploy models directly from NeMo Framework or Hugging Face training. Instead, it follows this workflow:
- Selects NIM-based pre-optimized models from the NVIDIA API Catalog
- Customizes these models for specific user domains (e.g., SFT, LoRA)
- Repackages the results as NIM format for deployment
This approach enables enterprises to leverage NVIDIA's high-performance models while adapting them to domain-specific requirements.
Core Components
NeMo Microservices is a modular, production-focused platform that enables enterprises to fine-tune, evaluate, secure, and deploy AI models at scale. The three core components are:
NeMo Customizer
- AI model fine-tuning and customization
- Support for efficient training techniques (LoRA, QLoRA)
- Automated hyperparameter optimization
NeMo Evaluator
- Systematic model performance evaluation
- Benchmarking and A/B testing capabilities
- Continuous model improvement workflows
NeMo Guardrails
- AI model safety and security
- Ethical AI usage frameworks
- Governance and compliance management
Additional Platform Components
NVIDIA NeMo Data Store
- Primary file storage solution for the NeMo microservices platform
- Hugging Face Hub client (HfApi) compatible API
NVIDIA NeMo Entity Store
- Management tool for namespaces, projects, datasets, models, and other entities
NVIDIA NeMo Deployment Management
- NIM deployment API for Kubernetes clusters
- Management through NIM Operator microservice
NVIDIA NeMo NIM Proxy
- Unified endpoint for accessing inference tasks across all deployed NIMs
Data Flywheel Architecture
One of NeMo Microservices' key strengths is its data flywheel architecture, which enables continuous optimization through this cyclical process:
- Real-time Data Collection → Gather user feedback and model performance metrics
- Data Analysis → Analyze model performance using collected data
- Model Improvement → Retrain models based on analysis insights
- Deployment and Monitoring → Deploy improved models to production
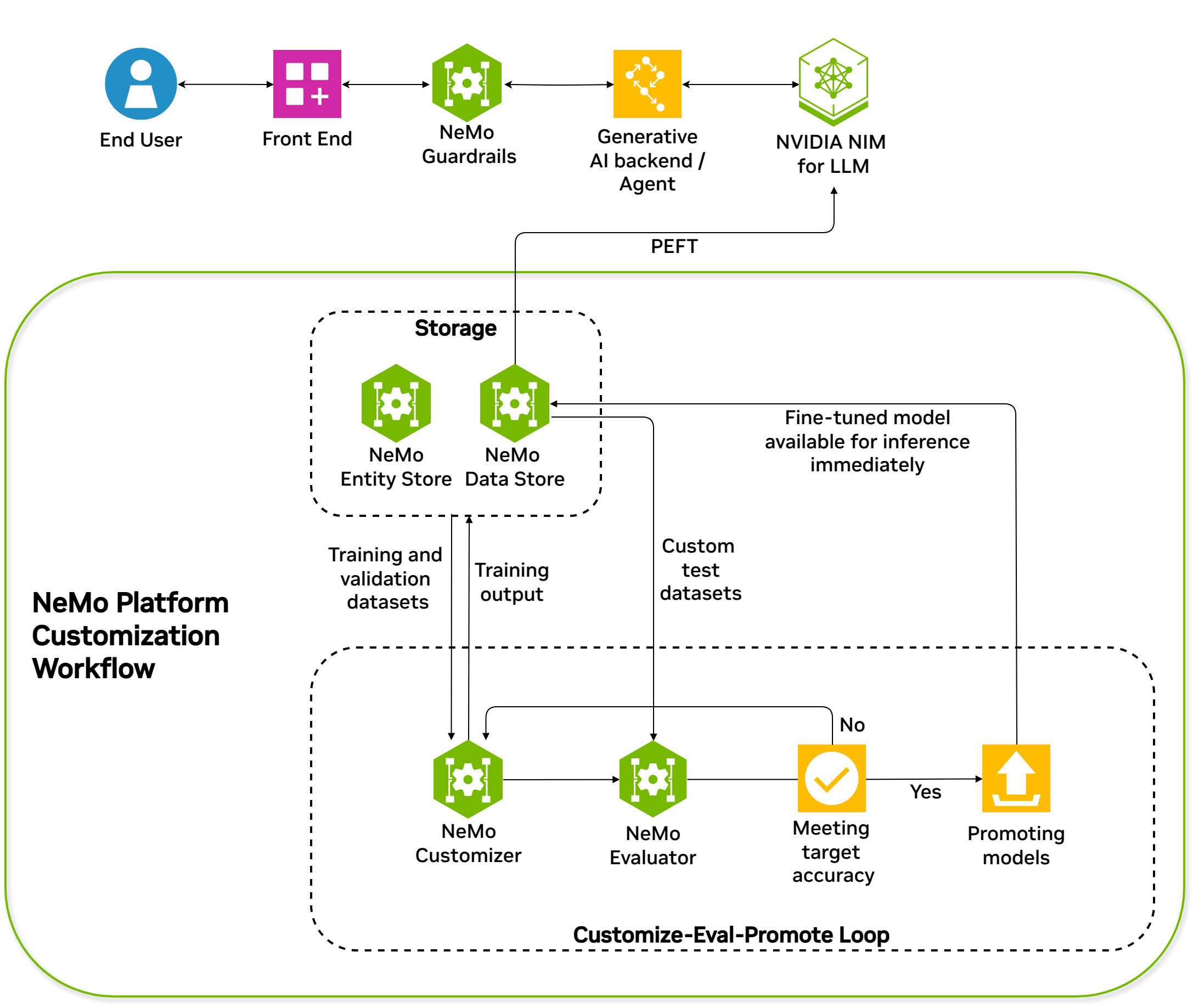
Image source: NVIDIA NeMo Microservices
Practical Implementation Examples
Model Fine-tuning Job Request
import requests
# Configuration
NMS_NAMESPACE = "your_org_namespace"
BASE_MODEL = "llama-3-8b-instruct"
DATASET_NAME = "your_custom_dataset"
NEMO_URL = "YOUR_NEMO_MICROSERVICES_ENDPOINT"
# Fine-tuning parameters
training_params = {
"name": "llama-3-8b-instruct-sft-lora",
"output_model": f"{NMS_NAMESPACE}/llama-3-8b-instruct-sft-lora-model",
"config": BASE_MODEL,
"dataset": {"name": DATASET_NAME, "namespace": NMS_NAMESPACE},
"hyperparameters": {
"training_type": "sft", # Supervised Fine-Tuning
"finetuning_type": "lora", # LoRA method
"epochs": 2,
"batch_size": 16,
"learning_rate": 0.0001,
"lora": {
"adapter_dim": 32,
"adapter_dropout": 0.1
}
}
}
# Submit API request
response = requests.post(
f"{NEMO_URL}/v1/customization/jobs",
json=training_params
)
Model Evaluation Job
# Model performance evaluation request
evaluation_params = {
"model_name": "llama-3-8b-instruct-sft-lora",
"evaluation_dataset": "benchmark_dataset",
"metrics": ["accuracy", "bleu", "rouge"],
"evaluation_type": "automated"
}
eval_response = requests.post(
f"{NEMO_URL}/v1/evaluation/jobs",
json=evaluation_params
)
Integration with NIM
NeMo Microservices works complementarily with NIM (NVIDIA Inference Microservices):
NIM's Role
- Inference Optimization: Specialized for optimized model serving
- Performance Maximization: Leverages TensorRT for optimal inference performance
- Rapid Deployment: Immediate deployment of pre-optimized models
NeMo Microservices' Role
- Model Enhancement: Focuses on data preparation, training, and evaluation
- Customization: Domain-specific adaptation of existing models
- Safety Management: Comprehensive model governance and security
Currently, NeMo Microservices is optimized for integration with NIM-based models from the NVIDIA API Catalog, following this workflow:
- Base Model Selection → Choose NIM-supported models from NVIDIA API Catalog
- Customization → Domain-specific fine-tuning via NeMo Microservices
- Deployment → NIM-based production deployment of customized models
- Operations → Ongoing monitoring and iterative improvement
NeMo Integration with PAASUP DIP Platform
NeMo Support in DIP Platform
The PAASUP DIP (Data Intelligence Platform) provides comprehensive support for both NeMo Framework and NeMo Microservices.
NeMo Framework Integration
- Access to NeMo Framework 2.0 library within DIP platform's Jupyter environment
- Recipe-based approach for fine-tuning large language models, speech recognition, and speech synthesis models
- Support for custom AI model development and prototyping
NeMo Microservices Integration
- Native access to NeMo Microservices through the DIP platform
- Full model customization (fine-tuning), evaluation, and governance capabilities
- Seamless production deployment of customized models through NIM
Real-World Implementation Scenarios
Scenario 1: Customer Service Chatbot Development
# Model fine-tuning with NeMo Framework 2.0 on DIP platform
import nemo_run as run
from nemo.collections.llm import api
data_config = {
"train_ds": {"file_path": "train.jsonl"},
"validation_ds": {"file_path": "val.jsonl"}
}
trainer_config = {
"max_steps": 1000,
"val_check_interval": 100,
"devices": 1,
"accelerator": "gpu"
}
# Recipe-based fine-tuning setup
recipe = run.Partial(
api.finetune,
model="mistral_7b_instruct",
data=data_config,
trainer=trainer_config
)
# Execute fine-tuning
run.run(recipe)
# Production fine-tuning with NeMo Microservices
import requests
training_params = {
"name": "customer-service-bot",
"config": "llama-3-8b-instruct",
"dataset": {"name": "customer_service_data", "namespace": "company_ns"},
"hyperparameters": {
"training_type": "sft",
"finetuning_type": "lora",
"epochs": 2
}
}
# Execute fine-tuning job
response = requests.post(f"{NEMO_URL}/v1/customization/jobs", json=training_params)
# Customized model deployed via NIM
Scenario 2: Speech Recognition System
# ASR model fine-tuning with NeMo Framework 2.0 on DIP platform
import nemo_run as run
from nemo.collections.asr import api
data_config = {
"train_ds": {"file_path": "train.jsonl"},
"validation_ds": {"file_path": "val.jsonl"}
}
trainer_config = {
"max_steps": 1000,
"val_check_interval": 100,
"devices": 1,
"accelerator": "gpu"
}
# ASR model fine-tuning recipe setup
asr_recipe = run.Partial(
api.finetune,
model="stt_en_conformer_ctc_small",
data=data_config,
trainer=trainer_config
)
# Execute fine-tuning
run.run(asr_recipe)
# Follow-up customization via NeMo Microservices based on fine-tuning results
Enterprise Adoption Considerations
Development Environment Strategy
- Research and Prototyping: Leverage NeMo Framework for flexibility and experimentation
- Production Deployment: Use NeMo Microservices + NIM combination for enterprise-grade operations
Operational Excellence
- Unified workflow from development to deployment within DIP platform's integrated environment
- Scalable operations through container-based microservices architecture
- Comprehensive automated MLOps pipeline capabilities
Conclusion
This article explored the NVIDIA NeMo platform, which spans the entire AI model lifecycle from development to operations. NeMo provides two complementary solutions, each optimized for different aspects of AI model management:
NeMo Framework offers researchers and ML engineers a powerful Python library for flexible model experimentation and customization in local environments.
NeMo Microservices provides enterprise development teams with an integrated platform for stable production deployment, systematic evaluation, and comprehensive governance of AI models.
PAASUP DIP (Data Intelligence Platform) creates a unified environment that seamlessly integrates both solutions. Users can choose between NeMo Framework in Jupyter environments for development and experimentation, or leverage NeMo Microservices through the platform catalog for production deployment.
As of 2025, the powerful capabilities of NeMo Framework 2.0 combined with the production-ready NeMo Microservices platform represent one of the most comprehensive solutions for successful enterprise AI adoption.
✅ Key Takeaways
- 🧪 NeMo Framework: Research and experimentation-focused model development and fine-tuning
- 🏭 NeMo Microservices: Enterprise-grade model customization, evaluation, and operations management
- 🔗 PAASUP DIP: Unified end-to-end AI operations environment integrating both platforms
In the next article, we'll examine detailed examples of model fine-tuning using NeMo Framework and model customization and evaluation using NeMo Microservices within the PAASUP DIP environment.