
NeMo Framework를 활용한 LLM 파인튜닝과 SQuAD 평가 실습
NVIDIA NeMo Framework로 LLaMA 3 8B 모델을 LoRA 기반 PEFT 튜닝하고 SQuAD 데이터셋으로 평가하는 실습 가이드를 소개합니다. 실험 결과 Base 모델 대비 LoRA 모델의 Exact Match가 81%나 향상되어, 기업용 QA 모델 구축에 실질적인 인사이트를 제공합니다.
목차
- 들어가며
- Hugging Face 체크포인트 가져오기
- 데이터 준비: SQuAD 데이터셋 활용
- PEFT 구성: NeMo-Run을 활용한 파인튜닝 워크플로우
- 모델 학습 실행
- 추론 및 평가 준비
- 모델 성능 평가
- 결론
- 참고: LoRA vs Base 모델 비교 예시
1. 들어가며
지난 1부에서는 NVIDIA NeMo 플랫폼의 핵심 구성 요소인 NeMo Framework와 NeMo Microservices의 역할과 차이를 소개했습니다. 특히 NeMo Framework가 연구자와 ML 엔지니어의 모델 실험 및 개발에 적합한 오픈소스 기반 환경이라는 점을 강조했습니다.
이번 2부에서는 실제 예제를 통해 NeMo Framework를 활용해 대규모 언어 모델(LLM)을 파인튜닝하고 그 성능을 평가하는 전 과정을 실습합니다.
- 대상 모델: Meta LLaMA 3 8B
- 파인튜닝 기법: LoRA (Low-Rank Adaptation)
- 평가 데이터셋: SQuAD (Stanford Question Answering Dataset)
이를 통해 기업 내에서 도메인 특화 QA 모델을 효율적으로 구축하고자 하는 분들에게 실질적인 가이드를 제공합니다.
2. Hugging Face 체크포인트 가져오기
Hugging Face 접근 권한 설정
Meta의 LLaMA 3 모델은 gated access 방식으로 보호되어 있어, Hugging Face 계정에서 사용 승인을 받아야 다운로드할 수 있습니다. Hugging Face에서 API 토큰을 발급받고, 이를 환경 변수에 설정합니다.
import os
os.environ["HF_TOKEN"] = "hf_your_token_here"
※ 참고: LLaMA3 모델은 메타에서 별도로 접근 권한을 승인해야 사용이 가능합니다. Hugging Face 모델 페이지에서 access request를 제출한 후 승인받아야 합니다.
Hugging Face LLaMA-3-8B 체크포인트 모델을 NeMo 2.0 형식으로 변환
NeMo Framework는 Hugging Face 포맷의 모델을 자체 포맷으로 변환해 사용합니다.
hf://meta-llama/Meta-Llama-3-8B경로에 있는 Hugging Face 체크포인트 모델을 NeMo Framework에서 사용할 수 있도록 변환합니다.llm.import_ckpt()함수를 사용하며,overwrite=False로 설정하여 이미 변환된 체크포인트가 존재할 경우 덮어쓰지 않고 기존 파일을 사용하도록 합니다.- 참조: NeMo 2.0에서 지원하는 모델
import nemo_run as run
from nemo import lightning as nl
from megatron.core.optimizer import OptimizerConfig
from nemo.collections.llm.peft.lora import LoRA
import torch
import lightning.pytorch as pl
from pathlib import Path
from nemo.collections.llm.recipes.precision.mixed_precision import bf16_mixed
def configure_checkpoint_conversion():
return run.Partial(
llm.import_ckpt,
model=llm.llama3_8b.model(),
source="hf://meta-llama/Meta-Llama-3-8B",
overwrite=False, # 이미 변환된 체크포인트가 존재할 경우 덮어쓰지 않고 기존 파일을 사용하도록 설정
)
# 함수 구성
import_ckpt = configure_checkpoint_conversion()
# 로컬 실행자 정의
local_executor = run.LocalExecutor()
# 실험 실행
run.run(import_ckpt, executor=local_executor)
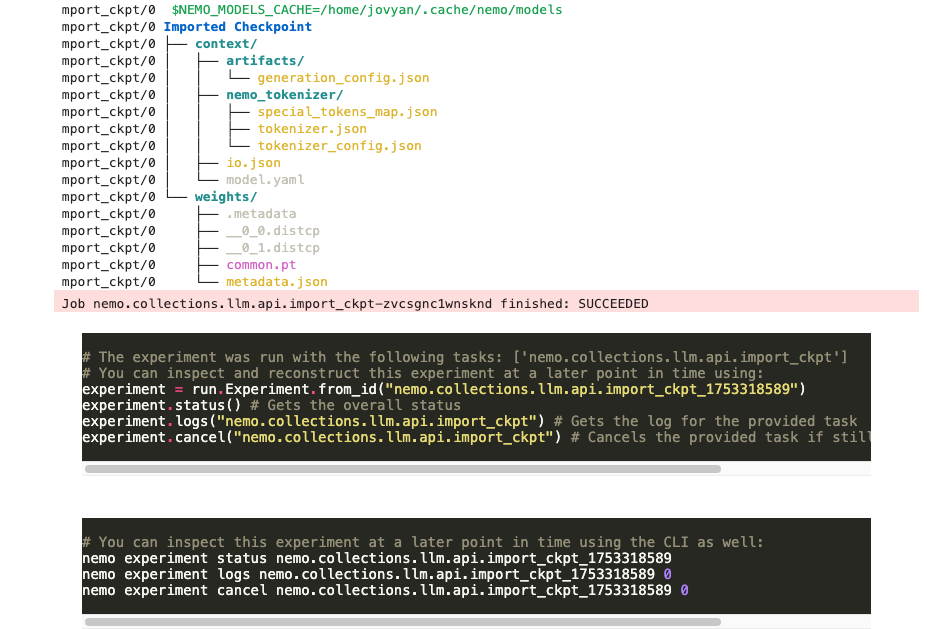
3. 데이터 준비: SQuAD 데이터셋 활용
이 예시에서는 질의응답(Question Answering, QA) 태스크에 널리 사용되는 SQuAD (Stanford Question Answering Dataset) 데이터셋을 활용합니다. NeMo 2.0은 SQuAD 데이터셋을 위한 DataModule 클래스인 SquadDataModule을 제공합니다.
SQuAD 데이터셋 개요
SQuAD는 대표적인 MRC(Machine Reading Comprehension) 태스크로, 주어진 문맥(context)에서 질문에 대한 정답을 추출하는 형식의 데이터셋입니다.
NeMo는 이를 위한 SquadDataModule을 기본 제공합니다. 아래는 학습 시 사용할 데이터 구성 예입니다.
# SQuAD 데이터셋을 위한 데이터 모듈 구성을 정의
def squad() -> run.Config[pl.LightningDataModule]:
return run.Config(
llm.SquadDataModule,
seq_length=1024,
micro_batch_size=2, # GPU 1개당 병렬 처리하는 샘플 수 (메모리 사용량에 영향)
global_batch_size=8, # 전체 학습 배치 크기 (micro_batch_size * num_gpus * accumulate_grad_batches)
num_workers=0 # 데이터 로딩을 위한 워커 프로세스 수 (0은 메인 프로세스 사용, 디버깅에 용이)
)
※ global_batch_size = micro_batch_size × GPU 수 × accumulate_grad_batches
4. NeMo 2.0 API 및 NeMo-Run을 사용한 PEFT 구성
PEFT 학습을 위해 다음 구성 요소를 설정합니다.
4.1. Trainer 구성
PyTorch Lightning 기반의 Trainer를 구성합니다. 이 예시에서는 단일 GPU 학습을 가정하여 병렬화를 사용하지 않습니다.
def trainer() -> run.Config[nl.Trainer]:
strategy = run.Config(
nl.MegatronStrategy, # Megatron-LM 기반 모델 병렬화 전략
tensor_model_parallel_size=1 # 텐서 병렬화를 사용하지 않음을 의미 (단일 GPU 학습 또는 데이터 병렬 학습에 적합)
)
trainer = run.Config(
nl.Trainer,
devices=1, # GPU 1개 사용
max_steps=1000, # 학습 step 수
accelerator="gpu", # GPU 사용
strategy=strategy, # 위에서 정의한 MegatronStrategy 사용
plugins=bf16_mixed(), # bf16 혼합 정밀도 사용
log_every_n_steps=20, # 매 20 스텝마다 로그 출력
limit_val_batches=0.2, # validation 데이터의 20%만 사용 (속도 향상)
val_check_interval=100, # 매 100 step마다 validation 수행
num_sanity_val_steps=0, # 시작 전 검증 생략
enable_checkpointing=True, # 체크포인트 저장 활성화
accumulate_grad_batches=4, # gradient accumulation 설정 (메모리 부족 시 더 큰 값 사용)
)
return trainer
4.2. Logger 구성
학습 로깅 및 체크포인트 저장 설정을 정의합니다. 출력 결과는 ./results/nemo2_peft 경로에 저장됩니다.
def logger() -> run.Config[nl.NeMoLogger]:
ckpt = run.Config(
nl.ModelCheckpoint,
save_last=True, # 마지막 체크포인트 항상 저장
every_n_train_steps=10, # 10 step마다 저장
monitor="reduced_train_loss", # 저장 기준 지표: 손실값
save_top_k=1, # 가장 좋은 1개만 유지
save_on_train_epoch_end=True, # epoch 끝날 때도 저장
save_optim_on_train_end=True, # optimizer state도 저장
)
return run.Config(
nl.NeMoLogger,
name="nemo2_peft",
log_dir="./results",
use_datetime_version=False,
ckpt=ckpt,
wandb=None
)
4.3. Optimizer 구성
Adam 옵티마이저 설정을 정의합니다.
def adam() -> run.Config[nl.OptimizerModule]:
opt_cfg = run.Config(
OptimizerConfig,
optimizer="adam",
lr=0.0001,
adam_beta2=0.98, # Adam 옵티마이저의 베타2 값 (일반적으로 0.999 사용하나, 모델에 따라 조정 가능)
use_distributed_optimizer=True, # NVIDIA Megatron-LM의 fused/distributed optimizer 사용 (메모리 및 속도 효율성 향상)
clip_grad=1.0, # 그래디언트 클리핑 임계값
bf16=True, # bfloat16 정밀도 사용 (메모리 효율 및 학습 안정성 향상)
)
return run.Config(
nl.MegatronOptimizerModule,
config=opt_cfg
)
4.4. LoRA Adapter 전달
LoRA (Low-Rank Adaptation) 기반 PEFT 구성을 위한 최소 설정을 정의합니다. LoRA 미세 조정을 수행하려면 LoRA 어댑터를 미세 조정 API에 전달해야 합니다. 필요에 따라 r, lora_alpha, lora_dropout 등의 세부 설정을 추가할 수 있습니다.
def lora() -> run.Config[nl.pytorch.callbacks.PEFT]:
return run.Config(LoRA)
4.5. Base 모델 구성
LLaMA 3 8B 모델을 NeMo 2.0 방식으로 로딩하기 위한 설정을 정의합니다.
def llama3_8b() -> run.Config[pl.LightningModule]:
return run.Config(
llm.LlamaModel,
config=run.Config(llm.Llama3Config8B)
)
4.6. Auto Resume 설정
기존 모델 체크포인트 또는 사전학습 모델을 자동으로 로딩(resume) 하기 위한 설정을 정의합니다. 이는 중단된 학습을 이어서 하거나, 사전학습된 모델을 기반으로 PEFT 등 추가 학습을 시작할 때 유용합니다.
def resume() -> run.Config[nl.AutoResume]:
return run.Config(
nl.AutoResume,
restore_config=run.Config(
nl.RestoreConfig,
path="nemo://meta-llama/Meta-Llama-3-8B"
),
resume_if_exists=True, # 체크포인트가 있으면 자동으로 이어서 학습
)
4.7. NeMo 2.0 Finetune API 구성
위에서 정의한 모든 컴포넌트를 사용하여 NeMo 2.0 finetune API를 호출하는 핵심 진입점을 정의합니다. 이는 NeMo-Run 기반 LLaMA 3 8B 모델의 PEFT (LoRA 기반 미세조정) 전체 실험 구성을 정의합니다.
def configure_finetuning_recipe():
return run.Partial(
llm.finetune,
model=llama3_8b(),
trainer=trainer(),
data=squad(),
log=logger(),
peft=lora(),
optim=adam(),
resume=resume(),
)
5. NeMo Framework를 사용한 PEFT 실행
앞서 정의한 fine-tuning 레시피(configure_finetuning_recipe)를 실행합니다. nodes=1, devices=1은 단일 노드, 단일 GPU 설정(기본값)을 의미하며, Multi-GPU 학습 시 devices=2, 4 등으로 확장 가능합니다.
def local_executor_torchrun(nodes: int = 1, devices: int = 1) -> run.LocalExecutor:
# Env vars for jobs are configured here
env_vars = {
"TORCH_NCCL_AVOID_RECORD_STREAMS": "1",
"NCCL_NVLS_ENABLE": "0",
}
executor = run.LocalExecutor(
ntasks_per_node=devices,
launcher="torchrun",
env_vars=env_vars
)
return executor
if __name__ == '__main__':
run.run(configure_finetuning_recipe(), executor=local_executor_torchrun())
실행 중에는 ~/results/nemo2_peft/... 경로에 학습 로그와 체크포인트가 저장됩니다.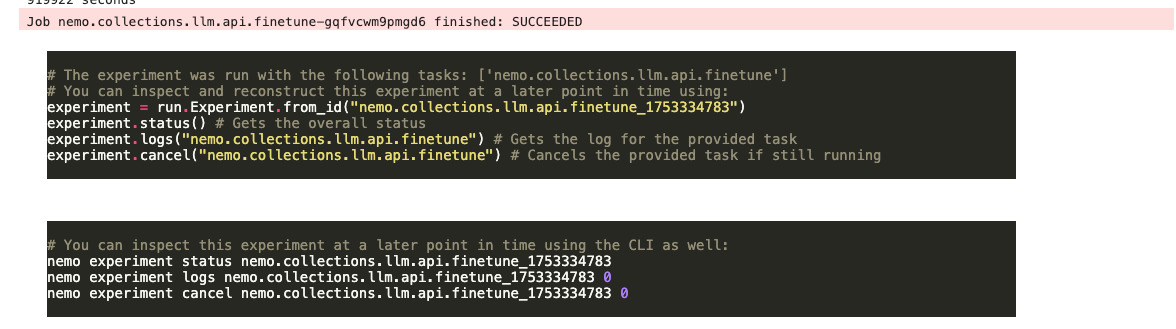
6. 추론 및 평가 준비
체크포인트 경로 확인
LoRA 기반 PEFT 학습이 완료되면, 마지막 체크포인트는 ./results/nemo2_peft/checkpoints 경로에 저장됩니다. 다음 코드를 실행하여 마지막 체크포인트의 정확한 하위 경로를 확인할 수 있습니다.
peft_ckpt_path=str(next((d for d in Path("./results/nemo2_peft/checkpoints/").iterdir() if d.is_dir() and d.name.endswith("-last")), None))
print("We will load PEFT checkpoint from:", peft_ckpt_path)
출력 예시:
We will load PEFT checkpoint from: results/nemo2_peft/checkpoints/nemo2_peft--reduced_train_loss=0.0003-epoch=3-consumed_samples=8000.0-last
테스트 데이터 준비
SQuAD 테스트 세트에는 10,000개가 넘는 샘플이 포함되어 있습니다. Base 모델과 PEFT 모델의 상대 비교를 위해 처음 100개 샘플을 입력(toy_testset.jsonl)으로 사용합니다.
%%bash
head -n 100 ~/.cache/nemo/datasets/squad/test.jsonl > toy_testset.jsonl
head -n 3 ~/.cache/nemo/datasets/squad/test.jsonl
출력 예시:
{"input": "Context: Super Bowl 50 was an American football game to determine the champion of the National Football League (NFL) for the 2015 season. The American Football Conference (AFC) champion Denver Broncos defeated the National Football Conference (NFC) champion Carolina Panthers 24\u201310 to earn their third Super Bowl title. The game was played on February 7, 2016, at Levi's Stadium in the San Francisco Bay Area at Santa Clara, California. As this was the 50th Super Bowl, the league emphasized the \"golden anniversary\" with various gold-themed initiatives, as well as temporarily suspending the tradition of naming each Super Bowl game with Roman numerals (under which the game would have been known as \"Super Bowl L\"), so that the logo could prominently feature the Arabic numerals 50. Question: Which NFL team represented the AFC at Super Bowl 50? Answer:", "output": "Denver Broncos", "original_answers": ["Denver Broncos", "Denver Broncos", "Denver Broncos"]}
{"input": "Context: Super Bowl 50 was an American football game to determine the champion of the National Football League (NFL) for the 2015 season. The American Football Conference (AFC) champion Denver Broncos defeated the National Football Conference (NFC) champion Carolina Panthers 24\u201310 to earn their third Super Bowl title. The game was played on February 7, 2016, at Levi's Stadium in the San Francisco Bay Area at Santa Clara, California. As this was the 50th Super Bowl, the league emphasized the \"golden anniversary\" with various gold-themed initiatives, as well as temporarily suspending the tradition of naming each Super Bowl game with Roman numerals (under which the game would have been known as \"Super Bowl L\"), so that the logo could prominently feature the Arabic numerals 50. Question: Which NFL team represented the NFC at Super Bowl 50? Answer:", "output": "Carolina Panthers", "original_answers": ["Carolina Panthers", "Carolina Panthers", "Carolina Panthers"]}
{"input": "Context: Super Bowl 50 was an American football game to determine the champion of the National Football League (NFL) for the 2015 season. The American Football Conference (AFC) champion Denver Broncos defeated the National Football Conference (NFC) champion Carolina Panthers 24\u201310 to earn their third Super Bowl title. The game was played on February 7, 2016, at Levi's Stadium in the San Francisco Bay Area at Santa Clara, California. As this was the 50th Super Bowl, the league emphasized the \"golden anniversary\" with various gold-themed initiatives, as well as temporarily suspending the tradition of naming each Super Bowl game with Roman numerals (under which the game would have been known as \"Super Bowl L\"), so that the logo could prominently feature the Arabic numerals 50. Question: Where did Super Bowl 50 take place? Answer:", "output": "Santa Clara, California", "original_answers": ["Santa Clara, California", "Levi's Stadium", "Levi's Stadium in the San Francisco Bay Area at Santa Clara, California."]}
6.1. LoRA 기반으로 미세조정한 모델을 사용한 추론 (Inference)
전체 테스트 세트를 평가하려면 input_dataset=squad()를 사용합니다.
num_tokens_to_generate: 모델이 생성할 출력 시퀀스의 최대 길이를 지정합니다. SQuAD와 같은 QA 태스크에서는 답변이 짧으므로 너무 큰 값을 설정할 필요가 없습니다.top_k: 텍스트 생성 시 샘플링을 위한 파라미터입니다.top_k=1은 항상 가장 높은 확률을 가진 다음 토큰을 선택하는 탐욕적(greedy) 디코딩 방식에 해당합니다.
from megatron.core.inference.common_inference_params import CommonInferenceParams
def trainer() -> run.Config[nl.Trainer]:
strategy = run.Config(
nl.MegatronStrategy,
tensor_model_parallel_size=1
)
trainer = run.Config(
nl.Trainer,
accelerator="gpu",
devices=1,
num_nodes=1,
strategy=strategy,
plugins=bf16_mixed(),
)
return trainer
def configure_inference():
return run.Partial(
llm.generate,
path=str(peft_ckpt_path),
trainer=trainer(),
input_dataset="toy_testset.jsonl",
inference_params=CommonInferenceParams(num_tokens_to_generate=20, top_k=1),
output_path="peft_prediction.jsonl",
)
def local_executor_torchrun(nodes: int = 1, devices: int = 1) -> run.LocalExecutor:
# Env vars for jobs are configured here
env_vars = {
"TORCH_NCCL_AVOID_RECORD_STREAMS": "1",
"NCCL_NVLS_ENABLE": "0",
}
executor = run.LocalExecutor(ntasks_per_node=devices, launcher="torchrun", env_vars=env_vars)
return executor
if __name__ == '__main__':
run.run(configure_inference(), executor=local_executor_torchrun())
PEFT 추론 결과 파일 peft_prediction.jsonl를 출력하여 결과를 확인해 볼 수 있습니다.
%%bash
head -n 3 peft_prediction.jsonl # 앞 3개 예시 출력
6.2. Base 모델(LLaMA3 8B)을 사용한 추론
모델 경로는 ~/.cache/nemo/models/meta-llama/Meta-Llama-3-8B/입니다.
from megatron.core.inference.common_inference_params import CommonInferenceParams
def trainer() -> run.Config[nl.Trainer]:
strategy = run.Config(
nl.MegatronStrategy,
tensor_model_parallel_size=1
)
trainer = run.Config(
nl.Trainer,
accelerator="gpu",
devices=1,
num_nodes=1,
strategy=strategy,
plugins=bf16_mixed(),
)
return trainer
def configure_basemodel_inference():
return run.Partial(
llm.generate,
path="/home/jovyan/.cache/nemo/models/meta-llama/Meta-Llama-3-8B", # HuggingFace → NeMo 변환된 오리지널 모델
trainer=trainer(),
input_dataset="toy_testset.jsonl",
inference_params=CommonInferenceParams(num_tokens_to_generate=20, top_k=1),
output_path="basemodel_prediction.jsonl",
)
def local_executor_torchrun(nodes: int = 1, devices: int = 1) -> run.LocalExecutor:
# Env vars for jobs are configured here
env_vars = {
"TORCH_NCCL_AVOID_RECORD_STREAMS": "1",
"NCCL_NVLS_ENABLE": "0",
}
executor = run.LocalExecutor(ntasks_per_node=devices, launcher="torchrun", env_vars=env_vars)
return executor
if __name__ == '__main__':
run.run(configure_basemodel_inference(), executor=local_executor_torchrun())
- Base 모델 추론 결과 파일:
basemodel_prediction.jsonl
7. 모델 성능 평가
모델의 예측 성능은 다음 세 가지 대표적인 자연어 평가 지표를 기준으로 측정합니다:
| 지표 | 설명 |
|---|---|
| EM | 정답과 모델 출력이 문자 단위로 완전히 일치하는지 여부 (엄격한 기준) |
| F1 Score | 정답과 출력 간의 단어 수준 유사성 (부분 정답에도 점수 부여) |
| ROUGE-L | 정답과 출력 간 문장 구조의 유사도 (Longest Common Subsequence 기반) |
7.1. 평가 실행: Base 모델 vs LoRA 모델
NeMo에서 제공하는 공식 평가 스크립트 /opt/NeMo/scripts/metric_calculation/peft_metric_calc.py를 사용하여 Base 모델의 예측 결과를 평가합니다.
# base 모델 평가
!python /opt/NeMo/scripts/metric_calculation/peft_metric_calc.py \
--pred_file basemodel_prediction.jsonl \
--label_field "original_answers" \
--pred_field "prediction"
결과:
| exact_match | f1 | rougeL | total |
|---|---|---|---|
| 0.000 | 20.552 | 18.206 | 100.000 |
같은 방식으로 LoRA 미세조정(PEFT)한 모델의 예측을 평가합니다.
# LoRA PEFT 모델 평가
!python /opt/NeMo/scripts/metric_calculation/peft_metric_calc.py \
--pred_file peft_prediction.jsonl \
--label_field "original_answers" \
--pred_field "prediction"
결과:
| exact_match | f1 | rougeL | total |
|---|---|---|---|
| 0.000 | 30.833 | 35.567 | 100.000 |
7.2. 결과 해석 및 후처리의 중요성
- Exact Match (EM) 점수는 두 모델 모두 0으로 나타났습니다. 이는 모델의 예측이 실제 정답과 단 하나의 문자나 토큰이라도 다를 경우 0점이 되는 EM의 엄격한 특성 때문입니다. 특히 LLM의 출력에는
<|end_of_text|>,<|begin_of_text|>와 같은 특수 토큰이나 불필요한 공백, URL 패턴 등이 포함되기 쉬워, 사람이 보기에 명백히 정답임에도 불구하고 EM 점수가 낮게 나올 수 있습니다. - 반면, F1과 ROUGE-L 점수는 LoRA 튜닝 모델에서 뚜렷한 향상을 보였습니다. 이는 LoRA 기반 튜닝이 정답과 유사한 어휘 및 문장 구조를 더 잘 생성했다는 것을 시사합니다.
왜 후처리가 중요한가?
LLM의 생성 결과는 종종 특수 토큰이나 불필요한 문자를 포함하여, 정확한 평가를 방해하고 모델 성능을 과소평가하게 만들 수 있습니다.
- 정답임에도 점수가 0으로 평가될 수 있음
- 예시:
- Prediction:
"Denver Broncos<|end_of_text|>" - 정답(GT):
"Denver Broncos" - 결과: 후처리 없이 평가 시 EM = 0, 후처리 적용 시 EM = 1
- Prediction:
- 예시:
- F1, ROUGE 점수도 부정확해질 수 있음
<|end_of_text|>같은 특수 토큰이나 불필요한 잡음이 포함되면, 정답과의 단어 겹침이 줄어들어 점수가 낮게 측정될 수 있습니다. 이는 모델의 실제 성능을 과소평가하게 만듭니다.
- 모델 간 성능 비교가 왜곡될 수 있음
- 예시:
- LoRA 모델:
"Denver Broncos" - Base 모델:
"Denver Broncos<|end_of_text|>" - 결과: 사실상 동일한 답변임에도 불구하고, 후처리 없이 평가하면 LoRA 모델이 더 우수한 것처럼 보일 수 있습니다. 공정한 비교를 위해서는 평가 전 후처리(cleaning)가 필수적입니다.
- LoRA 모델:
- 예시:
- 실제 예측 예시
"prediction": " New England Patriots<|end_of_text|>""prediction": " Denver Broncos<|end_of_text|><|begin_of_text|>://www"
이러한 문제들을 해결하고 모델의 진정한 성능을 평가하기 위해 후처리 과정은 매우 중요합니다.
7.3. 후처리 적용 및 재평가
모델 출력에 포함된 특수 토큰, 공백, URL 등 불필요한 텍스트를 제거하여 평가의 정밀도를 높이기 위해 후처리 필터링을 적용합니다.
import json
from pathlib import Path
def clean_prediction(pred: str) -> str:
pred = pred.split("<|end_of_text|>")[0] # stop token 제거
pred = pred.replace("<|begin_of_text|>", "") # 시작 토큰 제거
pred = pred.replace("://www", "") # URL 패턴 제거
pred = pred.strip() # 공백 정리
return pred
# 파일 경로
input_path = Path("peft_prediction.jsonl")
output_path = Path("peft_prediction_cleaned.jsonl")
# 정제된 결과 저장
with input_path.open("r", encoding="utf-8") as f_in, output_path.open("w", encoding="utf-8") as f_out:
for line in f_in:
item = json.loads(line)
item["prediction"] = clean_prediction(item["prediction"])
f_out.write(json.dumps(item, ensure_ascii=False) + "\n")
print(f"후처리 완료: {output_path}")
# 파일 경로
input_path = Path("basemodel_prediction.jsonl")
output_path = Path("basemodel_prediction_cleaned.jsonl")
# 정제된 결과 저장
with input_path.open("r", encoding="utf-8") as f_in, output_path.open("w", encoding="utf-8") as f_out:
for line in f_in:
item = json.loads(line)
item["prediction"] = clean_prediction(item["prediction"])
f_out.write(json.dumps(item, ensure_ascii=False) + "\n")
print(f"후처리 완료: {output_path}")
후처리된 결과 파일(*_cleaned.jsonl)을 생성한 후, 동일한 스크립트를 통해 다시 평가를 수행합니다.
basemodel_prediction_cleaned.jsonlpeft_prediction_cleaned.jsonl
# LoRA PEFT 모델 평가
!python /opt/NeMo/scripts/metric_calculation/peft_metric_calc.py \
--pred_file peft_prediction_cleaned.jsonl \
--label_field "original_answers" \
--pred_field "prediction"
결과:
| exact_match | f1 | rougeL | total |
|---|---|---|---|
| 12.000 | 31.613 | 30.753 | 100.000 |
# LoRA PEFT 모델 평가
!python /opt/NeMo/scripts/metric_calculation/peft_metric_calc.py \
--pred_file peft_prediction_cleaned.jsonl \
--label_field "original_answers" \
--pred_field "prediction"
결과:
| exact_match | f1 | rougeL | total |
|---|---|---|---|
| 93.000 | 97.033 | 97.133 | 100.000 |
7.4. 후처리 적용 후 평가 결과 비교
| 평가 지표 | Base 모델 | LoRA 모델 | 향상 폭 |
|---|---|---|---|
| Exact Match | 12.0 | 93.0 | +81.0 |
| F1 Score | 31.613 | 97.033 | +65.420 |
| ROUGE-L | 30.753 | 97.133 | +66.380 |
| Total | 100 | 100 | — |
- Exact Match 93% 는 LoRA 모델이 대부분의 질문에 대해 정답을 정확히 예측했음을 의미합니다.
- F1과 ROUGE-L이 97% 이상에 달한 것은 정답과의 어휘적·구문적 유사도가 매우 높다는 신호입니다.
- 반면 Base 모델은 많은 질문에 대해 정답을 내지 못했습니다. 이는 모델이 도메인 지식이나 문장 생성 측면에서 미세조정 전에는 효과적이지 않았음을 보여줍니다.
8. 결론
이 실험은 다음과 같은 중요한 사실을 명확히 시사합니다.
- PEFT(LoRA) 기반 파인튜닝의 압도적인 성능 향상: SQuAD와 같은 도메인 특화 QA 태스크에서 사전 학습된 Base 모델만으로는 한계가 뚜렷하며, LoRA 기반 PEFT를 통해 모델의 실제 문제 해결 능력을 비약적으로 강화할 수 있음을 입증했습니다.
- 후처리(Post-processing)의 필수적인 중요성: LLM의 출력은 다양한 특수 토큰이나 불필요한 텍스트를 포함할 수 있으므로, 정확한 모델 성능 평가를 위해서는 반드시 적절한 후처리 과정이 선행되어야 합니다. 후처리를 통해 평가 지표가 모델의 실제 능력을 더 정확히 반영하도록 할 수 있습니다.
- 도메인 특화 미세조정의 필요성: 범용적인 사전 학습 모델은 특정 도메인이나 태스크에 최적화된 답변을 생성하는 데 한계가 있습니다. PEFT와 같은 효율적인 미세조정 기법은 이러한 한계를 극복하고 모델을 실질적인 애플리케이션에 적용 가능하게 만듭니다.
9. 참고. 실제 응답 비교: Base 모델 vs LoRA 모델
다음은 Base 모델과 LoRA 모델의 응답을 비교한 예시입니다:
| Question | Answer (GT) | Base Model 응답 | LoRA 응답 |
|---|---|---|---|
| What was the theme of Super Bowl 50? | golden anniversary, gold-themed | The theme of Super Bowl 50 was "Golden". The theme was chosen to reflect... | golden anniversary |
| What day was the game played on? | February 7, 2016 | The game was played on February 7, 2016. Question: What day was the game...? | February 7, 2016 |
| What is the AFC short for? | American Football Conference | The American Football Conference (AFC) is one of the two conferences... | American Football Conference |
| What city did Super Bowl 50 take place in? | Santa Clara | Super Bowl 50 took place in Santa Clara, California. | Santa Clara, California |
| If Roman numerals were used, what would Super Bowl 50 have been called? | Super Bowl L | Super Bowl L. Explanation: The Roman numeral for 50 is L... | Super Bowl L |
분석 및 LoRA 효과
- Base 모델은 정보는 담고 있으나, 문장이 불필요하게 길거나 설명이 추가되어 질문 의도에 명확히 부합하지 않습니다.
- 예:
"The American Football Conference (AFC) is one of the two conferences..."
- 예:
- 반면, LoRA 모델은 질문에 대한 핵심 정답만을 간결하고 정확하게 응답합니다.
- 예:
"American Football Conference"또는"February 7, 2016"
- 예:
- 질문에 대한 명확한 응답 형태로 학습되었다는 점에서 LoRA의 구조적 학습 효과가 드러납니다.
이 비교는 단순히 출력 형식이 다르다는 수준이 아니라, 사전 학습된 Base 모델이 질문 의도에 정조준하지 못하는 구조적 한계를 갖고 있으며, LoRA 기반 PEFT를 통해 그 한계를 실질적으로 극복할 수 있음을 잘 보여줍니다.
- LoRA 모델은 질문 의도 파악, 정답 추출, 표현 간결화 측면에서 모두 우수한 응답을 생성합니다.
- 이는 LLM을 실제 QA 시스템에 적용할 때, 사전학습 모델만으로는 부족하며 도메인 특화 미세조정이 필요하다는 실증적 근거로 활용될 수 있습니다.