
파스업DIP로 구현하는 현대적 데이터 파이프라인: 지하철 이용자 통계 분석 프로젝트 #1
파스업 DIP(Data Intelligence Platform)를 활용해 Spark, Delta Lake, Superset 등으로 서울 지하철 이용자 통계 데이터를 전처리·시각화해 교통·상권·도시계획 인사이트를 도출한 프로젝트를 소개합니다.
들어가며
본 프로젝트의 첫번째 파트에서는 현대 도시에서 지하철은 가장 중요한 대중교통 수단 중 하나입니다. 수많은 시민들이 매일 이용하는 지하철의 이용 패턴을 분석하면 도시의 흐름과 시민들의 생활패턴을 이해할 수 있습니다.
본 프로젝트에서는 지하철 노선별, 일별 이용객수 데이터를 수집하고 분석하여 의미있는 인사이트를 도출하고자 합니다. 이를 통해 교통정책 수립, 상권 분석, 도시계획 등 다양한 분야에서 활용 가능한 분석 결과를 제공할 것입니다.
1. 프로젝트 개요
2. 데이터 시각화
3. 프로젝트 환경 설정
4. 데이터 파이프라인 설계 및 구현
5. 프로젝트 결과 및 시사점
프로젝트 개요
목표: 지하철 이용자 통계 데이터를 활용한 종합적 분석 대시보드 구축
데이터 소스
- 지하철 이용자 통계 (10년4개월치, 출처:공공데이터포털)
- 지하철 역 정보 (출처:공공데이터포털)
기술 스택:
- 데이터 처리: Apache Spark
- 데이터 저장: Delta Lake, PostgreSQL
- 시각화: Apache Superset
- 개발 환경: Jupyter Notebook
- 플랫폼: DIP 포털
데이터 시각화
데이터 시각화는 복잡한 데이터를 직관적으로 이해할 수 있게 도와주는 핵심 요소입니다.
본 프로젝트에서는 Apache Superset을 활용하여 3개의 대시보드를 구현
대시보드 1: 역별 이용자수 추이
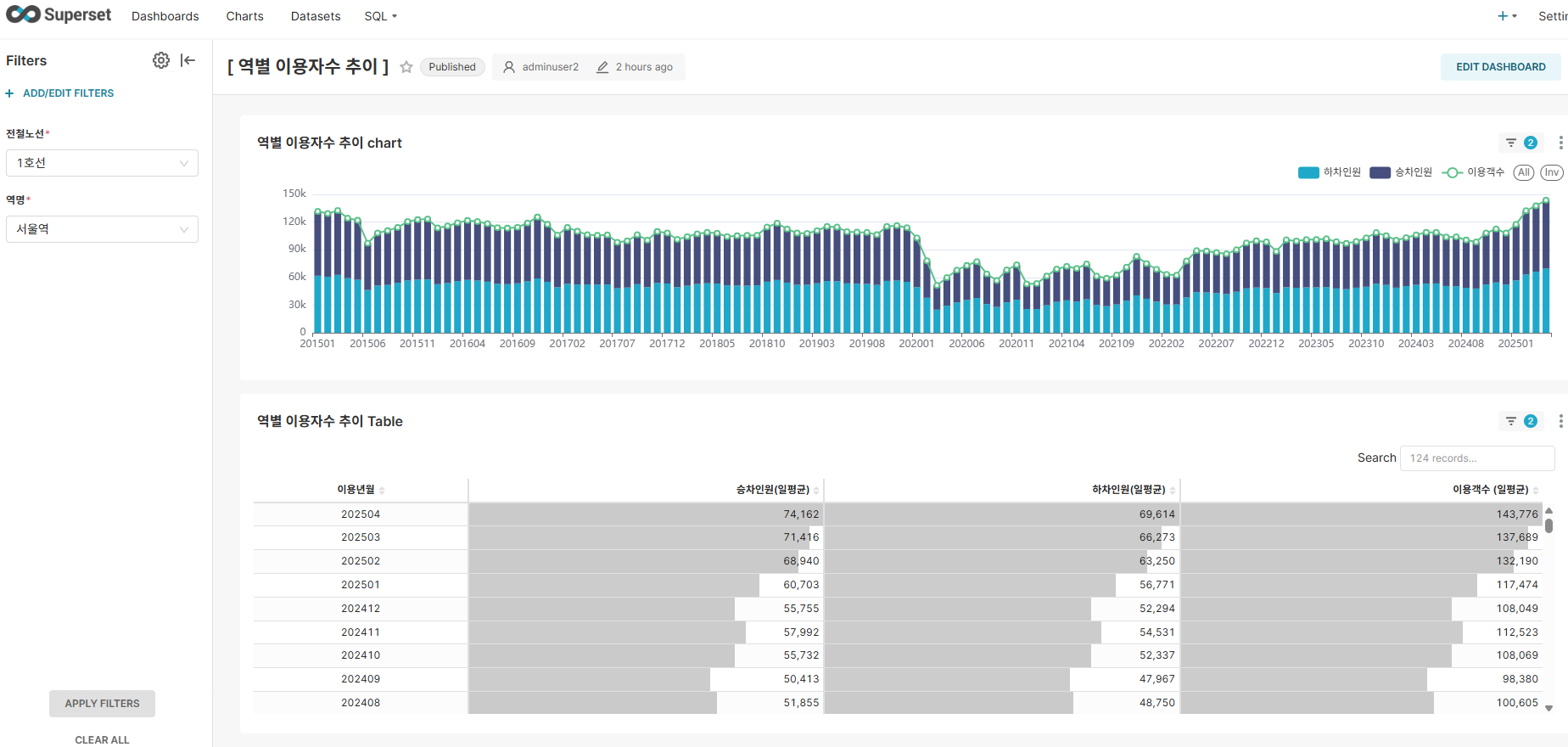
주요 기능:
- 시계열 분석: 월간 이용객수 추이 시각화
- 동적 필터: 노선별, 역별 동적 필터링
- 상호작용: 드릴다운을 통한 세부 분석
주요 인사이트:
- 코로나19 영향으로 2020년 초부터 급격한 이용객수 감소와 2022년까지 낮은 이용객수
- 2022년 후반부터 이용객수 점진적으로 증가하였으며 2023년 이후 안정된 이용 패턴을 보임
- 일정한 주기로 소폭의 증감을 반복하는 계적적 특정 확인
대시보드 2: 노선별 일평균 이용객수
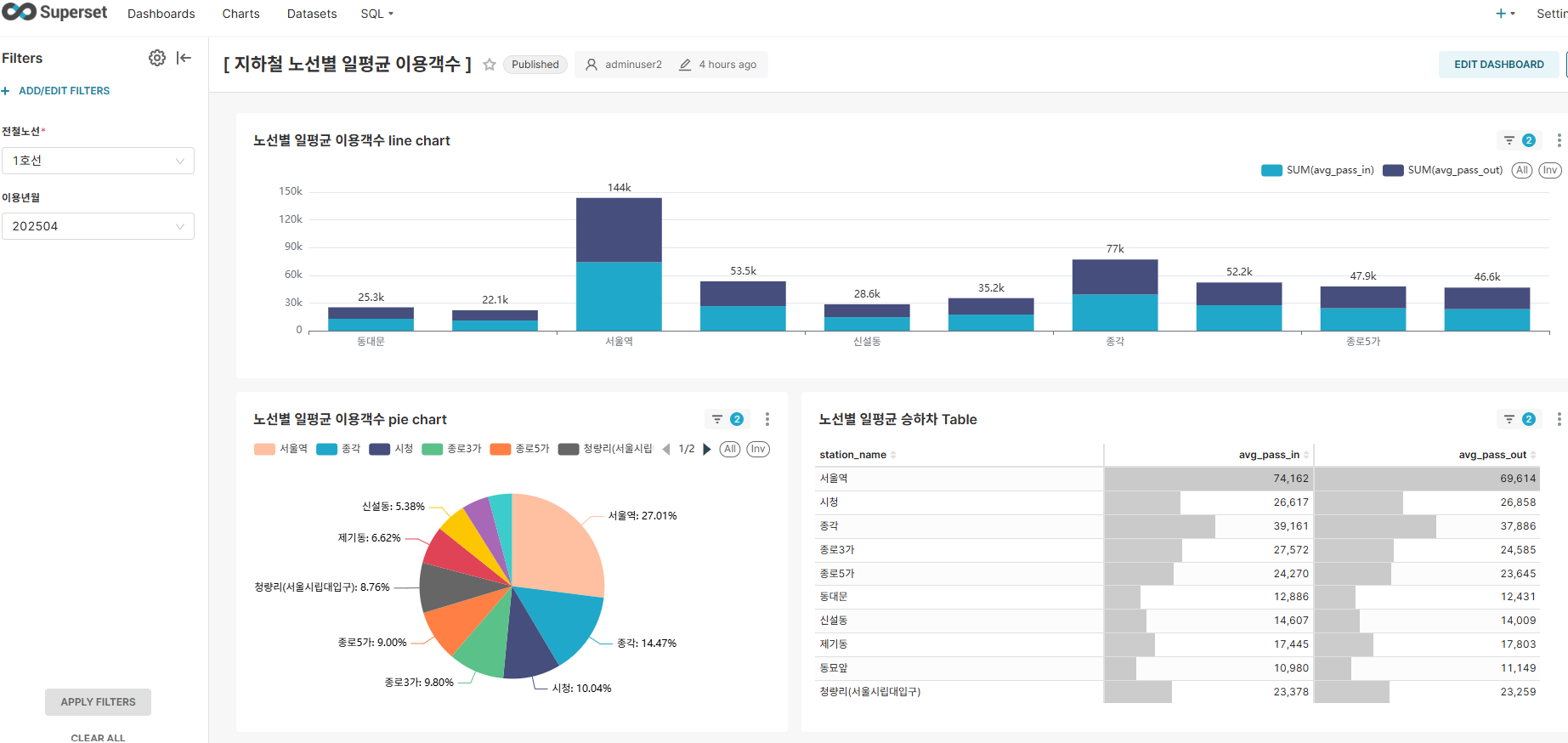
주요 기능:
- 밀도 분석: 노선별 이용객 밀도 한눈에 파악
- 동적 필터: 노선, 이용년월별 필터링
- 순위 분석: 동적 역사 순위 정렬 가능
주요 인사이트:
- 1호선 서울역, 2호선 강남역 등 도심 집중형 교통 이용 패턴 확인
- 주요 환승역과 일반역 간의 뚜렸한 이용객수 격차
- 대부분 역에서 승차인원과 하차인원이 비슷한 수준으로 정상적 지하철 이용 패턴 확인
대시보드 3: 요일별 이용객
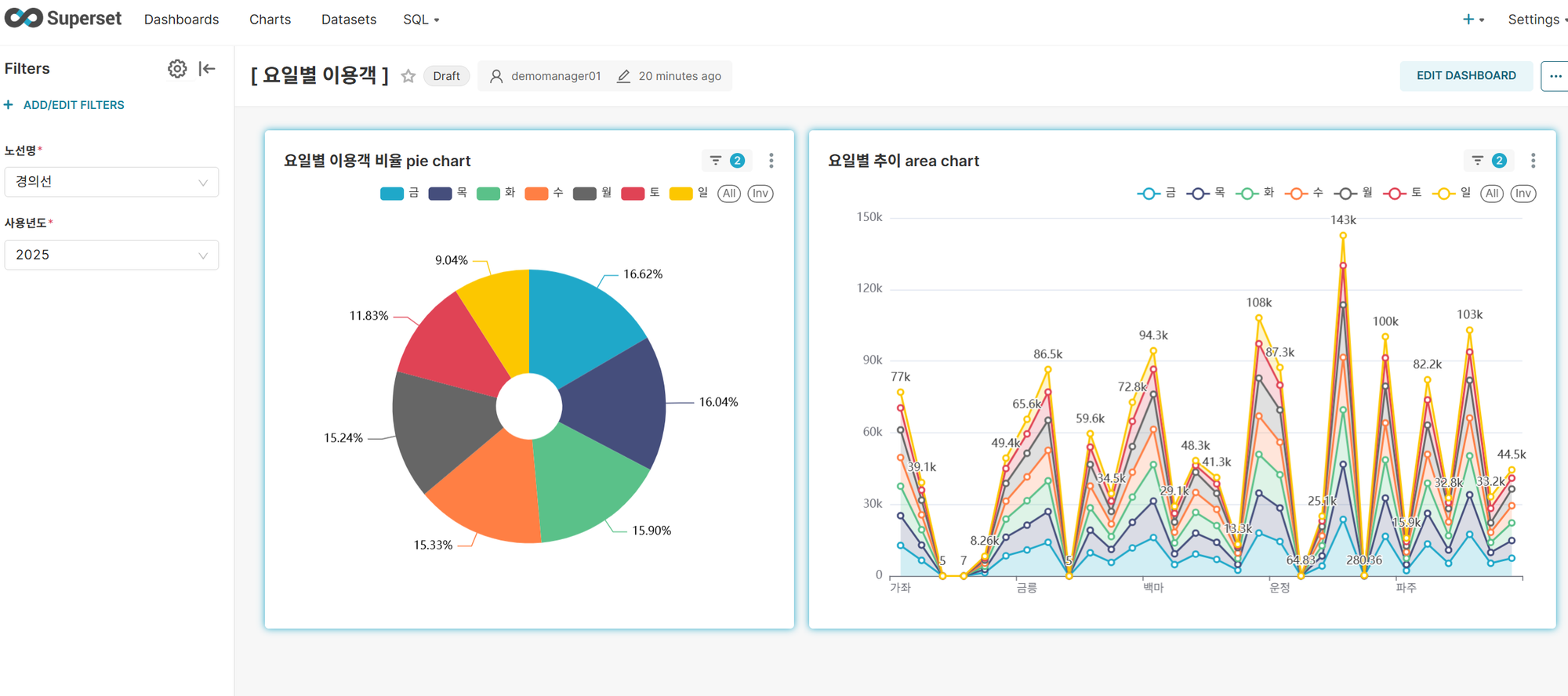
주요 기능:
- 밀도 분석: 요일별 이용객 비율을 노선별, 역별로 한눈에 파악
- 동적 필터: 노선, 이용년 필터링
- 순위 분석: 요일별 순위로 정렬
- 기 타 : raw data에 이용시간이 있다면 시간별 분석이 가능한데 일자별 데이터기 때문에 이용시간대 분석은 불가능
주요 인사이트:
- 금요일이 주중 최대 이용률을 보이고 나머지 평일은 고른 분포임(TGIF현상)
- 평일 vs 주말 격차 : 주말(토/일) 이용율이 평일에 비해 현저히 낮음으로 통근/통학 중심의 이용 패턴 확인
- 월요일 블루 효과 미미 : 화요일과 비슷한 수준
프로젝트 환경 설정
본 프로젝트는 DIP(Data Intelligence Platform) 포털을 통해 간단한 조작만으로 필요한 모든 환경을 구축할 수 있습니다.
필요한 서비스 카탈로그
- Kubeflow: jupyter notebook 연계 워크플로우 관리
- PostgreSQL: 데이터 저장 및 관리
- Apache Superset: 데이터 시각화 및 대시보드
환경 구축 단계별 가이드
1단계: 로그인 및 프로젝트 선택
DIP 관리자가 프로젝트와 매니저 계정을 먼저 생성합니다. 생성된 계정으로 로그인한 후, 매니저에게 할당된 프로젝트 리스트를 조회하고 카탈로그 생성 메뉴를 선택합니다.
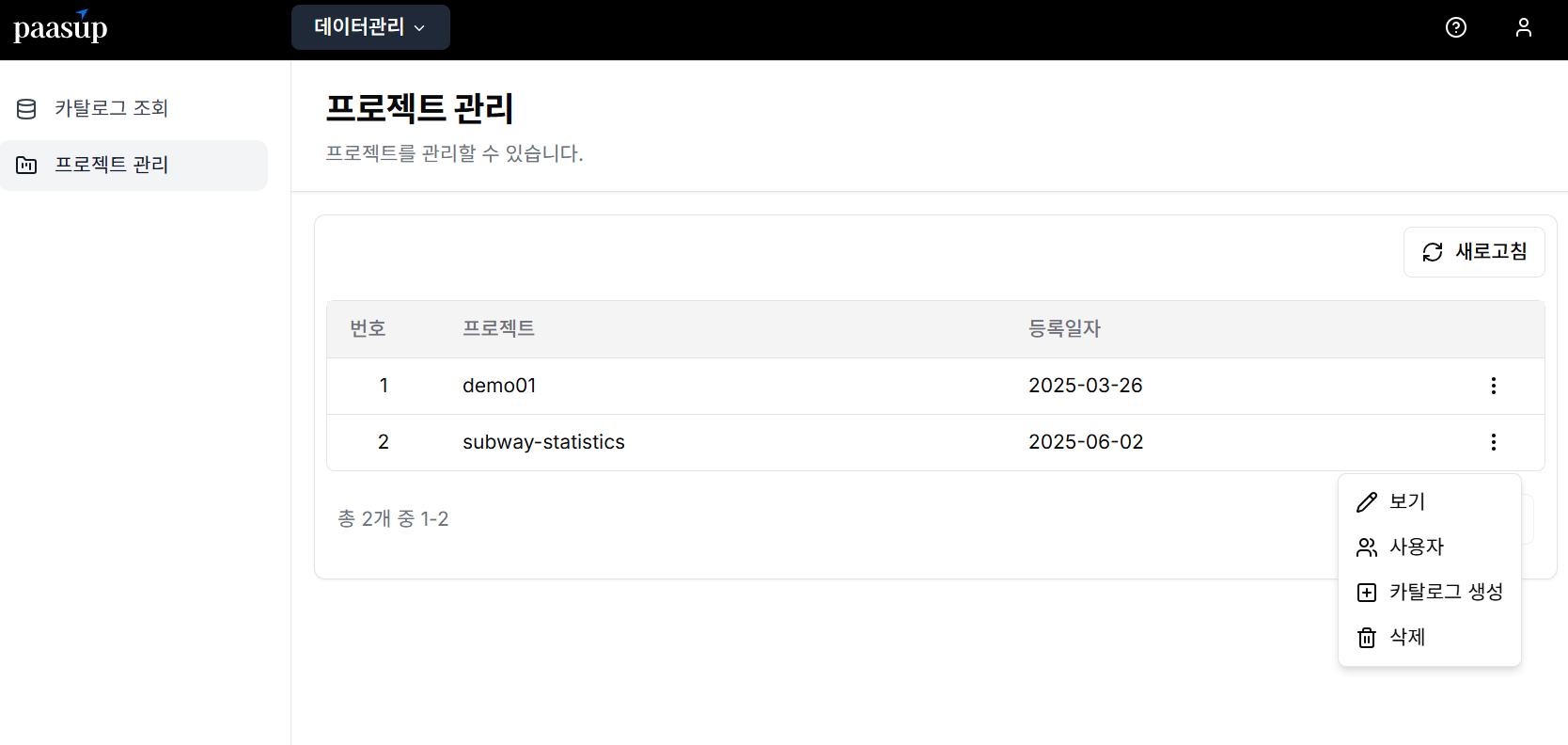
2단계: Kubeflow 카탈로그 생성
- 카탈로그 생성 메뉴에서 Kubeflow 선택
- 카탈로그 버전과 이름을 입력
- 생성 버튼 클릭하여 카탈로그 생성
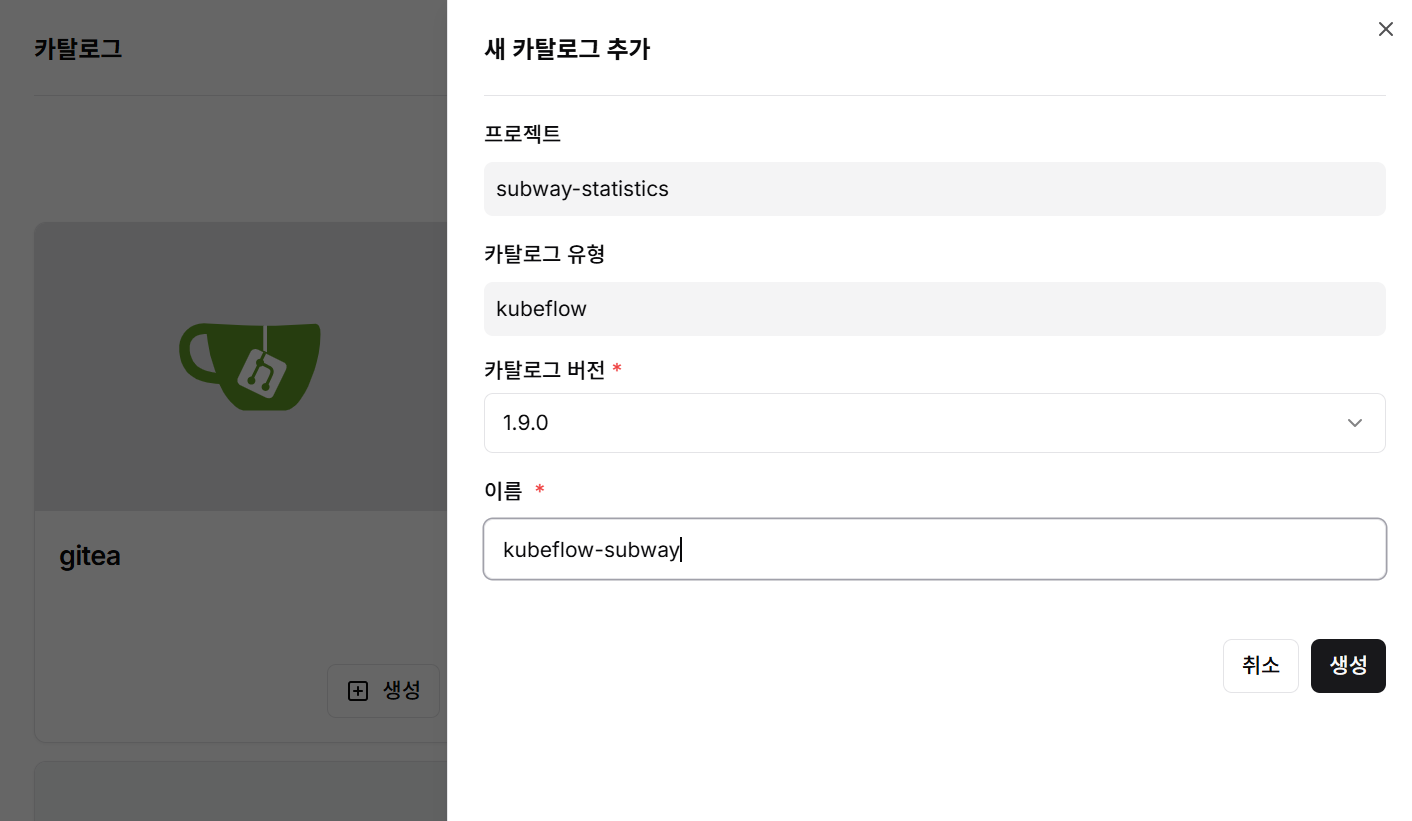
3단계: PostgreSQL 카탈로그 생성
- PostgreSQL 카탈로그 선택
- 카탈로그 버전과 이름을 입력
- 생성 버튼 클릭하여 데이터베이스 환경 구축
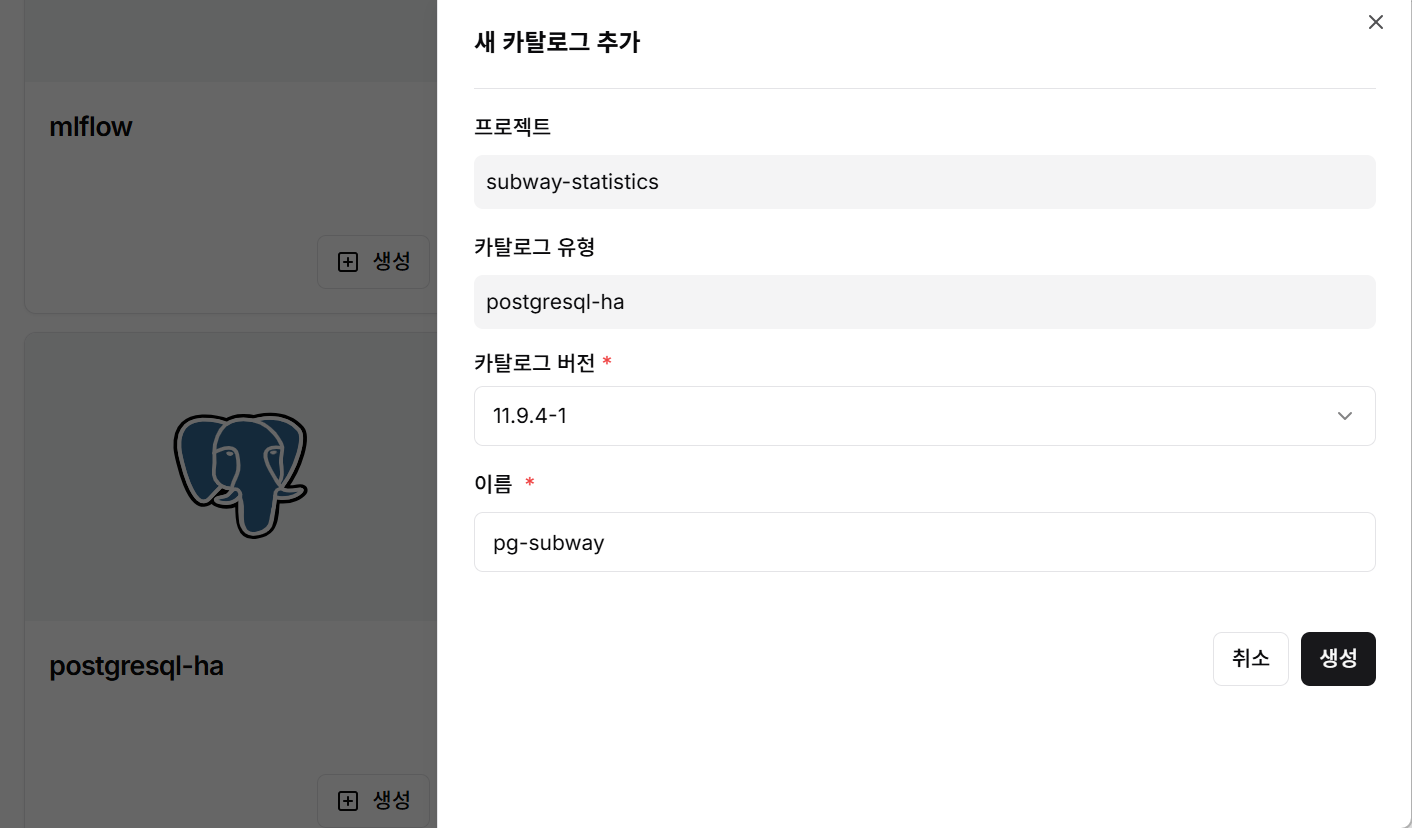
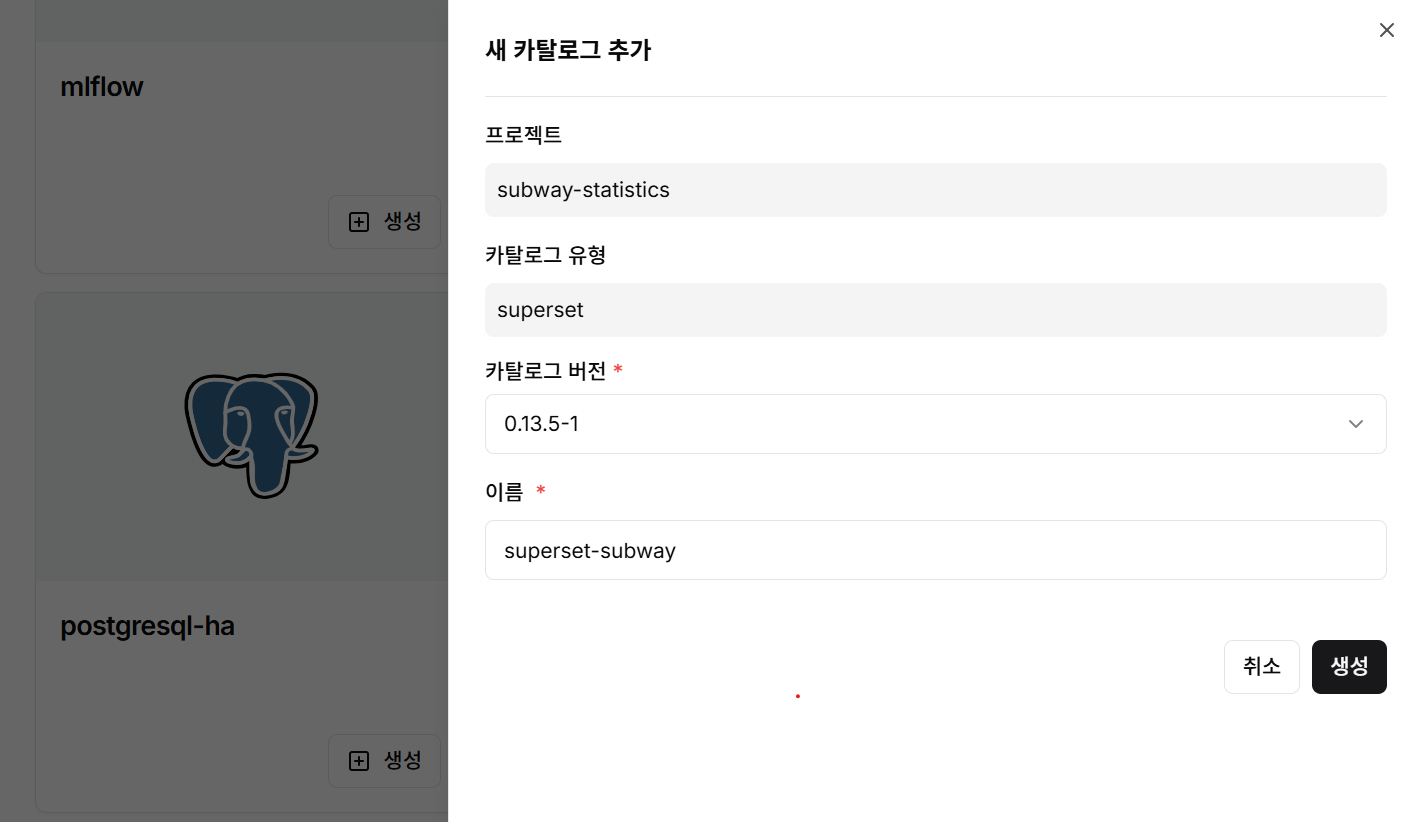
4단계: Superset 카탈로그 생성
- Apache Superset 카탈로그 선택
- 카탈로그 버전과 이름을 입력
- 생성 버튼 클릭하여 시각화 환경 구축
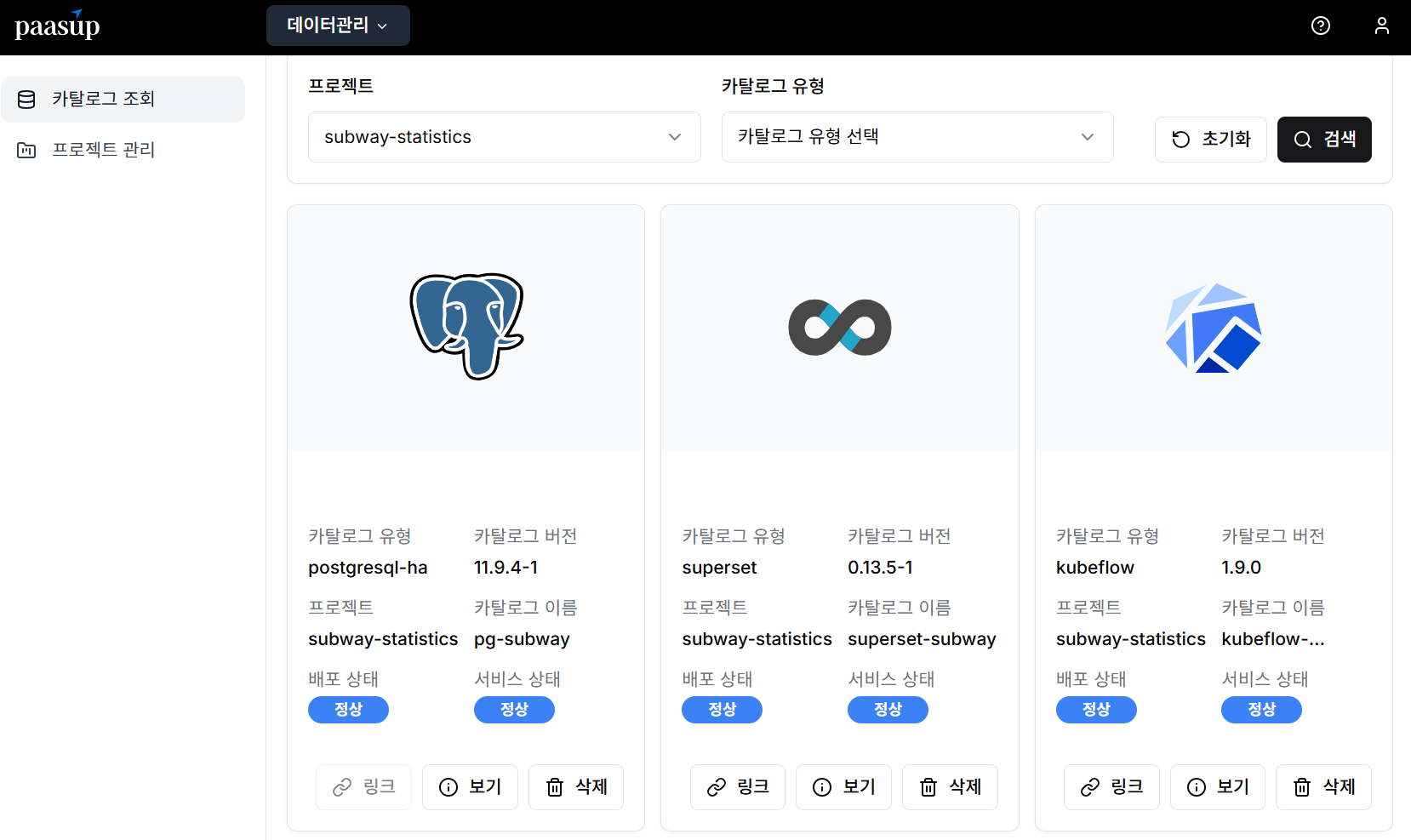
5단계: 카탈로그 상태 확인
카탈로그 조회 화면에서 프로젝트 단위로 생성된 각 카탈로그의 배포 상태와 서비스 상태를 실시간으로 모니터링할 수 있습니다.
6단계: PostgreSQL 접속 정보 확인
애플리케이션에서 PostgreSQL에 접근하기 위한 pg-host, pg-port 정보는 해당 카탈로그의 상세 정보 화면에서 확인 가능합니다.

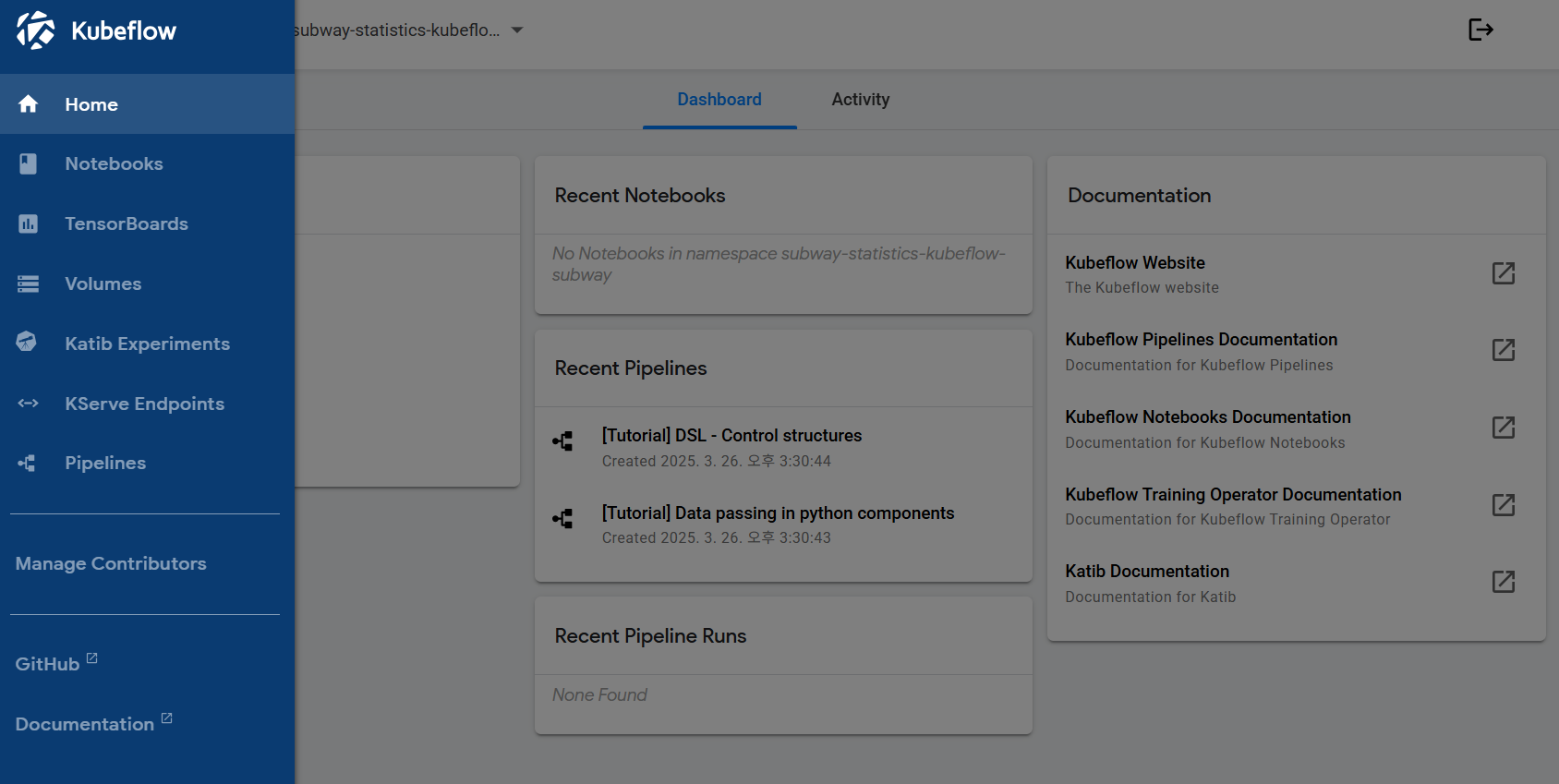
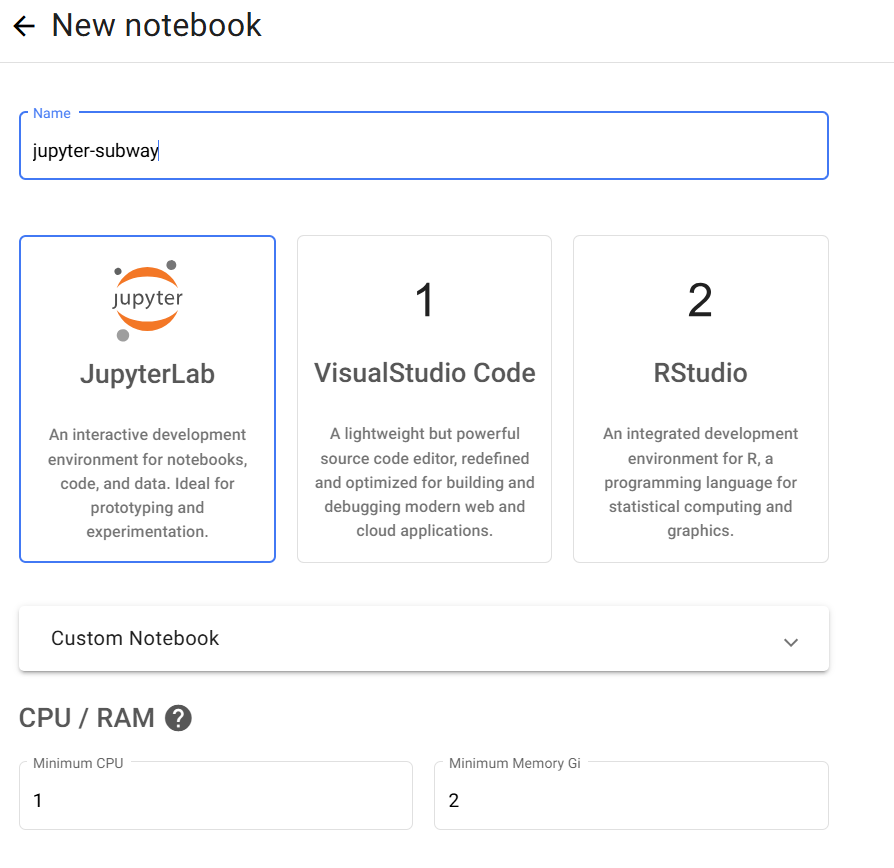
7단계: Jupyter Notebook 환경 생성
Python 코드 개발을 위한 JupyterLab 환경을 구축하려면 Kubeflow 서비스 링크를 통해 노트북 인스턴스를 생성합니다.
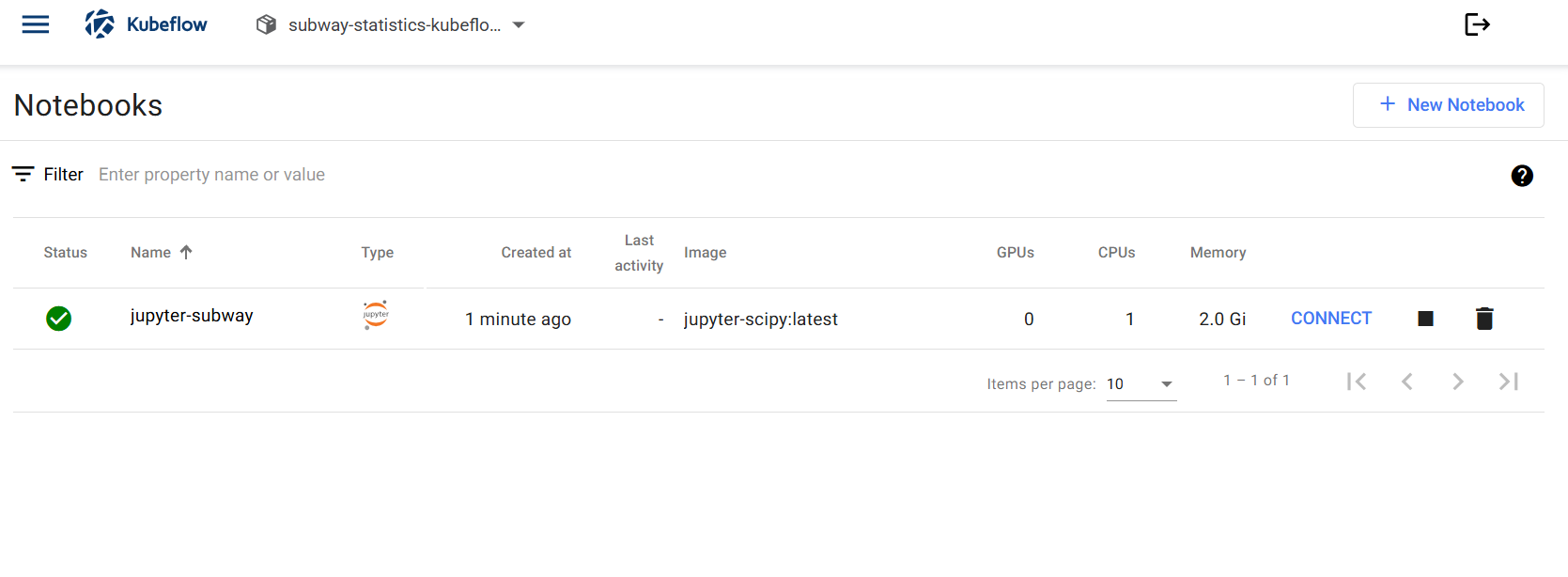
8단계: 개발 환경 접속
Jupyter Notebook의 Connect 링크를 클릭하면 Python 코드를 사용하여 필요한 애플리케이션을 개발할 수 있는 환경에 접속됩니다.
데이터 파이프라인 설계 및 구현
1단계: 데이터 수집 및 전처리
공공데이터포털에서 수집한 CSV 형태의 원시 데이터는 다음과 같은 특징을 가지고 있었습니다:
- 데이터 규모: 10년 4개월간의 일별 집계 데이터
- 소스데이터 정보:
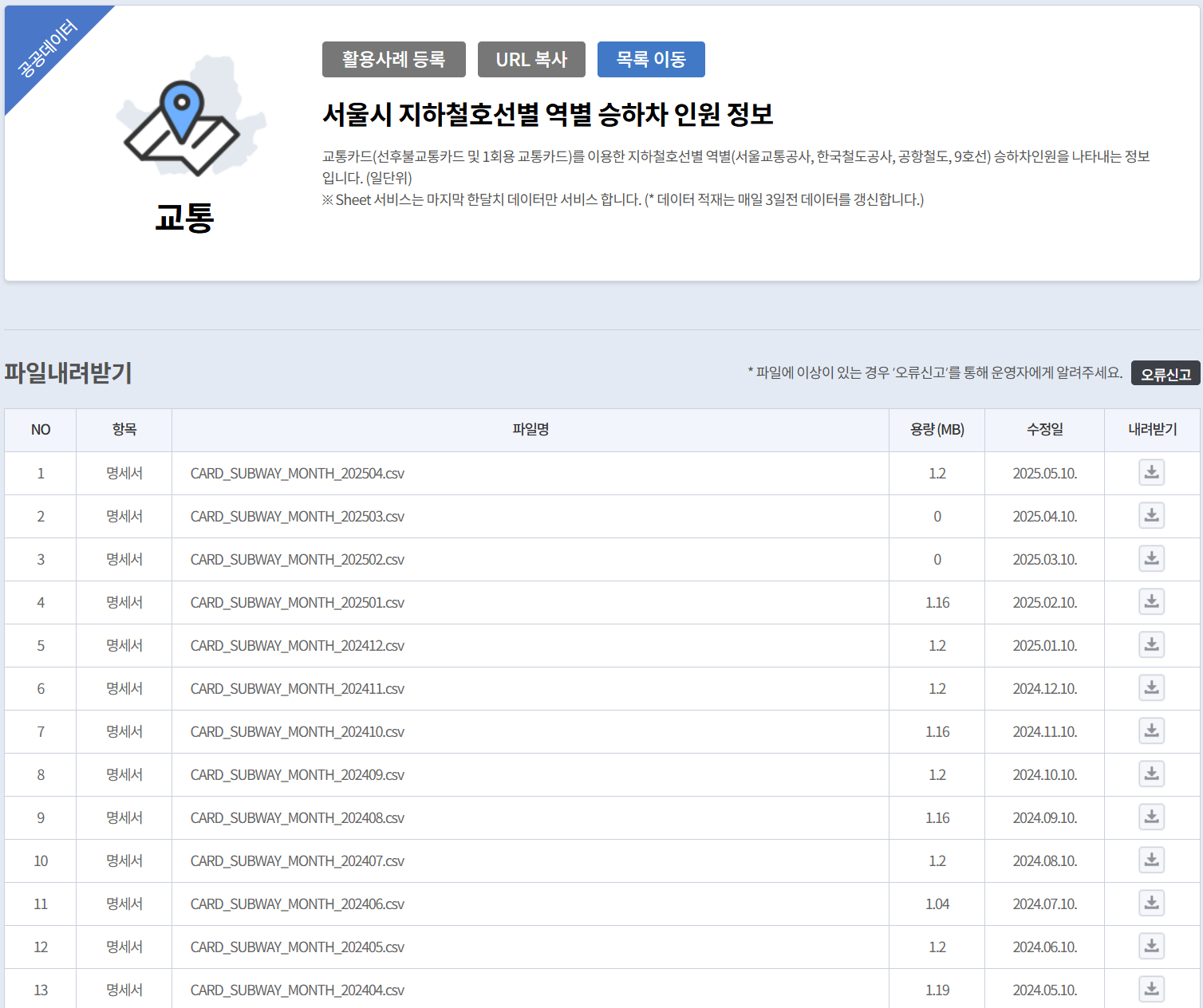
- 노선별/역별/일별 승하차인원 정보(CARD_SUBWAY_MONTH_{WK_YM}.csv) 모든 파일
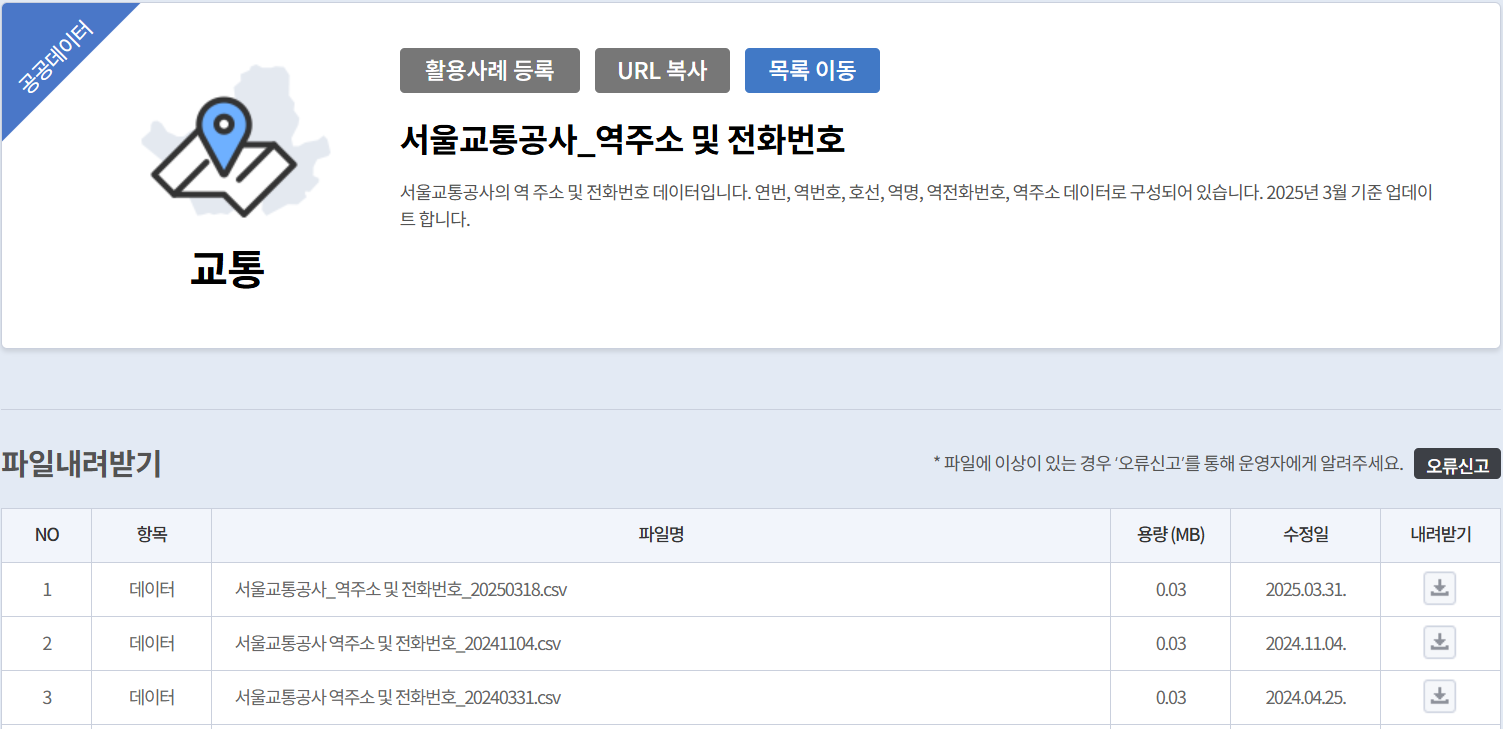
- 전철역 정보 (서울교통공사_노선별 지하철역 정보.csv) 중 최종 파일 1개
- 노선별/역별/일별 승하차인원 정보(CARD_SUBWAY_MONTH_{WK_YM}.csv) 모든 파일
- 데이터 품질 이슈:
- 2개의 소스데이터가 노선명, 전철역명 정보 불일치
- 가끔 한글데이터 깨짐 현상 발생 : excell에서 utf-8, csv로 저장하여 해결함
- 첫번째줄(Label)에 특수문자 있을시 spark error발생 : 특수문자 제거 후 저장함
2단계: PostgreSQL 데이터 마트 모델 생성
분석을 위해 최적화된 PostgreSQL 데이터 모델을 구성:
-- 지하철승하차정보 테이블 생성
CREATE TABLE subway_passengers (
use_date varchar(8) not null , --사용일자
line_no varchar(100) not NULL, -- 노선명
station_name varchar(100) not NULL, --역명
pass_in numeric(13) NULL, --승차인원
pass_out numeric(13) NULL, --하차인원
reg_date varchar(8) null); --
create index subway_passengers_idk1 on subway_passengers (use_date, line_no, station_name);
-- 지하철역정보 테이블 생성
CREATE TABLE subway_info (
station_name varchar(100) not NULL, -- 역명
line_no varchar(100) not NULL, -- 노선명
station_cd varchar(10) , -- 전철역코드 (sort기준)
station_cd_external varchar(10) , -- 전철역코드(외부코드)
station_ename varchar(100) , -- 역명(영문)
station_cname varchar(100) , -- 역명(중문)
station_jname varchar(100) -- 역명(일문)
);
create index subway_info_idk1 on subway_info (station_name, line_no, station_cd);
3단계: Spark 기반 데이터 변환 (CSV → Delta → PostgreSQL)
DIP의 Spark 클러스터를 활용하여 다음과 같은 데이터 변환 작업을 수행했습니다:
load_subway_passengers.ipynb : 지하철승하차정보 데이터 변환
- 필요한 라이브러리 import
from pyspark.sql import SparkSession
from pyspark.conf import SparkConf
from pyspark.sql.functions import lit, substring, col
from delta.tables import DeltaTable
import os
from dotenv import load_dotenv
import psycopg2
import boto3
from botocore.exceptions import ClientError
- Spark Session 생성 함수 : 공통Library
def create_spark_session(app_name, notebook_name, notebook_namespace, s3_access_key, s3_secret_key, s3_endpoint):
conf = SparkConf()
# Spark driver, executor 설정
conf.set("spark.submit.deployMode", "client")
conf.set("spark.executor.instances", "1")
# 중략 ....
# s3, delta, postgresql 사용 시 필요한 jar 패키지 설정
jar_list = ",".join([
"org.apache.hadoop:hadoop-common:3.3.4",
"org.apache.hadoop:hadoop-aws:3.3.4",
"com.amazonaws:aws-java-sdk:1.11.655",
"io.delta:delta-spark_2.12:3.3.1", # Keep if you might use Delta Lake for other operations
"org.postgresql:postgresql:42.7.2" # Added for PostgreSQL
])
conf.set("spark.jars.packages", jar_list)
# 중략 ....
# --- SparkSession 빌드 ---
spark = SparkSession.builder \
.appName(app_name) \
.config(conf=conf) \
.getOrCreate()
return spark
- CSV를 Delta에 저장 후 S3의 CSV파일 이동 함수 : 공통Library
"""
boto3를 사용하여 S3 내에서 파일을 이동(복사 후 삭제)합니다.
"""
s3_client = boto3.client(
's3',
aws_access_key_id=s3_config['access_key'],
aws_secret_access_key=s3_config['secret_key'],
endpoint_url=s3_config['endpoint'],
verify=False # 자체 서명 인증서 사용 시 필요할 수 있음
)
try:
copy_source = {'Bucket': s3_config['bucket'], 'Key': source_key}
print(f"Copying S3 object from {source_key} to {dest_key}...")
s3_client.copy_object(CopySource=copy_source, Bucket=s3_config['bucket'], Key=dest_key)
print(f"Deleting source S3 object: {source_key}...")
s3_client.delete_object(Bucket=s3_config['bucket'], Key=source_key)
print(f"Successfully moved {source_key} to {dest_key}.")
return True
except ClientError as e:
print(f"Error moving S3 file: {e}")
return False
except Exception as e:
print(f"An unexpected error occurred during S3 move: {e}")
return False
- 데이터 처리 메인 함수
데이터소스 파일(CSV)가 월간단위 이기 때문에 증분적재(Append) 및 재작업 가능하도록 구현함
def subway_data_append(spark, s3_config, pg_config): #pg_config, pg_table, pg_url, pg_properties, delete_sql, insert_sql):
"""
CSV--> DELTA --> POSTGRESQL 처리하는 메인 파이프라인
"""
pg_url = f"jdbc:postgresql://{pg_config['host']}:{pg_config['port']}/{pg_config['dbname']}"
pg_properties = {
"user": pg_config['user'],
"password": pg_config['password'],
"driver": "org.postgresql.Driver"
}
print(f" bucket name is {s3_config['bucket']}")
csv_source_key = f"datasource/CARD_SUBWAY_MONTH_{WK_YM}.csv"
csv_archive_key = f"archive/CARD_SUBWAY_MONTH_{WK_YM}.csv"
csv_s3_path = f"s3a://{s3_config['bucket']}/{csv_source_key}"
delta_s3_path = f"s3a://{s3_config['bucket']}/{s3_config['delta_path']}"
try:
print(f"\n--- Starting processing for {pg_config['table']} during '{WK_YM}' ---")
# --- 단계 1: S3 CSV 읽기 ---
print(f"Reading CSV from {csv_s3_path}...")
# CSV 스키마나 옵션(overwrite, inferSchema...)은 소스 파일에 맞게 조정
csv_df = spark.read.option("header", "true").option("overwriteSchema", "true").csv(csv_s3_path)
# '사용일자' 컬럼이 YYYYMMDD 형식이라고 가정
# 필요시 yyyymm 컬럼을 추가하거나 기존 컬럼을 확인
# csv_df = csv_df.withColumn("operation_month", lit(yyyymm)) # 필요시 추가
csv_df.createOrReplaceTempView("subway_data")
print(f"CSV for {WK_YM} loaded. Count: {csv_df.count()}")
csv_df.show(5)
# --- 단계 2: Delta Lake에 삭제 후 삽입 (Spark SQL 사용) ---
print(f"Deleting old data for {WK_YM} from Delta table: {delta_s3_path}")
if DeltaTable.isDeltaTable(spark, delta_s3_path):
# '사용일자' 컬럼 형식에 맞게 WHERE 조건 수정
print(f" Delta Table {delta_s3_path} 있음")
delete_delta_sql = f"delete from delta.`{delta_s3_path}` where `사용일자` like '{WK_YM}'||'%' "
delta_mode = "append"
try:
spark.sql(delete_delta_sql)
print(f"Deletion from Delta complete. Inserting new data for {WK_YM}...")
except Exception as e:
print(f"Skip on error occurred during Delta DELETE, even though table exists: {e}")
raise # 예상치 못한 오류는 다시 발생시킴
else:
print(f" Delta Table {delta_s3_path} 없음")
delta_mode = "overwrite"
# DataFrame API로 쓰기 (SQL INSERT INTO도 가능하지만, DF API가 S3 쓰기에 더 일반적)
csv_df.write.format("delta").mode(delta_mode).save(delta_s3_path)
print(f"Successfully wrote data to Delta table {delta_s3_path}.")
# --- 단계 3: S3 CSV 파일 이동 ---
print(f"Archiving S3 CSV file...")
move_s3_file(s3_config, csv_source_key, csv_archive_key)
# --- 단계 4: PostgreSQL에 삭제 후 삽입 ---
pg_table_name = pg_config['table']
print(f"Deleting old data for {WK_YM} from PostgreSQL table: {pg_table_name}")
conn = None
cursor = None
conn = psycopg2.connect (
host=pg_config['host'],
port=pg_config['port'],
dbname=pg_config['dbname'],
user=pg_config['user'],
password=pg_config['password'] )
cursor = conn.cursor()
delete_sql = f" delete from {pg_table_name} where use_date like '{WK_YM}'||'%' "
print(f"Executing DELETE query: {delete_sql}")
cursor.execute(delete_sql)
deleted_rows = cursor.rowcount
if cursor: cursor.close()
if conn:
conn.commit()
conn.close()
print(f"Successfully executed DELETE query. {deleted_rows} rows deleted.")
print(f"Inserting data for {WK_YM} into PostgreSQL table: {pg_table_name}")
# 데이터를 가공할 Spark SQL 쿼리
insert_sql = f"""
select `사용일자` use_date
,`노선명` line_no
,`역명` station_name
,cast(`승차총승객수` as int) pass_in
,cast(`하차총승객수` as int) pass_out
,substring(`등록일자`,1,8) reg_date
from delta.`{delta_s3_path}`
where `사용일자` like '{WK_YM}'||'%'
"""
print(insert_sql)
delta_df = spark.sql(insert_sql)
delta_df.write \
.jdbc(url=pg_url,
table=pg_table_name,
mode="append",
properties=pg_properties)
print(f"Successfully wrote data to PostgreSQL table {pg_table_name}.")
print(f"--- Processing for {WK_YM} completed successfully! ---")
except Exception as e:
print(f"An error occurred during processing {WK_YM}: {e}")
import traceback
traceback.print_exc()
- 메인 실행 블록
# --- 메인 실행 블록 ---
if __name__ == "__main__":
# input parameters from airflow (WK_YM)
# Pod 내의 .env 파일에서 환경변수 read
dotenv_path = './config/.env'
load_dotenv(dotenv_path=dotenv_path)
# --- APP구성 변수 설정 ---
APP_NAME = 'load_subway_passengers'
NOTEBOOK_NAME = "test"
NOTEBOOK_NAMESPACE = "demo01-kf"
S3_CONFIG = {
"access_key": os.getenv("S3_ACCESS_KEY"),
"secret_key": os.getenv("S3_SECRET_KEY"),
"endpoint": os.getenv("S3_ENDPOINT_URL"),
"bucket": os.getenv("S3_BUCKET_NAME"),
"delta_path": "deltalake/subway_passengers" # S3 버킷 내 Delta target 테이블 경로
}
PG_CONFIG = {
"host": os.getenv("PG_HOST"),
"port": os.getenv("PG_PORT", "5432"), # 기본값 5432 지정
"dbname": os.getenv("PG_DB"),
"user": os.getenv("PG_USER"),
"password": os.getenv("PG_PASSWORD"),
"table": "subway_passengers" # PostgreSQL target 테이블 이름
}
# SparkSession 생성
spark = create_spark_session(
app_name=APP_NAME,
notebook_name=NOTEBOOK_NAME,
notebook_namespace=NOTEBOOK_NAMESPACE,
s3_access_key=S3_CONFIG['access_key'],
s3_secret_key=S3_CONFIG['secret_key'],
s3_endpoint=S3_CONFIG['endpoint']
)
# 데이터 처리 실행
subway_data_append(spark, S3_CONFIG, PG_CONFIG)
# SparkSession 종료
spark.stop()
print("Spark session stopped.")
load_subway_info.ipynb : 지하철역 정보 데이터 변환
- 필요한 라이브러리 import : 상동
- Spark Session 생성 함수 : 공통Library
- CSV를 Delta에 저장 후 S3의 CSV파일 이동 함수 : 공통Library
- 데이터 처리 메인 함수 : master정보이므로 overwrite
def subway_info_overwrite(spark, s3_config, pg_config):
"""
CSV--> DELTA --> POSTGRESQL 처리하는 메인 파이프라인
"""
pg_url = f"jdbc:postgresql://{pg_config['host']}:{pg_config['port']}/{pg_config['dbname']}"
pg_properties = {
"user": pg_config['user'],
"password": pg_config['password'],
"driver": "org.postgresql.Driver"
}
print(f" bucket name is {s3_config['bucket']}")
csv_source_key = f"datasource/서울교통공사_노선별 지하철역 정보.csv"
csv_archive_key = f"archive/서울교통공사_노선별 지하철역 정보.csv"
csv_s3_path = f"s3a://{s3_config['bucket']}/{csv_source_key}"
delta_s3_path = f"s3a://{s3_config['bucket']}/{s3_config['delta_path']}"
try:
print(f"\n--- Starting processing for {pg_config['table']} ---")
# --- 단계 1: S3 CSV 읽기 ---
print(f"Reading CSV from {csv_s3_path}...")
# CSV 스키마나 옵션(overwrite, inferSchema...)은 소스 파일에 맞게 조정
csv_df = spark.read.option("header", "true").option("overwriteSchema", "true").csv(csv_s3_path)
csv_df.createOrReplaceTempView("subway_info")
csv_df.show(5)
print(f"CSV loaded. Count: {csv_df.count()}")
# --- 단계 2: Delta Lake에 저장 (Spark SQL 사용) ---
csv_df.write.format("delta").mode("overwrite").save(delta_s3_path)
print(f"Successfully wrote data to Delta table {delta_s3_path}.")
# --- 단계 3: S3 CSV 파일 이동 ---
print(f"Archiving S3 CSV file...")
move_s3_file(s3_config, csv_source_key, csv_archive_key)
# --- 단계 4: PostgreSQL에 삭제 후 삽입 ---
pg_table_name = pg_config['table']
print(f"Inserting data into PostgreSQL table: {pg_table_name}")
# 데이터를 가공할 Spark SQL 쿼리
insert_sql = f"""
select `전철역명` station_name
,`전철역코드` station_cd
,`전철명명_영문` station_ename
,`전철명명_중문` station_cname
,`전철명명_일문` station_jname
,`외부코드` station_cd_external
, case when substring(`호선`,1,1) = '0' then substring(`호선`,2,length(`호선`)-1)
when `호선` = '공항철도' then '공항철도 1호선'
when `호선` = '수인분당선' then '수인선'
when `호선` = '신분당선' then '분당선'
when `호선` = '우이신설경전철' then '우이신설선'
else `호선` end line_no
from delta.`{delta_s3_path}`
"""
print(insert_sql)
delta_df = spark.sql(insert_sql)
delta_df.write \
.jdbc(url=pg_url,
table=pg_table_name,
mode="overwrite",
properties=pg_properties)
print(f"Successfully wrote data to PostgreSQL table {pg_table_name}.")
print("--- Processing for completed successfully! ---")
except Exception as e:
print(f"An error occurred during processing : {e}")
import traceback
traceback.print_exc()
- 메인 실행 블록
# --- 메인 실행 블록 ---
if __name__ == "__main__":
# Pod 내의 .env 파일에서 환경변수 read
dotenv_path = './config/.env'
load_dotenv(dotenv_path=dotenv_path)
# --- APP구성 변수 설정 ---
APP_NAME = 'load_subway_info'
NOTEBOOK_NAME = "test"
NOTEBOOK_NAMESPACE = "demo01-kf"
S3_CONFIG = {
"access_key": os.getenv("S3_ACCESS_KEY"),
"secret_key": os.getenv("S3_SECRET_KEY"),
"endpoint": os.getenv("S3_ENDPOINT_URL"),
"bucket": os.getenv("S3_BUCKET_NAME"),
"delta_path": "deltalake/subway_info" # S3 버킷 내 Delta target 테이블 경로
}
PG_CONFIG = {
"host": os.getenv("PG_HOST"),
"port": os.getenv("PG_PORT", "5432"), # 기본값 5432 지정
"dbname": os.getenv("PG_DB"),
"user": os.getenv("PG_USER"),
"password": os.getenv("PG_PASSWORD"),
"table": "subway_info" # PostgreSQL target 테이블 이름
}
# SparkSession 생성
spark = create_spark_session(
app_name=APP_NAME,
notebook_name=NOTEBOOK_NAME,
notebook_namespace=NOTEBOOK_NAMESPACE,
s3_access_key=S3_CONFIG['access_key'],
s3_secret_key=S3_CONFIG['secret_key'],
s3_endpoint=S3_CONFIG['endpoint']
)
# 데이터 처리 실행
subway_info_overwrite(spark, S3_CONFIG, PG_CONFIG)
# SparkSession 종료
spark.stop()
print("Spark session stopped.")
주요 클린징 작업:
- 컬럼명 표준화: Delta --> PostgreSQL 작업시 한글 레이블을 영문 컬럼으로 변경하여 시스템 호환성 확보
- 데이터 정합성 확보: 전철 이용객수 데이터와 전철역 정보 데이터 간 불일치 해결
- 역명 표준화 (공백, 특수문자 처리)
- 노선명 통일 (표기 방식 일관성 확보)
- 데이터 타입 최적화: 숫자 컬럼의 적절한 데이터 타입 변환
프로젝트 결과 및 시사점
주요 분석 결과
1. 노선별 이용 패턴
- 2호선과 9호선이 가장 높은 이용률을 보임
- 강남구 중심의 노선들이 상대적으로 높은 이용객수 기록
- 분당선, 경의선 등 광역노선의 꾸준한 이용률 증가 추세
2. 역별 이용 특성
- 강남역, 홍대입구역, 건대입구역 등 주요 상권 거점역이 최고 이용률 기록
- 환승역의 경우 단일노선 역 대비 2-3배 높은 이용객수 관찰
- 주거밀집지역 근처 역들의 안정적인 이용 패턴 확인
3. 기간별 추이 분석
- 최근 3년간 전체적으로 10-15% 이용객수 증가 추세
- COVID-19 영향으로 2020-2021년 일시적 감소 후 빠른 회복
- 계절별로는 봄, 가을철 이용객수가 상대적으로 높음
4. 요일별 이용 특성
- 평일(월-금) 대비 주말(토-일) 이용객수는 약 25-30% 감소
- 금요일이 주중 최고 이용률을 기록하며 주말 여가활동 패턴 반영
- 월요일의 경우 다른 평일 대비 약간 낮은 이용률 관찰
비즈니스 인사이트
교통 정책 관점
- 노선별 이용률 격차를 고려한 차별화된 운영 전략 필요
- 주요 환승역 중심의 인프라 확충 우선순위 도출
- 요일별 패턴을 반영한 탄력적 배차 운영 방안 모색
상권 분석 관점
- 역세권별 유동인구 데이터를 활용한 상권 포텐셜 평가
- 요일별 이용 패턴과 업종별 매출 연관성 분석 가능
- 신규 매장 입지 선정 시 객관적 지표로 활용 가능
도시계획 관점
- 고이용률 노선 주변 지역의 개발 잠재력 평가
- 저이용률 구간의 도시재생 및 활성화 방안 모색
- 교통 인프라 투자 우선순위 결정을 위한 데이터 기반 근거 제공
기술적 성과
플랫폼 활용 효과
- DIP 포털을 통한 신속한 환경 구축 (기존 대비 80% 시간 단축)
- Kubeflow 기반 자동화된 파이프라인으로 운영 효율성 향상
- Superset을 활용한 신속한 모니터링 대시보드 구축
확장성 확보
- 다른 교통 데이터(버스, 택시 등)와의 통합 분석 기반 마련
- 실시간 스트리밍 데이터 처리 아키텍처로 확장 가능
- 머신러닝 모델 적용을 통한 예측 분석 준비
향후 발전 방향
단기 계획
- 시간대별 데이터 확보를 통한 출퇴근 패턴 분석
- 역별 세부 분석 확대 및 지역별 특성 분석 강화
- 계절별, 월별 상세 트렌드 분석 추가
중장기 계획
- 날씨, 이벤트 등 외부 요인과의 상관관계 분석
- AI/ML 모델을 활용한 이용객수 예측 시스템 구축
- 정책 시뮬레이션 및 의사결정 지원 시스템 개발
결론
본 프로젝트를 통해 지하철 이용 데이터가 단순한 교통 정보를 넘어 도시의 생활 패턴과 경제 활동을 이해하는 중요한 지표임을 확인할 수 있었습니다. DIP 포털의 통합 환경을 활용함으로써 기술적 복잡성을 최소화하면서도 고도화된 데이터 분석 시스템을 구축할 수 있었습니다.
이러한 분석 결과는 궁극적으로 시민들의 삶의 질 향상과 더 나은 도시 환경 조성에 기여할 수 있는 의미있는 데이터 기반 인사이트를 제공한다고 할 수 있습니다.