
파스업DIP로 구현하는 현대적 데이터 파이프라인: 지하철 이용자 통계 분석 프로젝트 #2
Jupyter Notebook 개발 환경에서 Airflow 운영 환경으로 전환한 지하철 데이터 파이프라인 자동화 프로젝트를 소개합니다. Kubernetes Secret 활용한 보안 강화와 Spark Kubernetes Operator를 통한 스케줄링 기반 워크플로우 구축을 구현했습니다.
들어가며
이전 블로그(파스업DIP로 구현하는 현대적 데이터 파이프라인: 지하철 이용자 통계 분석 프로젝트#1)에서는 Jupyter Notebook 환경에서 Spark Session을 생성하여 데이터 파이프라인을 구현했습니다.
이번 시리즈에서는 DIP의 프로젝트 서비스 카탈로그 중 하나인 Airflow를 활용하여, 실제 운영 환경에서 데이터 파이프라인을 구현하고 실행하는 과정을 다루겠습니다. Airflow DAGs를 통한 워크플로우 관리와 스케줄링 기능을 중심으로 설명하겠습니다.
목차
1. 프로젝트 개요
목표
개발 단계의 Jupyter Notebook 환경을 넘어서 Airflow 운영 환경에서 '지하철 이용자 통계 분석 프로젝트'의 데이터 파이프라인을 구현하고 자동화된 워크플로우를 구축합니다.
기술 스택
- 데이터 처리: Apache Spark
- 데이터 저장: Delta Lake, PostgreSQL
- 시각화: Apache Superset
- 운영 환경: Airflow
- 플랫폼: DIP 포털
2. Airflow 카탈로그 배포
- 프로젝트 카탈로그 생성
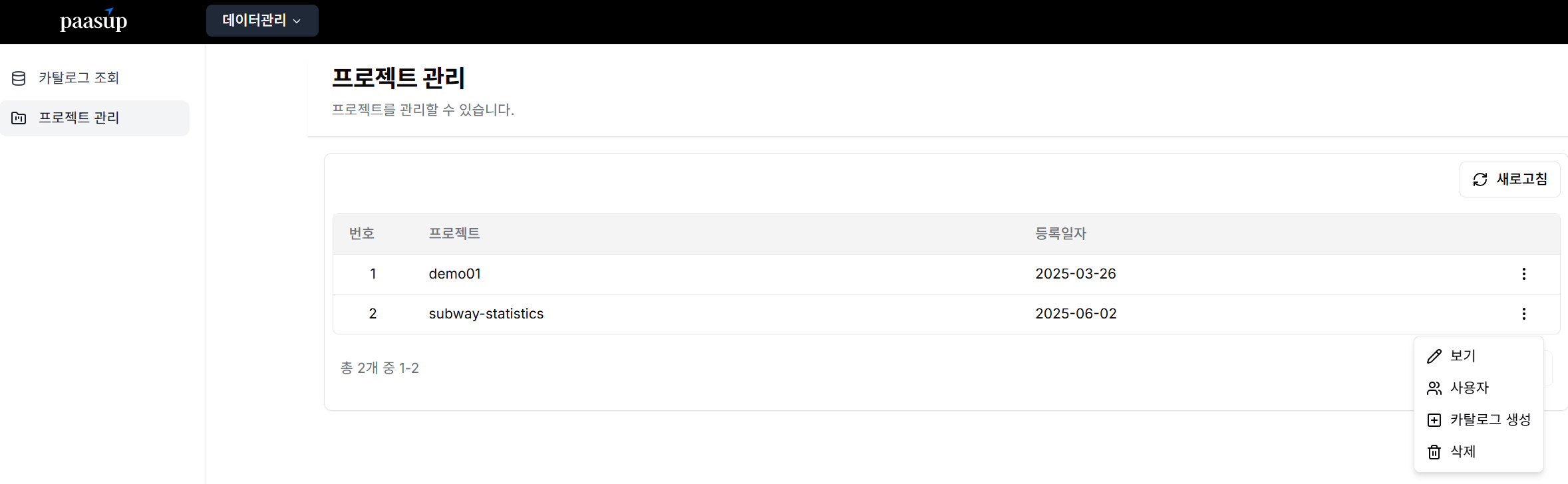
- Airflow를 선택한 후 버전과 인스턴스명을 정의한 후 배포
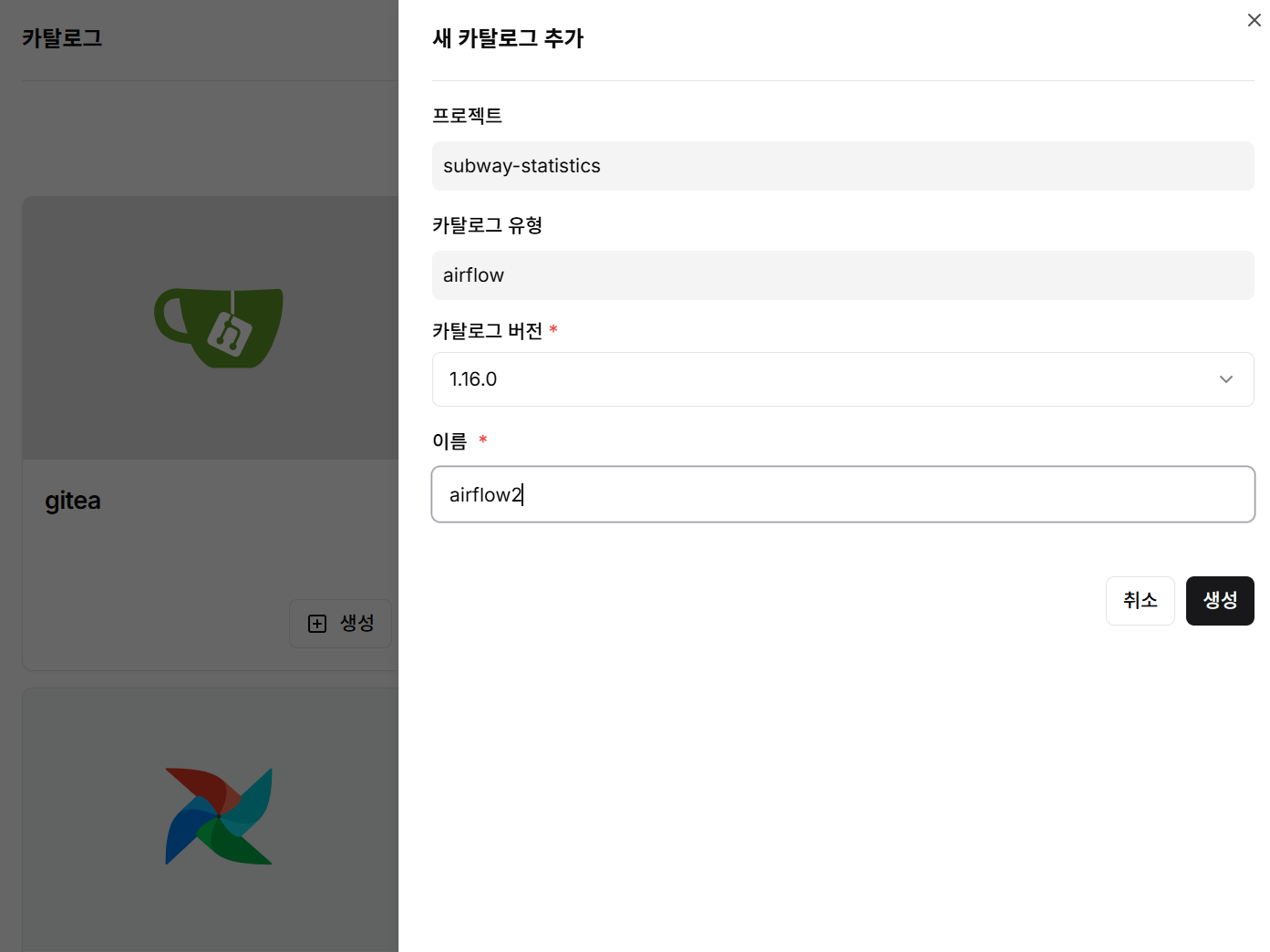
- 정상적으로 배포되었는지 카탈로그 조회
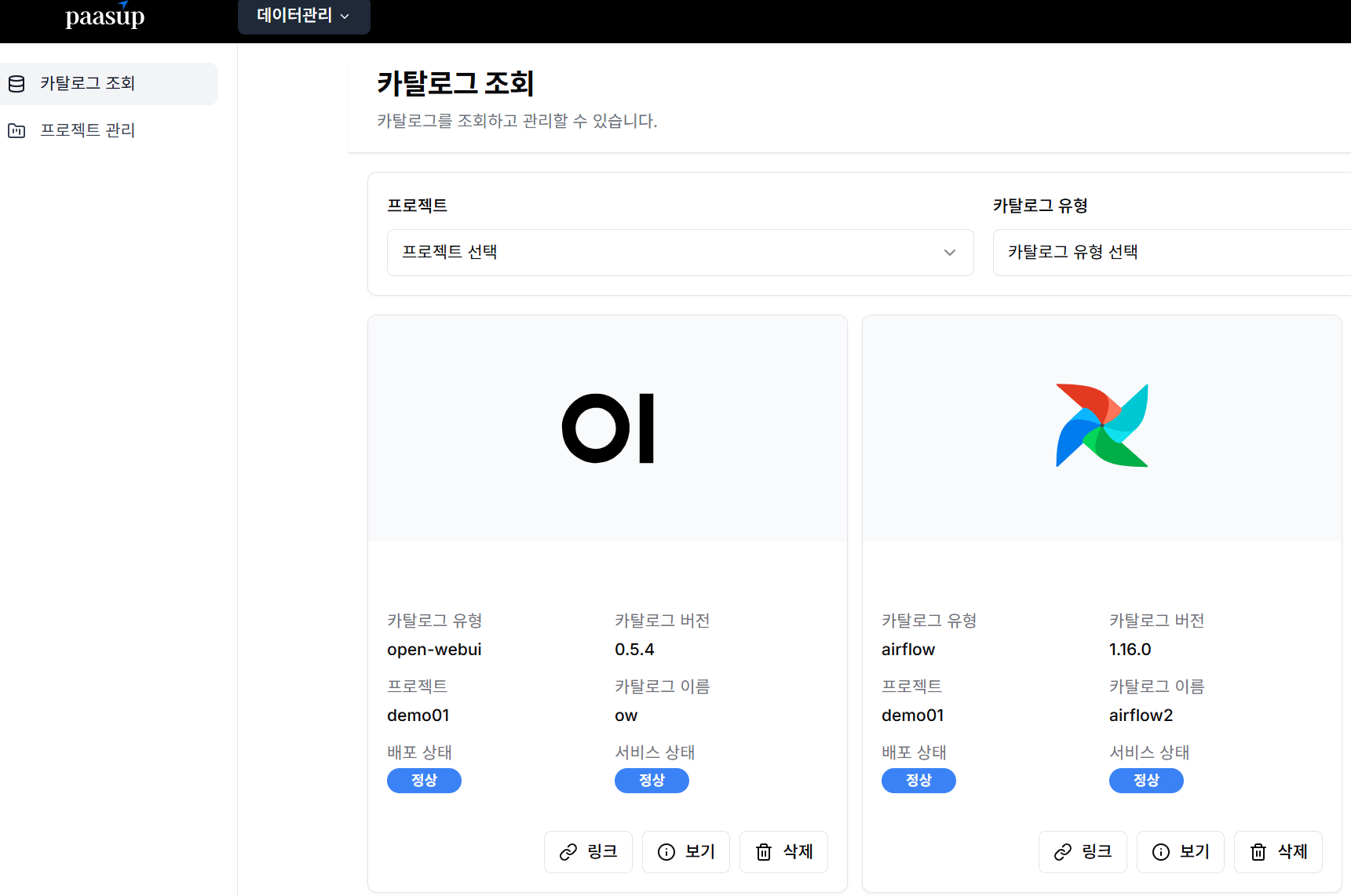
3. 데이터 파이프라인 수정
환경변수 설정
Jupyter Notebook 환경에서는 .env 파일을 통해 S3와 PostgreSQL 접속 정보를 관리했습니다. 하지만 Airflow 운영 환경에서는 보안과 관리의 효율성을 위해 Kubernetes Secret을 활용합니다. 민감한 접속 정보들을 Secret으로 생성하여 spark-app.yaml에서 안전하게 참조할 수 있습니다.
$ export NAMESPACE="spark-job"
# S3 Secret 생성
$ kubectl create -n $NAMESPACE secret generic s3-secret \
--from-literal=AWS_ACCESS_KEY_ID={your_s3_accesskey} \
--from-literal=AWS_SECRET_ACCESS_KEY={your_s3_secretKey} \
--from-literal=AWS_ENDPOINT_URL={your_s3_endpoint_url}
# PostgreSQL Secret 생성
$ kubectl create -n $NAMESPACE secret generic pg-secret \
--from-literal=PG_HOST={your_pg_host} \
--from-literal=PG_PORT={your_pg_port} \
--from-literal=PG_DB={your_pg_dbname} \
--from-literal=PG_USER={your_pg_user} \
--from-literal=PG_PASSWORD={your_pg_password}
DAG 파일 작성
Airflow DAG은 워크플로우의 구조와 실행 스케줄을 정의하는 핵심 요소입니다. 여기서는 지하철 승객 데이터를 처리하는 Spark 작업을 위한 DAG을 구성하며, 사용자가 실행 시점에 처리할 년월 데이터를 파라미터로 입력할 수 있도록 설계합니다.
from datetime import datetime, timedelta
from airflow import DAG
from airflow.models.param import Param
from airflow.providers.cncf.kubernetes.operators.spark_kubernetes import SparkKubernetesOperator
from airflow.providers.cncf.kubernetes.sensors.spark_kubernetes import SparkKubernetesSensor
dag = DAG(
dag_id="load_subway_passengers",
default_args={'max_active_runs': 1},
description='Submit deltalake example as SparkApplication on Kubernetes',
schedule_interval=timedelta(days=1),
start_date=datetime(2025, 6, 1),
catchup=False,
# DAG 레벨에서 파라미터 정의
params={
"WK_YM": Param(
default="202504",
type="string",
description="작업 년월 (YYYYMM 형식)"
)
}
)
t1 = SparkKubernetesOperator(
task_id='load_subway_passengers',
namespace="demo01-spark-job",
application_file="./spark-app.yaml",
# 환경변수나 template_fields를 통해 파라미터 전달
dag=dag
)
t1
Spark Application YAML 작성
SparkApplication YAML 파일은 Kubernetes 환경에서 Spark 작업을 실행하기 위한 리소스 정의서입니다. 이 파일에서는 Spark 클러스터 구성, 리소스 할당, 환경변수 설정, 그리고 Git 리포지토리에서 Python 스크립트를 동적으로 가져오는 설정을 포함합니다.
apiVersion: "sparkoperator.k8s.io/v1beta2"
kind: SparkApplication
metadata:
name: load-subway-passengers-{{ params.WK_YM if params.WK_YM else data_interval_start.in_timezone("Asia/Seoul").strftime("%Y%m") }}
namespace: demo01-spark-job
spec:
type: Python
pythonVersion: "3"
mode: cluster
image: paasup/spark-offline:3.5.2-java17-python3.11-3
imagePullPolicy: IfNotPresent
mainApplicationFile: local:///git/dip-usecase/dags/load_subway_passengers/load_subway_passengers.py # Git 리포지토리에 맞춰 변경 필요
sparkVersion: "3.5.2"
sparkConf:
spark.driver.extraJavaOptions: "-Divy.cache.dir=/tmp -Divy.home=/tmp -Dcom.amazonaws.sdk.disableCertChecking=true -Duser.timezone=Asia/Seoul"
spark.executor.extraJavaOptions: "-Dcom.amazonaws.sdk.disableCertChecking=true -Duser.timezone=Asia/Seoul"
spark.hadoop.fs.s3a.endpoint: "https://172.16.50.29:9000"
spark.hadoop.fs.s3a.impl: "org.apache.hadoop.fs.s3a.S3AFileSystem"
spark.hadoop.fs.s3a.path.style.access: "True"
spark.hadoop.fs.s3a.connection.ssl.enabled: "True"
spark.hadoop.fs.s3a.aws.credentials.provider: "EnvironmentVariableCredentialsProvider"
spark.sql.extensions: "io.delta.sql.DeltaSparkSessionExtension"
spark.sql.catalog.spark_catalog: "org.apache.spark.sql.delta.catalog.DeltaCatalog"
spark.kubernetes.driverEnv.WK_YM: "{{ params.WK_YM if params.WK_YM else data_interval_start.in_timezone("Asia/Seoul").strftime("%Y%m") }}"
# 도커 이미지에 jar 파일을 포함시켜 아래 설정이 필요 없음
# 이미지 내에 jar 파일이 있더라도 아래 설정을 추가하면 다운로드를 시도하여 이미지 내에 있을 때는 제외시켜야 함
spark.jars.packages: "org.apache.hadoop:hadoop-common:3.3.4,org.apache.hadoop:hadoop-aws:3.3.4,com.amazonaws:aws-java-sdk-bundle:1.12.262,io.delta:delta-spark_2.12:3.3.1,org.postgresql:postgresql:42.7.2"
timeToLiveSeconds: 120
restartPolicy:
type: Never
volumes:
- name: git-volume
emptyDir: {}
driver:
cores: 1
coreLimit: "1200m"
memory: "2048m"
labels:
version: 3.5.2
serviceAccount: spark
volumeMounts:
- mountPath: /git
name: git-volume
# airflow-dags 리포지토리에서 Spark를 실행시킬 Python 스크립트를 가져오기 위한 initContainer
initContainers:
- name: "init-clone-repo"
image: bitnami/git:2.40.1-debian-11-r2
imagePullPolicy: IfNotPresent
command:
- /bin/bash
args:
- -ec
- git clone https://github.com/paasup/dip-usecase.git --branch main /git/dip-usecase # Git 리포지토리에 맞춰 설정 필요
volumeMounts:
- mountPath: /git
name: git-volume
#envFrom:
#- secretRef:
#name: git-secret # 생성 필요. Public 리포지토리 대상시 제외
envFrom:
- secretRef:
name: s3-secret # 사용할 S3 또는 MinIO 접속 정보를 생성
- secretRef:
name: pg-secret # 사용할 PostgreSQL 접속 정보를 생성
executor:
instances: 1
cores: 1
memory: "2g"
labels:
version: 3.5.2
Python 스크립트 수정
기존 Jupyter Notebook에서 작성한 데이터 파이프라인 코드를 Airflow 환경에서 실행 가능하도록 수정해야 합니다. 주요 변경사항은 실행 환경 감지, 파라미터 처리 방식 개선, 그리고 파일 형식 변환입니다.
1. 실행 환경 감지 함수 구현
개발과 운영 환경에서 동일한 코드를 사용하기 위해 현재 실행 환경이 Jupyter Notebook인지 감지하는 함수를 구현합니다. 이를 통해 환경에 따라 다른 파라미터 처리 로직을 적용할 수 있습니다.
def is_running_in_jupyter():
try:
# IPython 환경인지 확인
shell = get_ipython().__class__.__name__
if shell == 'ZMQInteractiveShell':
return True # Jupyter Notebook 또는 QtConsole
elif shell == 'TerminalInteractiveShell':
return False # 터미널에서 실행되는 IPython
else:
return False # 기타 환경
except NameError:
return False # IPython이 아님 (일반 Python 인터프리터)
2. 파라미터 처리 로직 개선
실행 환경에 따라 파라미터를 다르게 처리하도록 메인 실행 블록을 수정합니다. Jupyter 환경에서는 테스트를 위해 하드코딩된 값을 사용하고, Airflow 환경에서는 환경변수에서 동적으로 파라미터를 받아옵니다.
# --- 메인 실행 블록 ---
if __name__ == "__main__":
if is_running_in_jupyter():
WK_YM = '202504'
else:
# input parameters by airflow
WK_YM = os.environ['WK_YM']
print("------------------------------")
print("WK_YM : " + WK_YM)
print("-------------------------------")
3. 노트북 파일 형식 변환
Jupyter Notebook 파일(.ipynb)을 일반 Python 스크립트 파일(.py)로 변환하여 Airflow와 Spark에서 직접 실행할 수 있도록 합니다. 이 과정에서 노트북의 셀 구조는 제거되고 순수한 Python 코드만 남게 됩니다.
Airflow 작업 등록 및 실행
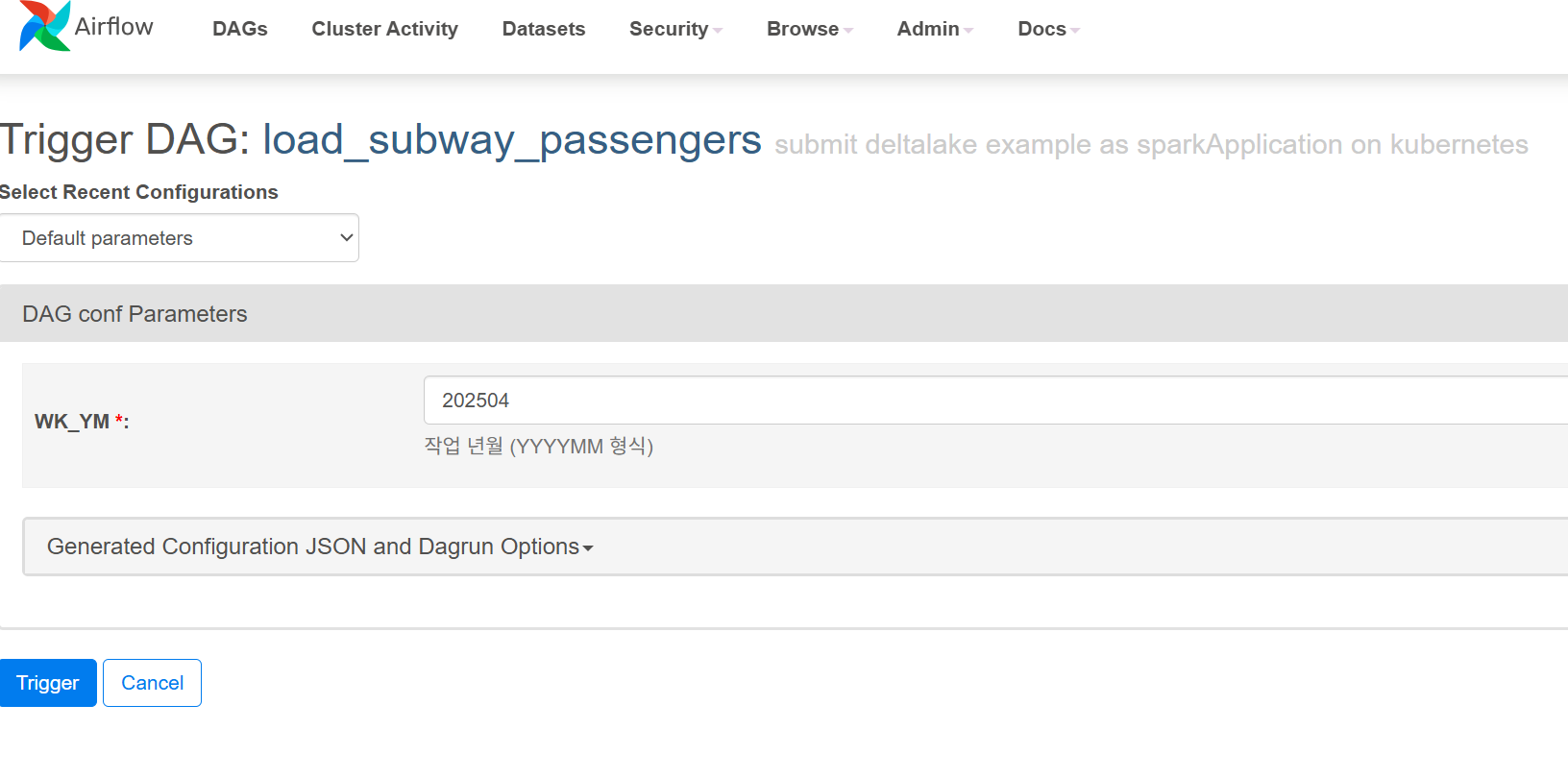
Airflow 작업은 spark-app.yaml에서 정의한 initContainers의 Git 리포지토리 정보를 통해 자동으로 등록됩니다. Airflow 웹 포털에서 해당 작업의 실행 버튼을 클릭하면 Spark Application에 전달할 파라미터를 입력할 수 있는 화면이 나타납니다. 필요한 파라미터를 입력한 후 Trigger 버튼을 클릭하여 작업을 실행할 수 있습니다.
작업 실행 과정은 다음과 같습니다:
- Git 리포지토리에서 DAG 파일이 자동으로 감지되어 Airflow에 등록
- 웹 UI에서 작업 선택 및 실행 버튼 클릭
- 파라미터 입력 화면에서 필요한 값 설정 (예: 처리할 년월 데이터)
- Trigger 버튼을 통한 작업 실행 및 모니터링
4. Jupyter Notebook vs Airflow DAG 환경 비교
Jupyter notebook 환경과 Airflow DAG 환경에서 Spark를 사용하는 것은 여러 측면에서 중요한 차이점이 있습니다.
실행 환경의 차이
Jupyter Notebook 환경
- 대화형(Interactive) 환경으로 셀 단위로 코드를 실행
- 개발자가 직접 브라우저에서 실시간으로 코드를 작성하고 테스트
- 즉시 결과 확인 가능하며 디버깅이 용이
- 세션이 유지되는 동안 Spark Context가 계속 살아있음
Airflow DAG 환경
- 배치(Batch) 처리 환경으로 스케줄링된 작업 실행
- 코드가 Python 스크립트로 패키징되어 워커 노드에서 실행
- 자동화된 워크플로우의 일부로 실행
- 각 태스크마다 새로운 Spark 세션이 생성되고 종료
주요 특성 비교
| 특성 | Jupyter Notebook | Airflow DAG |
|---|---|---|
| 리소스 관리 | • 개발자가 수동으로 리소스 관리 • 장시간 세션 유지로 인한 리소스 점유 가능 • 클러스터 리소스를 독점할 수 있음 |
• 태스크 완료 후 자동으로 리소스 해제 • 동적 리소스 할당 가능 • 여러 DAG가 리소스를 효율적으로 공유 |
| 오류 처리 및 재시도 | • 수동 오류 처리 • 실패 시 개발자가 직접 재실행 • 디버깅을 위한 상세한 정보 확인 가능 |
• 자동 재시도 메커니즘 • 실패 시 알림 및 로깅 • 의존성 관리 및 백프레셔 처리 |
| 스케줄링 및 의존성 | • 수동 실행 • 순차적 실행이 기본 • 의존성 관리 없음 |
• 크론 기반 스케줄링 • 복잡한 의존성 그래프 관리 • 병렬 실행 가능 |
| 모니터링 및 로깅 | • 셀 출력으로 결과 확인 • 제한적인 로깅 • 실시간 모니터링 어려움 |
• 중앙집중식 로깅 • 웹 UI를 통한 모니터링 • 작업 히스토리 및 메트릭 추적 |
| 보안 및 접근 제어 | • 개인 개발 환경 • 크리덴셜이 노트북에 하드코딩될 가능성 • 버전 관리 시 보안 정보 노출 위험 |
• Connection과 Variable을 통한 안전한 크리덴셜 관리 • RBAC 기반 접근 제어 • 프로덕션 환경에 적합한 보안 모델 |
5. 결론
Jupyter는 개발과 프로토타이핑에 적합하고, Airflow는 프로덕션 환경의 자동화된 데이터 파이프라인 운영에 적합합니다.
일반적인 개발 패턴은 개발 단계에서 Jupyter로 로직을 검증하고, 이를 Airflow DAG로 변환하여 운영하는 것입니다.