
StarRocks MView를 활용한 No-ETL 데이터 파이프라인 구현
복잡한 ETL 프로세스 없이 StarRocks의 Materialized View로 다양한 데이터 소스를 실시간 통합하는 방법을 소개합니다. StarRocks 내부 테이블과 Apache Iceberg를 원천으로 하는 두 시나리오를 통해 데이터 적재부터 Apache Superset 시각화까지 완전한 파이프라인을 구현하며, 운영비용 절감과 뛰어난 쿼리 성능을 달성하는 실무 가이드입니다.
들어가며
전통적인 ETL(Extract, Transform, Load) 프로세스는 복잡한 파이프라인 구성과 높은 운영 비용을 수반합니다. StarRocks의 Materialized View 기능을 활용하면 이러한 복잡성 없이도 다양한 원천 데이터를 실시간으로 통합하고 분석할 수 있는 효율적인 아키텍처를 구현할 수 있습니다.
StarRocks만의 핵심 강점은 Materialized View가 내부 데이터뿐만 아니라 External Catalog를 통해 이기종 데이터베이스나 Data Lake의 파일 형태 데이터까지 원천으로 활용할 수 있다는 점입니다.
본 가이드에서는 StarRocks와 Apache Iceberg를 원천 데이터로 하는 두 가지 시나리오에서 Materialized View를 생성하고, 이를 통해 데이터 시각화까지 구현하는 완전한 데이터 파이프라인을 단계별로 소개합니다.
사용 데이터: 뉴욕시 교통사고 데이터(NYPD_Crash_Data.csv)
데이터 출처: StarRocks 공식 홈페이지 Quickstart 예제
목차
- StarRocks 환경 구성
- 데이터 적재
- External Catalog 설정
- Materialized View 구현
- Apache Superset 연동 및 데이터 시각화
- 결론 및 향후 방향
StarRocks 환경 구성
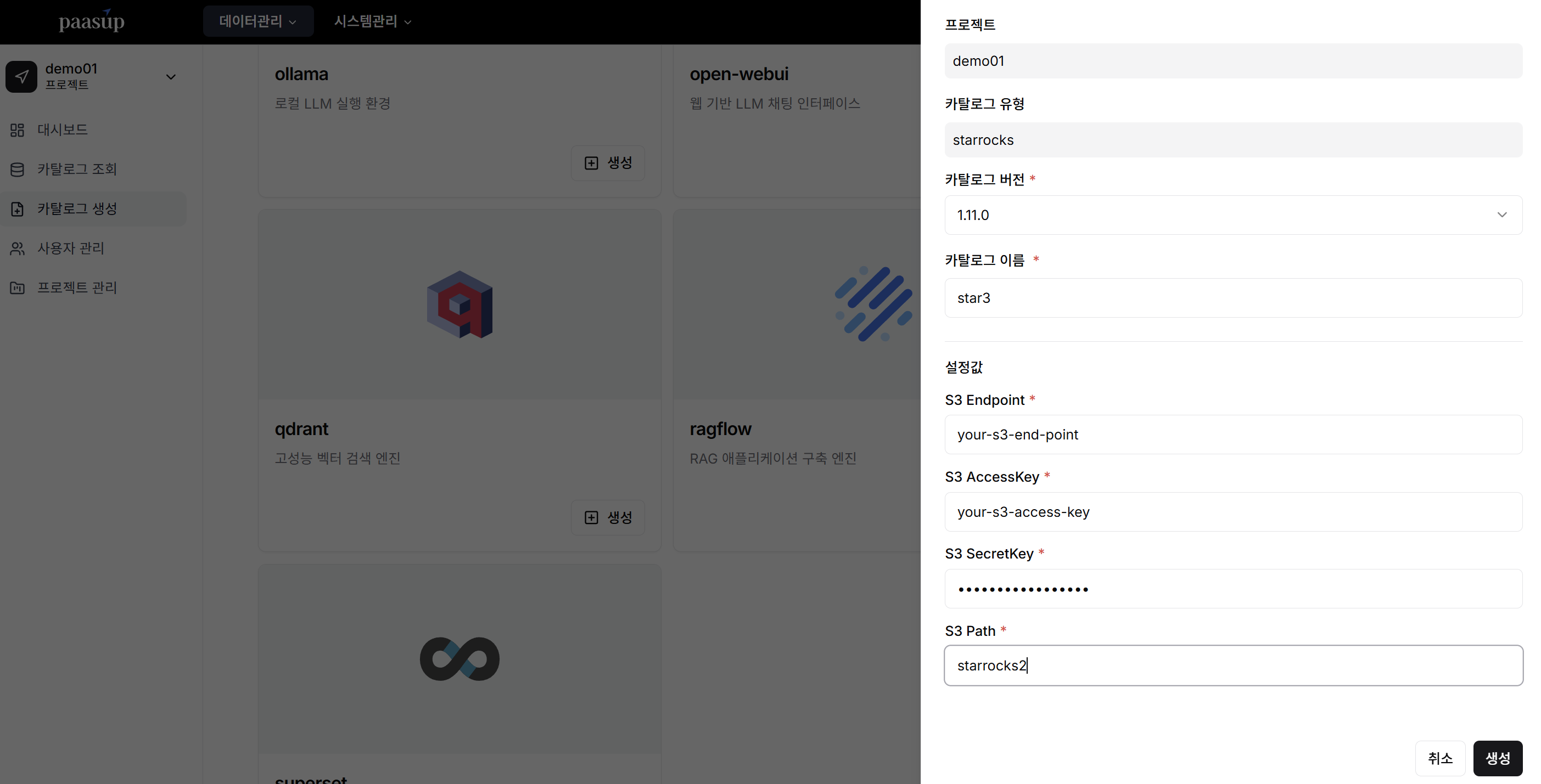
카탈로그 생성
DIP Portal의 카탈로그 생성 메뉴에서 StarRocks [생성] 버튼을 클릭한 후, 필수 설정 정보(버전, 이름, S3 설정값)를 입력하여 클러스터를 배포합니다.
클러스터 정보 확인
생성된 카탈로그의 [보기] 버튼을 클릭하면 Compute Node(CN)와 Front End(FE) Pod의 접속 주소를 확인할 수 있습니다.

데이터 적재
StarRocks 내부 테이블 적재
테이블 스키마 정의
CREATE TABLE IF NOT EXISTS crashdata (
CRASH_DATE DATETIME,
BOROUGH STRING,
ZIP_CODE STRING,
LATITUDE INT,
LONGITUDE INT,
LOCATION STRING,
ON_STREET_NAME STRING,
CROSS_STREET_NAME STRING,
OFF_STREET_NAME STRING,
CONTRIBUTING_FACTOR_VEHICLE_1 STRING,
CONTRIBUTING_FACTOR_VEHICLE_2 STRING,
COLLISION_ID INT,
VEHICLE_TYPE_CODE_1 STRING,
VEHICLE_TYPE_CODE_2 STRING
);
Stream Load API를 통한 데이터 적재
StarRocks의 Stream Load API를 활용하면 간단한 curl 명령어로 대용량 CSV 파일을 효율적으로 적재할 수 있습니다.
curl --location-trusted -u root:<your-password> \
-T NYPD_Crash_Data.csv \
-H "column_separator:," \
-H "skip_header:1" \
-H "enclose:\"" \
-H "max_filter_ratio:1" \
-H "columns:tmp_CRASH_DATE, tmp_CRASH_TIME, CRASH_DATE=str_to_date(concat_ws(' ', tmp_CRASH_DATE, tmp_CRASH_TIME), '%m/%d/%Y %H:%i'),BOROUGH,ZIP_CODE,LATITUDE,LONGITUDE,LOCATION,ON_STREET_NAME,CROSS_STREET_NAME,OFF_STREET_NAME,NUMBER_OF_PERSONS_INJURED,NUMBER_OF_PERSONS_KILLED,NUMBER_OF_PEDESTRIANS_INJURED,NUMBER_OF_PEDESTRIANS_KILLED,NUMBER_OF_CYCLIST_INJURED,NUMBER_OF_CYCLIST_KILLED,NUMBER_OF_MOTORIST_INJURED,NUMBER_OF_MOTORIST_KILLED,CONTRIBUTING_FACTOR_VEHICLE_1,CONTRIBUTING_FACTOR_VEHICLE_2,CONTRIBUTING_FACTOR_VEHICLE_3,CONTRIBUTING_FACTOR_VEHICLE_4,CONTRIBUTING_FACTOR_VEHICLE_5,COLLISION_ID,VEHICLE_TYPE_CODE_1,VEHICLE_TYPE_CODE_2,VEHICLE_TYPE_CODE_3,VEHICLE_TYPE_CODE_4,VEHICLE_TYPE_CODE_5" \
-XPUT http://<your-fe-domain>:8030/api/quickstart/crashdata/_stream_load
데이터 적재 결과 확인
원본 데이터는 약 42만 건이며, Materialized View 테스트를 위해 반복 적재하여 총 데이터량을 증대시켰습니다.
Apache Iceberg 테이블 적재
Iceberg 테이블 생성 및 데이터 적재를 위해서는 메타스토어(Hive, Glue, RDB 등)와의 연동이 필수입니다. 이는 추후 StarRocks에서 External Catalog를 생성하기 위한 전제조건입니다.
import os
import pandas as pd
import pyarrow as pa
from pyiceberg.catalog import load_catalog
from pyiceberg.exceptions import NoSuchTableError, NamespaceAlreadyExistsError
from pyiceberg.schema import Schema
from pyiceberg.types import (
NestedField,
StringType,
)
from thrift.transport import TSocket, TTransport
from thrift.protocol import TBinaryProtocol
from hive_metastore import ThriftHiveMetastore
# Hive Metastore 연결 설정
hive_uri = 'thrift://<your-hive-uri>:<port>'
minio_endpoint = '<your-endpoint>:<port>'
minio_access_key = '<your-access-key>'
minio_secret_key = '<your-secret-key>'
s3_warehouse_path = '<your-warehouse-path>'
# PyIceberg 카탈로그 초기화
catalog_properties = {
"uri": hive_uri,
"warehouse": s3_warehouse_path,
"s3.endpoint": minio_endpoint,
"s3.access-key-id": minio_access_key,
"s3.secret-access-key": minio_secret_key,
}
try:
catalog = load_catalog("hive", **catalog_properties)
print("Hive 카탈로그 연결 성공")
except Exception as e:
print(f"카탈로그 연결 실패: {str(e)}")
raise
# CSV 데이터 전처리
print("NYPD_Crash_Data.csv 파일 읽기 및 전처리 중...")
df = pd.read_csv('NYPD_Crash_Data.csv', on_bad_lines='skip', low_memory=False)
# 컬럼명 정규화 (소문자 변환, 공백을 언더스코어로 대체)
df.columns = [col.lower().replace(' ', '_') for col in df.columns]
# 분석에 필요한 핵심 컬럼 선택
columns_to_keep = [
'crash_date', 'crash_time', 'borough', 'zip_code', 'latitude', 'longitude',
'on_street_name', 'number_of_persons_injured', 'contributing_factor_vehicle_1', 'vehicle_type_code_1'
]
df = df[columns_to_keep].copy()
# 데이터 타입 통일화 (모든 컬럼을 문자열로 변환)
df.fillna('', inplace=True)
for col in df.columns:
df[col] = df[col].astype(str)
print("데이터 전처리 완료")
print("샘플 데이터 확인:")
print(df.head())
# Iceberg 테이블 스키마 정의
schema = Schema(
NestedField(field_id=1, name="crash_date", field_type=StringType(), required=False),
NestedField(field_id=2, name="crash_time", field_type=StringType(), required=False),
NestedField(field_id=3, name="borough", field_type=StringType(), required=False),
NestedField(field_id=4, name="zip_code", field_type=StringType(), required=False),
NestedField(field_id=5, name="latitude", field_type=StringType(), required=False),
NestedField(field_id=6, name="longitude", field_type=StringType(), required=False),
NestedField(field_id=7, name="on_street_name", field_type=StringType(), required=False),
NestedField(field_id=8, name="number_of_persons_injured", field_type=StringType(), required=False),
NestedField(field_id=9, name="contributing_factor_vehicle_1", field_type=StringType(), required=False),
NestedField(field_id=10, name="vehicle_type_code_1", field_type=StringType(), required=False),
)
# 테이블 생성 및 데이터 적재
db_name = "nyc_db"
table_name = "crashes"
table_identifier = (db_name, table_name)
# 네임스페이스 생성
try:
catalog.create_namespace(db_name)
print(f"네임스페이스 '{db_name}' 생성 완료")
except NamespaceAlreadyExistsError:
print(f"네임스페이스 '{db_name}' 이미 존재")
try:
# 기존 테이블 확인 및 데이터 추가
table = catalog.load_table(table_identifier)
print(f"기존 테이블 '{db_name}.{table_name}' 발견, 데이터 추가 중...")
arrow_table = pa.Table.from_pandas(df)
table.append(arrow_table)
print("기존 테이블에 데이터 추가 완료")
except NoSuchTableError:
# 새 테이블 생성 및 데이터 적재
print(f"테이블 '{db_name}.{table_name}' 생성 중...")
table = catalog.create_table(identifier=table_identifier, schema=schema)
print(f"테이블 '{db_name}.{table_name}' 생성 완료")
arrow_table = pa.Table.from_pandas(df)
table.append(arrow_table)
print("새 테이블에 데이터 적재 완료")
# 데이터 검증
print(f"'{db_name}.{table_name}' 테이블 데이터 건수 확인:")
snapshot = table.current_snapshot()
if snapshot:
record_count = int(snapshot.summary.get("total-records", 0))
else:
record_count = 0
print(f"총 레코드 수: {record_count}")
Iceberg 테이블에도 Materialized View 테스트를 위해 반복 적재를 수행했습니다.

External Catalog 설정
StarRocks 클라이언트 도구(MySQL 호환 클라이언트)를 통해 외부 데이터 소스에 접근하기 위한 External Catalog를 구성합니다.
지원 데이터 소스
StarRocks는 다양한 외부 데이터 소스와의 연동을 지원합니다:
- Data Lake 포맷: Apache Iceberg, Apache Hudi, Delta Lake
- 관계형 데이터베이스: MySQL, PostgreSQL, Oracle, SQL Server 등
Apache Iceberg Catalog 생성
Data Lake 포맷의 카탈로그 생성을 위해서는 메타스토어(Hive, Glue, REST Catalog, RDB 등)와의 인터페이스 설정이 필수입니다.
-- Iceberg External Catalog 생성
CREATE EXTERNAL CATALOG iceberg_catalog3
PROPERTIES (
"type" = "iceberg",
"iceberg.catalog.type" = "hive",
"hive.metastore.uris" = "thrift://<hive-metastore>:<port>",
"aws.s3.enable_path_style_access" = "true", -- MinIO 사용 시 필수 설정
"aws.s3.endpoint" = "<your-endpoint>:<port>",
"aws.s3.access_key" = "<your-s3-access-key>",
"aws.s3.secret_key" = "<your-s3-secret-key>"
);
카탈로그 검증 및 테스트
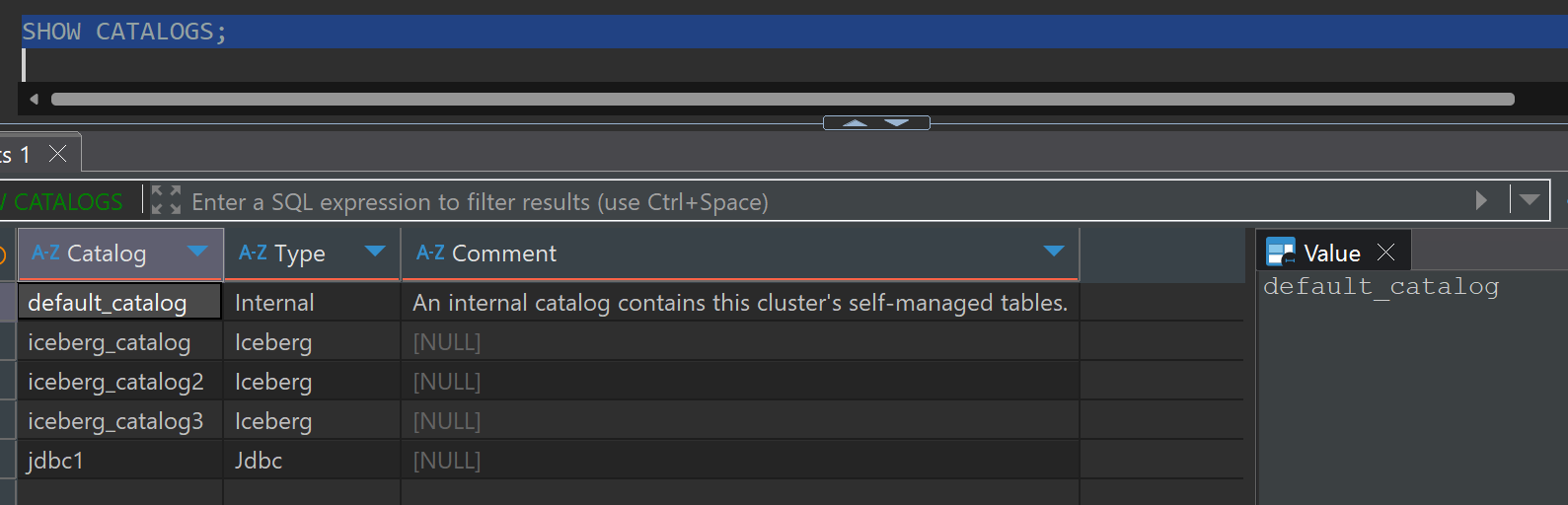
생성된 카탈로그 목록 확인
SHOW CATALOGS;
카탈로그 내 데이터베이스 조회
SHOW DATABASES FROM iceberg_catalog3;
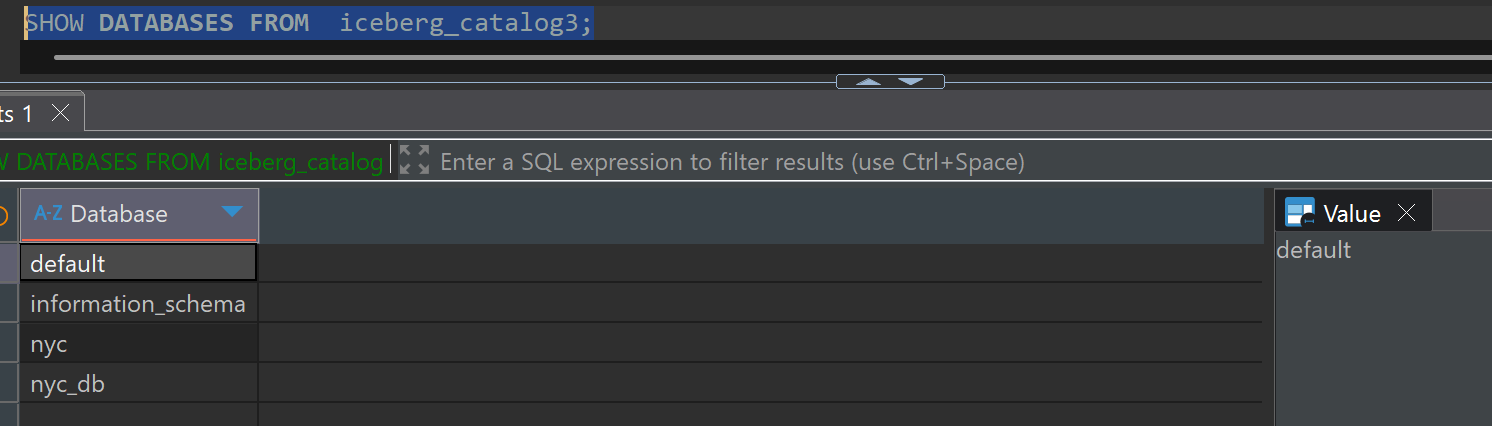
테이블 목록 확인
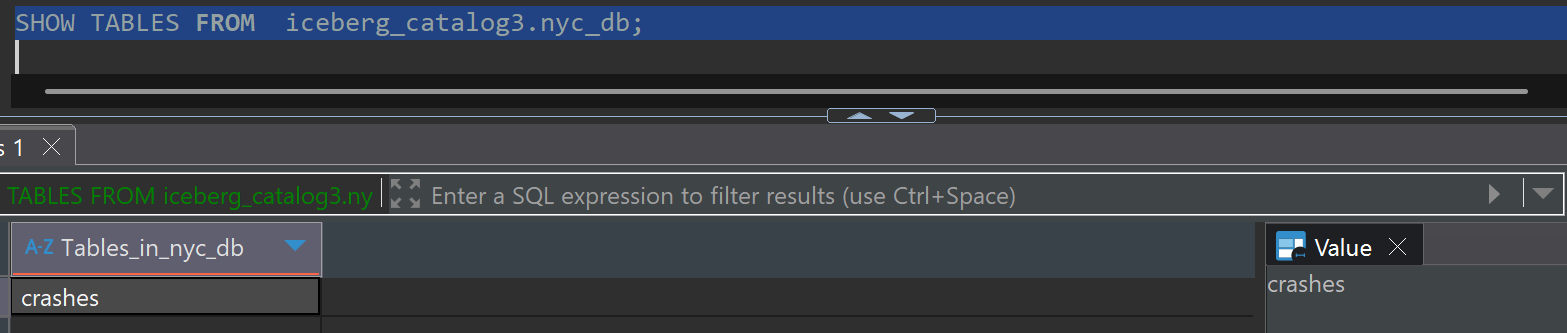
SHOW TABLES FROM iceberg_catalog3.nyc_db;
데이터 샘플 조회
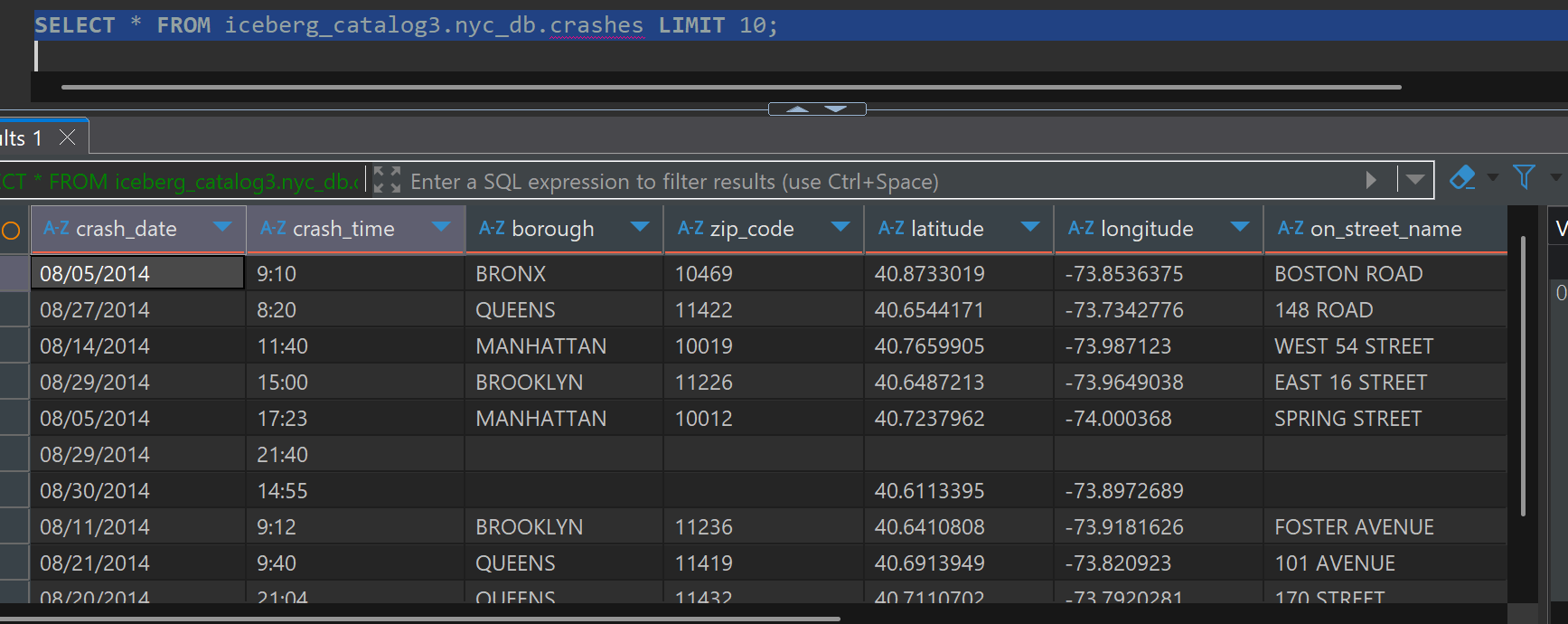
SELECT * FROM iceberg_catalog3.nyc_db.crashes LIMIT 10;
Materialized View 구현
StarRocks에서 집계 함수(SUM, AVG, COUNT 등)를 포함한 Materialized View는 반드시 ASYNC 모드로 생성해야 합니다.
단일 데이터 소스 기반 Materialized View
StarRocks 내부 테이블을 원천으로 하는 경우
내부 카탈로그의 데이터를 기반으로 비동기 Materialized View를 생성합니다.
-- StarRocks 내부 테이블 기반 Materialized View
CREATE MATERIALIZED VIEW mv_crashdata
REFRESH ASYNC START("2024-01-01 00:00:00") EVERY(INTERVAL 10 MINUTE)
AS SELECT
date_trunc('day', CRASH_DATE) AS Time,
VEHICLE_TYPE_CODE_1,
count(*) AS CNT
FROM quickstart.crashdata
GROUP BY Time, VEHICLE_TYPE_CODE_1;
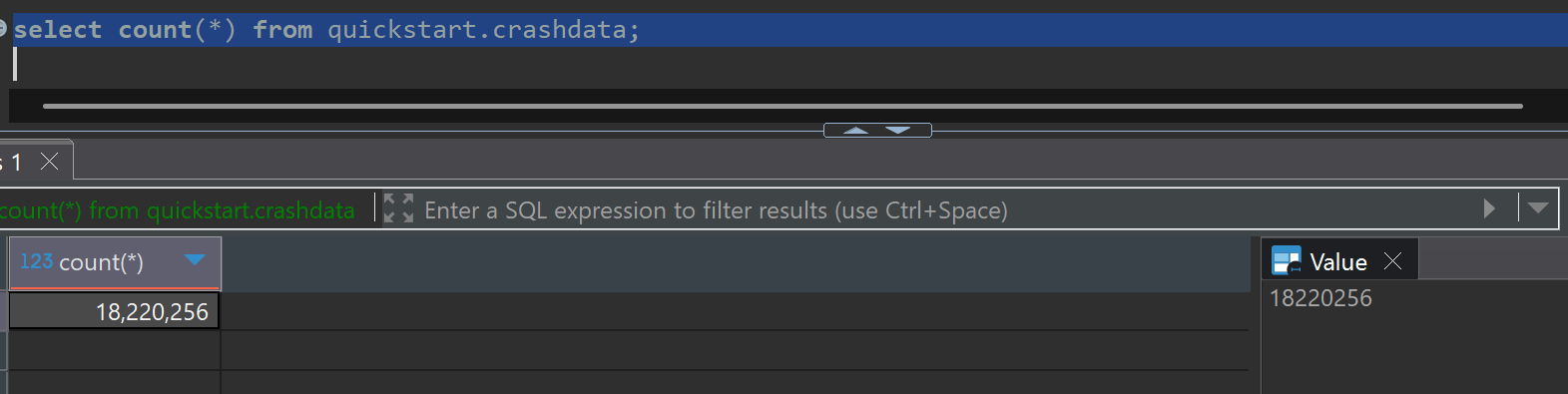
데이터 집계 결과 확인
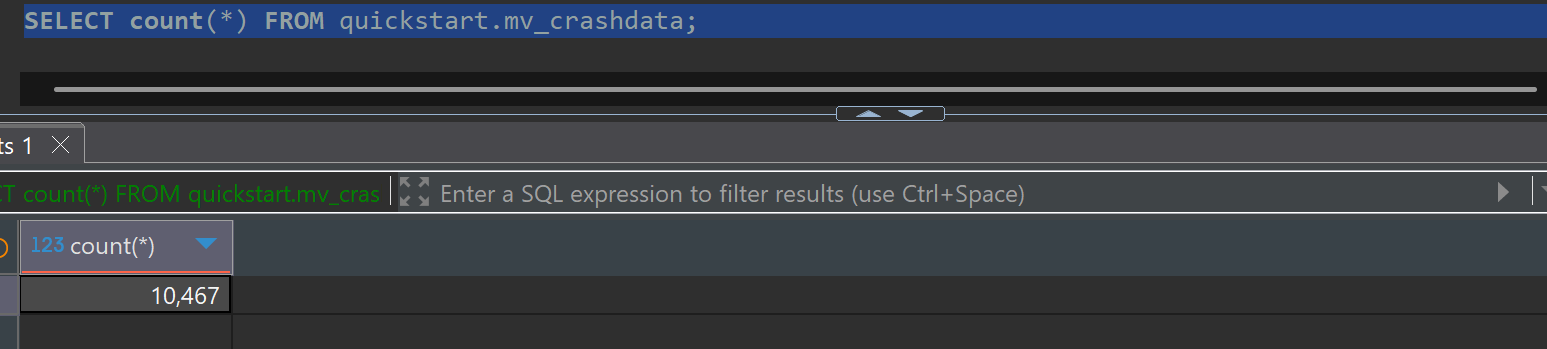
원본 데이터(quickstart.crashdata) 18,220,556건이 집계되어 mv_crashdata 10,467건으로 압축되었습니다.
SELECT count(*) FROM quickstart.mv_crashdata;
Iceberg External Catalog을 원천으로 하는 경우
외부 카탈로그의 Iceberg 테이블을 기반으로 비동기 Materialized View를 생성합니다.
-- Iceberg 테이블 기반 Materialized View
CREATE MATERIALIZED VIEW mv_iceberg_crashdata
REFRESH ASYNC START('2024-01-01 00:00:00') EVERY(INTERVAL 10 MINUTE)
AS
SELECT
CAST(STR_TO_DATE(CRASH_DATE,'%m/%d/%Y') AS DATETIME) AS Time,
VEHICLE_TYPE_CODE_1,
COUNT(*) AS CNT
FROM iceberg_catalog3.nyc_db.crashes
GROUP BY Time, VEHICLE_TYPE_CODE_1;
데이터 집계 결과 확인
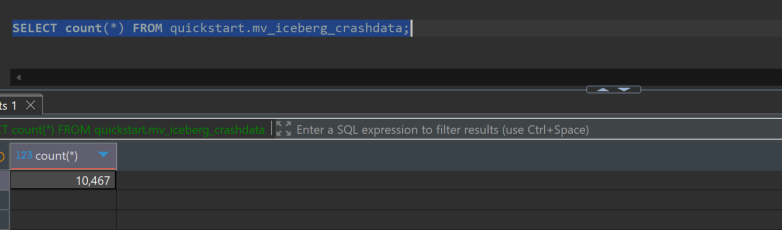
원본 데이터(iceberg_catalog3.nyc_db.crashes) 9,745,657건이 집계되어 mv_iceberg_crashdata 10,467건으로 압축되었습니다.
SELECT count(*) FROM quickstart.mv_iceberg_crashdata;
다중 데이터 소스 조인 Materialized View (활용 예시)
StarRocks의 강력한 기능 중 하나는 서로 다른 외부 카탈로그의 데이터를 조인하여 통합 분석 뷰를 생성할 수 있다는 점입니다.
-- 다중 외부 카탈로그 조인 Materialized View 예시
CREATE MATERIALIZED VIEW unified_customer_analysis
REFRESH ASYNC START('2024-01-01 00:00:00') EVERY(INTERVAL 30 MINUTE)
AS SELECT
c.customer_id,
c.customer_name,
c.region,
o.order_count,
o.total_spent,
p.last_payment_date,
p.payment_method
FROM mysql_catalog.crm_db.customers c
LEFT JOIN (
SELECT
customer_id,
COUNT(*) as order_count,
SUM(amount) as total_spent
FROM iceberg_catalog.sales_db.orders
WHERE order_date >= CURRENT_DATE - INTERVAL 90 DAY
GROUP BY customer_id
) o ON c.customer_id = o.customer_id
LEFT JOIN (
SELECT
customer_id,
MAX(payment_date) as last_payment_date,
payment_method
FROM postgres_catalog.payment_db.payments
WHERE payment_date >= CURRENT_DATE - INTERVAL 30 DAY
GROUP BY customer_id, payment_method
) p ON c.customer_id = p.customer_id;
Materialized View 운영 관리
뷰 상태 모니터링
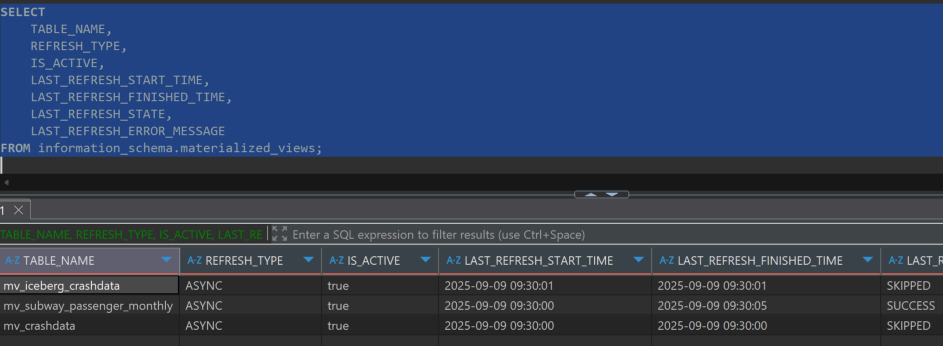
information_schema.materialized_views를 통해 모든 Materialized View의 상태 정보를 확인할 수 있습니다.
-- Materialized View 상태 종합 조회
SELECT
TABLE_NAME,
REFRESH_TYPE,
IS_ACTIVE,
LAST_REFRESH_START_TIME,
LAST_REFRESH_FINISHED_TIME,
LAST_REFRESH_STATE,
LAST_REFRESH_ERROR_MESSAGE
FROM information_schema.materialized_views;
수동 제어 및 관리
REFRESH와 ALTER 명령어를 통해 수동 새로고침 및 스케줄 관리가 가능합니다.
-- 수동 새로고침 실행
REFRESH MATERIALIZED VIEW mv_iceberg_crashdata;
-- Materialized View 작업 일시 중단/재개
ALTER MATERIALIZED VIEW mv_iceberg_crashdata PAUSE;
ALTER MATERIALIZED VIEW mv_iceberg_crashdata RESUME;
성능 최적화 전략 (권장사항)
파티셔닝을 활용하면 전체 데이터가 아닌 특정 파티션만 선택적으로 새로고침할 수 있어 성능이 크게 향상됩니다.
-- 파티션 기반 Materialized View 예시
CREATE MATERIALIZED VIEW partitioned_sales_mv
PARTITION BY DATE_TRUNC('month', order_date)
REFRESH ASYNC START('2024-01-01 00:00:00') EVERY(INTERVAL 1 HOUR)
AS SELECT
DATE_TRUNC('month', order_date) as month,
product_category,
SUM(sales_amount) as total_sales,
COUNT(*) as order_count
FROM sales_data
GROUP BY DATE_TRUNC('month', order_date), product_category;
Apache Superset 연동 및 데이터 시각화
구현한 4가지 형태의 데이터 소스를 Apache Superset과 연동하여 시각화 대시보드를 구성하고, 각각의 조회 성능과 데이터 정합성을 비교 분석할 수 있습니다.
시각화 데이터 소스 비교
- Chart 1: StarRocks 원본 테이블 (quickstart.crashdata)
- Chart 2: StarRocks Materialized View (quickstart.mv_crashdata)
- Chart 3: Iceberg 원본 테이블 (iceberg_catalog3.nyc_db.crashes)
- Chart 4: Iceberg 기반 Materialized View (quickstart.mv_iceberg_crashdata)
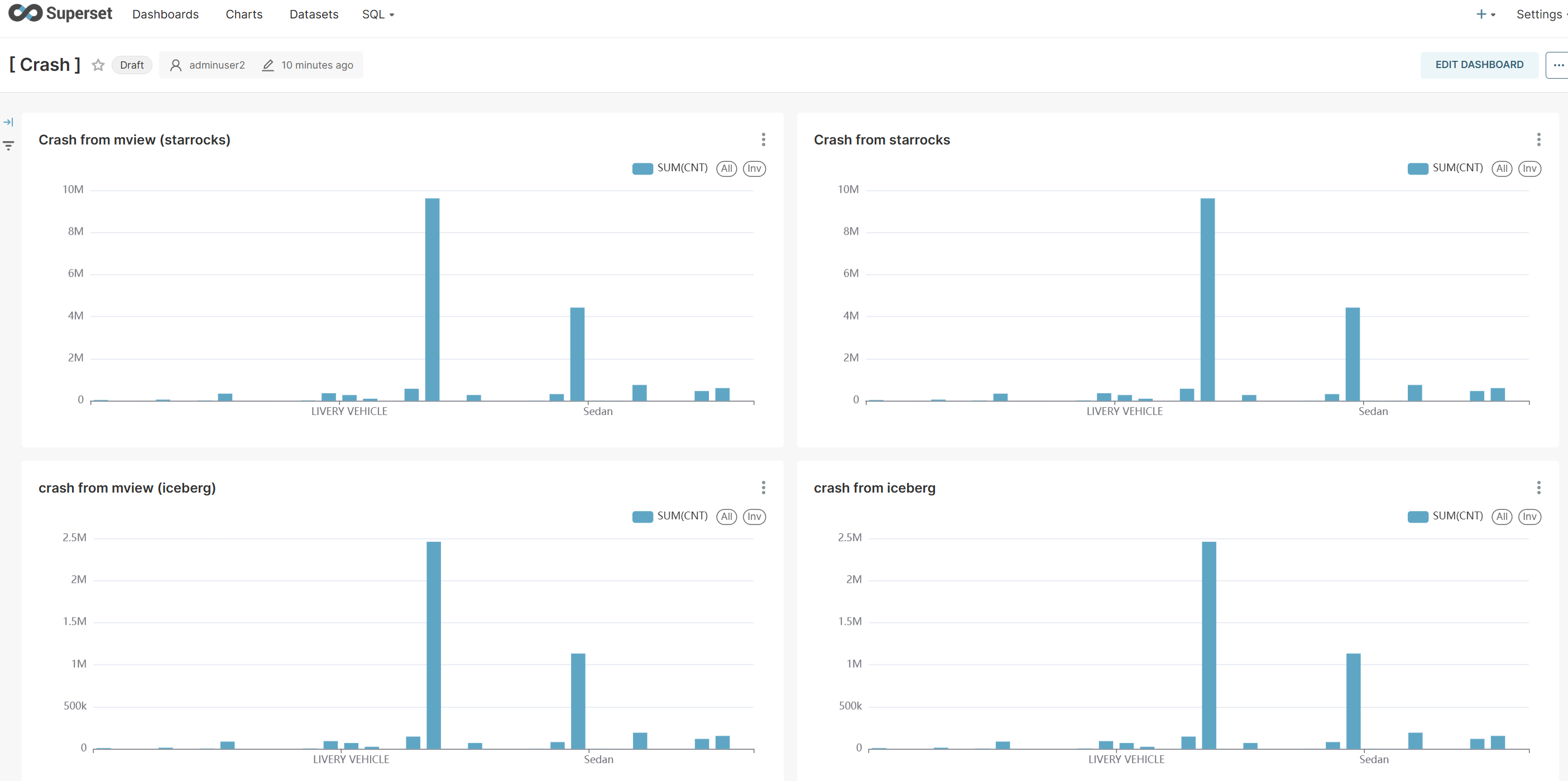
성능 분석 결과
이 시각화를 통해 다음과 같은 인사이트를 얻을 수 있습니다:
- 쿼리 응답 속도: Materialized View가 원본 테이블 대비 현저히 빠른 응답 시간을 보임
- 데이터 정합성: 모든 차트에서 동일한 트렌드와 패턴을 확인
- 리소스 효율성: 사전 집계된 데이터로 인한 컴퓨팅 리소스 절약 효과
결론 및 향후 방향
핵심 성과
StarRocks의 Materialized View를 활용한 No-ETL 아키텍처는 다음과 같은 명확한 가치를 제공합니다:
- 실시간 데이터 통합: 별도의 복잡한 ETL 파이프라인 없이도 다양한 소스의 데이터를 실시간으로 통합 분석
- 운영 비용 최적화: ETL 인프라 구축 및 유지보수 비용을 대폭 절감하고 운영 복잡성 최소화
- 확장성과 유연성: 새로운 데이터 소스 추가 시 단순한 SQL 기반 설정으로 빠른 확장 가능
- 뛰어난 성능: 사전 계산된 Materialized View를 통한 서브 세컨드 수준의 쿼리 응답 시간 달성
- 개발 생산성: SQL 기반의 직관적인 데이터 변환 및 분석 로직 구현
향후 발전 방향
- 스트리밍 데이터 연동: Apache Kafka 등 실시간 스트리밍 데이터와의 통합 확장
- 머신러닝 파이프라인 연동: MLOps 워크플로우와의 자연스러운 통합 구현
- 고급 분석 기능: 시계열 분석, 이상 탐지 등 고도화된 분석 케이스 적용
- 멀티 클라우드 전략: 다양한 클라우드 환경에서의 하이브리드 데이터 아키텍처 구성
이 가이드를 통해 StarRocks의 강력한 Materialized View 기능을 마스터하고, 차세대 데이터 분석 환경 구축의 기반을 마련하시기 바랍니다.