
StarRocks 아키텍처 이해
StarRocks는 FE(Frontend)와 BE/CN(Backend/Compute Nodes) 두 종류 컴포넌트로 구성된 단순한 아키텍처의 분석 데이터베이스입니다. 로컬 저장소를 사용하는 Shared-nothing 모드(고성능)와 객체 스토리지를 활용하는 Shared-data 모드(비용 효율적)를 환경에 따라 선택할 수 있습니다. 복잡한 외부 의존성 없이 MPP 구조로 뛰어난 성능과 운영 중단 없는 수평 확장을 제공하는 것이 핵심 특징입니다.
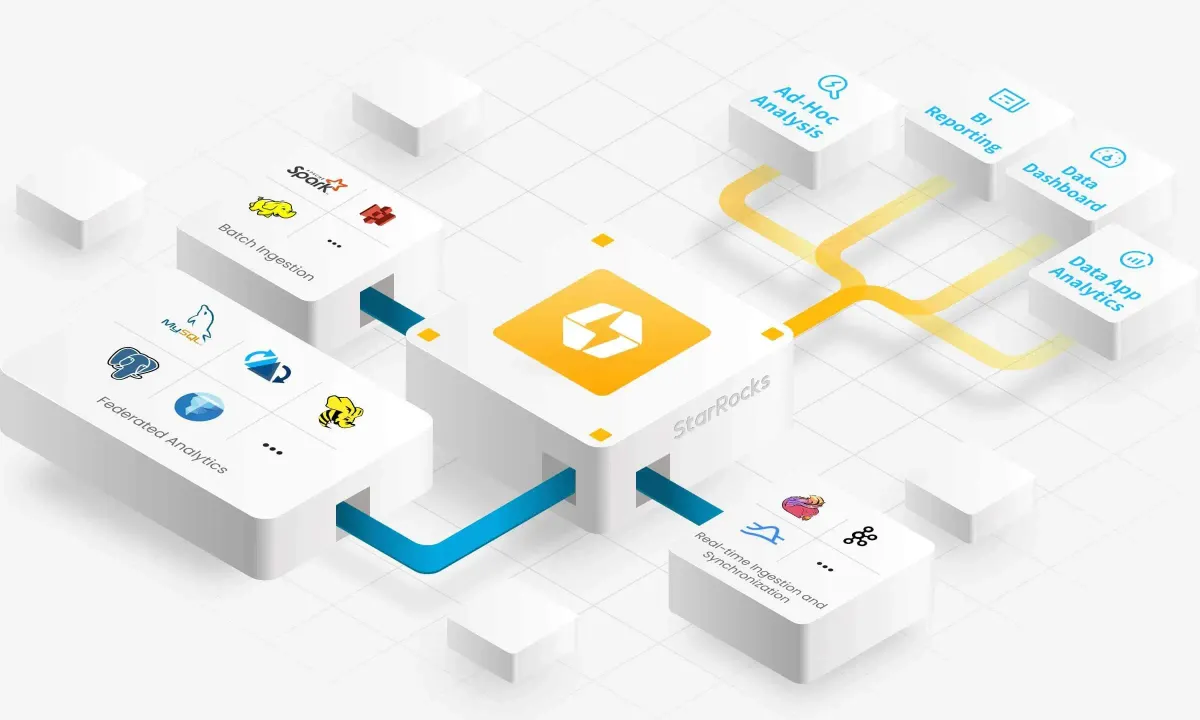
1. StarRocks 소개
왜 StarRocks인가?
최근 데이터 분석 시장에서 StarRocks가 주목받고 있습니다.
그 이유는 무엇일까요?
StarRocks는 단순함과 성능을 동시에 추구하는 분석 데이터베이스입니다. 복잡한 외부 의존성 없이도 뛰어난 성능을 제공하며, 운영 중단 없이 수평 확장이 가능한 것이 가장 큰 특징입니다.
핵심 특징과 장점
🎯 단순한 아키텍처
- FE(Frontend) + BE(Backend)/CN(Compute Nodes) 두 종류의 컴포넌트만으로 구성
- 외부 컴포넌트에 의존하지 않는 독립적인 시스템
⚡ 뛰어난 성능
- MPP(Massively Parallel Processing) 구조로 대용량 데이터 처리
- 로컬 데이터 직접 접근으로 최적화된 쿼리 성능
🔧 유연한 확장성
- 운영 중단 없는 수평 확장
- 환경에 따른 두 가지 배포 모드 지원
2. 아키텍처 기본 구조
StarRocks의 아키텍처는 놀랍도록 단순합니다. 크게 세 종류의 컴포넌트로만 구성되어 있습니다.
FE (Frontend) - 두뇌 역할
주요 역할:
- 📊 메타데이터 관리: BDB JE를 사용하여 메타데이터를 메모리에 저장
- 🔗 클라이언트 연결: 사용자 요청을 받아 처리
- 📋 쿼리 계획 수립: SQL을 분석하여 실행 계획 생성
- ⚖️ 스케줄링: 작업을 BE/CN 노드들에 분산
고가용성 구조:
- Leader: 실제 메타데이터 변경 작업 수행
- Follower: Leader와 동기화되며, Leader 장애 시 대체 가능
- Observer: 읽기 전용으로 쿼리 부하 분산
FE 노드들은 Raft 프로토콜을 사용하여 리더를 선출하고 데이터를 동기화합니다.
BE/CN - 실제 작업자
BE (Backend) - Shared-nothing 모드
- 💾 데이터 저장: 로컬 저장소에 데이터 보관
- ⚙️ SQL 실행: FE의 계획을 받아 실제 쿼리 실행
- 🔄 데이터 복제: MPP 구조로 고가용성 보장
CN (Compute Nodes) - Shared-data 모드
- 🧮 연산 전용: 데이터 저장 없이 연산만 수행
- 📦 캐시 관리: 자주 사용하는 데이터를 로컬에 캐시
- 🚀 빠른 확장: 상태가 없어 추가/제거가 매우 빠름
3. Shared-nothing vs Shared-data 완벽 비교
StarRocks의 가장 큰 특징 중 하나는 환경에 따라 최적의 아키텍처를 선택할 수 있다는 점입니다.
Shared-nothing: 로컬 저장소의 강력함
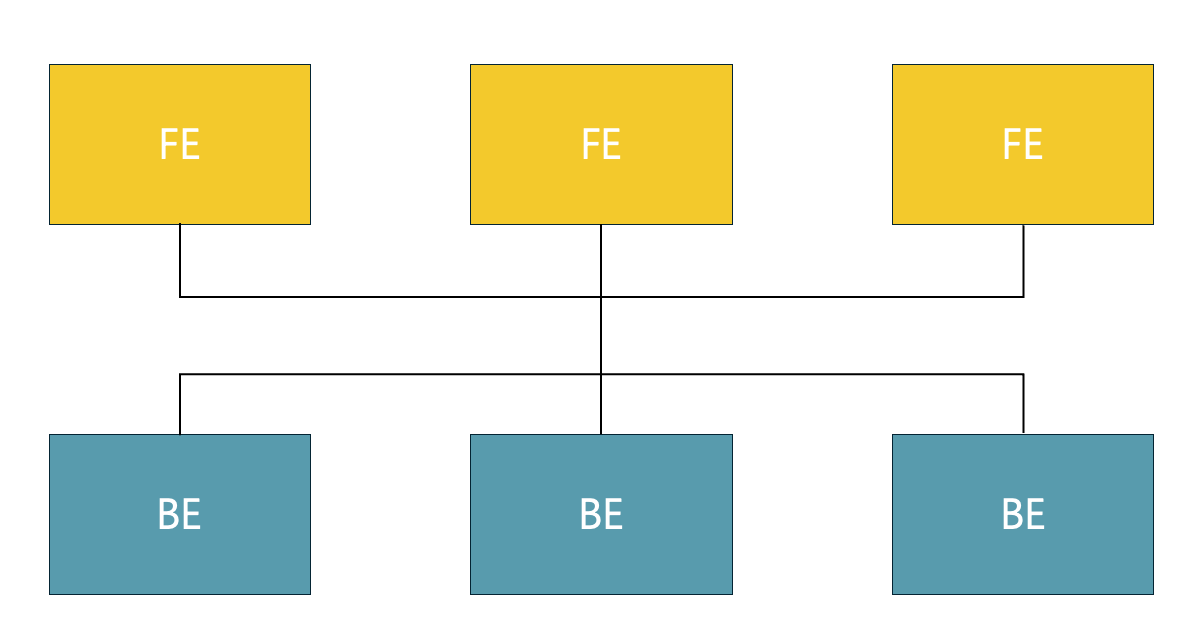
구조:
- BE 노드들이 로컬 저장소에 데이터를 저장
- 각 노드가 자체적으로 쿼리를 직접 처리
장점:
- ⚡ 초고속 쿼리: 로컬 데이터 직접 접근으로 최고 성능
- 🛡️ 안정성: MPP 구조로 데이터 복제와 고가용성 보장
- 🎯 실시간 처리: 저지연 쿼리 처리에 최적화
적합한 상황:
- 실시간 대시보드나 OLAP 쿼리가 중요한 경우
- 네트워크 지연을 최소화해야 하는 환경
- 예측 가능한 워크로드 패턴
Shared-data: 클라우드 네이티브의 유연함
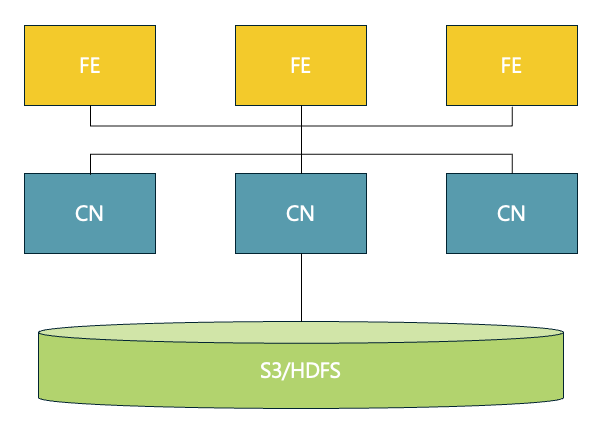
구조:
- 객체 스토리지(AWS S3, GCS, Azure Blob, MinIO 등) 또는 HDFS를 저장소로 사용
- CN 노드들이 캐시와 연산만 담당
핵심 기술 - 멀티 티어 캐시 시스템:
메모리 캐시 → 로컬 디스크 캐시 → 원격 객체 스토리지
↑ ↑ ↑
Hot data Warm data Cold data
- Hot data: 메모리에서 직접 접근 (최고 성능)
- Warm data: 로컬 디스크 캐시에서 접근 (빠른 성능)
- Cold data: 객체 스토리지에서 로드 후 캐시 (점진적 성능 향상)
장점:
- 💰 비용 절감: 저렴한 객체 스토리지 활용
- 🔄 리소스 격리: 컴퓨팅과 스토리지 독립적 확장
- 🚀 빠른 확장: CN 노드 추가/제거가 매우 빠름
- ☁️ 클라우드 친화적: 클라우드 네이티브 환경에 최적화
적합한 상황:
- 클라우드 환경에서 비용 효율성이 중요한 경우
- 워크로드가 예측하기 어려운 환경
- 스토리지와 컴퓨팅을 독립적으로 확장해야 하는 경우
언제 어떤 모드를 선택할까?
| 비교 항목 | Shared-nothing | Shared-data |
|---|---|---|
| 성능 | ⭐⭐⭐⭐⭐ (최고) | ⭐⭐⭐⭐ (캐시 적중 시 우수) |
| 비용 | ⭐⭐⭐ (중간) | ⭐⭐⭐⭐⭐ (매우 저렴) |
| 확장성 | ⭐⭐⭐ (데이터 재분배 필요) | ⭐⭐⭐⭐⭐ (즉시 확장) |
| 운영 복잡도 | ⭐⭐⭐⭐ (단순) | ⭐⭐⭐ (캐시 관리 필요) |
| 클라우드 친화도 | ⭐⭐⭐ (보통) | ⭐⭐⭐⭐⭐ (최적) |
선택 가이드:
Shared-nothing을 선택하세요:
- 🎯 실시간 대시보드나 저지연 쿼리가 핵심인 경우
- 📊 예측 가능한 워크로드 패턴
- 🏢 온프레미스 환경이나 전용 인프라
Shared-data를 선택하세요:
- ☁️ 클라우드 환경에서 비용 효율성이 중요한 경우
- 📈 워크로드가 급변하거나 예측하기 어려운 경우
- 🔄 스토리지와 컴퓨팅을 독립적으로 확장해야 하는 경우
마무리
StarRocks의 아키텍처는 단순함 속의 강력함을 보여줍니다. 두 가지 배포 모드를 통해 다양한 환경과 요구사항에 맞는 최적의 솔루션을 제공합니다.
다음 Part 2에서는 실제로 Kubernetes 환경에서 StarRocks를 배포하는 방법을 단계별로 알아보겠습니다. 이론을 실습으로 연결하여 StarRocks의 진정한 가치를 경험해보세요!