
파스업DIP로 구현하는 현대적 데이터 파이프라인: 지하철 이용자 통계 분석 프로젝트 #3
서울시 지하철 10여 년간의 승하차 데이터를 현대적 데이터레이크 기술 스택으로 처리한 도시 교통 패턴 분석 프로젝트를 소개합니다. 73,692개 레코드를 Delta Lake와 Apache Superset으로 변환하여 출퇴근 러시아워와 환승역 허브 효과를 시각화했습니다.
서울시 지하철 시간별 승하차 집계 데이터로 도시 교통 패턴 분석하기
프로젝트 개요
서울시 지하철 네트워크는 하루 평균 700만 명이 넘는 시민들이 이용하는 대한민국 최대 규모의 도시철도 시스템입니다.
본 프로젝트는 이전 블로그에서 제시했던 향후 발전계획 중 '시간대별 데이터 확보를 통한 출퇴근 패턴 분석' 과제를 실제로 구현한 결과입니다.
공공데이터포털에서 제공하는 10여 년간의 지하철 승하차 데이터를 현대적인 데이터레이크 기술 스택으로 처리하여, 도시민의 이동 패턴과 교통 혼잡도를 분석할 수 있는 인텔리전트 대시보드 시스템을 구축하는 것을 목표로 합니다.
목차
📋원본 데이터 구조
- 파일명: 서울시 지하철 호선별 역별 시간대별 승하차 인원 정보.json
- 출처: 공공데이터포털
- 규모: 73,692개 레코드
- 시간 범위: 월별/노선별/역별 시간대(00시-24시) 승하차 인원 정보
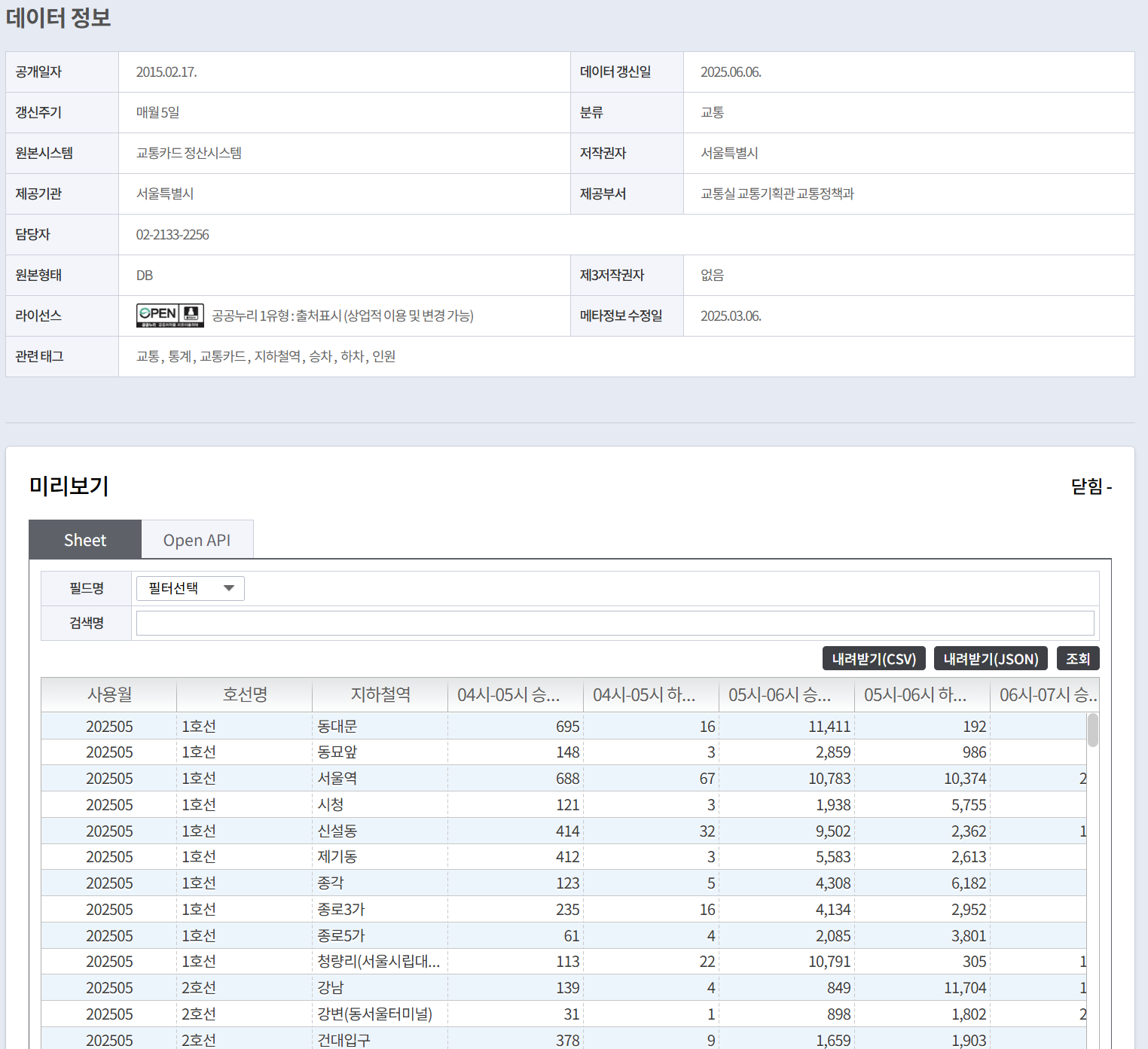
원본 JSON 데이터는 각 역별로 24시간 동안의 시간대별 승차/하차 인원을 포함하고 있으며, 다음과 같은 주요 필드로 구성되어 있습니다:
{
"USE_MM": "사용월",
"SBWY_ROUT_LN_NM": "호선명",
"STTN": "지하철역",
"HR_7_GET_ON_NOPE": "07시-08시 승차인원",
"HR_7_GET_OFF_NOPE": "07시-08시 하차인원",
// ... 24시간 전체 시간대
}
⚙️데이터 파이프라인 구축
아키텍처 설계
본 프로젝트는 확장 가능하고 성능이 최적화된 현대적 데이터 레이크하우스 아키텍처를 구현했습니다. 원본 JSON 데이터를 클라우드 스토리지에 저장하고, Delta Lake 형식으로 변환하여 ACID 트랜잭션과 스키마 진화를 지원하며, 최종적으로 관계형 데이터베이스와 BI 도구로 연결하는 다층 구조를 채택했습니다.
전체 데이터 파이프라인(시각화 제외)은 Apache Spark Operator를 통해 구현되어 분산 처리 환경에서 안정적이고 확장 가능한 데이터 처리를 보장합니다.
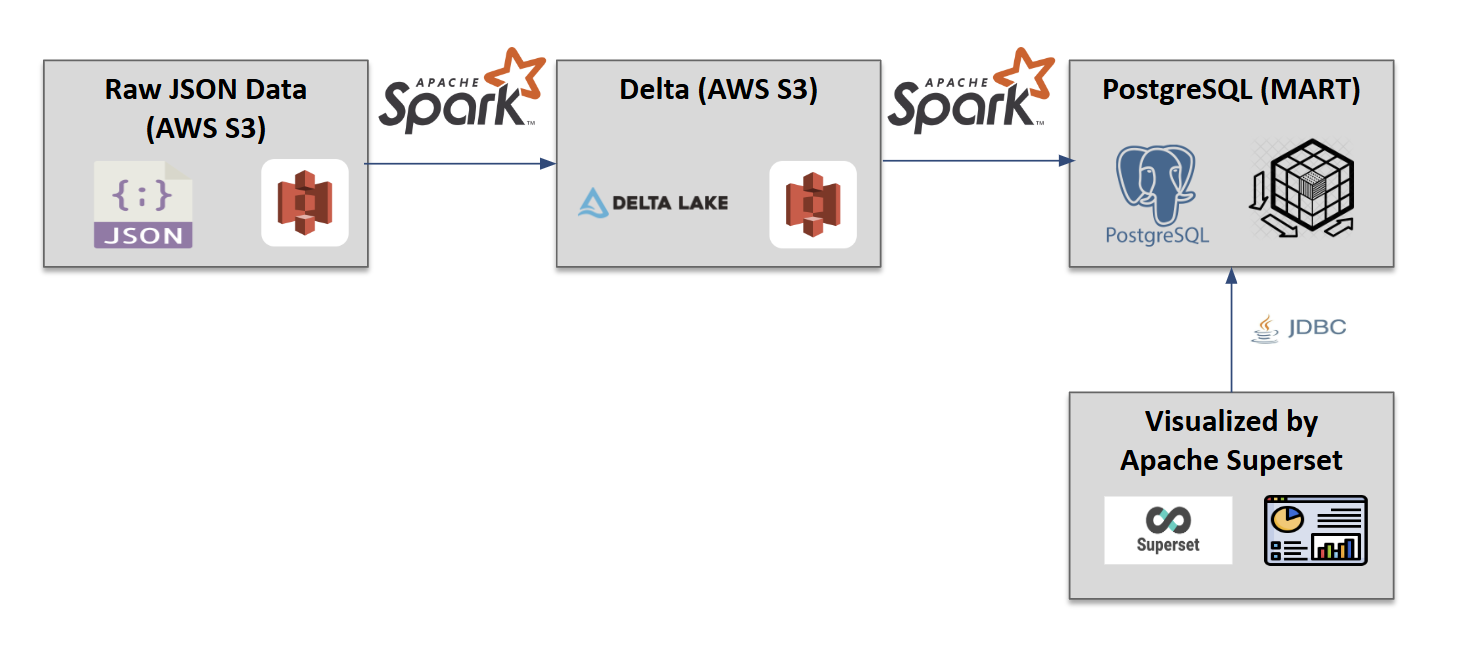
기술 스택:
- 데이터 처리: Apache Spark
- 데이터 저장: Delta Lake, PostgreSQL
- 시각화: Apache Superset
- 개발 환경: Jupyter Notebook
- 플랫폼: DIP 포털
데이터 정규화 과정
원본 JSON의 넓은 형태(Wide Format) 데이터를 분석에 적합한 긴 형태(Long Format)로 변환했습니다:
변환 전 (Wide Format): JSON파일 또는 Delta 테이블 스키마
사용년월 | 노선명 | 지하철역 | HR_7_GET_ON | HR_7_GET_OFF | HR_8_GET_ON | HR_8_GET_OFF | ...
변환 후 (Long Format): PostgreSQL의 테이블 스키마
CREATE TABLE subway_passengers_time (
use_ym VARCHAR(6), -- 사용년월
line_no VARCHAR(100), -- 노선명
station_name VARCHAR(100), -- 역명
time_term VARCHAR(20), -- 시간대
pass_in NUMERIC(12), -- 승차인원
pass_out NUMERIC(12), -- 하차인원
reg_date VARCHAR(8), -- 등록일자
PRIMARY KEY (use_ym, line_no, station_name, time_term)
);
최종 데이터 규모: 10년 4개월치 1,768,608 레코드
데이터 파이프라인 구현
Spark를 활용한 데이터 파이프라인의 핵심 코드는 다음과 같습니다:
def subway_data_time_overwrite(spark, s3_config, pg_config, json_file):
"""
지하철 승객 시간대별 데이터 처리 메인 파이프라인
JSON 원본 데이터 → Delta Lake → PostgreSQL 순서로 데이터를 처리
Args:
spark: Spark 세션 객체
s3_config: S3 설정 정보 (bucket, access_key, secret_key 등)
pg_config: PostgreSQL 설정 정보 (host, port, dbname, user, password)
json_file: 처리할 JSON 파일명
"""
# PostgreSQL JDBC 연결 URL 생성
pg_url = f"jdbc:postgresql://{pg_config['host']}:{pg_config['port']}/{pg_config['dbname']}"
# PostgreSQL 연결 속성 설정
pg_properties = {
"user": pg_config['user'],
"password": pg_config['password'],
"driver": "org.postgresql.Driver"
}
print(f" bucket name is {s3_config['bucket']}")
# S3 파일 경로 정의
json_source_key = f"datasource/{json_file}" # 원본 JSON 파일 경로
json_archive_key = f"archive/{json_file}" # 처리 완료 후 아카이브할 경로
json_file_path = f"s3a://{s3_config['bucket']}/{json_source_key}" # 전체 S3 파일 경로
# Delta Lake 테이블 저장 경로
delta_table_path = f"s3a://{s3_config['bucket']}/deltalake/subway_passengers_time"
# PostgreSQL 테이블명
pg_table_name = "subway_passengers_time"
try:
# =================================================================
# 단계 1: S3에서 JSON 파일 읽기 및 DataFrame 생성
# =================================================================
print(f"S3에서 JSON 파일 읽는 중: {json_file_path}...")
# JSON 파일의 특수한 구조 처리를 위해 원시 텍스트로 읽기
# 실제 데이터가 JSON의 "DATA" 키 안에 배열 형태로 저장되어 있음
raw_json_rdd = spark.sparkContext.textFile(json_file_path)
# RDD의 모든 라인을 하나의 문자열로 결합
raw_json_string = "".join(raw_json_rdd.collect())
# JSON 문자열을 Python 딕셔너리로 파싱
data_dict = json.loads(raw_json_string)
# 'DATA' 키에서 실제 데이터 레코드 목록 추출
records = data_dict.get("DATA")
if not records:
print("오류: JSON에서 'DATA' 키를 찾을 수 없거나 비어 있습니다.")
return
# 추출한 레코드 목록으로 Spark DataFrame 생성
df_json = spark.createDataFrame(records)
# =================================================================
# 단계 2: Delta Lake에 데이터 저장 (덮어쓰기 모드)
# =================================================================
print(f"Delta Lake 테이블에 데이터 저장 중: {delta_table_path}")
# overwrite 모드로 Delta Lake에 데이터 저장
df_json.write.format("delta").mode("overwrite").save(delta_table_path)
print("Delta Lake 테이블에 데이터 저장 완료")
# =================================================================
# 단계 3: 처리 완료된 JSON 파일을 아카이브 폴더로 이동
# =================================================================
print(f"처리 완료된 JSON 파일을 아카이브 폴더로 이동 중...")
move_s3_file(s3_config, json_source_key, json_archive_key)
# =================================================================
# 단계 4: Delta Lake 데이터를 변형하여 PostgreSQL에 적재
# =================================================================
print(f"PostgreSQL 테이블에 데이터 삽입 중: {pg_table_name}")
# 시간대별 컬럼(hr_0~hr_23)을 행으로 변환하는 UNPIVOT 작업을 UNION ALL로 구현
# 원본 데이터: 1개 행에 24개 시간대 컬럼
# 변환 후: 24개 행으로 각 시간대별 데이터 분리
insert_sql = f"""
-- 00시-01시 승하차 데이터
select use_mm use_ym -- 사용년월
, sbwy_rout_ln_nm line_no -- 지하철 노선명
, sttn station_name -- 역명
, '00시-01시' time_term -- 시간대
, hr_0_get_on_nope pass_in -- 승차인원
, hr_0_get_off_nope pass_out -- 하차인원
, job_ymd reg_date -- 등록일자
from delta.`{delta_table_path}`
union all
-- 01시-02시 승하차 데이터
select use_mm use_ym
, sbwy_rout_ln_nm line_no
, sttn station_name
, '01시-02시' time_term
, hr_1_get_on_nope pass_in
, hr_1_get_off_nope pass_out
, job_ymd reg_date
from delta.`{delta_table_path}`
union all
...
"""
# Spark SQL 실행하여 변환된 DataFrame 생성
delta_df = spark.sql(insert_sql)
# PostgreSQL에 데이터 쓰기 (overwrite 모드로 기존 데이터 삭제 후 신규 데이터 적재)
delta_df.write \
.jdbc(url=pg_url,
table=pg_table_name,
mode="overwrite",
properties=pg_properties)
print(f"PostgreSQL 테이블 {pg_table_name}에 데이터 적재 완료")
print(f"--- 모든 처리가 성공적으로 완료되었습니다! ---")
except Exception as e:
print(f"데이터 처리 중 오류가 발생했습니다: {e}")
import traceback
traceback.print_exc() # 상세한 에러 스택 트레이스 출력
주요 구현 포인트:
- 동적 컬럼 처리: 24시간 승하차 데이터를 동적으로 Long Format으로 변환
- Delta Lake 활용: ACID 트랜잭션과 스키마 진화 지원
- 분산 처리: Spark의 분산 컴퓨팅으로 대용량 데이터 효율적 처리
- 데이터 품질: 중복 제거 및 집계를 통한 데이터 정합성 확보
📊대시보드 개발
Apache Superset을 활용하여 두 개의 주요 대시보드를 구축했습니다.
대시보드 1: 시간대별 혼잡도 상세 분석
목표: 특정 기간, 노선, 역의 시간대별 승하차 패턴 분석을 통한 최적 이동시간 제안
주요 기능:
- 동적 필터링: 조회 기간, 노선명 다중 선택, 역명 다중 선택
- 실시간 분석: 사용자 선택에 따른 즉시 차트 업데이트
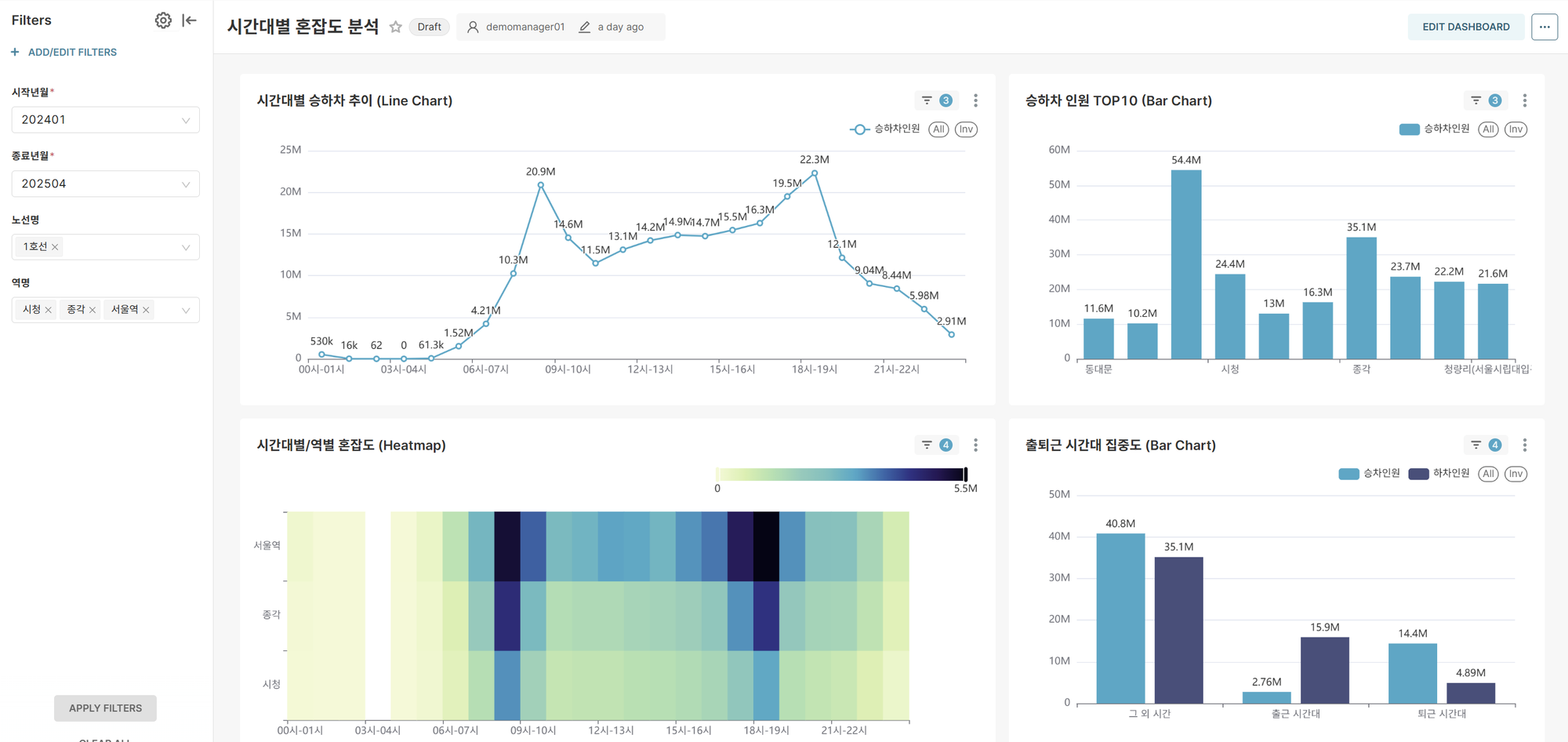
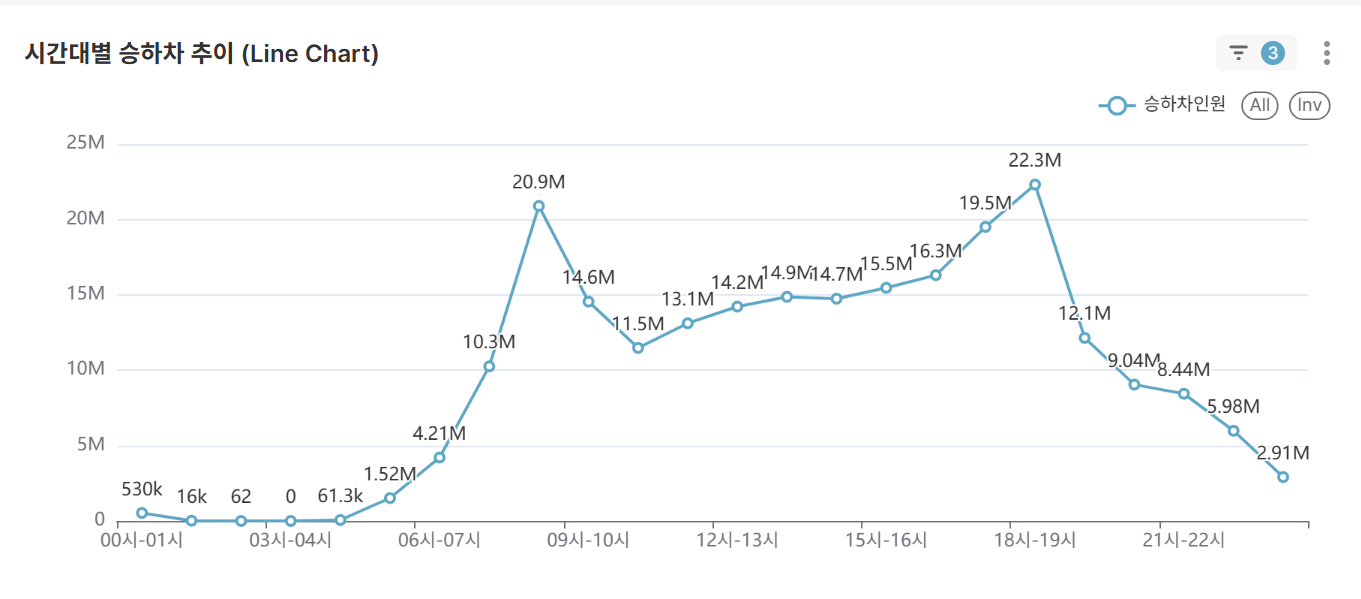
핵심 차트:
-
시간대별 평균 승하차 추이 (Line Chart)
- 선택된 조건의 시간대별 평균 승하차 패턴 시각화
- 출퇴근 러시아워 및 한적한 시간대 식별
-
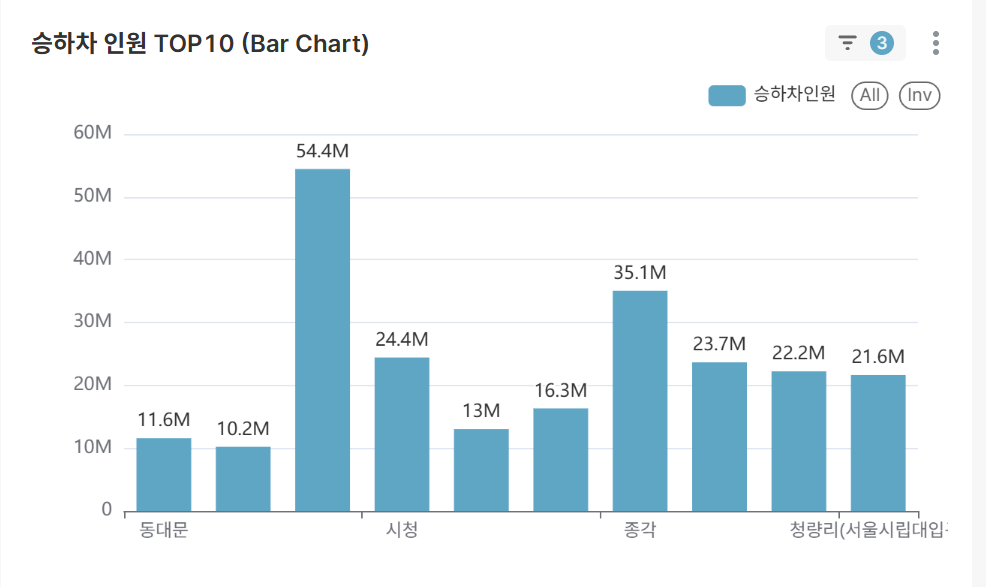
승하차 인원 TOP 10 역 (Bar Chart)
- 선택 조건에서 가장 붐비는 상위 10개 역 랭킹
- 주요 교통 허브 역 식별
-
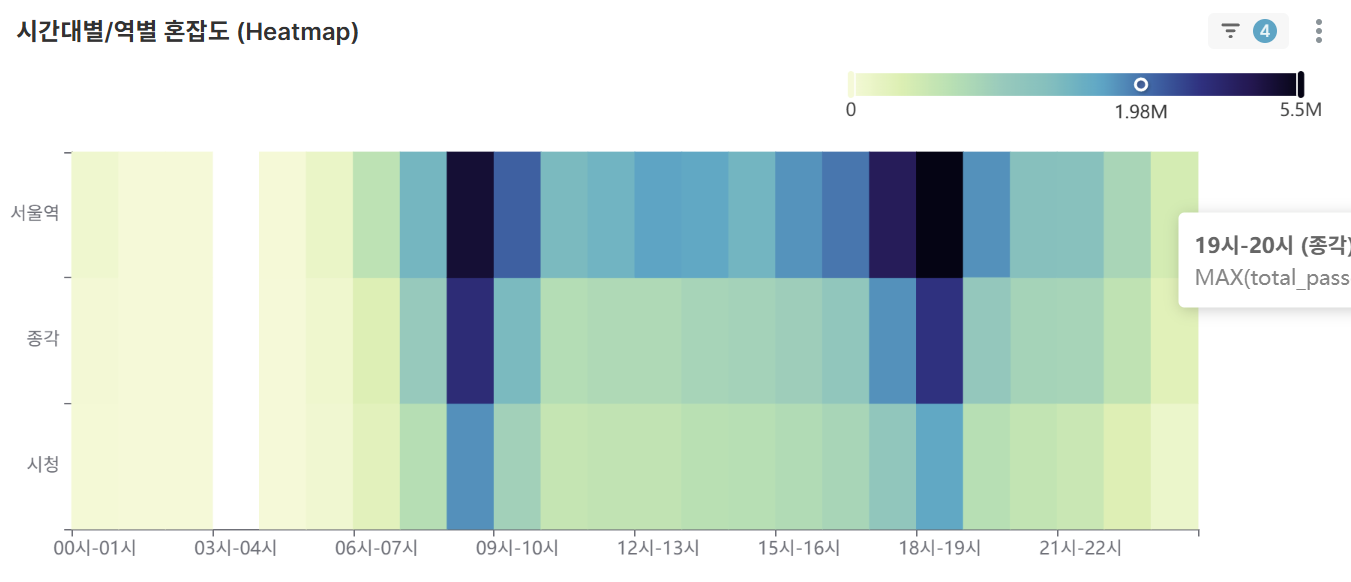
시간대별/역별 혼잡도 히트맵 (Heatmap)
- 선택한 역 조건에서 2차원 매트릭스로 시간-역별 혼잡도 한눈에 파악
- 색상 강도로 혼잡 정도 직관적 표현
-
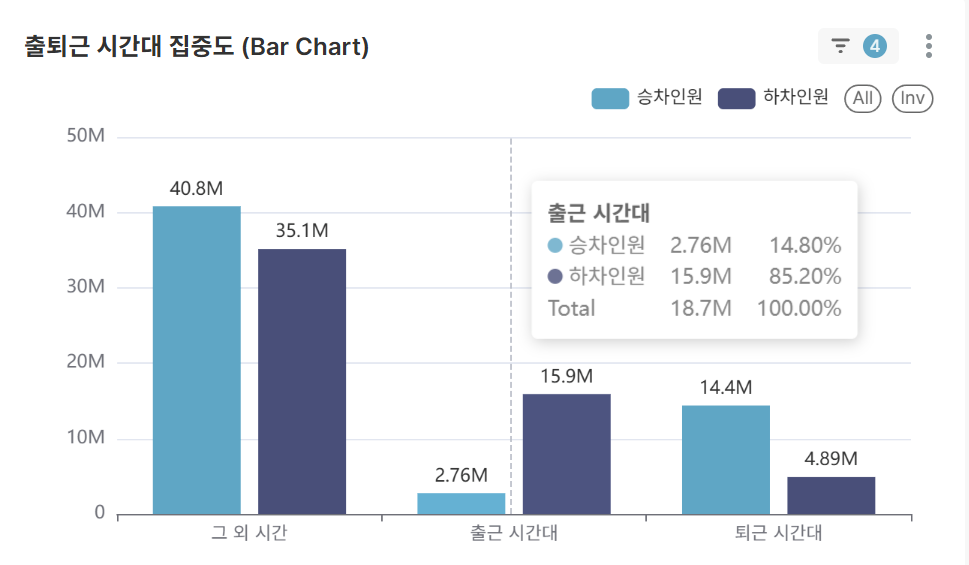
출퇴근 시간대 집중도 분석 (Bar Chart)
- 선택한 역 조건에서 출퇴근 시간(07-09시, 18-20시) vs 기타 시간대 승객 분포
- 교통 집중도 정량적 분석
대시보드 2: 환승역 중심의 유동인구 분석
목표: 주요 환승역의 교통 허브 역할과 노선 간 연결성 심층 분석
주요 기능:
- 동적 필터링: 조회 기간, 환승역 다중 선택
- 실시간 분석: 사용자 선택에 따른 즉시 차트 업데이트
핵심 인사이트:
-
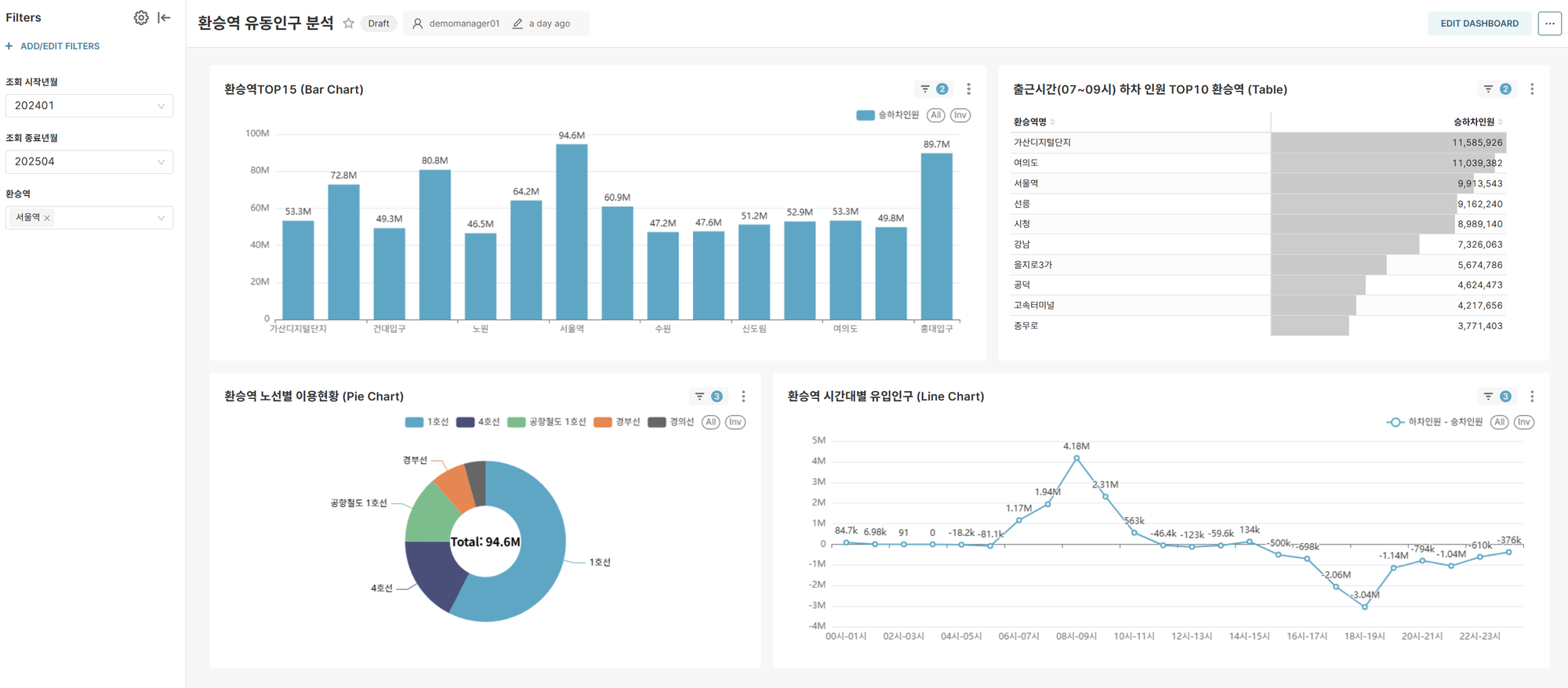
대한민국 환승역 TOP 15 (Bar Chart)
- 전체 기간 이용객 수 기준 주요 환승역 순위
- 국가 교통 인프라의 핵심 노드 식별
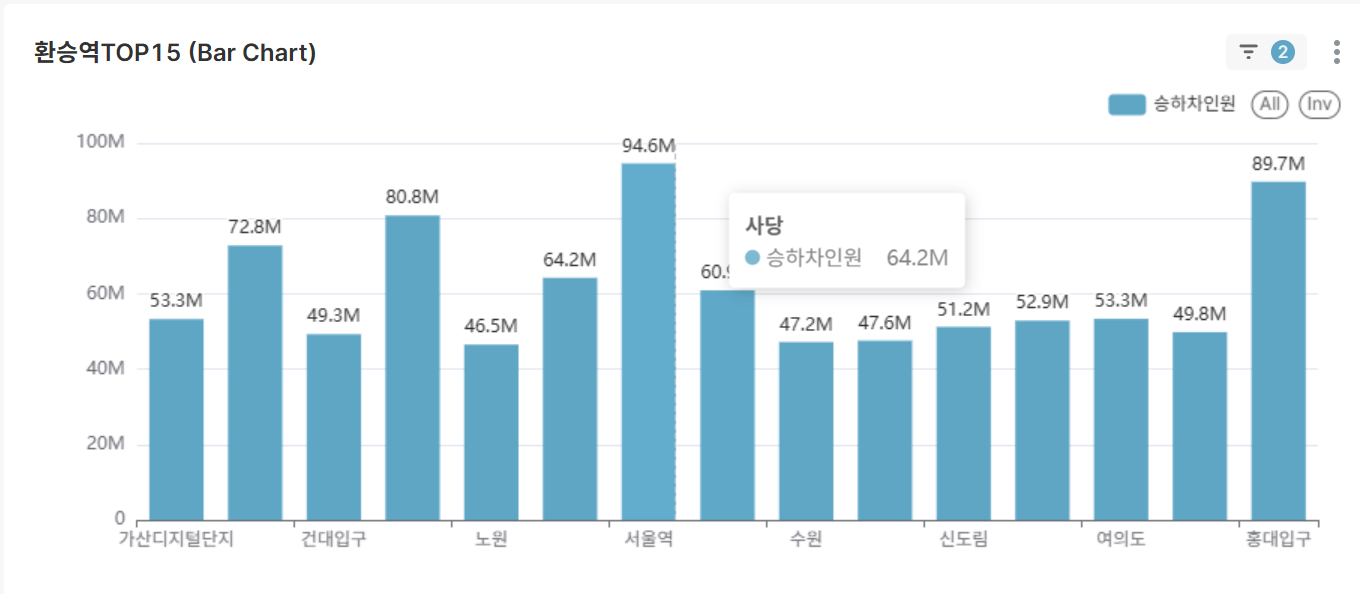
-
출근시간 하차 인원 TOP 10 환승역 (Table)
- 07-09시 하차 집중 환승역 분석
- 주요 업무 지구 연결 환승역 파악
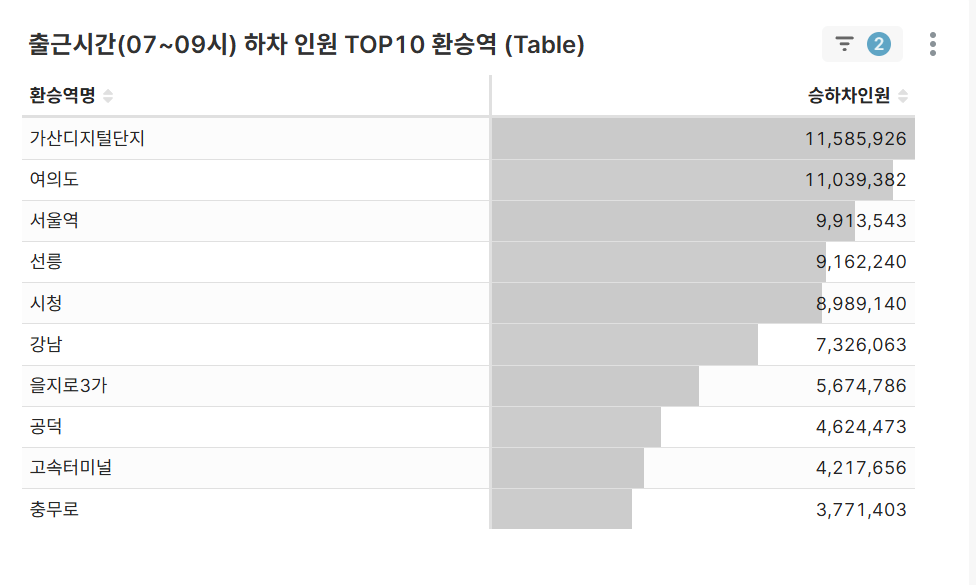
-
환승역 시간대별 순유입 인구 분석 (Line Chart)
- 선택한 환승역 조건에서 순유입(하차인원 - 승차인원) 인구 분석
양수(+): 도착지 성격 (업무지구)
음수(-): 출발지 성격 (주거지역) - 선택한 환승역의 기능적 특성(주거/업무) 정량적 분석
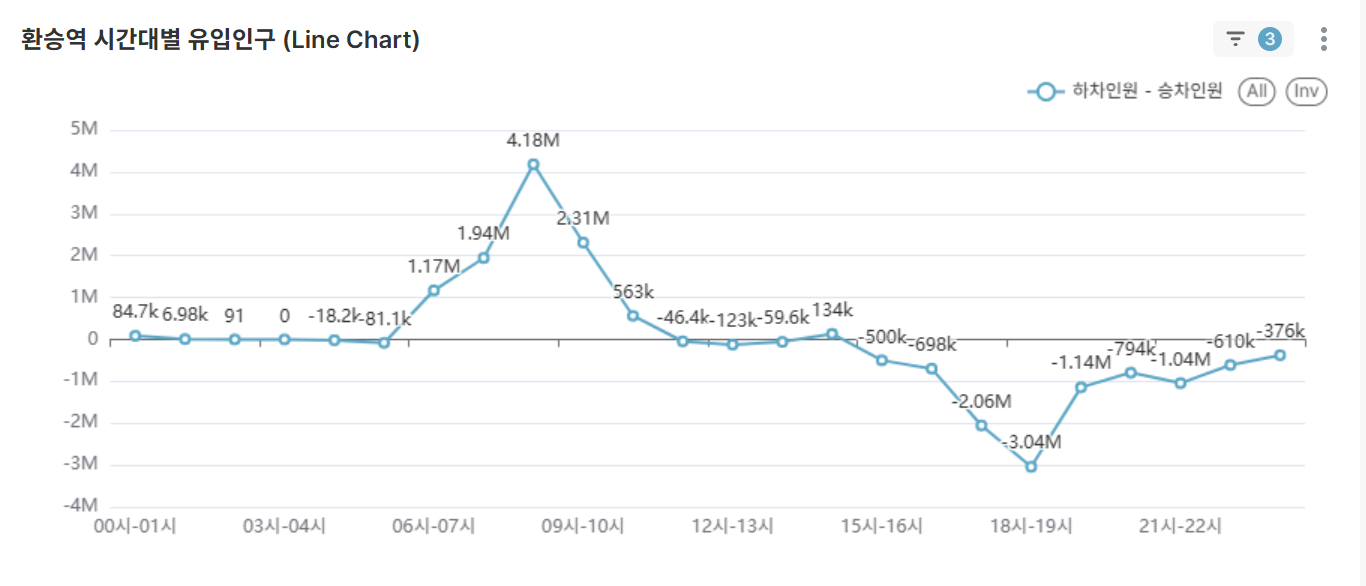
- 선택한 환승역 조건에서 순유입(하차인원 - 승차인원) 인구 분석
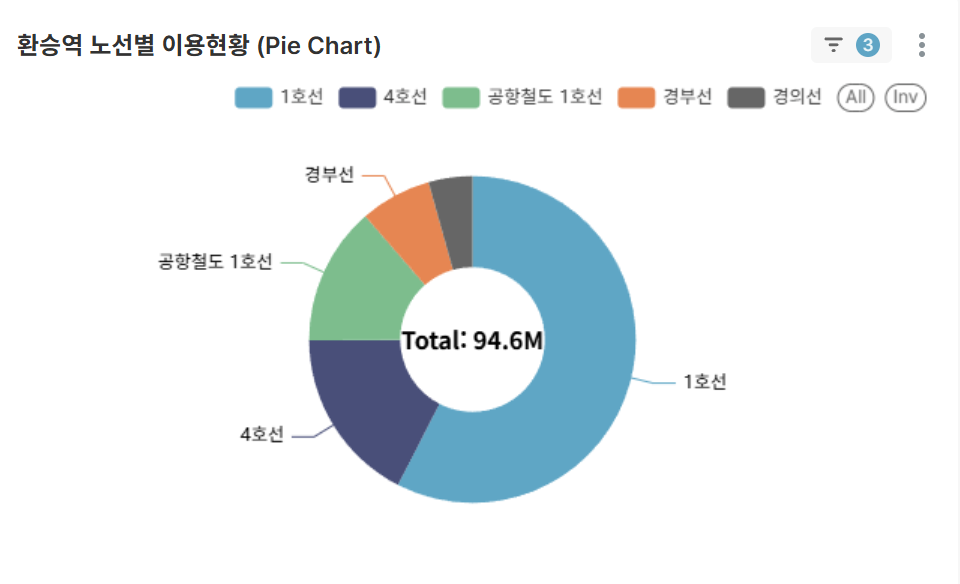
-
환승역의 노선별 기여도 (Pie Chart)
- 선택한 환승역 내 각 노선별 이용 비중
- 핵심 노선과 보조 노선 구분
📈비즈니스 인사이트
-
출퇴근 집중 현상
- 07-09시, 18-20시에 전체 승객의 약 40% 집중
- 강남역, 잠실역 등 업무 중심지 하차 집중
-
환승역 허브 효과
- 상위 5개 환승역이 전체 교통량의 25% 담당
- 노선별 특성에 따른 차별화된 이용 패턴
-
지역별 특성 분석
- 주거지역: 아침 승차, 저녁 하차 집중
- 업무지역: 아침 하차, 저녁 승차 집중
🚀마무리
이 프로젝트를 통해 단순한 승하차 데이터가 도시민의 생활 패턴과 도시 구조를 이해하는 강력한 도구가 될 수 있음을 확인했습니다.
현대적인 데이터 파이프라인과 시각화 도구를 활용하여 공공데이터의 가치를 극대화하고, 시민들의 교통 편의를 향상시킬 수 있는 인사이트를 도출할 수 있었습니다.