
Apache Flink를 활용한 API Gateway 실시간 로그 분석 파이프라인 최적화
Apache Flink를 활용하여 Kafka 메시지를 사전 가공함으로써 StarRocks 쿼리 부하를 90% 절감하고 대시보드 응답 속도를 70% 개선한 실시간 로그 분석 파이프라인 최적화 사례
목차
들어가며
이전 블로그에서는 PAASUP DIP의 API Gateway 로그를 실시간으로 수집하고 StarRocks에 저장한 뒤 Apache Superset으로 시각화하는 모니터링 시스템 구축 사례를 소개했습니다.
당시 아키텍처는 Kafka의 StarRocks Sink Connector를 사용하여 API Gateway 로그를 필터링이나 가공 없이 그대로 kong_log_events 테이블에 적재하는 방식이었습니다. 이로 인해 다음과 같은 문제점이 발생했습니다:
- 불필요한 데이터 저장: Access Log 분석에 필요하지 않은 row와 column이 포함
- 실시간 쿼리 부하: 수초마다 갱신되는 대시보드가 매번 복잡한 정규식(
REGEXP_EXTRACT)과 문자열 함수(SPLIT_PART)를 실행 - 시스템 리소스 낭비: 동일한 파싱 로직이 매 쿼리마다 반복 수행
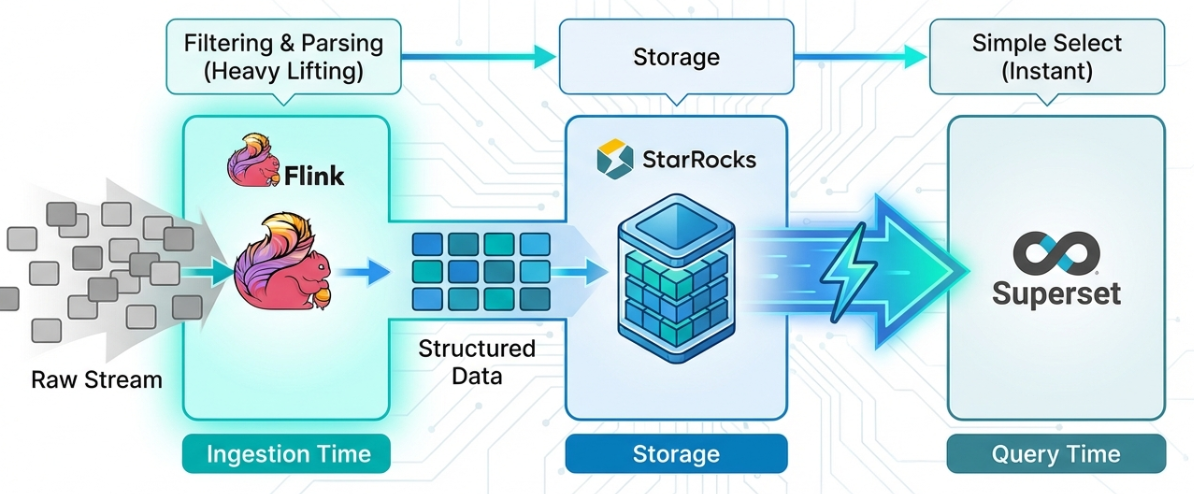
본 블로그에서는 Apache Flink Cluster를 활용하여 Kafka 메세지를 필터링하고 가공하여 타겟DB에 데이터를 저장함으로써 실시간 로그 분석 파이프라인을 경량화한 사례를 공유합니다.
1. 아키텍처 비교
1.1 이전 아키텍처 (StarRocks Sink Connector)
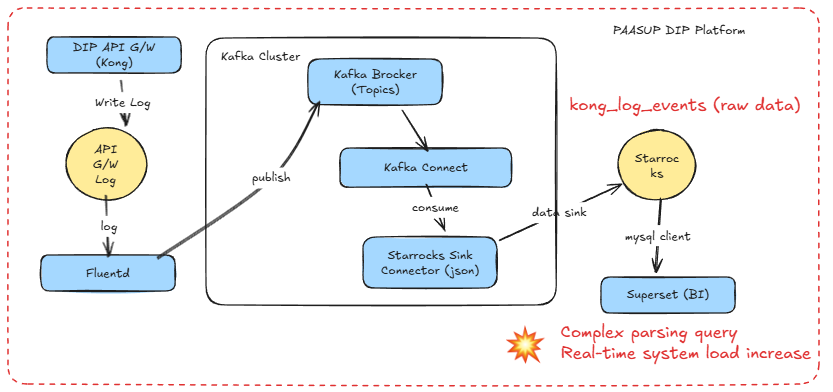
문제점:
- 매 대시보드 조회마다
message컬럼 파싱 수행 - 7개 이상의
REGEXP_EXTRACT,SPLIT_PART함수 반복 실행 - 불필요한 로그 데이터(stderr, API Gateway가 자체적으로 생산한 Healthy check event 등)도 저장
1.2 현재 아키텍처 (Apache Flink 기반)
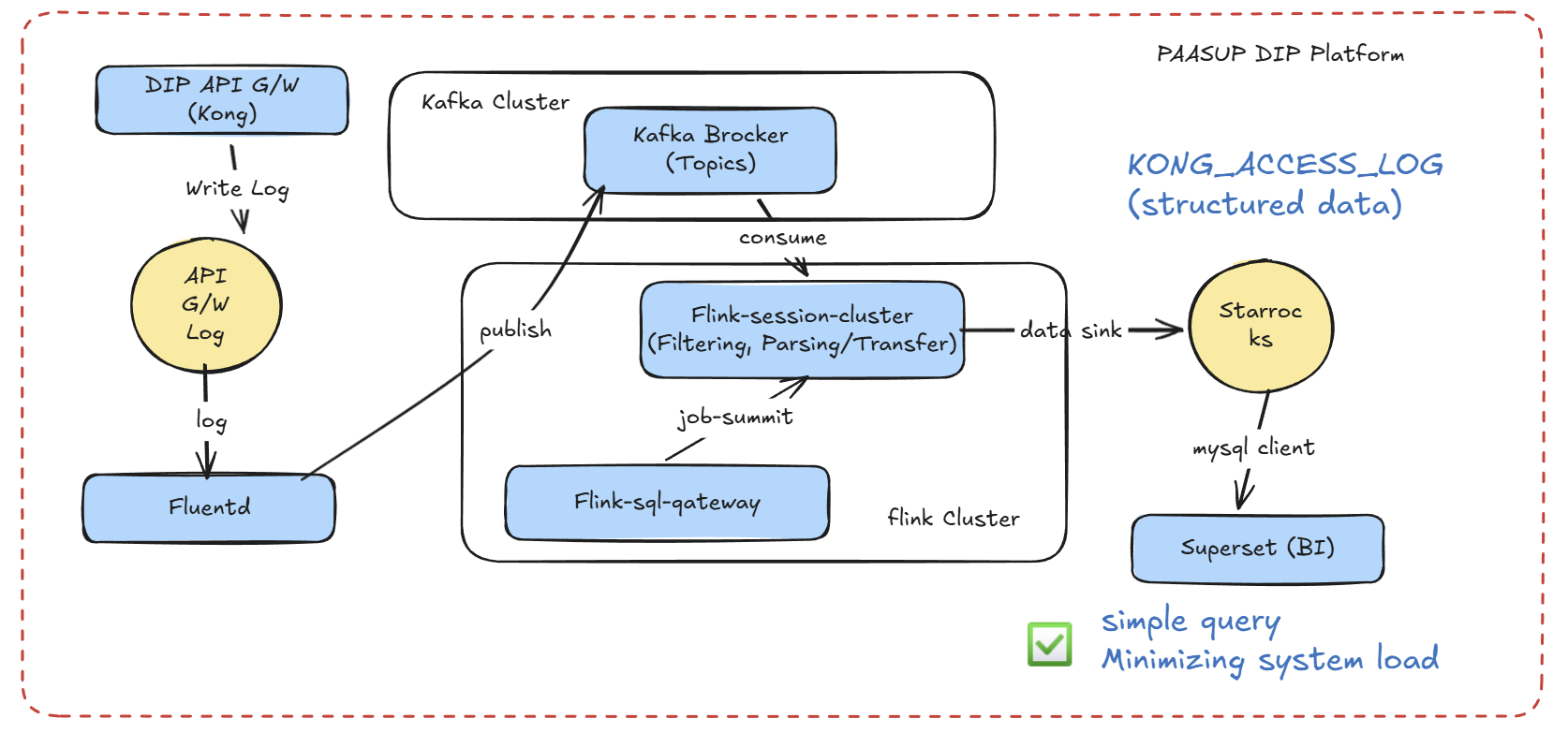
개선사항:
- Flink에서 1회만 파싱 수행, StarRocks에는 정제된 데이터 저장
- Superset 쿼리가 단순 컬럼 조회로 변경
- 불필요한 데이터를 Flink 레벨에서 필터링 (저장소 효율 증가)
2. 개발환경
2.1 개발환경 목록
| 구성요소 | 버전/도구 | 용도 |
|---|---|---|
| Apache Flink | 2.01 | 실시간 스트림 처리 |
| Flink SQL Gateway | REST API | Python에서 Flink SQL 실행 |
| Apache Kafka | 4.0 | 메시지 큐 |
| StarRocks | 4.0.4 | OLAP 데이터베이스 |
| Python | 3.0+ | Flink SQL Gateway 클라이언트 |
| Jupyter Notebook | - | 파이프라인 개발/테스트 |
| Apache Superset | 4.1.1 | 대시보드 BI 도구 |
2.2 Apache Flink Cluster 생성
DIP 클러스터 카탈로그에는 관리자가 flink-kubernetes-operator가 생성되어 있어야 합니다.
프로젝트 책임자는 DIP 프로젝트 카탈로그 생성 메뉴에서 flink cluster를 생성합니다.
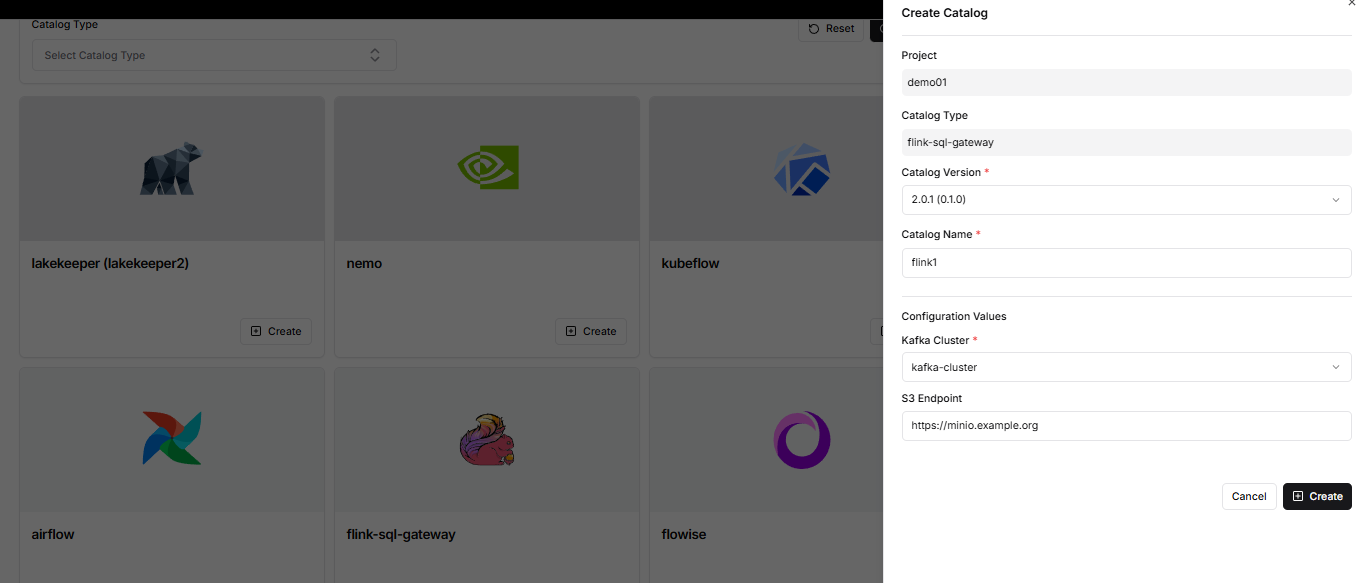
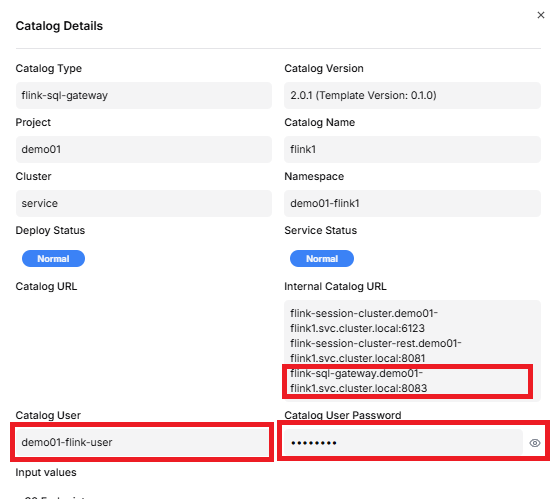
프로젝트 카탈로그 조회 메뉴에서 flink-sql-gateway의 보기 버튼을 click하면 flink-sql-ateway url과 Catalog User, Catalog User Password를 조회할 수 있으며 이 정보는 실시간 데이터 파이프라인을 구축할 때 사용합니다.
3. 실시간 데이터 파이프라인 구축
3.1 Flink SQL Gateway 클라이언트
Python으로 Flink SQL Gateway REST API를 호출하는 클라이언트를 구현했습니다. 주요 기능은 다음과 같습니다:
세션 관리 및 에러 핸들링
class FlinkSQLGatewayClient:
def __init__(self, gateway_url: str = "http://localhost:8083"):
self.gateway_url = gateway_url.rstrip('/')
self.session_handle = None
def create_session(self, savepoints: Optional[str] = None) -> str:
"""
새로운 SQL Gateway 세션 생성
savepoints 경로가 있으면 해당 시점부터 복구
"""
properties = {
"execution.runtime-mode": "streaming",
"sql-gateway.session.idle-timeout": "30min",
"table.exec.resource.default-parallelism": "1"
}
if savepoints:
properties["execution.savepoint.path"] = savepoints
# 세션 생성 로직...
3.2 Kafka Source 테이블 정의
Kafka에서 Kong 로그를 읽어오는 Source 테이블을 정의합니다:
source_ddl = f"""
CREATE TABLE IF NOT EXISTS source_kong_log (
`time` STRING,
`stream` STRING,
`message` STRING
) WITH (
'connector' = 'kafka',
'topic' = '{SOURCE_TOPIC}',
'properties.bootstrap.servers' = '{BOOTSTRAP_SERVER}',
'properties.group.id' = '{GROUP_ID}',
'properties.auto.offset.reset' = 'latest',
-- SASL_SSL 보안 설정
'properties.security.protocol' = 'SASL_SSL',
'properties.sasl.mechanism' = 'SCRAM-SHA-512',
'properties.sasl.jaas.config' = 'org.apache.kafka.common.security.scram.ScramLoginModule required username="{KAFKA_USER}" password="{KAFKA_PASSWORD}";',
'properties.ssl.truststore.location' = '/opt/flink/certs/ca.p12',
'properties.ssl.truststore.password' = '[YOUR-SSL-KEY]',
'properties.ssl.truststore.type' = 'PKCS12',
-- JSON 포맷 설정
'format' = 'json',
'json.timestamp-format.standard' = 'ISO-8601',
'json.ignore-parse-errors' = 'true'
)
"""
client.execute_sql(source_ddl)
3.3 StarRocks Sink 테이블 정의
파싱된 데이터를 저장할 StarRocks 테이블을 정의합니다:
sink_ddl = f"""
CREATE TABLE IF NOT EXISTS sink_starrocks (
`log_time` STRING,
`stream` STRING,
`client_ip` STRING,
`response_time` DOUBLE,
`host_domain` STRING,
`request_url` STRING,
`status_code` INT,
`project_name` STRING,
`original_message` STRING
) WITH (
'connector' = 'jdbc',
'url' = 'jdbc:mysql://kube-starrocks-fe-service.demo01-star3.svc.cluster.local:9030/quickstart?useSSL=false',
'table-name' = '{SR_TABLE_NAME}',
'username' = '{SR_USERNAME}',
'password' = '{SR_PASSWORD}'
)
"""
client.execute_sql(sink_ddl)
StarRocks 테이블 스키마 (미리 생성 필요):
CREATE TABLE quickstart.KONG_ACCESS_LOG (
log_time DATETIME,
stream VARCHAR(20),
client_ip VARCHAR(45),
response_time DOUBLE,
host_domain VARCHAR(255),
request_url VARCHAR(1000),
status_code INT,
project_name VARCHAR(100),
original_message STRING
)
DUPLICATE KEY(log_time)
DISTRIBUTED BY HASH(log_time) BUCKETS 10
PROPERTIES (
"replication_num" = "1"
);
3.4 실시간 ETL 쿼리
핵심인 ETL 쿼리입니다. Kafka 메시지를 파싱하여 StarRocks로 전송합니다:
INSERT INTO sink_starrocks
SELECT
-- UTC → KST 시간 변환
CONVERT_TZ(
REPLACE(REPLACE(`time`, 'T', ' '), 'Z', ''),
'UTC',
'Asia/Seoul'
) AS log_time,
`stream`,
-- Client IP 추출
SPLIT_INDEX(message, ' ', 0) AS client_ip,
-- Response Time 추출 및 타입 변환
CAST(
REGEXP_EXTRACT(message, 'HTTP/[0-9.]+" [0-9]+ ([0-9.]+)', 1)
AS DOUBLE
) AS response_time,
-- Host Domain 추출
REGEXP_EXTRACT(
message,
'HTTP/[0-9.]+" [0-9]+ [-0-9. ]+ "(.*?)"',
1
) AS host_domain,
-- Request URL 추출 (쿼리스트링 제거)
SPLIT_INDEX(
REGEXP_EXTRACT(message, '"(GET|POST|PUT|DELETE|HEAD|OPTIONS) (.*?) HTTP', 2),
'?',
0
) AS request_url,
-- HTTP Status Code 추출
CAST(
REGEXP_EXTRACT(message, 'HTTP/[0-9.]+" ([0-9]{3})', 1)
AS INT
) AS status_code,
-- Project Name 추출 (host_domain에서 파생)
CASE
WHEN REGEXP_EXTRACT(message, 'HTTP/[0-9.]+" [0-9]+ [-0-9. ]+ "(.*?)"', 1) LIKE '%-%'
THEN SPLIT_INDEX(
REGEXP_EXTRACT(message, 'HTTP/[0-9.]+" [0-9]+ [-0-9. ]+ "(.*?)"', 1),
'-',
0
)
ELSE 'platform'
END AS project_name,
-- 원본 메시지 보관 (디버깅용)
message AS original_message
FROM source_kong_log
-- 필터링 조건
WHERE
`stream` = 'stdout' -- 표준 출력 로그만 필터링
AND message LIKE '%HTTP/%' -- HTTP 프로토콜 로그만 필터링
AND REGEXP_EXTRACT(message, '^[0-9]{1,3}\\.[0-9]{1,3}\\.[0-9]{1,3}\\.[0-9]{1,3}') IS NOT NULL -- IP 형식 검증
AND SPLIT_INDEX(message, ' ', 0) <> '127.0.0.1' -- API Gateway 자체 생성 메세지 제외
파이프라인 실행
print(">>> [3/3] Streaming Job 제출 중...")
result = client.execute_sql(etl_sql)
print(f"\n[Success] Flink Job Submitted Successfully!")
print(f"Job ID: {result.get('operationHandle')}")
Savepoint 활용 (장애 복구)
Flink는 Savepoint 기능을 통해 특정 시점부터 파이프라인을 재시작할 수 있습니다:
savepoint는 flink dashboard에서 조회할 수 있습니다.
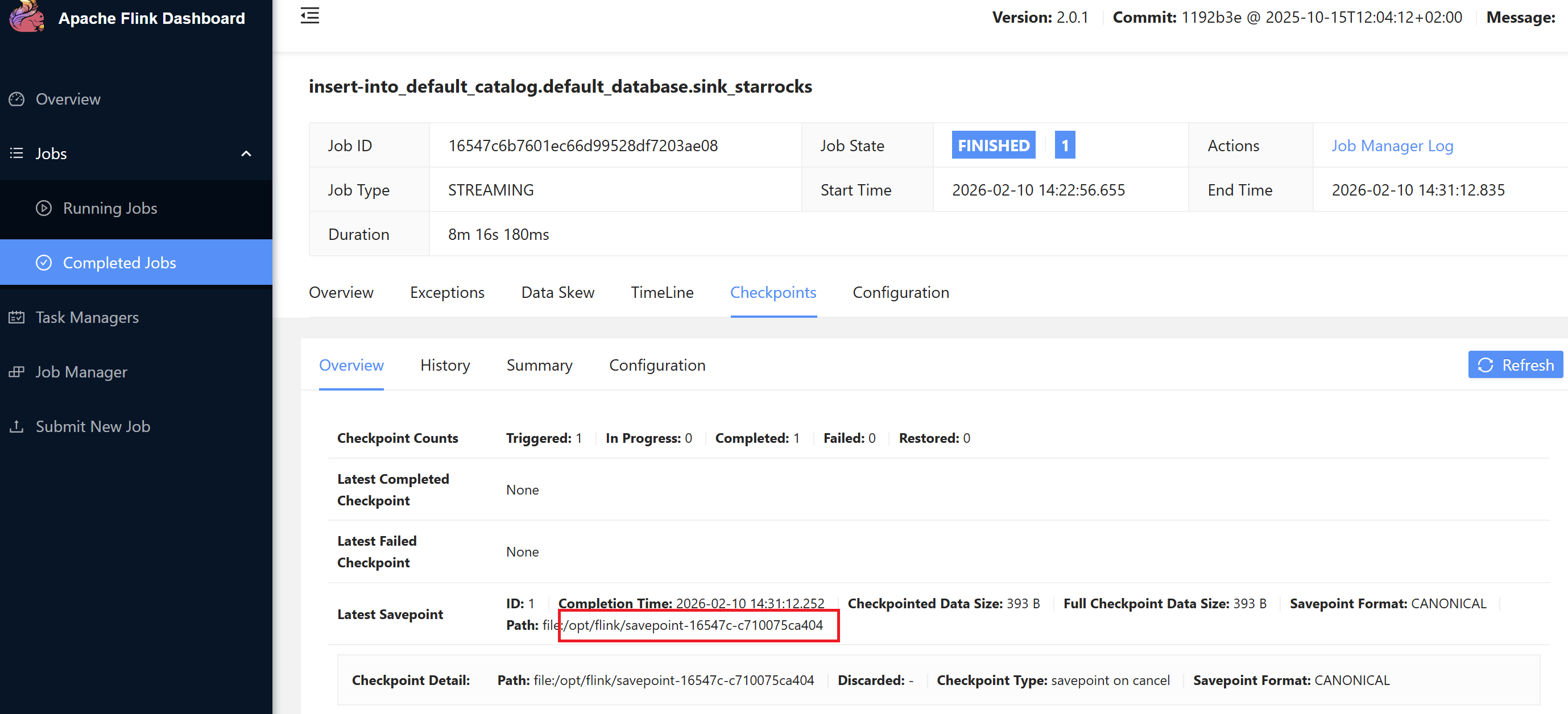
# 재작업 시 savepoint 경로 지정
client.create_session("/opt/flink/savepoint-16547c-c710075ca404")
4. 대시보드 생성
4.1 이전 사례: 복잡한 Dataset SQL
매 대시보드 조회마다 실행되는 쿼리입니다. 복잡한 파싱 로직이 포함되어 있습니다:
SELECT
kst_time,
split_part(message, ' ', 1) AS client_ip,
regexp_extract(message, 'HTTP/[0-9.]+" [0-9]+ ([0-9.]+)', 1) AS response_time,
regexp_extract(message, 'HTTP/[0-9.]+" [0-9]+ [-0-9. ]+ "(.*?)"', 1) AS host_domain,
CASE
WHEN regexp_extract(message, 'HTTP/[0-9.]+" [0-9]+ [-0-9. ]+ "(.*?)"', 1) LIKE '%-%'
THEN split_part(regexp_extract(message, 'HTTP/[0-9.]+" [0-9]+ [-0-9. ]+ "(.*?)"', 1), '-', 1)
ELSE 'platform'
END AS project_name,
split_part(regexp_extract(message, '"(GET|POST|PUT|DELETE|HEAD|OPTIONS) (.*?) HTTP', 2), '?', 1) AS request_url,
regexp_extract(message, 'HTTP/[0-9.]+" ([0-9]{3})', 1) AS status_code,
message
FROM
quickstart.kong_log_events
WHERE
stream = 'stdout'
AND message LIKE '%HTTP/%'
AND message REGEXP '^[0-9]{1,3}\\.[0-9]{1,3}\\.[0-9]{1,3}\\.[0-9]{1,3}'
AND split_part(message, ' ', 1) != '127.0.0.1'
{% if from_dttm %}
AND kst_time >= '{{ from_dttm }}'
{% endif %}
{% if to_dttm %}
AND kst_time < '{{ to_dttm }}'
{% endif %}
문제점:
regexp_extract7회 호출split_part4회 호출- 동일한 정규식 패턴 중복 실행
- 대시보드 새로고침마다 수천~수만 건의 로그에 대해 파싱 수행
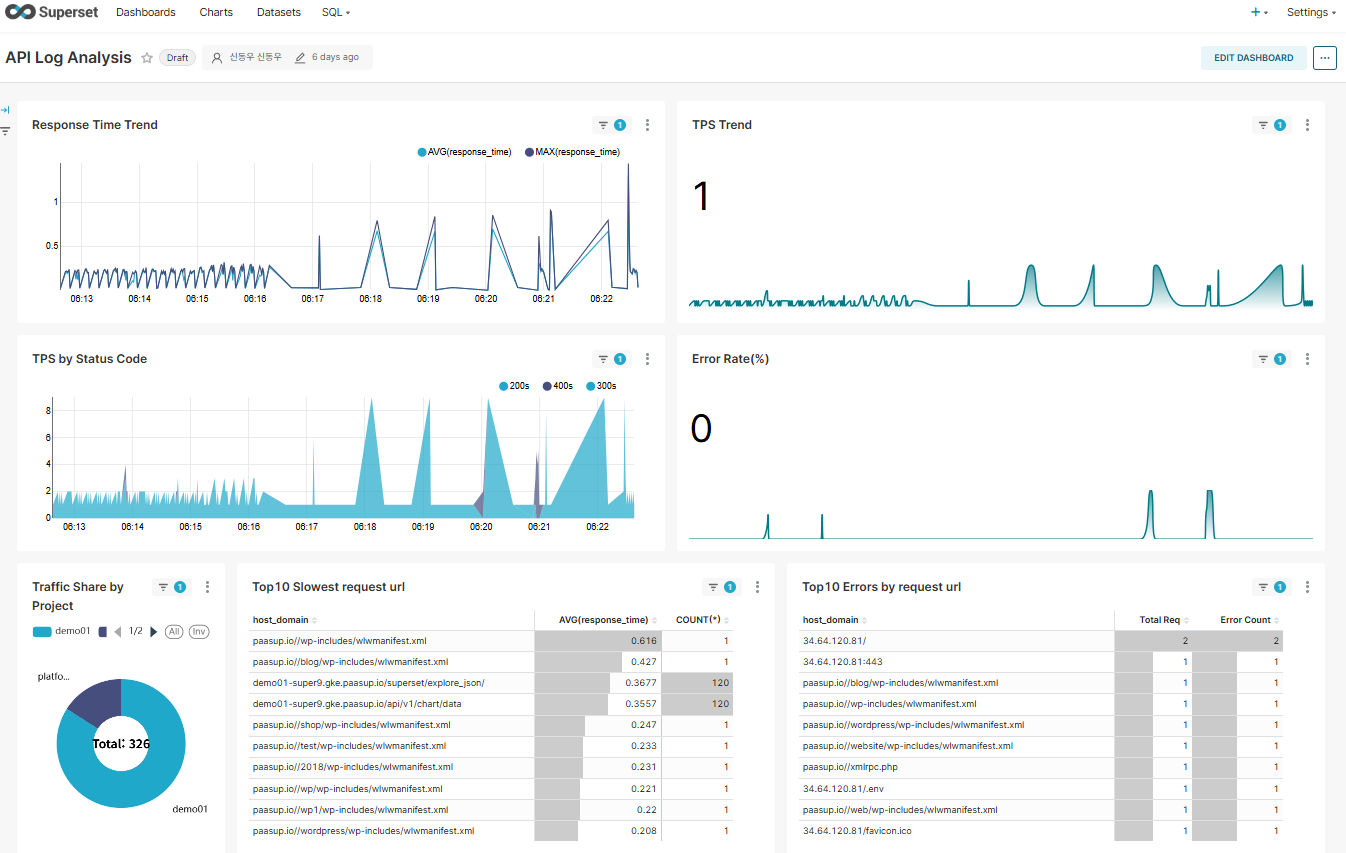
4.2 현재 사례: 단순한 Dataset SQL
Flink에서 이미 파싱된 데이터를 조회하는 단순한 쿼리입니다:
SELECT
log_time,
client_ip,
response_time,
host_domain,
project_name,
request_url,
status_code,
original_message
FROM quickstart.KONG_ACCESS_LOG
{% if from_dttm %}
WHERE log_time >= '{{ from_dttm }}'
{% endif %}
{% if to_dttm %}
AND log_time < '{{ to_dttm }}'
{% endif %}
개선효과:
- 정규식/문자열 함수 호출 0회 (모두 제거)
- 단순 인덱스 스캔으로 성능 대폭 향상
- 쿼리 복잡도 약 90% 감소
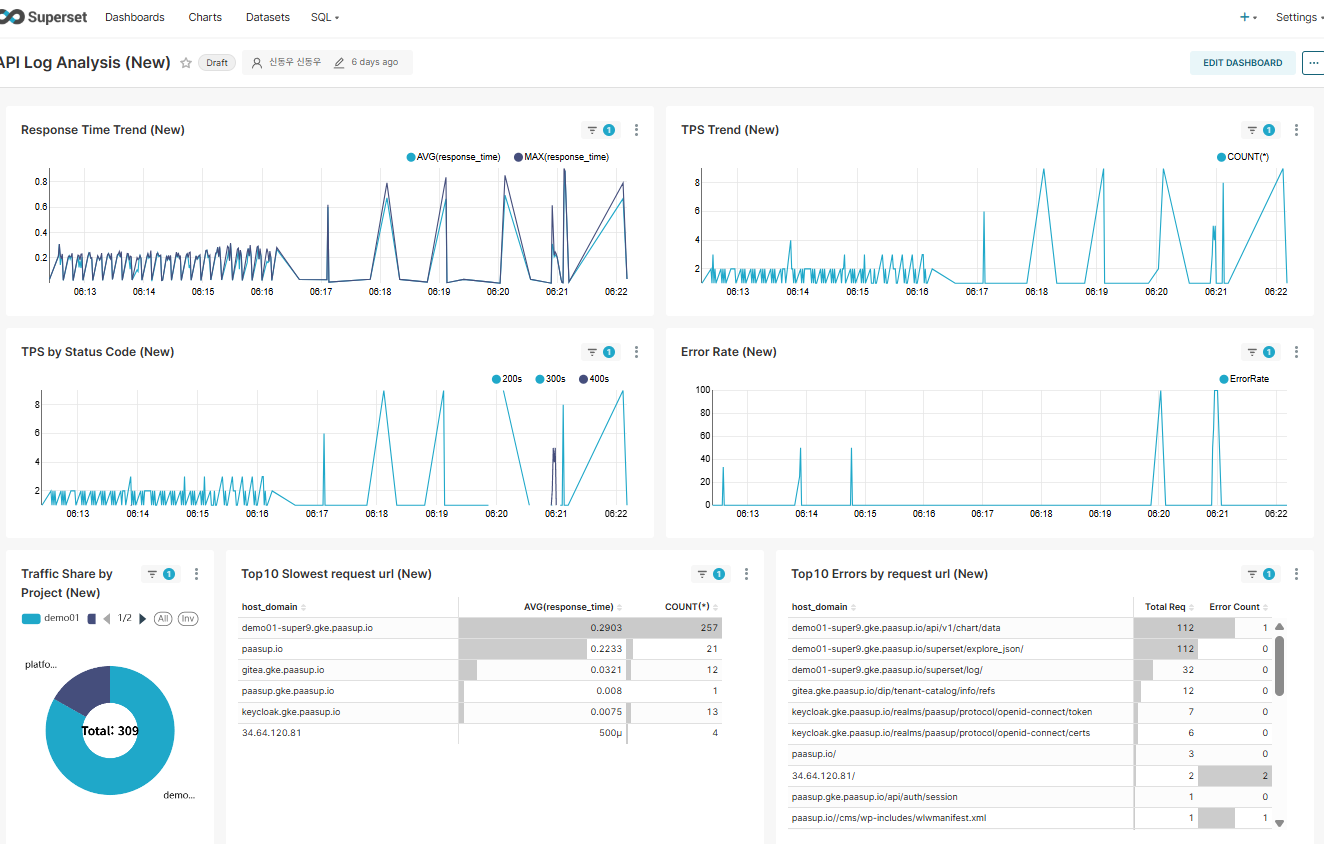
4.3 성능 비교
| 항목 | 이전 (StarRocks Connector) | 현재 (Flink Pipeline) |
|---|---|---|
| 쿼리 복잡도 | 복잡 (11개 함수 호출) | 단순 (SELECT만) |
| 대시보드 로딩 시간 | ~1-2초 | ~0.5초 |
| CPU 사용률 | 높음 | 낮음 |
| 저장 공간 | 100% (전체 로그) | ~50% (필터링된 로그) |
| 확장성 | 쿼리 부하 증가 | Flink 스케일 아웃 가능 |
5. 결론
Apache Flink를 도입하여 실시간 로그 분석 파이프라인을 경량화한 결과 다음과 같은 효과를 얻을 수 있었습니다:
5.1 주요 성과
-
시스템 부하 절감
- Superset 쿼리 복잡도 90% 감소
- 대시보드 응답 시간 70% 개선
- StarRocks CPU 사용률 감소
-
데이터 품질 향상
- Flink 단계에서 데이터 검증 및 필터링
- 불필요한 로그 제거로 저장 공간 50% 절약
- 구조화된 스키마로 데이터 일관성 확보
-
운영 효율성 증대
- Flink Savepoint를 통한 장애 복구
- 파싱 로직의 중앙화 (Flink SQL 한 곳에서 관리)
- Superset 차트 개발 속도 향상
5.2 마무리
Kafka-Flink-StarRocks로 이어지는 스트림 처리 파이프라인은 "가공은 한 번, 조회는 여러 번"이라는 원칙을 실현합니다. 실시간 데이터 분석이 필요한 환경에서 Flink를 활용하면 시스템 전반의 효율을 크게 개선할 수 있습니다.
특히 로그 분석과 같이 비정형 텍스트를 구조화된 데이터로 변환해야 하는 경우, Flink SQL의 강력한 문자열 처리 기능과 실시간 스트리밍 능력이 큰 도움이 됩니다.