
구글의 Open Lakehouse 혁신과 기업 데이터 전략에 미치는 영향
원문: Extending the Google Data Cloud lakehouse architecture (Google Cloud Blog, 2025)
구글이 AI 기반 Open Lakehouse 아키텍처의 대규모 업데이트를 발표했습니다. 이번 발표는 개방성, 통합성, 고성능을 핵심으로 하며, Apache Iceberg를 중심으로 한 진정한 멀티엔진 상호 운용성 구현에 중점을 두고 있습니다.
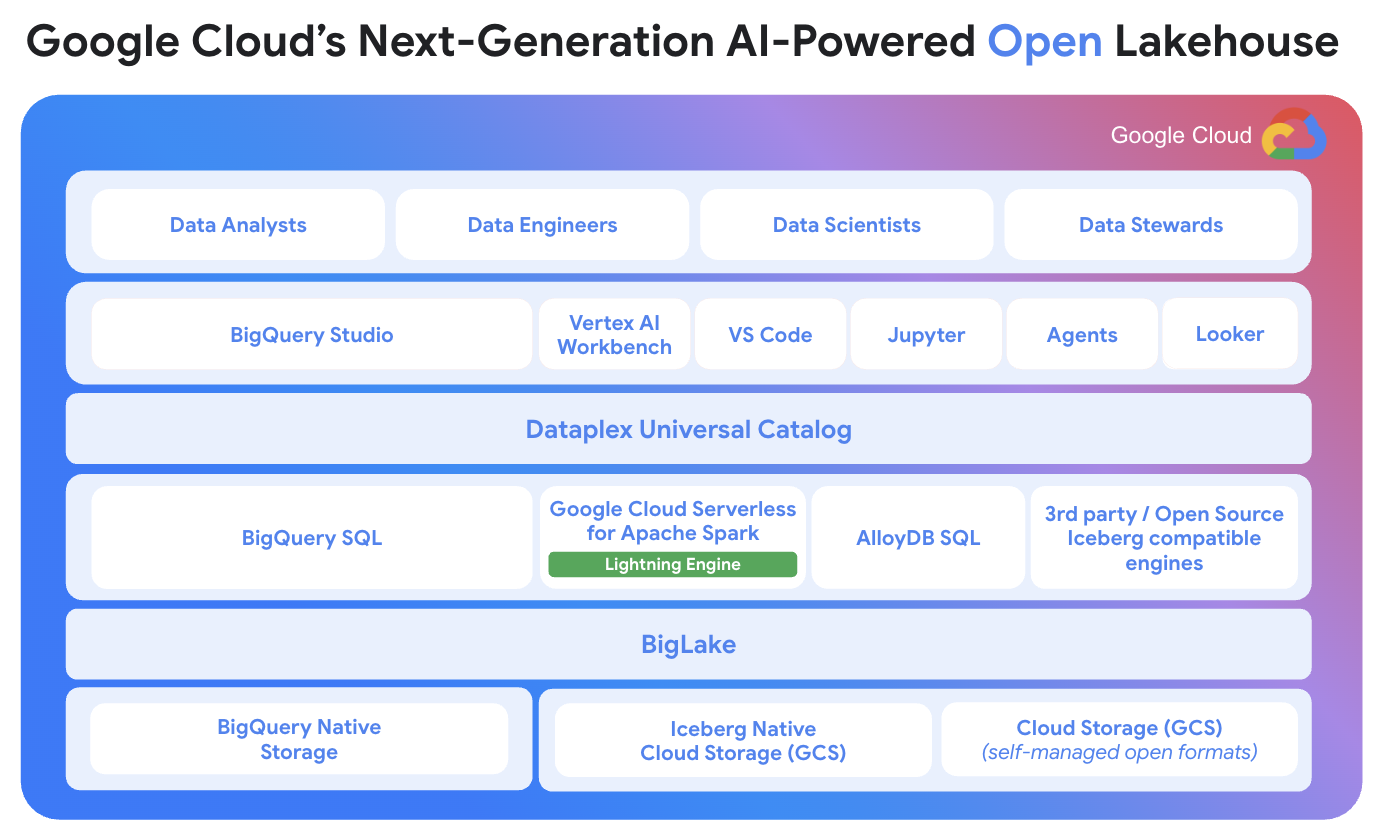
핵심 혁신 기술
BigLake Iceberg 네이티브 스토리지 Apache Iceberg 오픈 포맷을 완전 지원하는 엔터프라이즈급 스토리지로, 벤더 락-인 없는 데이터 관리와 Hadoop/Cloudera에서의 자동 마이그레이션을 지원합니다.
분석과 운영의 통합 BigQuery(분석)와 AlloyDB(운영) 모두 동일한 Iceberg 데이터를 처리할 수 있어, 복잡한 ETL 없이 실시간 분석과 운영이 가능합니다. Bayer는 이를 통해 50% 향상된 응답률과 5배 처리량 증가를 달성했습니다.
극적인 성능 향상
- BigQuery: 고급 런타임, 저지연 API, 세밀한 업데이트/삭제 작업 10배 가속화
- Apache Spark: Lightning Engine으로 TPC-H 벤치마크 3.6배 성능 향상
AI-Native 환경 Gemini 기반 Dataplex Universal Catalog로 데이터셋 식별 정확도 50% 향상, AI 지원 노트북과 IDE 통합으로 개발자 생산성 혁신(서버리스 Spark 노트북 사용량 4배 증가)
기업에게 주는 의미
주요 기회
- 데이터 자유도: 오픈 표준으로 벤더 락-인 해소, 툴 간 자유로운 전환
- 운영 효율성: 분석-운영 통합으로 데이터 복제 비용 대폭 절감
- AI 가속화: Gemini 통합으로 개발자 생산성과 인사이트 도출 속도 향상
고려사항
- Google Cloud 생태계 의존도 증가
- Apache Iceberg, Spark 등 오픈소스 기술 전문성 필요
- 레거시 시스템 통합과 마이그레이션 복잡성
국내 기업 관점: 현실적 제약사항
데이터 주권과 규제 환경 국내 금융, 의료, 공공 부문은 여전히 엄격한 제약이 있습니다. 금융권의 경우 금융감독원 클라우드 이용 가이드라인에 따른 복잡한 보고 절차와 CSP 안전성 평가가 필요하며, 개인정보보호법상 해외 이전 시 정보주체 동의와 ISO27018 등 추가 보안 요구사항을 충족해야 합니다.
맞춤화 한계 글로벌 표준화 서비스는 한국 기업의 복잡한 레거시 시스템, 고유한 비즈니스 프로세스, 업계별 특수 요구사항에 대한 깊은 맞춤화에 제약이 있을 수 있습니다.
파스업 DIP의 차별화 이런 맥락에서 파스업 DIP는 프라이빗 환경에서 구글 수준의 고도화된 분석 기능을 제공하는 대안적 접근을 제시합니다. 온프레미스나 프라이빗 클라우드에서 완전한 데이터 통제권을 유지하면서도, 국내 규제 환경에 특화된 컴플라이언스와 기업별 완전 맞춤화가 가능합니다.
결론
구글의 Open Lakehouse는 데이터 생태계가 개방성과 상호 운용성 중심으로 재편될 것임을 보여주는 중요한 이정표입니다. 글로벌 확장과 빠른 혁신이 중요한 기업에게는 매력적인 선택지가 될 것입니다.
반면 데이터 주권, 규제 준수, 세밀한 맞춤화가 핵심인 국내 기업들에게는 파스업 DIP와 같은 프라이빗 솔루션이 더 적합할 수 있습니다. 중요한 것은 각 기업의 우선순위와 제약 조건에 맞는 최적의 데이터 전략을 선택하는 것입니다.