
Lakekeeper를 활용한 레이크하우스 거버넌스 구현 가이드
Lakekeeper를 활용한 Apache Iceberg 기반 레이크하우스 거버넌스 구축 가이드입니다. OpenFGA 기반의 세밀한 권한 관리, 역할 기반 접근 제어 구현, Spark와 StarRocks 연동을 통한 실제 사례를 단계별로 소개합니다.

목차
개요
현대적인 레이크하우스 환경에서는 데이터의 보안과 접근 제어가 점점 더 중요해지고 있습니다. 특히 여러 팀과 다양한 분석 도구가 동일한 데이터 소스를 사용하는 경우, 중앙화된 메타데이터 관리와 세밀한 권한 제어가 필수적입니다.
이 블로그에서는 Lakekeeper라는 Iceberg REST Catalog를 활용하여 Apache Iceberg 기반 레이크하우스의 거버넌스 체계를 구축하는 방법을 소개합니다. Lakekeeper는 기존 Hive Metastore(HMS)를 대체하며, 다음과 같은 핵심 기능을 제공합니다:
- 중앙화된 메타데이터 관리: 모든 테이블과 데이터 구조를 한 곳에서 관리
- 세밀한 접근 제어: 프로젝트, 웨어하우스, 네임스페이스, 테이블 레벨의 권한 관리
- 멀티 엔진 호환성: Spark, StarRocks 등 다양한 쿼리 엔진과의 원활한 통합
- 데이터 리니지 추적: 데이터 변경 이력과 작업 추적
PAASUP DIP의 시스템 카탈로그인 Lakekeeper를 통해 실제 구현 사례를 단계별로 살펴보며, 역할 기반 접근 제어(Role-Based Access Control)를 구성하고 검증하는 전 과정을 다룹니다.
Lakekeeper Authorization 체계
Lakekeeper는 CNCF 프로젝트인 OpenFGA를 사용하여 권한을 저장하고 평가합니다. OpenFGA는 계층적 네임스페이스를 가진 현대적인 레이크하우스 환경에 최적화된 양방향 상속을 지원하는 강력한 권한 모델을 제공합니다.
Lakekeeper의 데이터 접근 관리를 효과적으로 활용하려면 먼저 권한 구조를 이해해야 합니다.
Entity별 권한 종류
| Entity | 사용 가능한 권한 |
|---|---|
| server | admin, operator |
| project | project_admin, security_admin, data_admin, role_creator, describe, select, create, modify |
| warehouse | ownership, pass_grants, manage_grants, describe, select, create, modify |
| namespace | ownership, pass_grants, manage_grants, describe, select, create, modify |
| table | ownership, pass_grants, manage_grants, describe, select, modify |
| view | ownership, pass_grants, manage_grants, describe, modify |
| role | assignee, ownership |
Entity 계층 구조
server > project > warehouse > namespace > table or view
주요 권한 설명
소유권 및 관리 권한:
-
ownership: 객체(Object)의 소유자는 해당 객체에 대한 모든 권한을 가집니다. 주체(Principal)가 새 객체를 생성하면 자동으로 소유자가 되며, 기본적으로 다른 사용자에게 권한을 부여할 수 있습니다.
-
server admin: 서버의
admin역할은 서버 내에서 가장 강력한 역할입니다. 감사 가능성(auditability)을 보장하기 위해 모든 프로젝트를 나열하고 관리할 수 있지만, 프로젝트 내 데이터에는 직접 접근할 수 없습니다. 데이터 접근이 필요한 경우 자신에게project_admin역할을 할당해야 합니다.admin은 모든 프로젝트, 서버 설정 및 사용자를 관리할 수 있습니다. -
project_admin: 프로젝트 내에서
security_admin과data_admin의 책임을 모두 포함합니다. 권한 및 소유권 관리를 포함한 모든 보안 관련 측면과 객체의 생성, 수정, 삭제를 포함한 모든 데이터 관련 작업을 수행할 수 있습니다. -
data_admin: 프로젝트 내 객체의 생성, 수정, 삭제 등 모든 데이터 관련 작업을 관리할 수 있지만, 권한 부여나 소유권 관리는 할 수 없습니다.
데이터 접근 권한:
-
describe: 객체를 수정하지 않고 메타데이터와 세부 정보를 조회할 수 있습니다.
-
select: 테이블이나 뷰에서 데이터를 읽을 수 있습니다. 쿼리 및 데이터 검색이 포함됩니다.
-
create: 엔티티 내에 테이블, 뷰, 네임스페이스와 같은 새로운 객체를 생성할 수 있습니다.
create권한은 암시적으로describe권한을 포함합니다. -
modify: 테이블의 데이터 업데이트나 뷰 변경 등 객체의 콘텐츠나 속성을 변경할 수 있습니다.
modify권한은 암시적으로select와describe권한을 포함합니다.
권한 관리:
-
pass_grants: 자신의 권한을 다른 사용자에게 전달할 수 있습니다.
-
manage_grants: 권한 생성, 수정, 취소를 포함하여 객체에 대한 모든 권한을 관리할 수 있습니다.
manage_grants와pass_grants권한도 포함됩니다.
상속(Inheritance)
Lakekeeper의 권한 체계는 양방향 상속을 지원합니다:
하향식 상속 (Top-Down Inheritance):
상위 엔티티의 권한은 자식 엔티티로 상속됩니다. 예를 들어, 주체(principal)에게 웨어하우스에 대한 modify 권한이 부여되면 중첩된 네임스페이스를 포함하여 그 안의 모든 네임스페이스, 테이블, 뷰를 수정할 수 있습니다.
상향식 상속 (Bottom-Up Inheritance):
테이블과 같은 하위 엔티티에 대한 권한은 모든 상위 계층에 기본적인 탐색 권한을 상속합니다. 예를 들어, 사용자가 ns1.ns2.table_1 테이블에 대한 select 권한을 부여받으면 자동으로 ns1과 ns2에 대한 제한적인 목록 조회(list) 권한을 얻습니다. 사용자에게는 직접적인 경로에 있는 항목만 표시되므로, ns1.ns3이 존재하더라도 ns1에서 목록을 조회하면 ns1.ns2만 표시됩니다.
Lakekeeper UI를 통한 권한 부여
PAASUP DIP를 설치하면 시스템 카탈로그인 Lakekeeper가 자동으로 설치되며, 다음 두 개의 기본 사용자가 생성됩니다:
- service-account-lakekeeper-admin: server admin 권한을 가진 application user
- dataup: server admin 권한을 가진 human user이자 전사 데이터 거버넌스 관리자로, Lakekeeper UI에 최초 로그인할 수 있는 권한을 보유합니다.
Lakekeeper UI 접속
프로젝트 카탈로그 메뉴에서 Lakekeeper Link를 클릭하면 Lakekeeper UI 창이 열립니다.
dataup으로 로그인합니다.
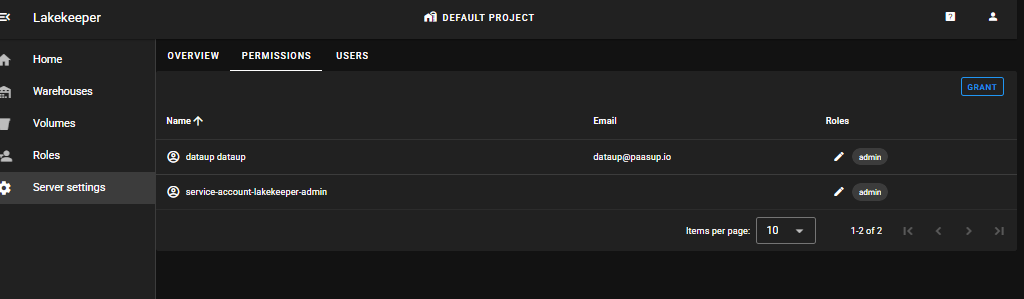
Server 설정 확인
Server settings > PERMISSIONS
2개의 admin user(application user 1, human user 1)를 확인할 수 있습니다.
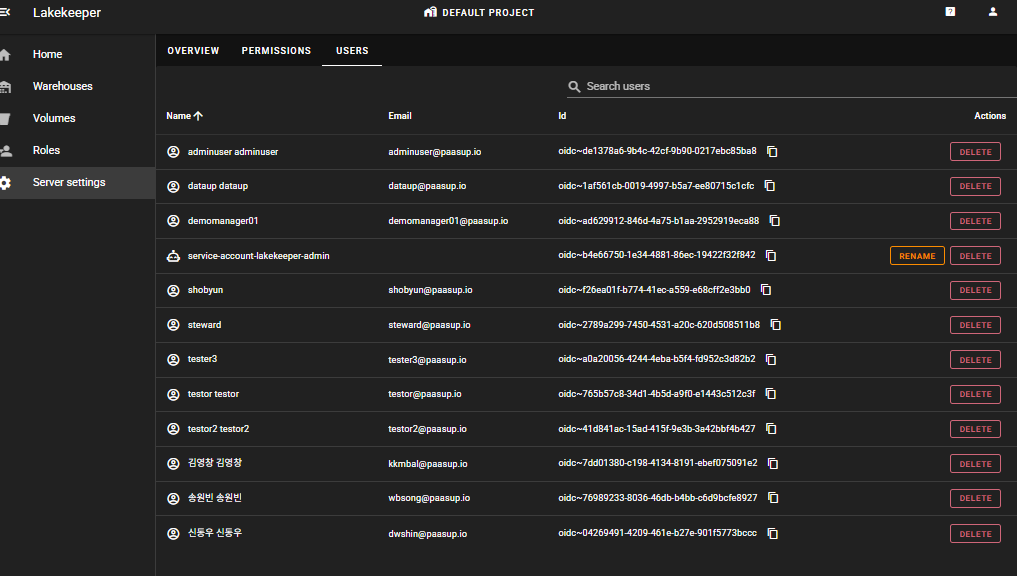
Server settings > USERS
server admin 권한을 가진 user만 USERS 탭을 볼 수 있으며, keycloak과 연동된 사용자 목록을 확인할 수 있습니다.
프로젝트 생성 및 권한 부여
DEFAULT PROJECT는 기본으로 생성되어 있는 프로젝트이며, 상단의 DEFAULT PROJECT를 클릭하여 필요 시 새로운 프로젝트를 생성할 수 있습니다. 이 예제에서는 DEFAULT PROJECT를 사용하겠습니다.
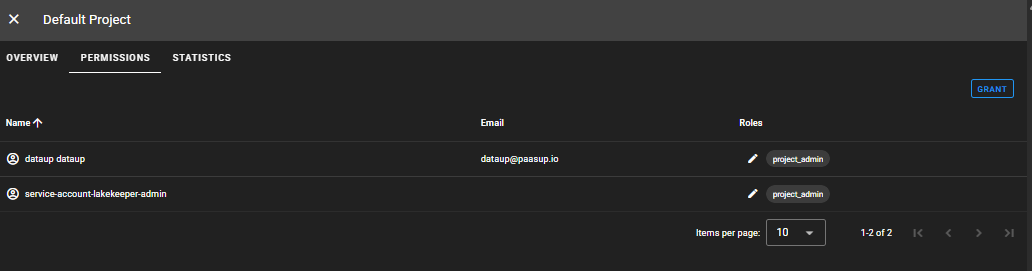
DEFAULT Project > PERMISSIONS > GRANT
dataup user도 프로젝트 내의 데이터에 접근하려면 자신에게 권한을 부여해야 합니다.
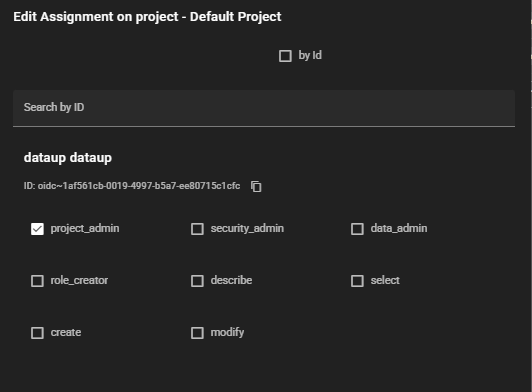
Warehouse 생성
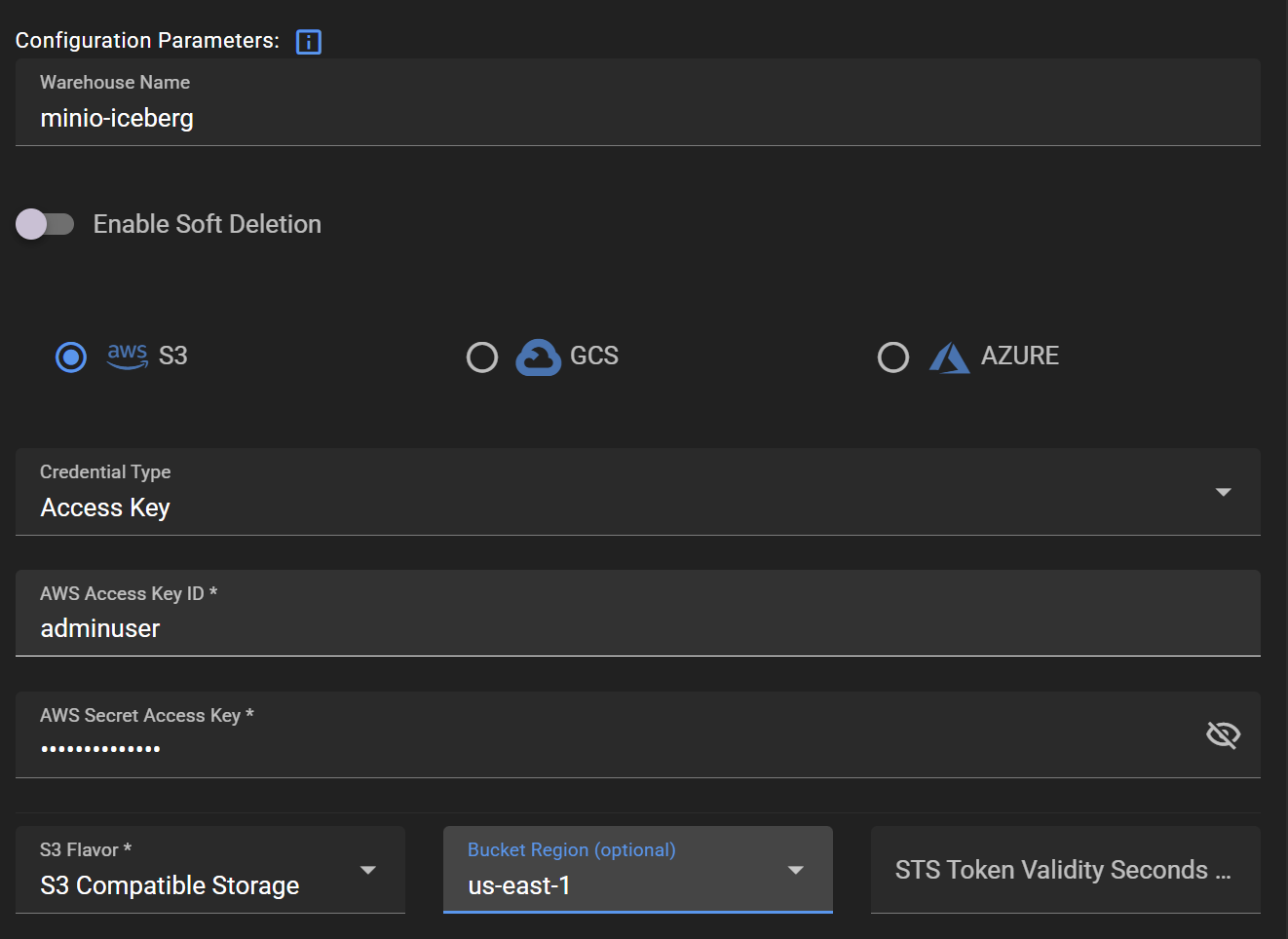
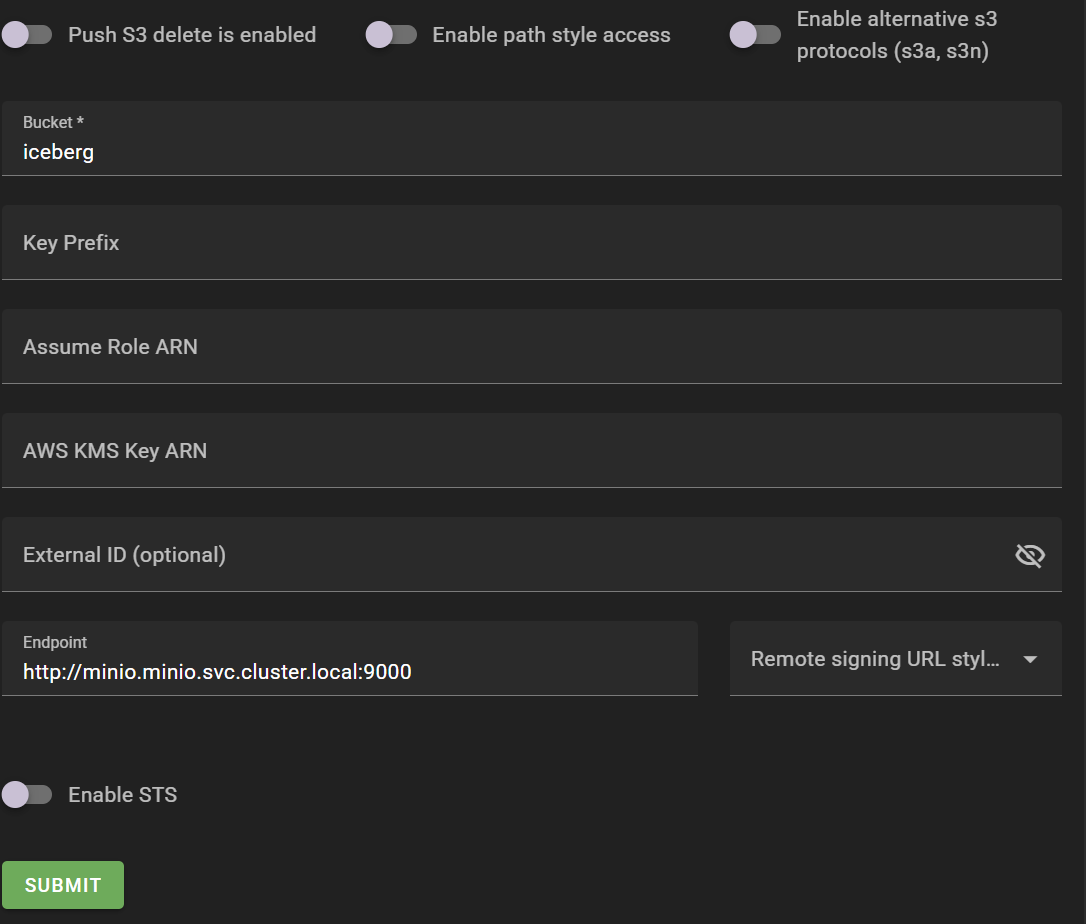
프로젝트 하위 그룹으로 실제 데이터 저장소인 warehouse를 생성합니다. warehouse를 생성하려면 저장소 접근을 위한 Credentials 정보, bucket region, bucket 이름, endpoint 등을 입력해야 합니다.
Warehouses > ADD WAREHOUSE
ROLE 생성 및 USER 할당
Grants의 대상은 User(인증된 개별 주체) 또는 Role(사용자가 할당받는 권한 집합)입니다. User에게 직접 권한을 부여하는 방법도 가능하지만, 이 예제에서는 Role을 이용한 권한 부여 방법을 다루겠습니다.
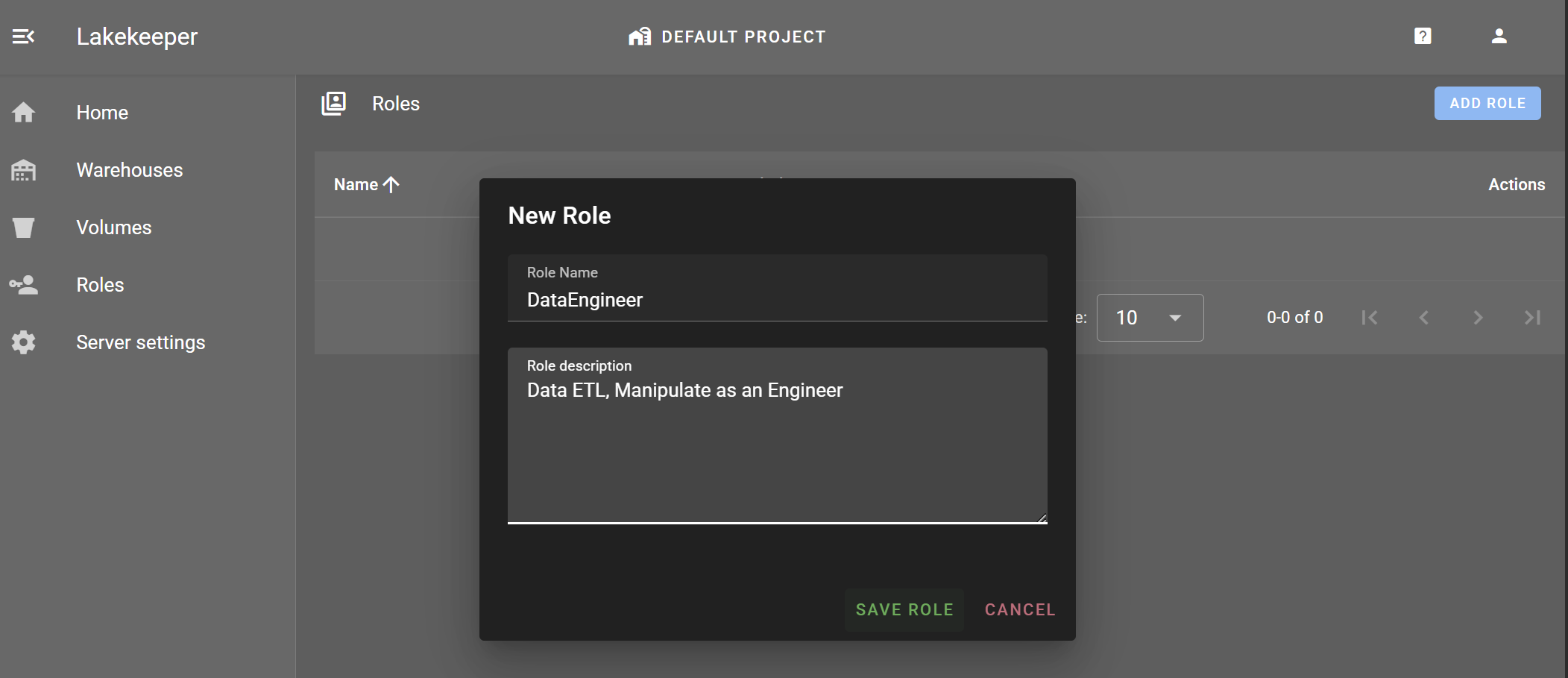
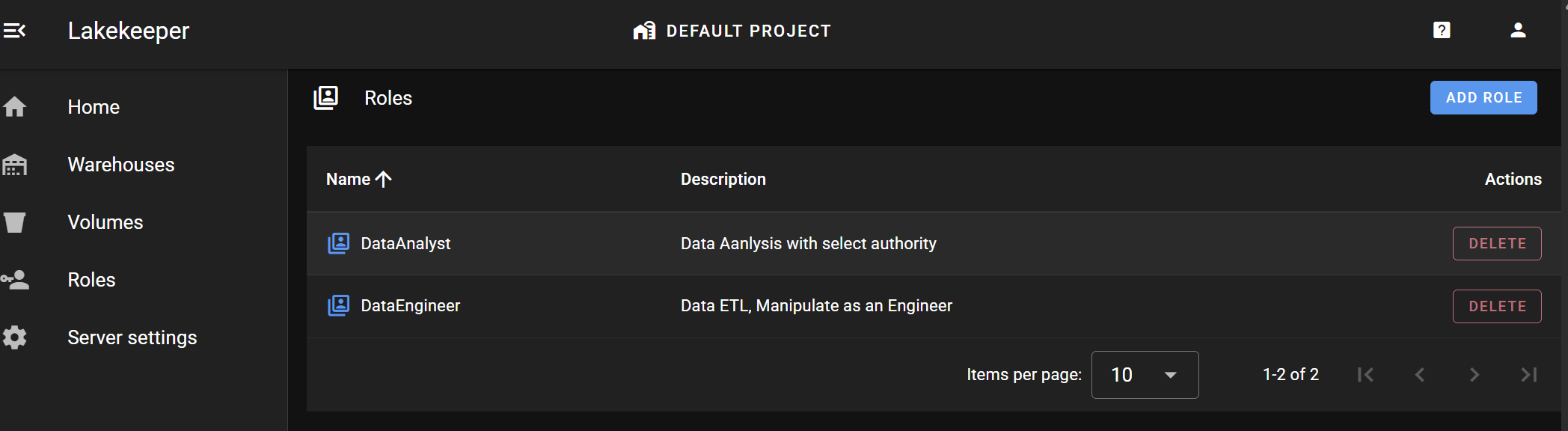
Roles > ADD ROLE
DataEngineer와 DataAnalyst Role을 생성합니다.
Roles > [role_name] > PERMISSIONS > GRANT
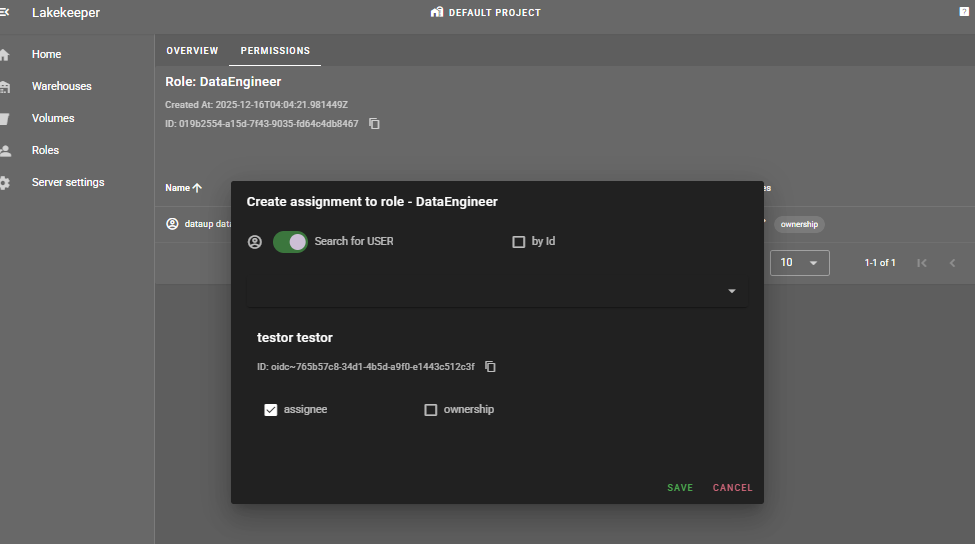
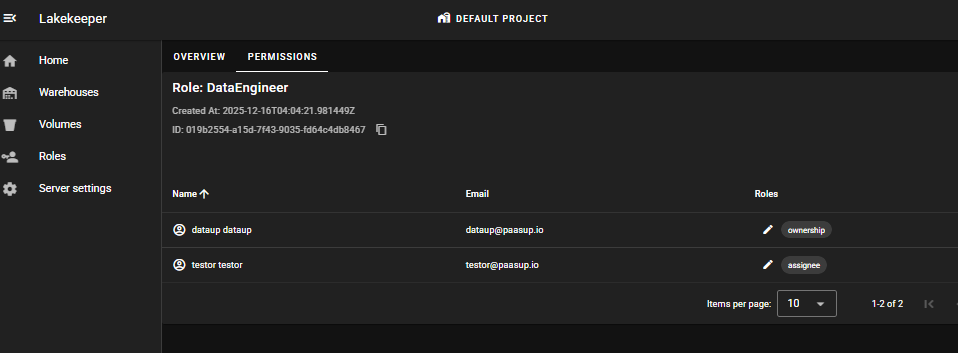
DataEngineer role은 testor user에게 할당하고, DataAnalyst role은 testor2 user에게 할당합니다.
ROLE에 Entity 접근 권한 부여
Entity 계층에 따라 데이터 접근 권한은 Project, Warehouse, Namespace, Table 레벨까지 부여할 수 있습니다. 이 예제에서는 위에서 생성한 minio-iceberg warehouse 레벨에서 DataAnalyst Role에는 select 권한을, DataEngineer Role에는 create와 modify 권한을 부여하겠습니다.
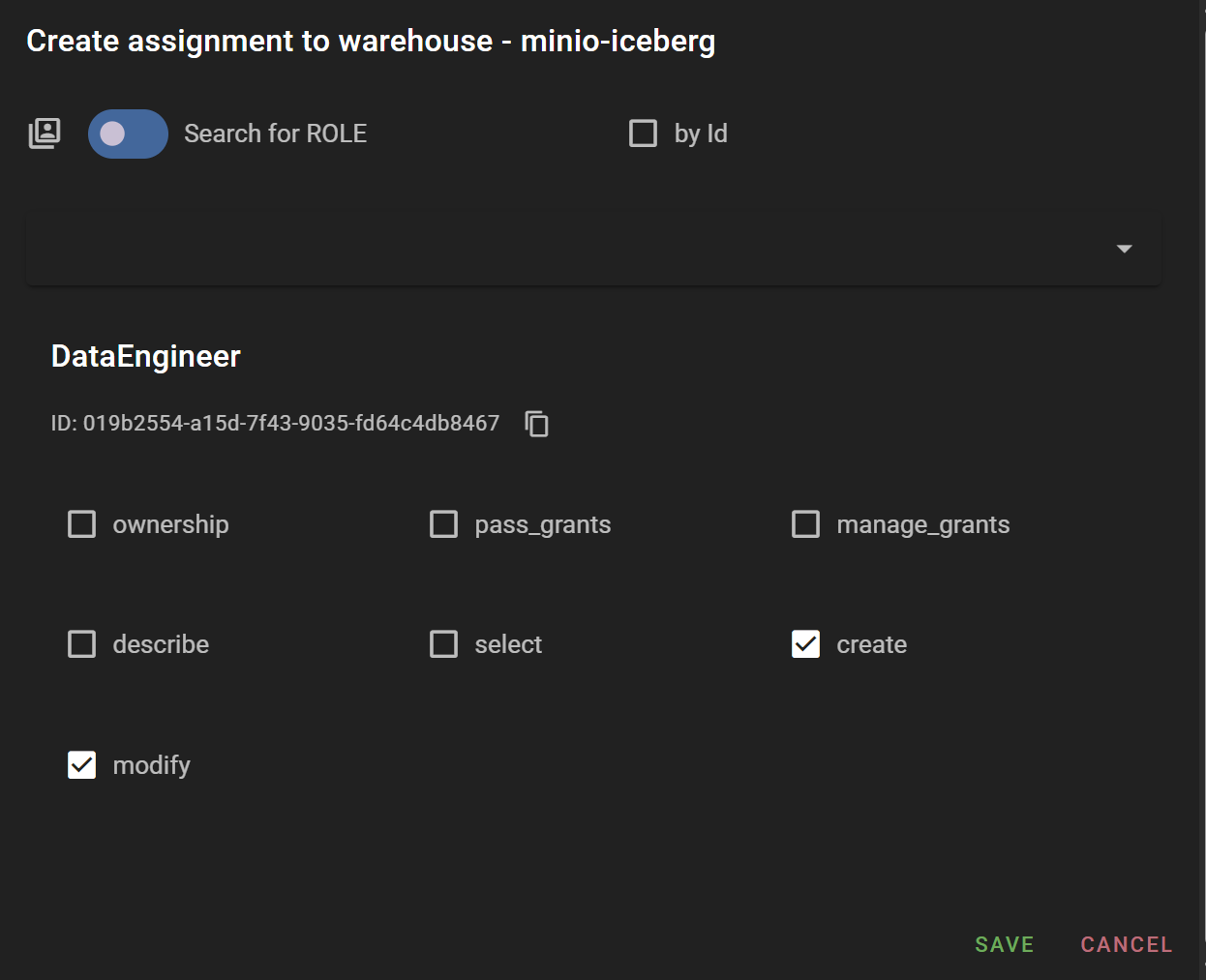
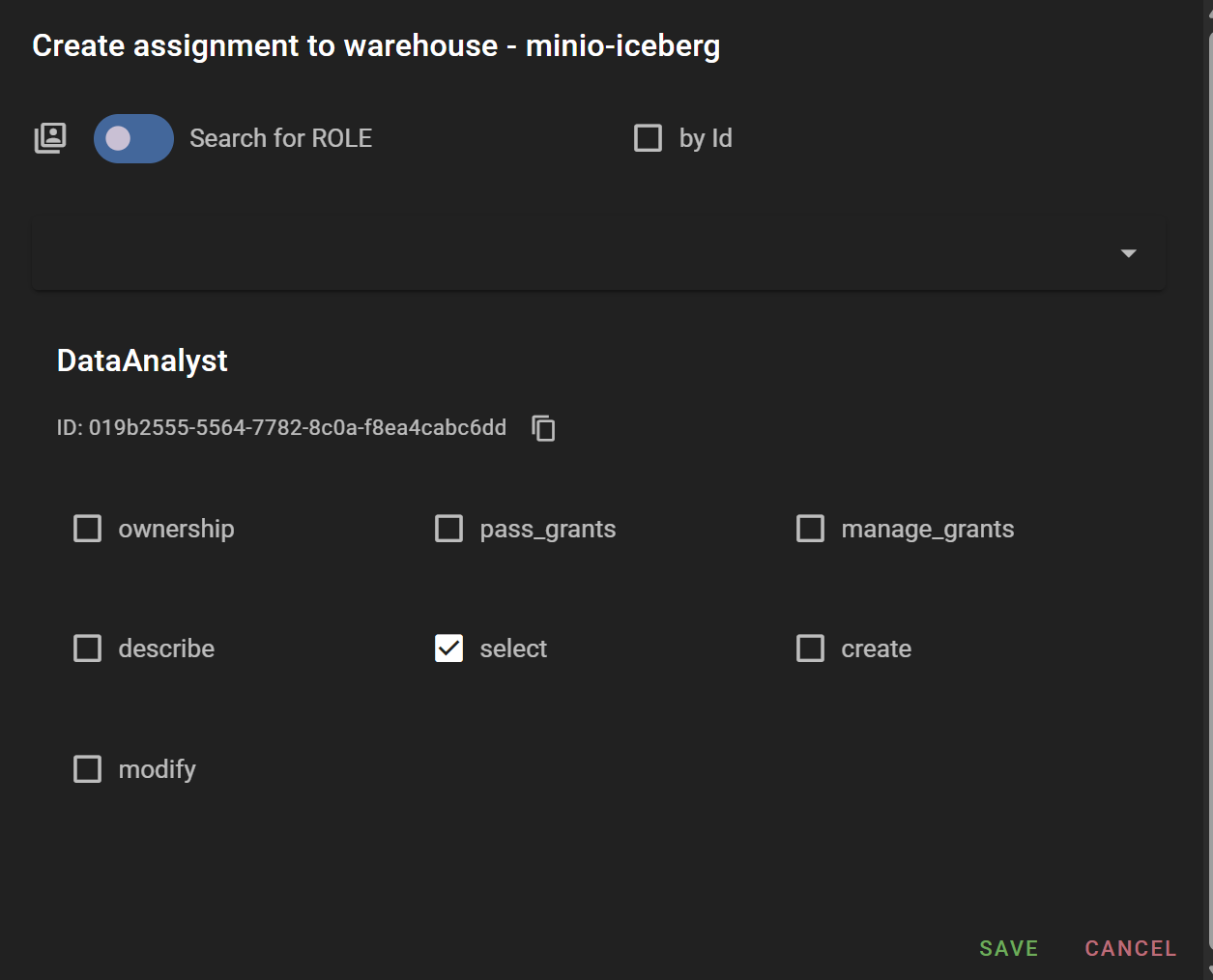
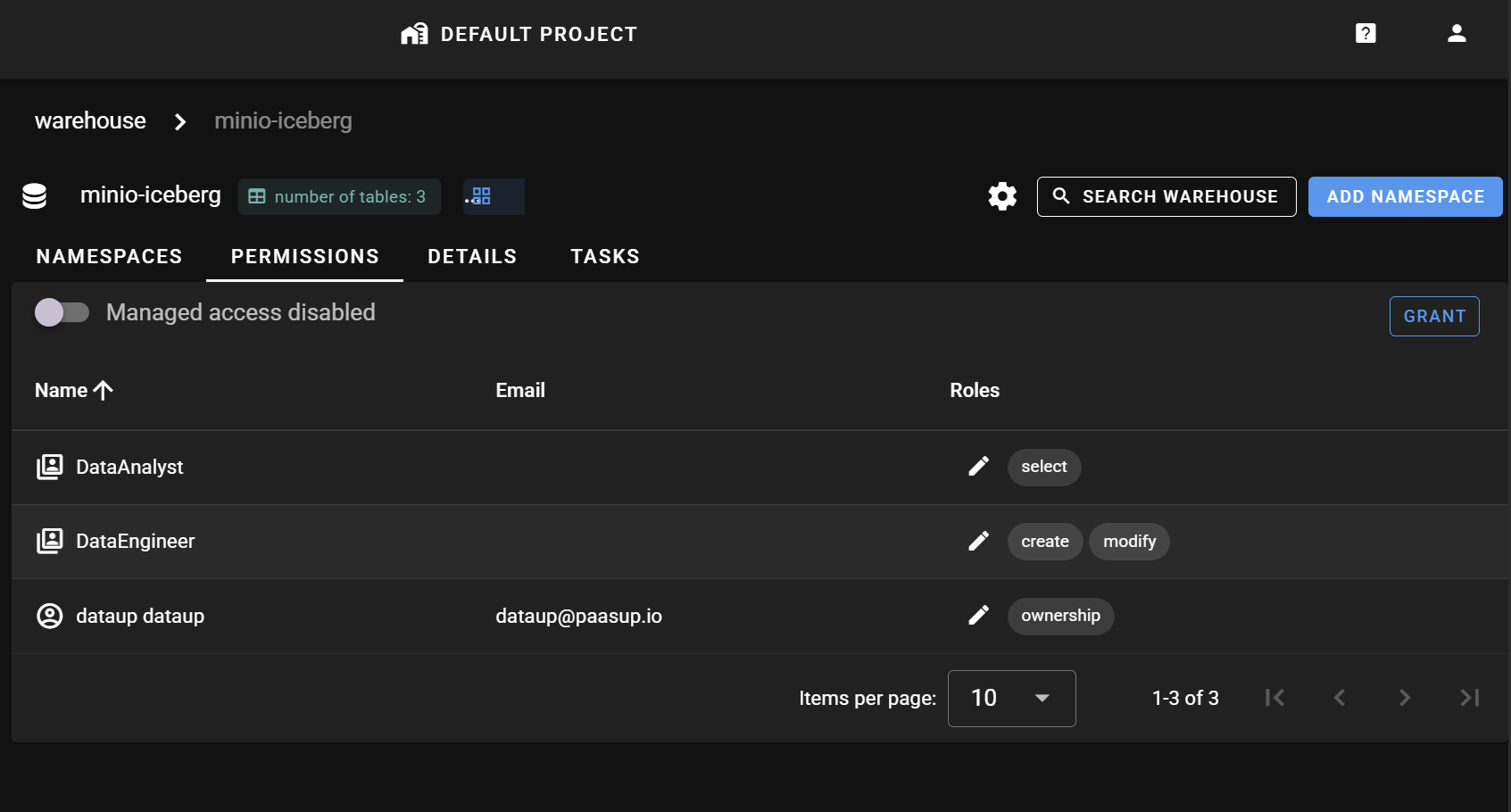
지금까지의 권한 부여 요약
- DataEngineer (Role): testor user에게 할당, minio-iceberg (warehouse) entity에 대한
create,modify권한 부여 - DataAnalyst (Role): testor2 user에게 할당, minio-iceberg (warehouse) entity에 대한
select권한 부여
권한 부여 검증
Lakekeeper를 통해 부여된 데이터 접근 권한 체계를 실제 Jupyter Notebook 환경에서 Spark batch를 통해 검증하겠습니다. 검증에 사용할 데이터셋은 WHO의 COVID-19 통계 데이터(WHO-COVID-19-global-daily-data.csv)입니다.
Spark Session 설정
Lakekeeper catalog를 통해 Iceberg에 접근하는 Spark session을 생성합니다. Spark session 생성 방법에는 두 가지가 있습니다:
- 임시 토큰으로 Lakekeeper catalog에 접속
- Keycloak의 client ID로 Lakekeeper catalog에 접속
이 예제에서는 human user(Keycloak의 client로 등록되어 있지 않음)에게 부여된 권한을 검증해야 하므로 임시 토큰 방식을 사용합니다.
testor user 권한 검증
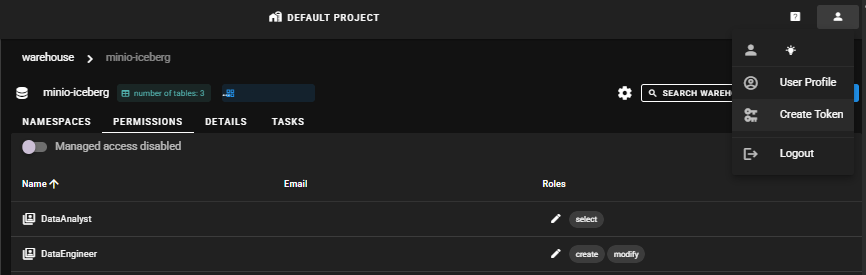
Lakekeeper 임시 토큰 발급
testor user로 Lakekeeper UI에 접속하여 우측 상단 프로필 > Create token을 클릭하면 임시 토큰이 clipboard에 저장됩니다.
Spark Session 생성
발급받은 임시 토큰 값을 입력하여 Spark session을 생성합니다. catalog_name은 'demo'로 설정했습니다.
from pyspark import SparkConf, SparkContext
from pyspark.sql import SparkSession
from pyspark.sql.functions import col, lit
import pyspark
import os
def define_conf_token(conf:SparkConf, notebook_name, notebook_namespace, token, CATALOG_URL, WAREHOUSE):
pyspark_version = pyspark.__version__
pyspark_version = ".".join(pyspark_version.split(".")[:2]) # Strip patch version
iceberg_version = "1.6.1"
jar_list = ",".join([
"org.apache.hadoop:hadoop-common:3.3.4",
"org.apache.hadoop:hadoop-aws:3.3.4",
"com.amazonaws:aws-java-sdk:1.11.655",
f"org.apache.iceberg:iceberg-spark-runtime-{pyspark_version}_2.12:{iceberg_version},"
f"org.apache.iceberg:iceberg-aws-bundle:{iceberg_version},"
f"org.apache.iceberg:iceberg-azure-bundle:{iceberg_version},"
f"org.apache.iceberg:iceberg-gcp-bundle:{iceberg_version}"
])
# jar 패키지 설정
conf.set("spark.jars.packages", jar_list)
# SparkSessionCatalog (spark_catalog 대체)
conf.set("spark.sql.catalog.spark_catalog", "org.apache.iceberg.spark.SparkSessionCatalog")
conf.set("spark.sql.catalog.spark_catalog.type", "hive") # 또는 in-memory, 필요에 따라 설정
conf.set("spark.sql.extensions", "org.apache.iceberg.spark.extensions.IcebergSparkSessionExtensions")
# RESTCatalog (Lakekeeper REST API 연결용)
catalog_name = "demo"
conf.set(f"spark.sql.catalog.{catalog_name}", "org.apache.iceberg.spark.SparkCatalog")
conf.set(f"spark.sql.catalog.{catalog_name}.catalog-impl", "org.apache.iceberg.rest.RESTCatalog")
conf.set(f"spark.sql.catalog.{catalog_name}.uri", CATALOG_URL)
conf.set(f"spark.sql.catalog.{catalog_name}.token", token)
conf.set(f"spark.sql.catalog.{catalog_name}.warehouse", WAREHOUSE)
notebook_name = "demo01"
notebook_namespace = "demo01-kubeflow"
CATALOG_URL = "[YOUR_CATALOG_URL]" # lakekeeper의 catalog api URL
WAREHOUSE = "minio-iceberg"
# 토큰 발행은 lakekeeper UI 우측 상단 프로필 > create token 클릭 : token은 24시간만 유지
# testor : DataEngineer
lakekeeper_token = "[TESTOR_TOKEN_HERE]"
conf = SparkConf()
define_conf_token(
conf=conf,
notebook_name = notebook_name,
notebook_namespace = notebook_namespace,
token = lakekeeper_token,
CATALOG_URL=CATALOG_URL,
WAREHOUSE=WAREHOUSE
)
appname = 'ingest_covid_daily'
spark = SparkSession.builder.config(conf=conf)\
.appName(appname)\
.master("local")\
.getOrCreate()
Namespace 생성 테스트
DataEngineer Role은 minio-iceberg에 대한 create 권한을 가지고 있기 때문에 testor user의 임시 토큰으로 minio-iceberg 하위의 namespace를 생성할 수 있습니다.

Table 생성 및 데이터 조작 테스트
DataEngineer Role은 minio-iceberg에 대한 create, modify 권한을 가지고 있기 때문에 testor user의 임시 토큰으로 minio-iceberg 하위의 table을 생성하고 데이터를 insert할 수 있습니다.
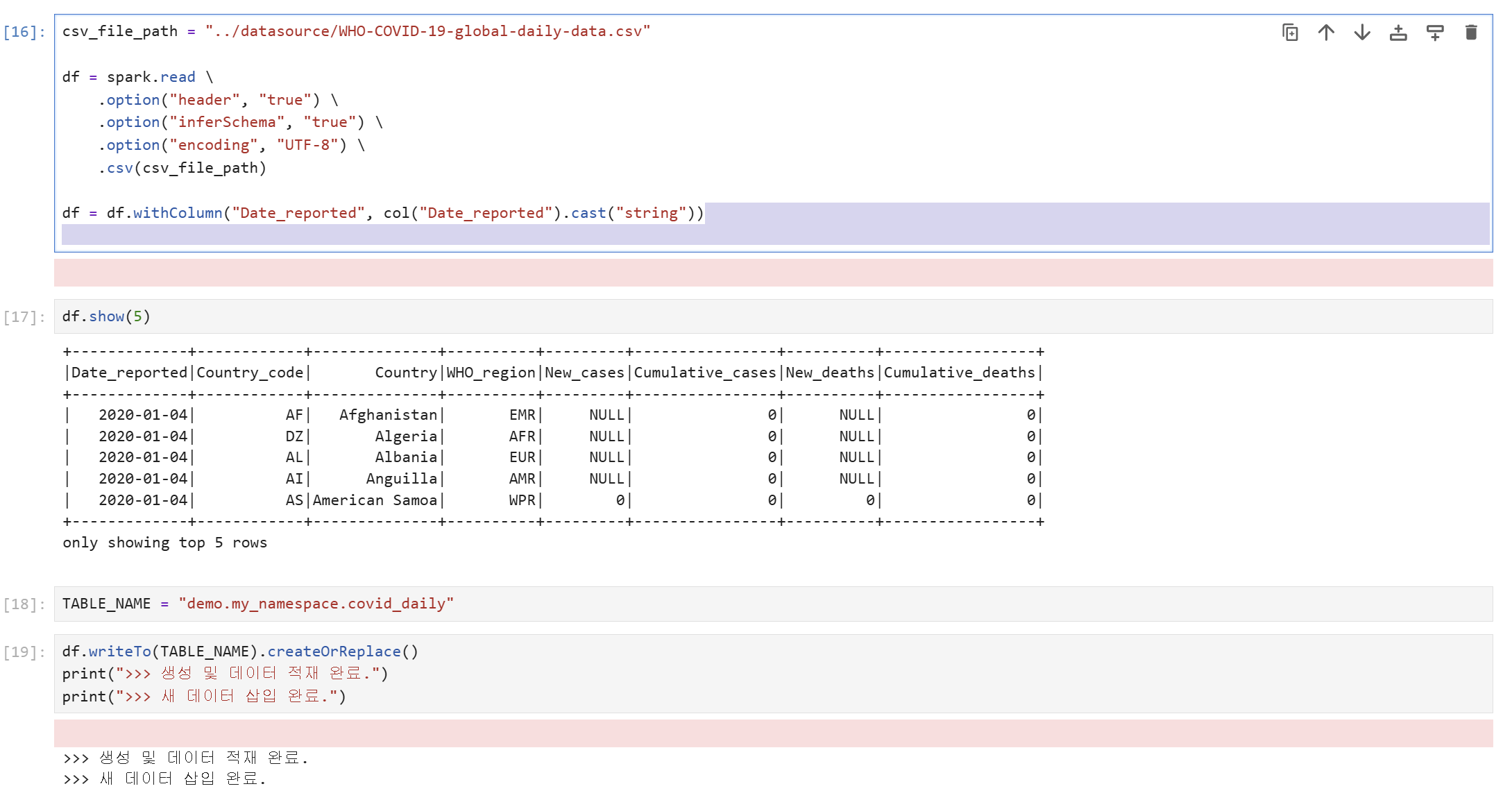
Table Select 테스트
DataEngineer Role은 minio-iceberg에 대한 modify 권한을 가지고 있으며, modify 권한은 암시적으로 select와 describe 권한을 포함하기 때문에 testor user의 임시 토큰으로 minio-iceberg 하위의 table을 조회할 수 있습니다.
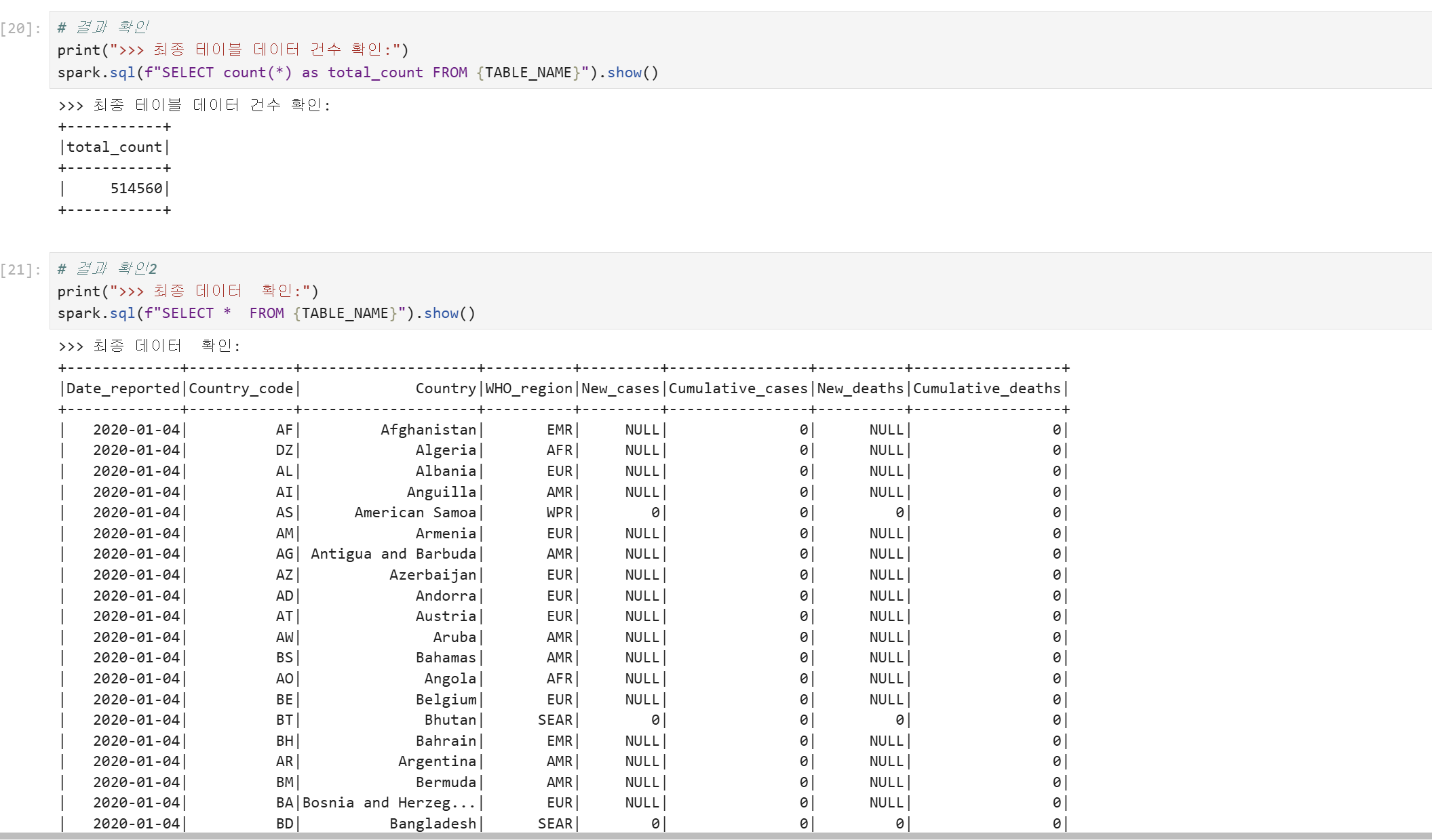
testor2 user 권한 검증
Spark Session 생성
testor2의 임시 토큰 값을 입력하여 Spark session을 생성합니다.
...
# testor2 : DataAnalyst
lakekeeper_token = "[TESTOR2_TOKEN_HERE]"
...
appname = 'ingest_covid_daily'
spark = SparkSession.builder.config(conf=conf)\
.appName(appname)\
.master("local")\
.getOrCreate()
Table 생성 및 데이터 조작 테스트
DataAnalyst Role은 minio-iceberg에 대한 select 권한만 가지고 있기 때문에 testor2 user의 임시 토큰으로 minio-iceberg 하위의 table을 생성하거나 데이터를 insert할 수 없습니다.
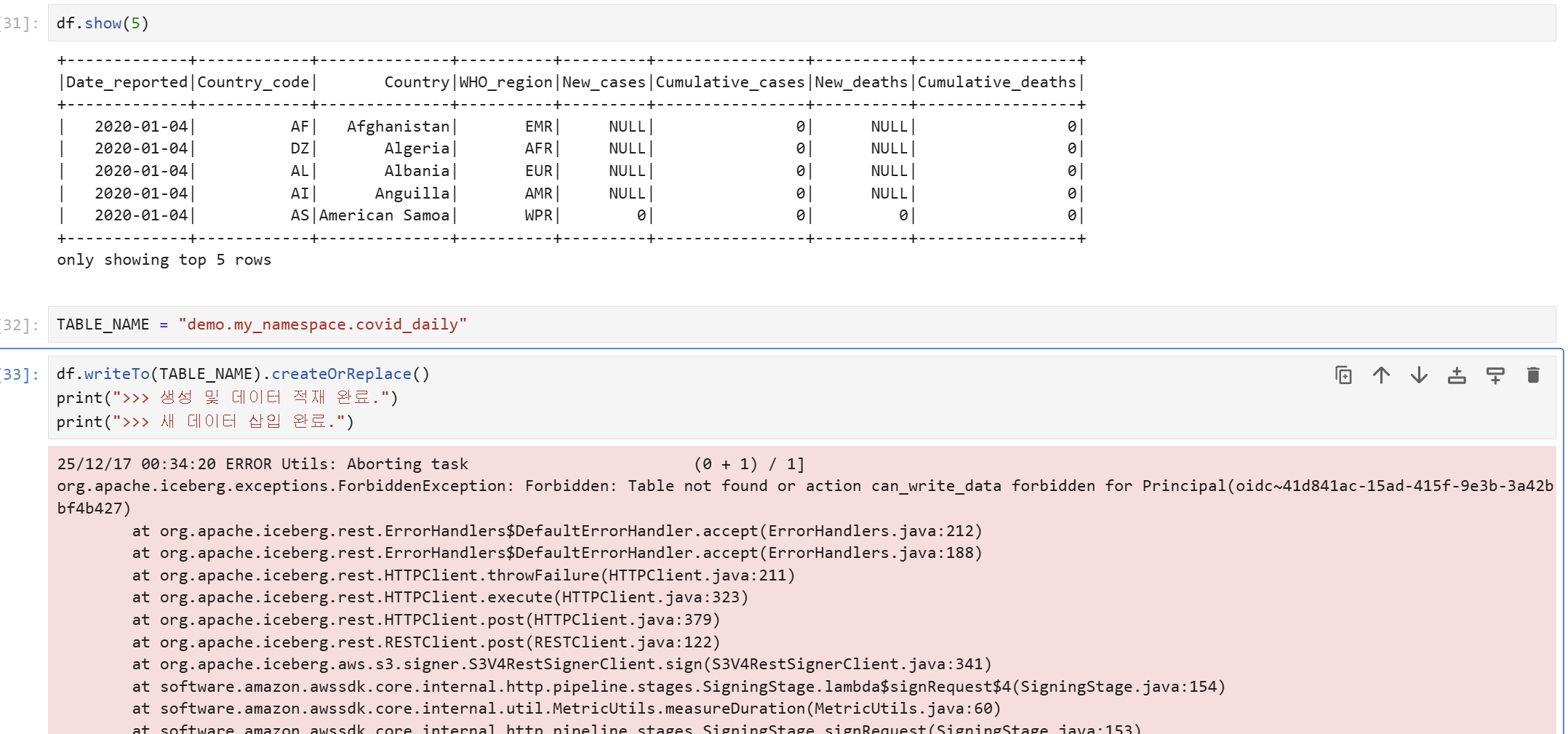
Table Select 테스트
그러나 DataAnalyst Role은 minio-iceberg에 대한 select 권한을 가지고 있기 때문에 testor2 user의 임시 토큰으로 minio-iceberg 하위의 table을 조회할 수 있습니다.
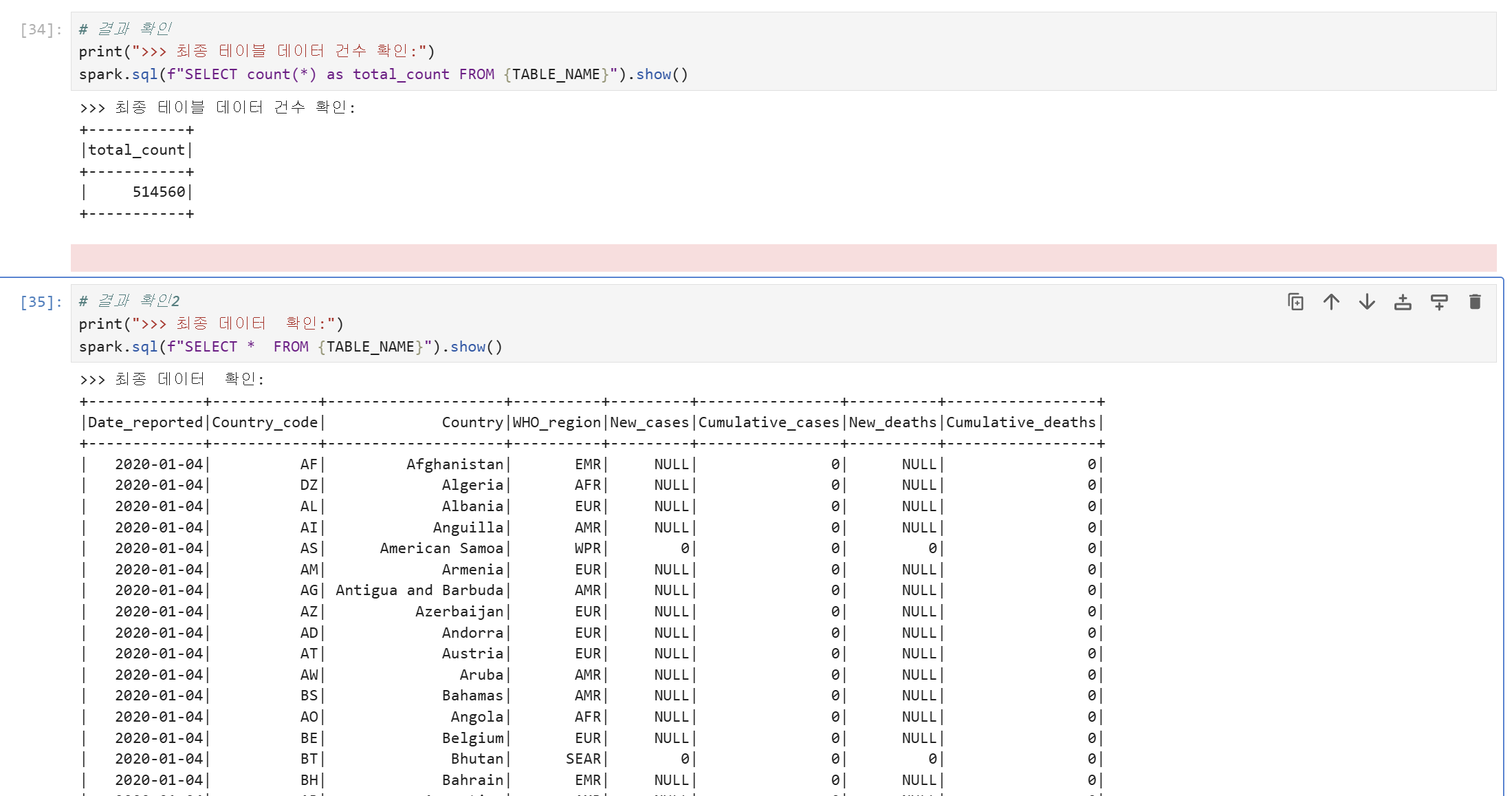
Lakekeeper UI에서 Table 정보 확인
Lakekeeper UI에서 Table에 대한 다양한 정보를 확인할 수 있습니다.
Project > Warehouses > NAMESPACES
Table 목록을 확인할 수 있습니다.
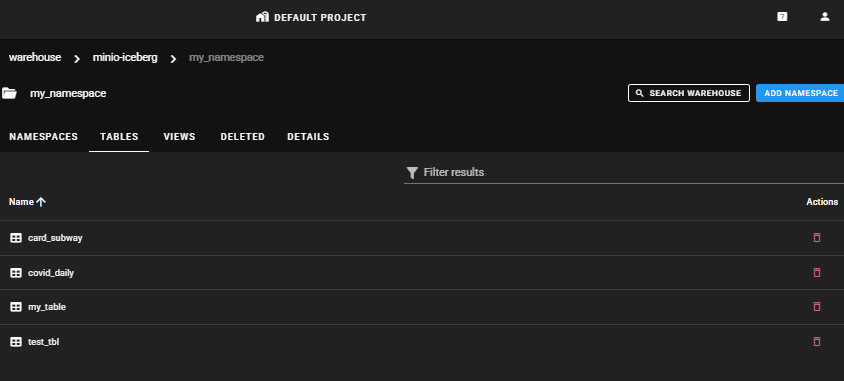
Project > Warehouses > NAMESPACES > TABLES
Table명을 클릭하면 OVERVIEW, RAW, BRANCH, TASK 탭에서 스키마 정보와 작업 히스토리 정보를 확인할 수 있습니다.
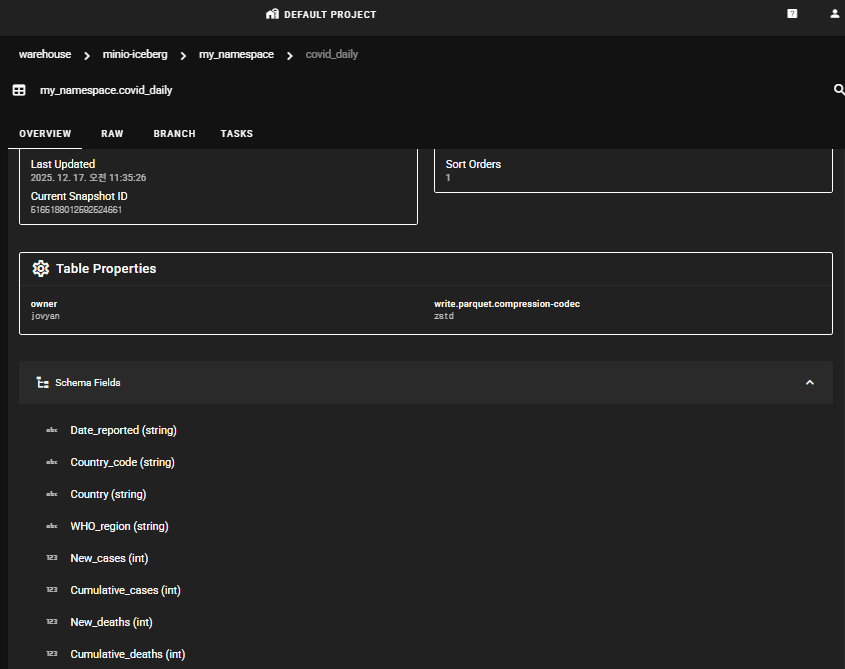
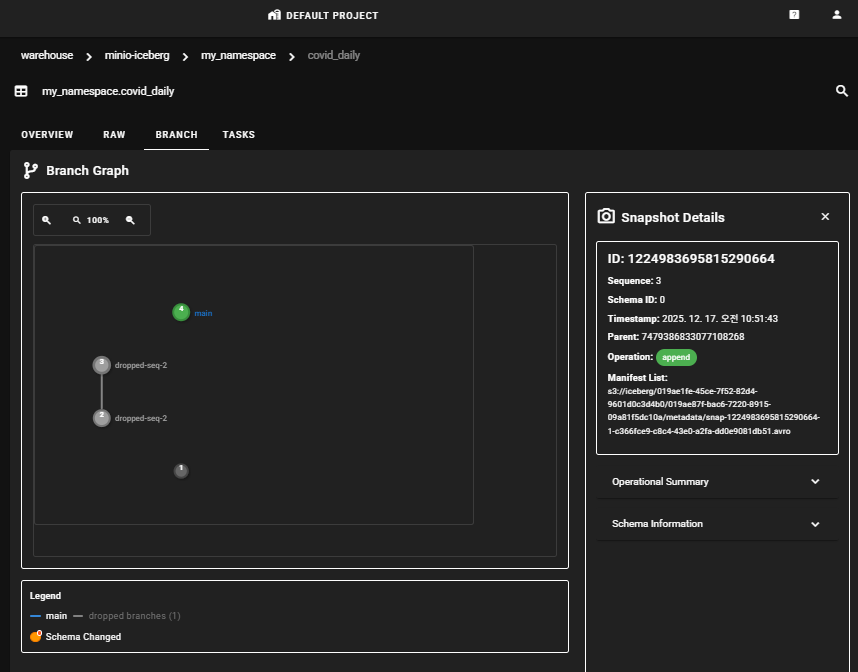
데이터 시각화를 위한 StarRocks 연결
Lakekeeper와 같은 IRC(Iceberg REST Catalog)를 통해 StarRocks DB의 external catalog를 생성하여 StarRocks Client(MySQL client 사용)에서 직접 Iceberg 레이크하우스의 데이터를 쿼리할 수 있습니다.
Iceberg External Catalog 생성
IRC를 통해 Iceberg External Catalog를 생성할 때, Lakekeeper 접속을 위한 credentials는 Keycloak의 client로 등록되어 있는 application user여야 합니다. Human user는 임시 토큰으로 접근해야 하므로 External Catalog 선언문에 적합하지 않습니다.
CREATE EXTERNAL CATALOG lakekeeper_catalog
PROPERTIES (
"type" = "iceberg",
"iceberg.catalog.type" = "rest",
"iceberg.catalog.security" = "oauth2",
-- LakeKeeper Credentials
"iceberg.catalog.uri" = "[LAKEKEEPER_CATALOG_URI]",
"iceberg.catalog.oauth2.server-uri" = "[KEYCLOAK_SERVER_URI]",
"iceberg.catalog.warehouse" = "minio-iceberg",
"iceberg.catalog.oauth2.credential" = "[KEYCLOAK_CLIENT_ID]:[CLIENT_PASSWORD]",
"iceberg.catalog.oauth2.scope" = "lakekeeper",
"aws.s3.region" = "us-east-1",
"aws.s3.enable_path_style_access" = "true" -- S3 호환 스토리지 사용 시 true
);
Query 테스트
External Catalog를 이용하여 SQL Client에서 Query 테스트를 수행할 수 있습니다.
SHOW DATABASES
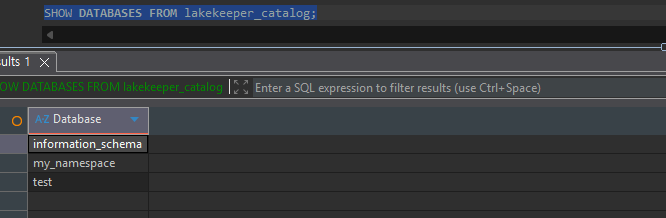
Table Description
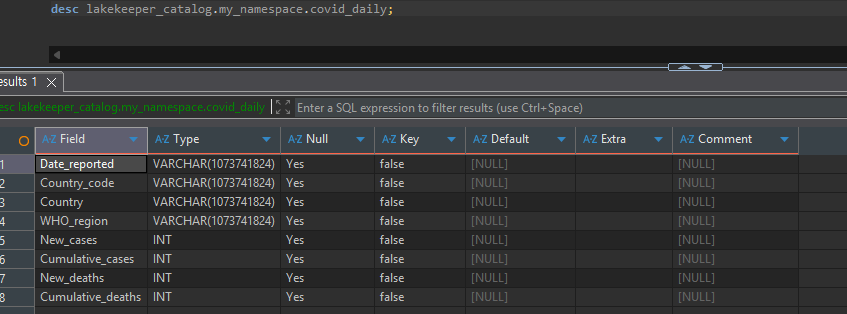
Table Create
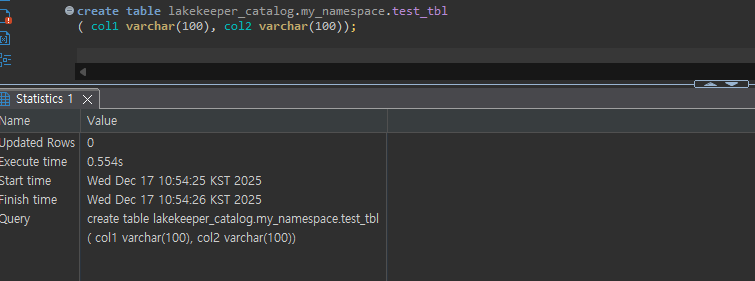
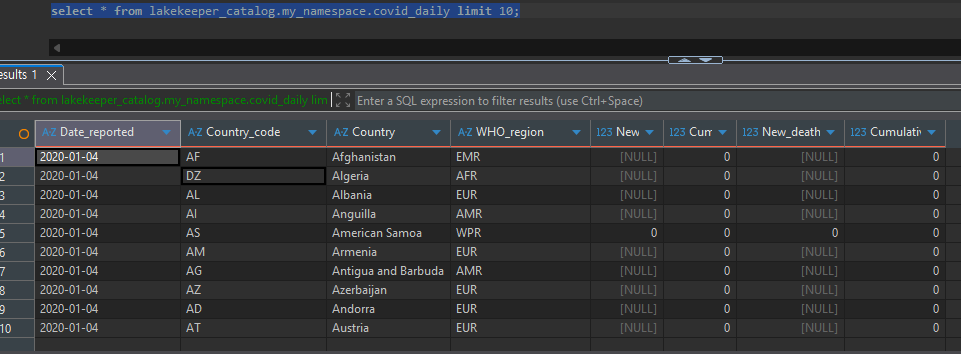
Data Manipulation
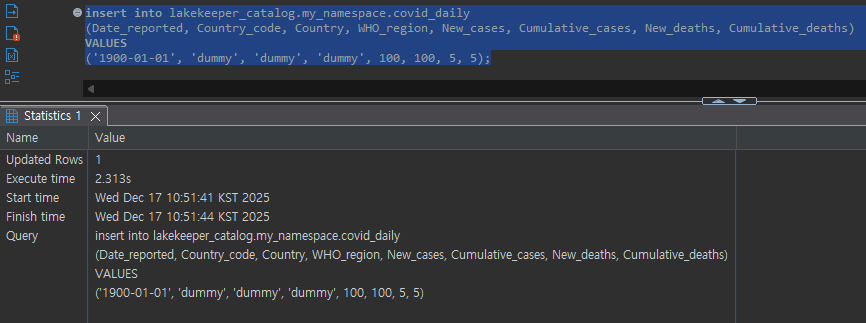
Data Select:
Data Insert:
데이터 시각화 by Apache Superset
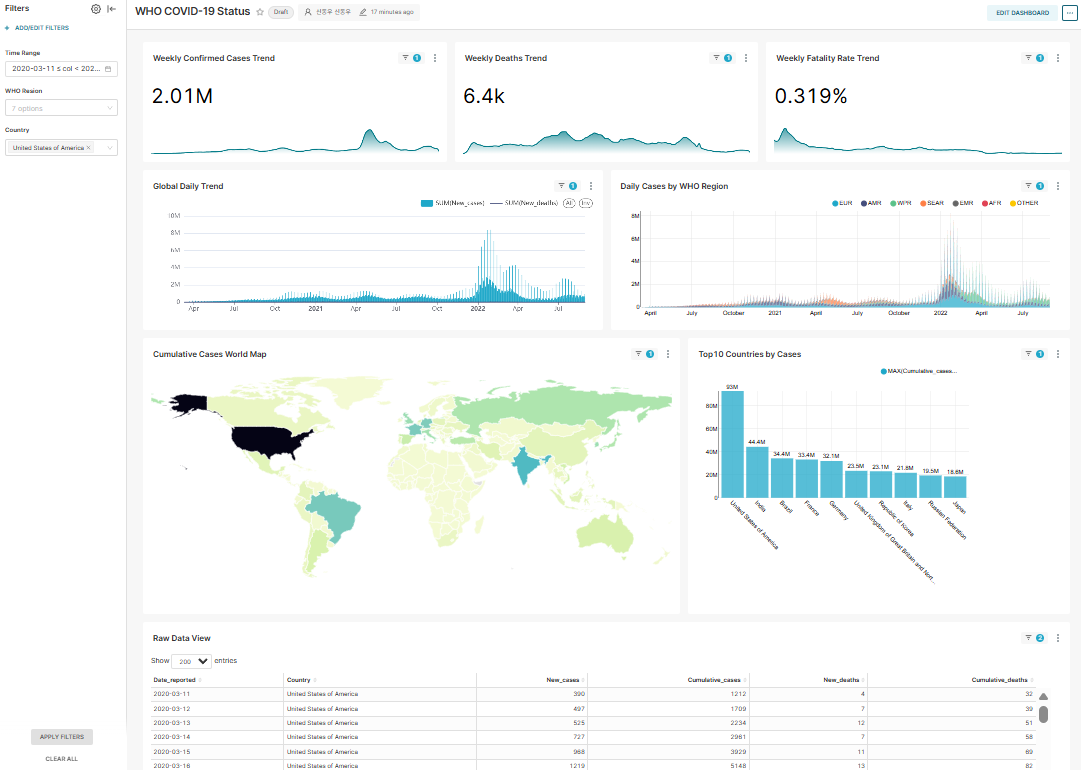
대시보드는 [요약(KPI)] > [시계열 추이] > [지리적 분포] > [상세 랭킹] 순서로 구성했습니다.
대시보드 필터 정의
- Time Range: Date_reported 칼럼을 DateType으로 변환하여 적용
- WHO Region: WHO_region 칼럼 필터링
- Country: Raw data (table) Chart에만 Country 필터 적용
Dataset 정의
SELECT
-- [핵심] 문자열을 날짜로 변환
-- Superset에서 이 컬럼을 'Temporal'로 인식하게 됩니다.
CAST(Date_reported AS DATE) AS Date_reported,
-- Dimension (차원)
Country_code,
Country,
WHO_region,
-- Metric (지표) - NULL 처리
COALESCE(New_cases, 0) AS New_cases,
COALESCE(New_deaths, 0) AS New_deaths,
COALESCE(Cumulative_cases, 0) AS Cumulative_cases,
COALESCE(Cumulative_deaths, 0) AS Cumulative_deaths
FROM lakekeeper_catalog.my_namespace.covid_daily
WHERE 1 = 1
{% if from_dttm %}
AND Date_reported >= DATE_FORMAT('{{ from_dttm }}' , '%Y-%m-%d')
{% endif %}
{% if to_dttm %}
AND Date_reported < DATE_FORMAT('{{ to_dttm }}' , '%Y-%m-%d')
{% endif %}
{% if filter_values('WHO_region') %}
AND WHO_region IN ({{ "'" + "','".join(filter_values('WHO_region')) + "'" }})
{% endif %}
Chart 정의
- Weekly Confirmed Cases Trend (BIG Number with time-series chart)
- Weekly Deaths Trend (BIG Number with time-series chart)
- Weekly Fatality Trend (BIG Number with time-series chart)
- Global Daily Trend (Mixed chart)
- Daily Cases by WHO Region (Bar chart (stack))
- Cumulative Cases World Map (World Map chart)
- Top10 Countries by Cases (Bar chart)
- Raw Data View (Table chart)
결론
이 글에서는 Lakekeeper를 활용한 Apache Iceberg 기반 레이크하우스의 거버넌스 체계 구축 방법을 실제 사례와 함께 살펴보았습니다.
주요 성과
체계적인 권한 관리
- OpenFGA 기반의 강력한 권한 모델을 통해 서버부터 테이블 레벨까지 세밀한 접근 제어를 구현했습니다.
- 역할(Role) 기반 접근 제어를 통해 DataEngineer와 DataAnalyst의 권한을 명확히 분리하고 관리할 수 있었습니다.
- 양방향 상속 체계로 권한 관리의 복잡성을 줄이면서도 보안성을 유지했습니다.
멀티 엔진 통합
- Spark를 통한 배치 처리와 StarRocks를 통한 실시간 쿼리를 단일 카탈로그로 통합했습니다.
- 각 엔진에서 동일한 권한 체계가 일관되게 적용되어 데이터 거버넌스의 일관성을 확보했습니다.
실용적인 검증
- 실제 COVID-19 데이터를 활용한 권한 검증을 통해 이론과 실제 구현 간의 간격을 좁혔습니다.
- Apache Superset을 통한 시각화까지 연결하여 End-to-End 데이터 파이프라인을 완성했습니다.
도입 효과
Lakekeeper를 도입함으로써 다음과 같은 효과를 기대할 수 있습니다:
- 보안 강화: 세밀한 권한 제어로 데이터 유출 위험을 최소화하고 컴플라이언스 요구사항을 충족할 수 있습니다.
- 운영 효율성: 중앙화된 메타데이터 관리로 데이터 자산의 가시성이 향상되고 관리 비용이 감소합니다.
- 확장성: 다양한 쿼리 엔진과의 호환성으로 조직의 요구사항 변화에 유연하게 대응할 수 있습니다.
- 감사 추적: 데이터 접근 및 변경 이력을 추적하여 거버넌스 요구사항을 충족할 수 있습니다.
Lakekeeper는 현대적인 레이크하우스 환경에서 강력하고 유연한 거버넌스 체계를 구축할 수 있는 효과적인 솔루션입니다. 이 글이 여러분의 데이터 거버넌스 체계 구축에 실질적인 도움이 되기를 바랍니다.