
Lakekeeper로 시작하는 Apache Iceberg REST Catalog - 설치부터 Spark 연동까지
Apache Iceberg 데이터 레이크 환경에서 Hive Metastore(HMS)를 대체할 REST Catalog(IRC)의 도입 필요성과 장점을 다룹니다. Kubernetes 환경에 최적화된 Rust 기반 오픈소스 카탈로그 Lakekeeper의 특징과 기본 배포 아키텍처를 알아봅니다.

들어가며
현대 데이터 레이크 환경에서 Apache Iceberg는 대규모 분석 워크로드를 안정적으로 처리하기 위한 핵심 테이블 포맷으로 자리 잡았습니다.
하지만 Iceberg 테이블이 가진 스냅샷, 스키마 진화, ACID 커밋 같은 기능을 안정적으로 활용하려면, 이를 관리하는 메타데이터 카탈로그가 반드시 필요합니다.
최근 Iceberg 커뮤니티에서는 이 카탈로그를 **REST API 기반으로 표준화한 “Apache Iceberg REST Catalog(IRC)”**가 빠르게 확산되고 있습니다. 이는 카탈로그를 하나의 독립적인 서비스로 두고, Iceberg 클라이언트(Spark, Flink, Trino 등)는 표준 HTTP API를 통해 테이블 메타데이터를 읽고 쓰는 구조입니다.
왜 REST API 카탈로그로 전환하는가?
과거 많은 조직이 메타데이터 관리에 Hive Metastore(HMS) 를 사용해 왔지만, 클라우드 및 컨테이너 기반 환경으로 전환되면서 다음과 같은 한계가 드러났습니다.
🚫 Hive Metastore의 한계점:
- 단일 장애점(HA 구축 난이도): 중앙 집중형 구조로 가용성을 확보하기 어렵고 운영 부담이 큼
- 확장성 제약: 동시 커밋 및 메타데이터 요청 증가 시 병목 발생
- Thrift 기반 네트워크 의존성: 방화벽·로드밸런서 구성 난이도 증가
- 현대적 인증 체계 부족: HMS는 기본적으로 Kerberos 기반이며 OIDC/OAuth와 직접 호환되지 않음
- Hadoop 생태계 의존: 운영 환경이 Hadoop-free(K8s native)로 이동하는 추세와 불일치
REST Catalog(IRC)의 장점 — HMS를 넘어서는 이유
Iceberg REST Catalog는 **Iceberg 프로젝트에서 공식 표준으로 정의한 카탈로그 프로토콜(OpenAPI 기반)**입니다.
특징은 다음과 같습니다.
✅ Iceberg REST Catalog 장점
- HTTP/HTTPS 기반의 클라우드 네이티브 아키텍처 : Kubernetes·컨테이너 환경에서 운영하기 쉬움
- 언어·엔진 독립성 : Spark/Flink/Trino/Presto/Snowflake 등이 모두 동일 표준을 사용
- 서버사이드 커밋 모델 : 동시성 제어·테이블 커밋을 서버가 담당 → 더 안전한 멀티엔진 쓰기
- 현대적 인증 체계 적용 가능 : REST 표준을 기반으로 OIDC, OAuth2, JWT 등을 구현체 수준에서 쉽게 확장
- 확장성과 운영 편의성 : 로드밸런서를 통한 수평 확장 및 마이크로서비스와 자연스러운 통합
- 메타데이터 접근 표준화 : 각 엔진별 별도 카탈로그 클라이언트를 유지하지 않아도 됨
이러한 이유로 많은 조직이 Hive Metastore에서 REST Catalog로 전환을 검토하고 있으며,
특히 컨테이너 기반 환경(Kubernetes)에서는 REST Catalog가 가장 자연스러운 Iceberg 카탈로그 선택지가 되고 있습니다.
Lakekeeper란 무엇인가?
Lakekeeper는 Apache Iceberg REST Catalog 사양(IRC)을 준수하는 오픈소스 카탈로그 구현체입니다.
즉, Lakekeeper는 Iceberg에서 정의한 표준 REST API를 충실히 구현하여,
Spark/Flink/Trino 등 다양한 엔진이 공통된 방식으로 Iceberg 테이블을 읽고 쓸 수 있도록 합니다.
또한 Lakekeeper는 다음을 포함합니다:
- 독립 실행 가능한 REST Catalog 서비스
- S3, GCS, MinIO 등 다양한 오브젝트 스토리지 지원
- OIDC 연동과 같은 현대적 인증 방식 구현
- Kubernetes 네이티브 배포를 위한 Helm 차트 지원
Apache Iceberg REST Catalog의 필요성
Apache Iceberg는 대용량 분석 데이터셋을 위한 오픈 테이블 포맷으로, 다음과 같은 장점을 제공합니다:
- ACID 트랜잭션: 데이터 일관성 보장
- 스키마 진화: 하위 호환성을 유지하면서 스키마 변경 가능
- 타임 트래블: 과거 시점의 데이터 조회 가능
- 파티션 진화: 기존 데이터 재작성 없이 파티션 전략 변경
그러나 이 기능들이 제대로 동작하려면 메타데이터 업데이트·조회·스냅샷 관리·커밋 작업을 담당하는 카탈로그 서비스가 반드시 필요하며,
이 역할을 REST Catalog(Lakekeeper)가 수행합니다.
Lakekeeper 아키텍처
Lakekeeper는 Rust로 개발된 고성능 Iceberg REST Catalog 구현체입니다. 주요 특징은 다음과 같습니다:
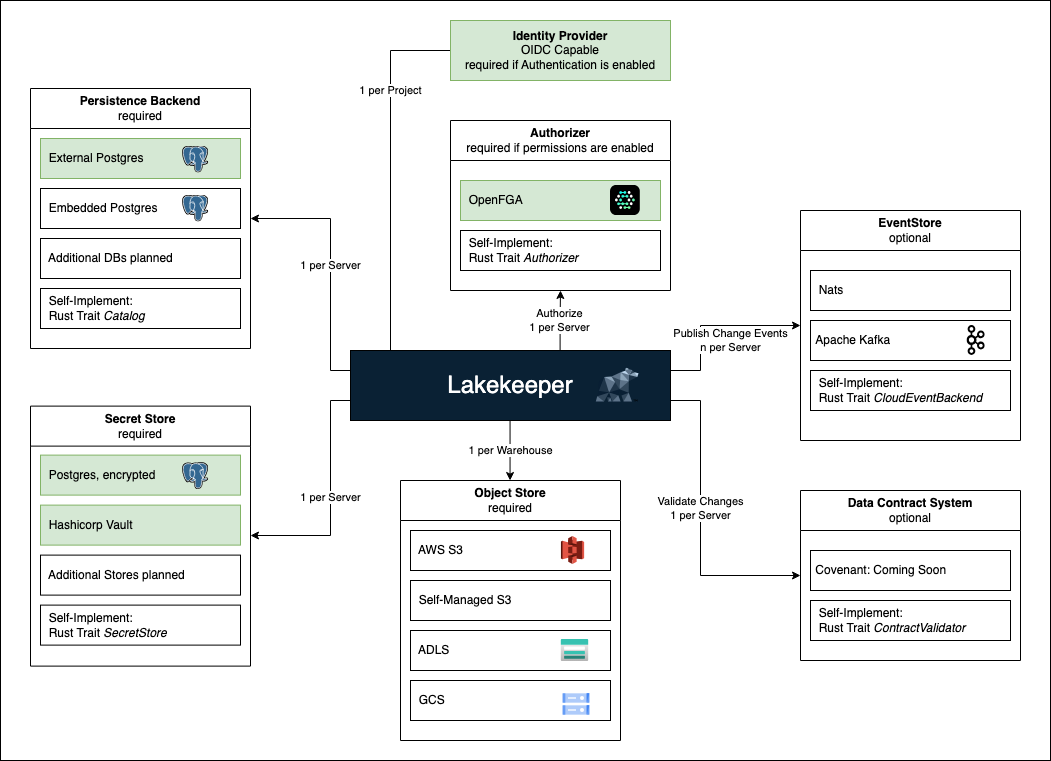
- REST API 기반: 언어와 플랫폼에 독립적인 접근
- 멀티 테넌시: 여러 프로젝트와 사용자를 안전하게 격리
- 확장 가능한 인증/인가: OIDC 및 세밀한 권한 제어 지원
- 클라우드 네이티브: Kubernetes 환경에 최적화
기본 배포 아키텍처
본 포스트에서 구축할 Lakekeeper 기본 배포 환경의 컴포넌트 간 관계는 다음과 같습니다:
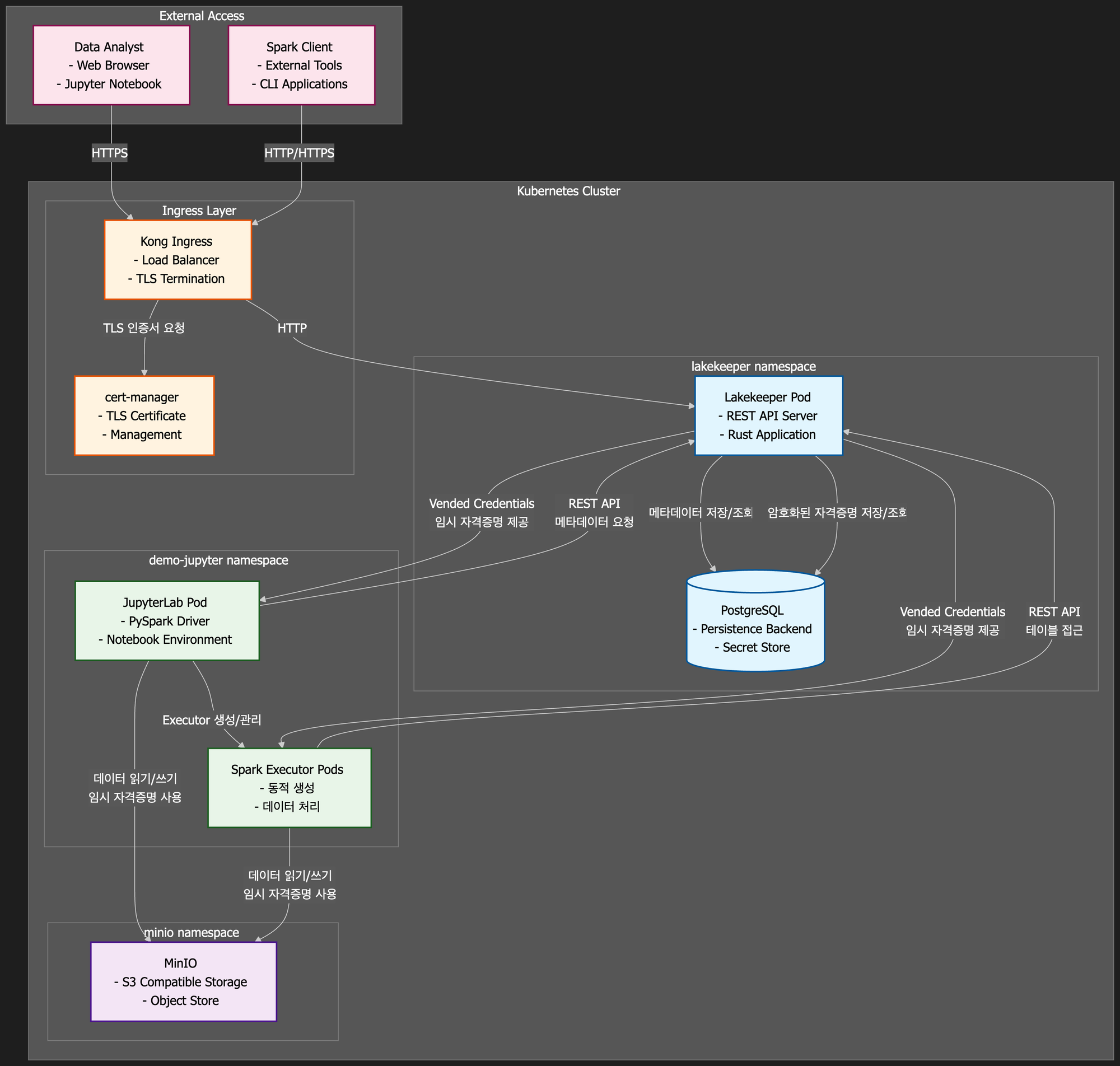
주요 컴포넌트 역할:
- Lakekeeper Core: Iceberg REST API 제공, 메타데이터 관리, 임시 자격증명 발급
- PostgreSQL: 메타데이터 저장(Persistence Backend) + 자격증명 암호화 저장(Secret Store)
- JupyterLab: Spark Driver 역할, 사용자 인터페이스
- Spark Executors: 동적 생성되는 데이터 처리 워커
- MinIO: S3 호환 객체 스토리지, 실제 Iceberg 데이터 파일 저장
- Ingress: 외부 트래픽 라우팅 및 TLS 종료
ㅡ
기본 설치 및 설정
테스트 환경
- Kubernetes 클러스터 (테스트 환경 : v1.31.4)
- Helm 3.18.3
- cert-manager 배포 및 PV 동적 프로비저닝 사용 가능 환경
- Minio
Helm을 통한 Lakekeeper 설치
먼저 Lakekeeper Helm 저장소를 추가합니다:
helm repo add lakekeeper https://lakekeeper.github.io/lakekeeper-charts/
helm repo update
기본 설치를 진행합니다:
helm install lakekeeper lakekeeper/lakekeeper -n lakekeeper --create-namespace
기본 설치 시에는 인증/인가가 비활성화되어 있고, Ingress도 비활성화 상태입니다. 실제 환경에서 사용하기 위해서는 추가 설정이 필요합니다.
Ingress 및 TLS 설정
프로덕션 환경에서 사용하기 위해 custom-values.yaml 파일을 작성합니다:
catalog:
ingress:
enabled: true
annotations:
cert-manager.io/issuer: cert-issuer
host: "lakekeeper.example.org"
ingressClassName: "kong"
path: ""
tls:
enabled: true
secretName: "lakekeeper-tls"
config:
LAKEKEEPER__BASE_URI: "https://lakekeeper.example.org"
이 설정을 적용하여 Lakekeeper를 업그레이드합니다:
helm upgrade lakekeeper lakekeeper/lakekeeper -n lakekeeper -f custom-values.yaml
주요 구성 파라미터
LAKEKEEPER__BASE_URI: 클라이언트가 접근할 기본 URILAKEKEEPER__USE_X_FORWARDED_HEADERS: 프록시 환경에서 헤더 사용 여부- Ingress 설정을 통해 외부 접근 가능한 엔드포인트 제공
첫 번째 데이터 레이크 구축
MinIO Warehouse 등록
Lakekeeper UI에 접속하여 첫 번째 Warehouse를 등록해보겠습니다.
- Warehouse 추가 페이지 접속
- Lakekeeper UI > Warehouse > Add Warehouse
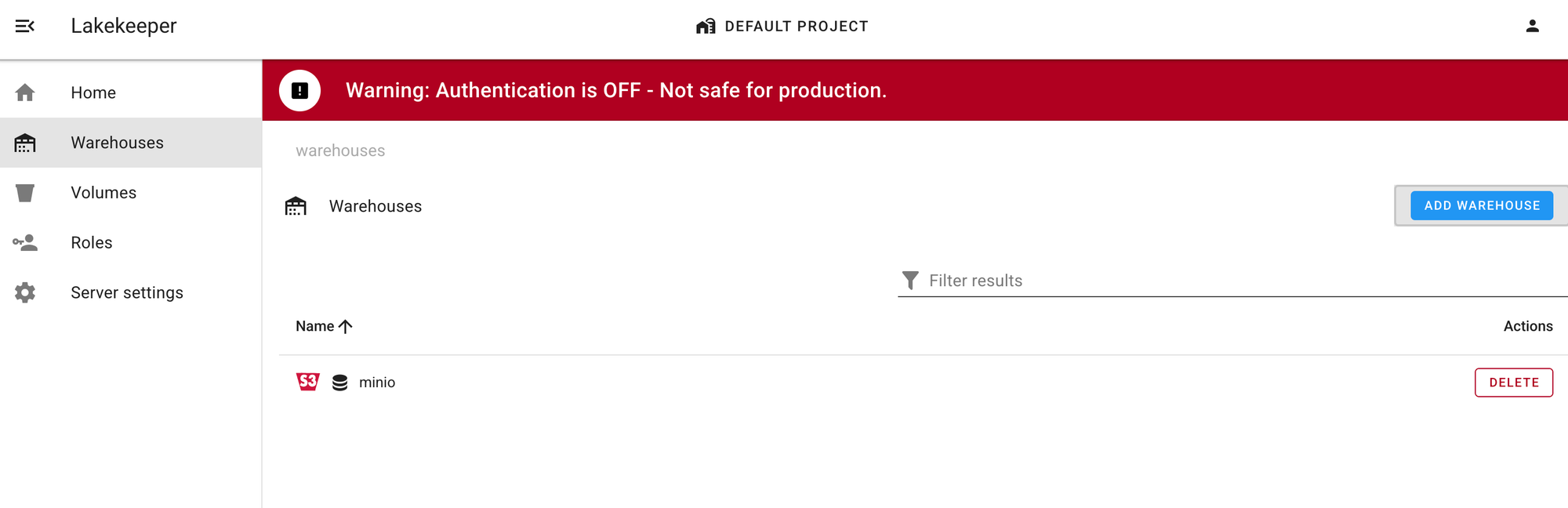
- Lakekeeper UI > Warehouse > Add Warehouse
- 기본 정보 입력
- Warehouse name:
minio - Storage type:
S3선택
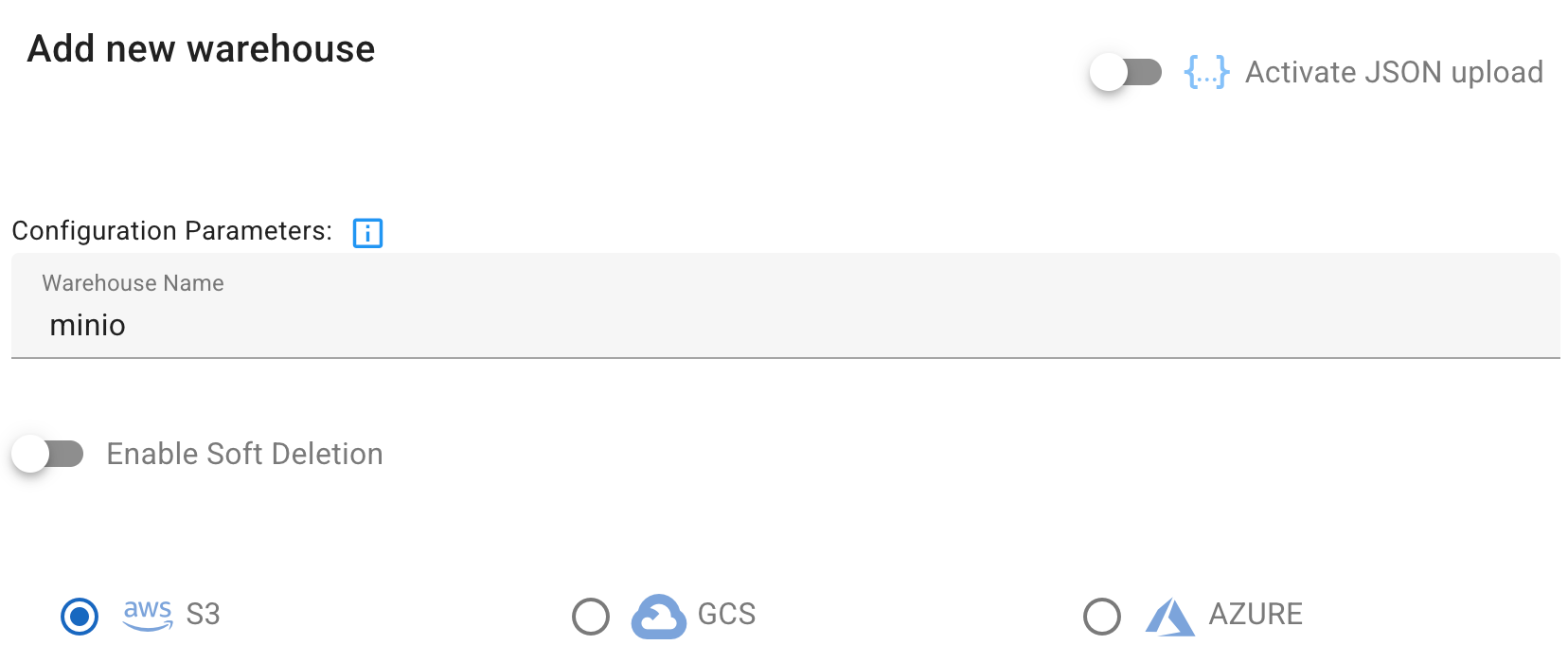
- Warehouse name:
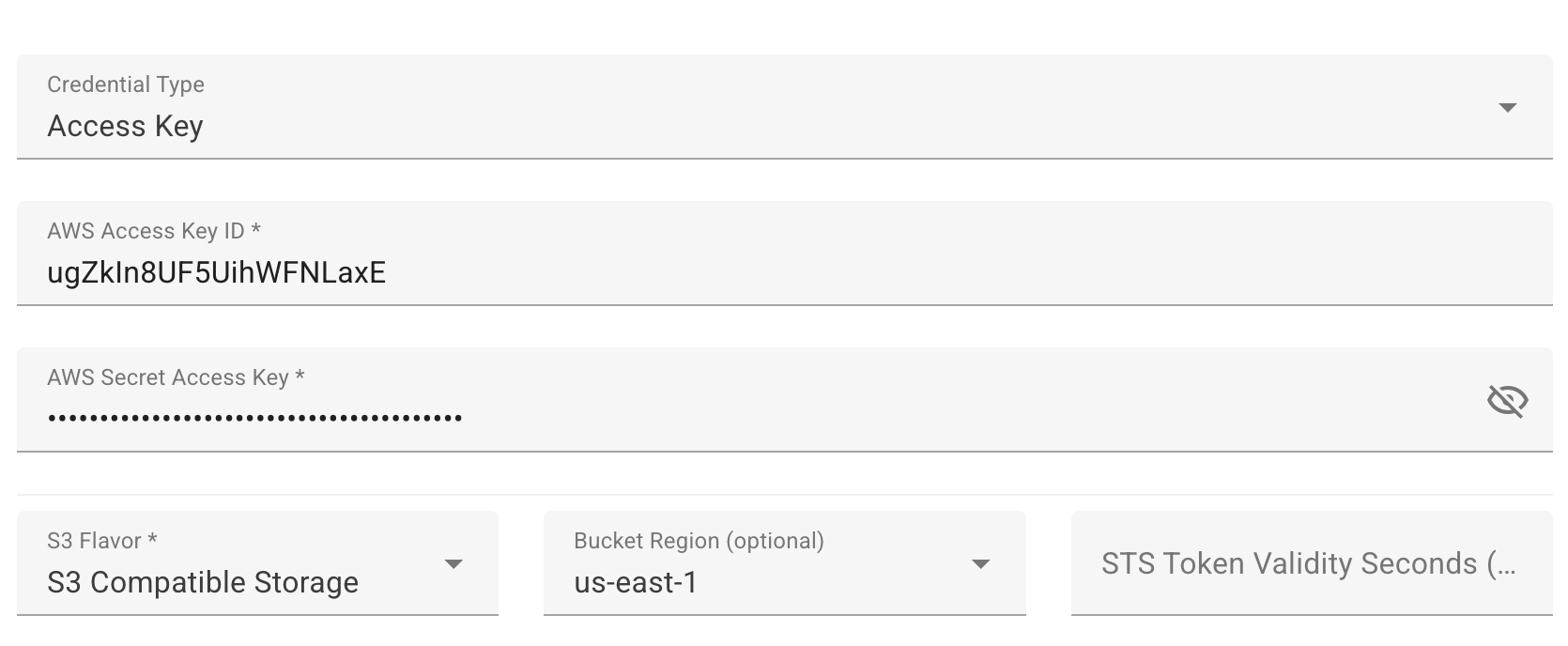
- MinIO 연결 설정
Access Key: [MinIO Access Key] Secret Key: [MinIO Secret Key] S3 Flavor: S3 Compatible Storage Region: us-east-1 Path style access: enable Alternative protocols: enable
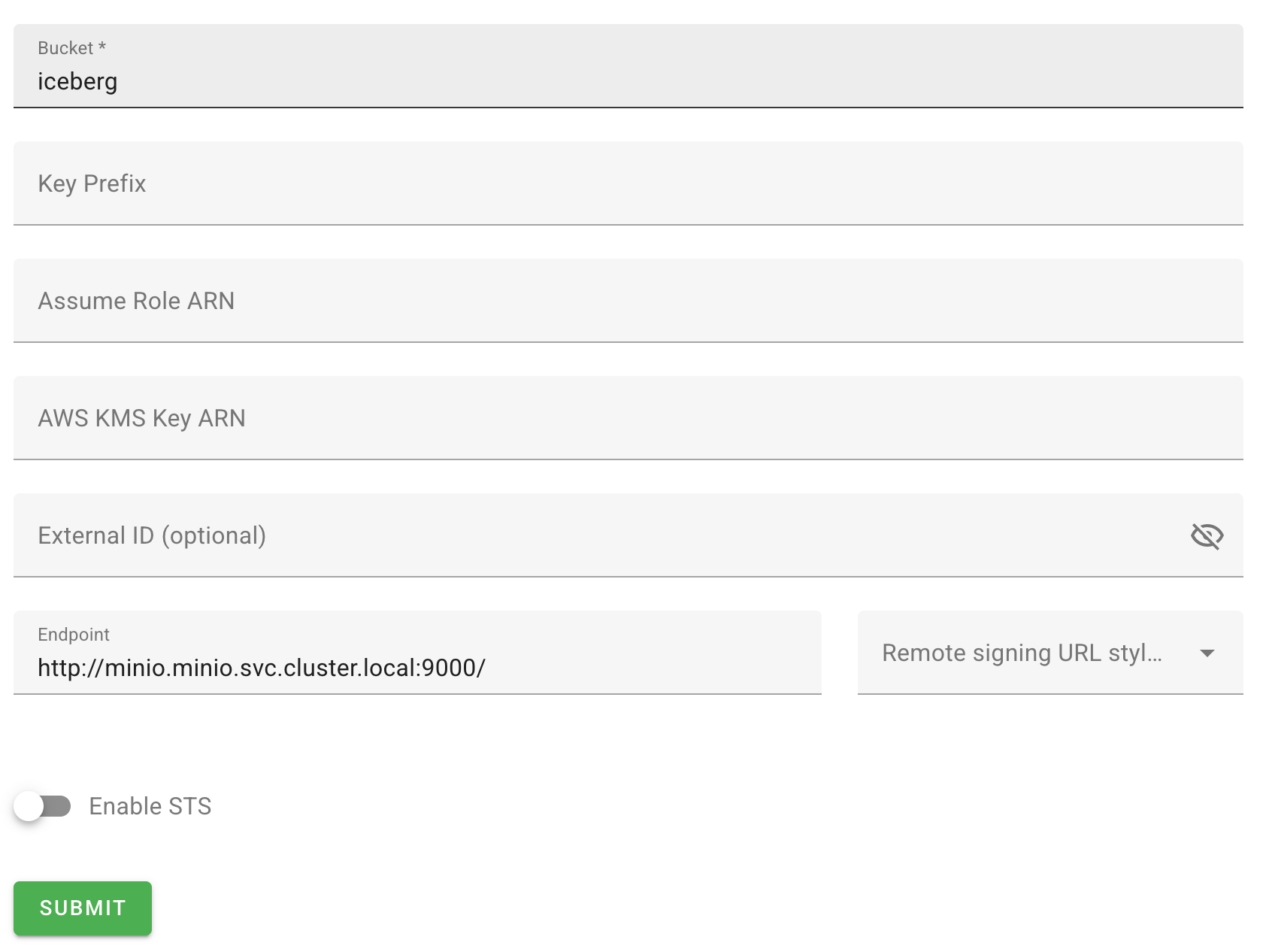
4. 스토리지 경로 설정
Bucket: iceberg
Endpoint: http://minio.minio.svc.cluster.local:9000/
S3 호환 스토리지 설정 주의사항
MinIO와 같은 S3 호환 스토리지를 사용할 때 주의할 점들:
- Path Style Access: MinIO는 path-style 접근을 사용하므로 반드시 활성화
- Alternative Protocols: HTTP 프로토콜 사용 시 활성화 필요
- Endpoint URL: 클러스터 내부 서비스 주소 사용 권장
Spark와의 첫 만남
실행 환경 전제 조건
이 예제를 실행하기 위해서는 다음 환경이 준비되어 있어야 합니다:
본 예제는 DIP(Data Intelligence Platform) 환경에서 제공하는 데이터 분석 환경에서 실행되었습니다. 해당 환경의 구성은 다음과 같습니다.
- JupyterLab 환경: PySpark를 실행할 수 있는 JupyterLab이 배포되어 있어야 합니다
- 서비스 계정: JupyterLab Pod가 Kubernetes API에 접근할 수 있는
jupyter서비스 계정이 설정되어 있어야 합니다 - 네트워크 접근: JupyterLab에서 Lakekeeper 서비스(
lakekeeper.lakekeeper.svc.cluster.local:8181)에 접근 가능해야 합니다
💡 참고: DIP 환경이 아닌 경우, 네임스페이스명과 서비스 계정명을 실제 환경에 맞게 수정하여 사용하시기 바랍니다.
PySpark 환경 구성
Kubernetes 환경에서 PySpark를 통해 Lakekeeper에 연결하는 완전한 설정을 살펴보겠습니다. 아래는 모든 설정을 포함한 통합 코드입니다:
1단계: Spark Session 생성
먼저 Lakekeeper와 연동하기 위한 Spark 설정 함수를 정의하고 Spark Session을 생성합니다:
from pyspark import SparkConf, SparkContext
from pyspark.sql import SparkSession
import pyspark
import pandas as pd
import os
def define_conf(conf: SparkConf, notebook_name, notebook_namespace):
"""
Kubernetes 환경에서 Lakekeeper와 연동하기 위한 완전한 Spark 설정 함수
"""
# 1. Spark 기본 리소스 설정
conf.set("spark.submit.deployMode", "client")
conf.set("spark.executor.instances", "1")
conf.set("spark.executor.memory", "1G")
conf.set("spark.driver.memory", "1G")
conf.set("spark.executor.cores", "1")
# 2. Kubernetes 환경 설정
conf.set("spark.kubernetes.namespace", notebook_namespace)
conf.set("spark.kubernetes.container.image", "paasup/spark:3.5.2-java17-python3.11-2")
conf.set("spark.kubernetes.authenticate.driver.serviceAccountName", "jupyter")
conf.set("spark.kubernetes.driver.pod.name", os.environ["HOSTNAME"])
# 3. 네트워크 설정 (포트 충돌 방지)
conf.set("spark.driver.bindAddress", "0.0.0.0")
conf.set("spark.driver.host", f"{notebook_name}-headless.{notebook_namespace}.svc.cluster.local")
conf.set("spark.driver.port", "51810")
conf.set("spark.broadcast.port", "51811")
conf.set("spark.blockManager.port", "51812")
# 4. Iceberg 라이브러리 설정
pyspark_version = pyspark.__version__
pyspark_version = ".".join(pyspark_version.split(".")[:2]) # 패치 버전 제거
iceberg_version = "1.6.1"
jar_list = ",".join([
"org.apache.hadoop:hadoop-common:3.3.4",
"org.apache.hadoop:hadoop-aws:3.3.4",
"com.amazonaws:aws-java-sdk:1.11.655",
f"org.apache.iceberg:iceberg-spark-runtime-{pyspark_version}_2.12:{iceberg_version}",
f"org.apache.iceberg:iceberg-aws-bundle:{iceberg_version}",
f"org.apache.iceberg:iceberg-azure-bundle:{iceberg_version}",
f"org.apache.iceberg:iceberg-gcp-bundle:{iceberg_version}"
])
conf.set("spark.jars.packages", jar_list)
# 5. Iceberg Spark 확장 설정
conf.set("spark.sql.extensions", "org.apache.iceberg.spark.extensions.IcebergSparkSessionExtensions")
# 6. SparkSessionCatalog 설정 (기본 카탈로그)
conf.set("spark.sql.catalog.spark_catalog", "org.apache.iceberg.spark.SparkSessionCatalog")
conf.set("spark.sql.catalog.spark_catalog.type", "hive")
# 7. Lakekeeper REST Catalog 설정
catalog_name = "demo"
conf.set(f"spark.sql.catalog.{catalog_name}", "org.apache.iceberg.spark.SparkCatalog")
conf.set(f"spark.sql.catalog.{catalog_name}.catalog-impl", "org.apache.iceberg.rest.RESTCatalog")
conf.set(f"spark.sql.catalog.{catalog_name}.uri", "http://lakekeeper.lakekeeper.svc.cluster.local:8181/catalog/")
conf.set(f"spark.sql.catalog.{catalog_name}.token", "dummy") # 인증 비활성화 시 더미 토큰
conf.set(f"spark.sql.catalog.{catalog_name}.warehouse", "minio") # 앞서 등록한 warehouse 이름
# Spark Session 생성 및 실행
notebook_name = "jupyter"
notebook_namespace = "demo-jupyter"
conf = SparkConf()
define_conf(
conf=conf,
notebook_name=notebook_name,
notebook_namespace=notebook_namespace,
)
# Spark Session 생성
spark = SparkSession.builder.config(conf=conf)\
.appName('jupyter-iceberg-test')\
.master("k8s://https://kubernetes.default.svc.cluster.local:443")\
.getOrCreate()
설정 구성 요소 설명:
- 1-3단계: Spark 리소스, Kubernetes 환경, 네트워크 설정으로 기본 실행 환경 구성
- 4단계: Iceberg 관련 JAR 패키지를 동적으로 다운로드하여 호환성 보장
- 5-7단계: Iceberg 확장 기능과 카탈로그 설정으로 Lakekeeper와 연결
2단계: Iceberg 테이블 생성 및 데이터 조작
Spark Session이 생성되면 실제 Iceberg 테이블을 생성하고 데이터를 조작해보겠습니다:
# 네임스페이스 생성 및 확인
spark.sql("USE demo")
spark.sql("CREATE NAMESPACE IF NOT EXISTS my_namespace")
print("🔍 현재 존재하는 네임스페이스:")
print(spark.sql("SHOW NAMESPACES").toPandas())
# 테이블 생성 및 데이터 삽입
# 샘플 데이터 생성
sdf = spark.createDataFrame(
pd.DataFrame(
[[1, 1.2, "foo"], [2, 2.2, "bar"]],
columns=["my_ints", "my_floats", "strings"]
)
)
# Iceberg 테이블 생성
spark.sql("DROP TABLE IF EXISTS demo.my_namespace.my_table")
spark.sql("""
CREATE TABLE demo.my_namespace.my_table
(my_ints INT, my_floats DOUBLE, strings STRING)
USING iceberg
""")
# 데이터 삽입 및 조회
sdf.writeTo("demo.my_namespace.my_table").append()
print("📊 생성된 테이블 데이터:")
spark.table("demo.my_namespace.my_table").show()
실행 과정 설명:
- 카탈로그 선택:
USE demo로 Lakekeeper 카탈로그 활성화 - 네임스페이스 생성: 테이블을 그룹화할 논리적 컨테이너 생성
- 테이블 스키마 정의:
USING iceberg로 Iceberg 포맷 테이블 생성 - 데이터 삽입:
writeTo().append()메서드로 안전한 데이터 추가 - 결과 확인: 생성된 테이블의 데이터와 메타데이터 검증
주요 설정 포인트
Kubernetes 네이티브 실행
- Spark Driver는 JupyterLab Pod에서 실행되고, Executor는 별도 Pod로 동적 생성
spark.kubernetes.namespace로 리소스 격리 및 관리- 서비스 계정을 통한 Kubernetes API 접근 권한 제어
Iceberg REST Catalog 연동
org.apache.iceberg.rest.RESTCatalog구현체 사용- HTTP 기반 통신으로 방화벽 친화적
dummy토큰으로 인증 비활성화 상태에서 테스트
설정 시 주의사항
네트워킹 고려사항
- 클러스터 내부 통신: Spark executor들이 Lakekeeper에 접근할 수 있도록 서비스 주소 사용
- 포트 설정: Spark driver의 포트들이 충돌하지 않도록 고유한 포트 사용
- DNS 해석: Kubernetes 서비스 DNS가 정상적으로 작동하는지 확인
성능 최적화
- 메모리 설정: 데이터 크기에 맞는 적절한 executor 메모리 할당
- 병렬 처리: executor 인스턴스 수와 코어 수 조정
- 네트워크 최적화: 브로드캐스트 및 블록 매니저 포트 분리
마무리
이번 포스트에서는 Lakekeeper의 기본 개념부터 실제 설치, 그리고 Spark와의 연동까지 살펴보았습니다.
주요 성과:
- ✅ Lakekeeper 기본 설치 및 Ingress 설정
- ✅ MinIO Warehouse 등록 및 연결
- ✅ PySpark 환경에서 Iceberg 테이블 생성 및 조작
다음 포스트에서는 엔터프라이즈 환경에서 필수적인 보안 설정에 대해 다룰 예정입니다. Keycloak을 통한 인증과 OpenFGA를 활용한 세밀한 권한 제어를 구현하여, 프로덕션 환경에서 안전하게 Lakekeeper를 운영하는 방법을 알아보겠습니다.