
NVIDIA DGX Spark 활용하기: 로컬 연결부터 120B 모델 서빙까지
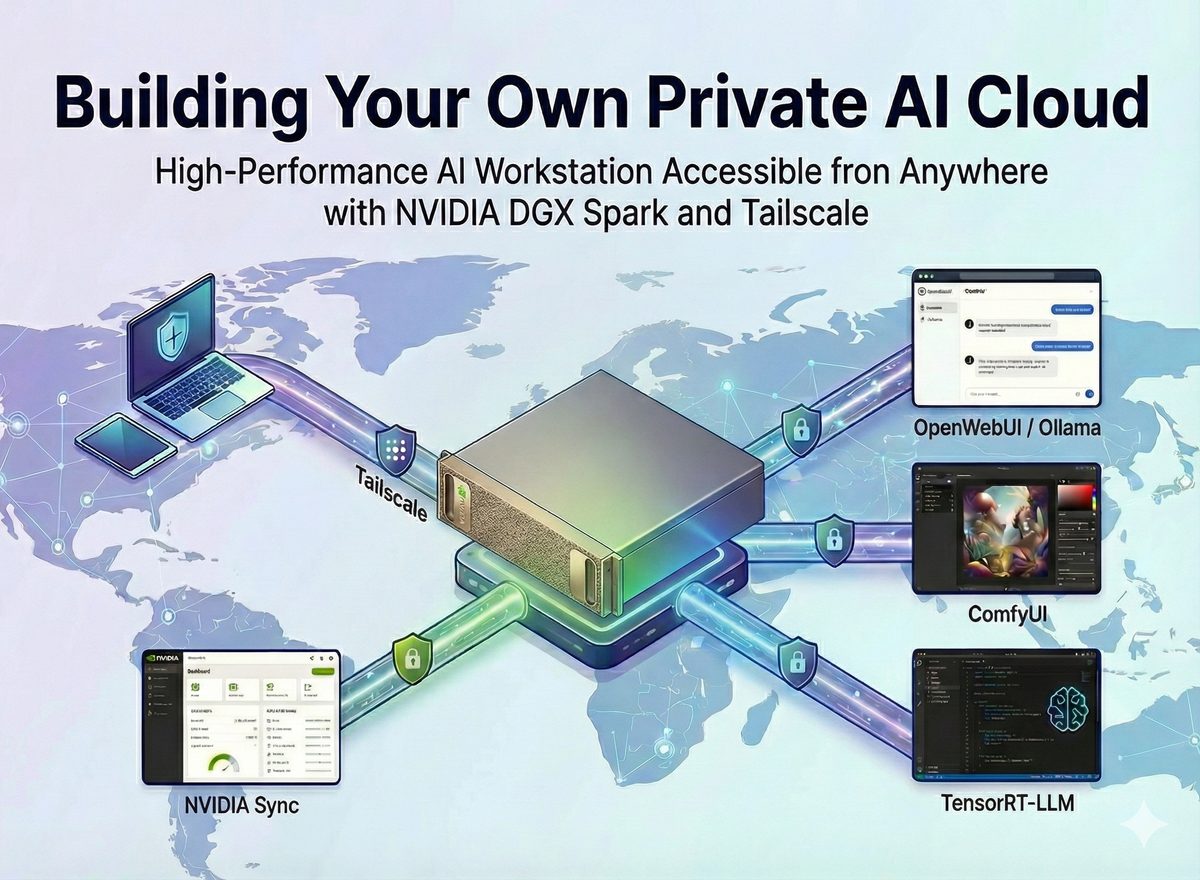
고성능 AI 워크스테이션인 NVIDIA DGX Spark를 도입했지만, 단순한 로컬 접속만으로는 그 잠재력을 모두 끌어내기 어렵습니다. 이 글에서는 NVIDIA Sync를 통한 간편한 기기 관리, Tailscale을 이용한 안전한 원격 액세스, 그리고 Docker Custom Script를 활용해 클릭 한 번으로 생성형 AI 서비스(Ollama, ComfyUI, TensorRT-LLM)를 배포하고 관리하는 ‘나만의 AI 프라이빗 클라우드’ 구축 과정을 상세히 다룹니다.
목차
- 들어가며: 고성능 장비를 쉽고 편하게 쓰는 법
- NVIDIA Sync: 복잡한 설정 없는 로컬 연결
- Tailscale: 어디서든 접속 가능한 보안 네트워크
- OpenWebUI: 나만의 프라이빗 챗봇 구축
- ComfyUI: Stable Diffusion 이미지 생성 자동화
- TensorRT-LLM: 엔터프라이즈급 LLM 서빙 및 활용
- 마치며: 나만의 프라이빗 AI 클라우드 완성하기
본 가이드는 NVIDIA DGX Spark 공식 플레이북을 기반으로 작성되었으며, 실제 운영 환경에서의 편의성을 높이기 위한 추가적인 설정(Tailscale, Custom Script)을 포함하고 있습니다.
1. 들어가며: 고성능 장비를 쉽고 편하게 쓰는 법
강력한 GPU가 탑재된 워크스테이션이 있어도, 매번 터미널을 열고 긴 Docker 명령어를 입력해야 한다면 활용도가 떨어집니다. 또한 사무실 밖에서도 이 장비에 안전하게 접속하고 싶다는 니즈는 필연적입니다.
우리는 이 문제를 해결하기 위해 다음 세 가지 도구를 조합합니다.
- NVIDIA Sync: 로컬 네트워크 내 장치 자동 검색 및 상태 모니터링
- Tailscale: 포트 포워딩 없이 외부에서 접속 가능한 Mesh VPN 구축
- Docker & Custom Script: 복잡한 실행 과정을 버튼 하나로 단축
이제 이 강력한 하드웨어를 진정한 '개인용 AI 클라우드'로 변모시켜 보겠습니다.
2. NVIDIA Sync: 복잡한 설정 없는 로컬 연결
DGX Spark 세팅 후 가장 먼저 해야 할 일은 내 PC와 장비를 연결하는 것입니다. IP를 일일이 스캔할 필요 없이, NVIDIA에서 제공하는 전용 툴을 사용하면 됩니다.
1) 설치 및 장치 검색
NVIDIA Sync는 mDNS(Multicast DNS)를 사용하여 동일 네트워크 대역의 장치를 자동으로 찾아냅니다.
- 다운로드: NVIDIA Spark - Connect to your Spark에서 OS에 맞는 버전을 설치합니다.
- 장치 추가: PC와 Spark 장비가 동일한 네트워크(Wi-Fi/공유기) 에 있는지 확인 후 앱을 실행합니다.
Hostname or IP: 장비의 호스트명 또는 IPUsername / Password: 초기 설정한 계정 정보
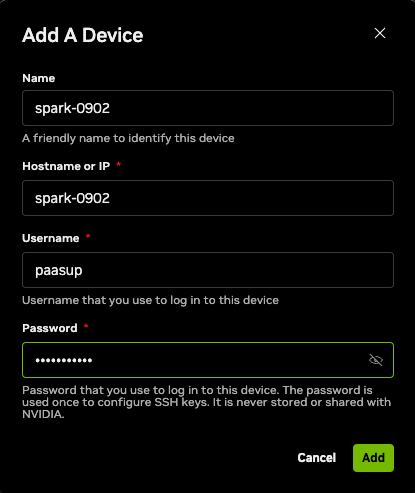
- 연결 (Connect): 등록한 장치를 선택 후
Connect버튼을 클릭합니다.
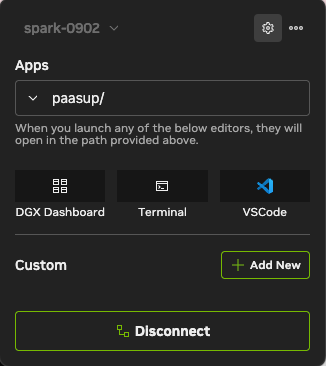
2) 대시보드 활용
연결이 완료되면 대시보드에서 CPU/GPU 리소스 모니터링, JupyterLab 접속, 터미널 실행 등 핵심 기능을 즉시 사용할 수 있습니다. 특히 이후 단계에서 설정할 AI 서비스들을 이곳의 'Custom' 메뉴에 등록하여 관리하게 됩니다.
3. Tailscale: 어디서든 접속 가능한 보안 네트워크
로컬 연결은 완료되었지만, 우리는 사무실 밖에서도 접속하길 원합니다. 복잡한 방화벽 설정이나 포트 포워딩 없이 안전한 사설망을 구성해주는 Tailscale이 최적의 솔루션입니다.
1) DGX Spark 장비에 Tailscale 설치 (Host)
내장 터미널 또는 SSH를 통해 접속 후 아래 명령어로 설치를 진행합니다.
# 패키지 리스트 업데이트 및 필수 도구 설치
sudo apt update && sudo apt install -y curl gnupg
# Tailscale GPG 키 추가
curl -fsSL https://pkgs.tailscale.com/stable/ubuntu/noble.noarmor.gpg | \
sudo tee /usr/share/keyrings/tailscale-archive-keyring.gpg > /dev/null
# Tailscale 저장소 추가
curl -fsSL https://pkgs.tailscale.com/stable/ubuntu/noble.tailscale-keyring.list | \
sudo tee /etc/apt/sources.list.d/tailscale.list
# 설치 진행 및 실행
sudo apt update && sudo apt install -y tailscale
sudo tailscale up
sudo tailscale up 실행 시 출력되는 인증 URL을 브라우저에 입력하여 로그인을 진행합니다.
Tip: 비즈니스 메일 계정 사용 시 평가판 사용이 가능하나, 장기적인 개인 사용 목적이라면 개인 Gmail 계정 등을 권장합니다.
로그인이 완료되면 Connect 버튼을 눌러 DGX Spark를 안전한 사설망(Tailnet)의 일원으로 등록합니다.
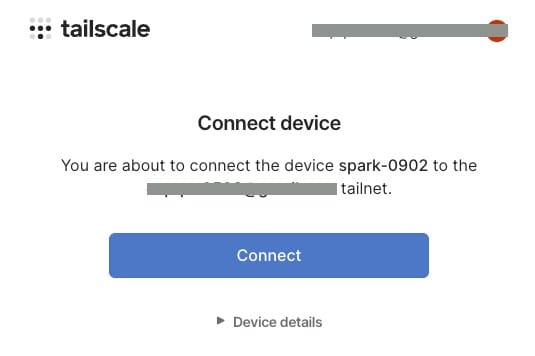
※ 참고: Tailscale 시작 시 private tailnet이 생성되고 100.x.x.x 대역의 고정 IP 주소가 할당됩니다.
2) 클라이언트 장치 설정 (내 PC/Mac)
이제 접속하려는 내 컴퓨터(Client)에도 Tailscale을 설치하고 동일한 계정으로 로그인해야 합니다.
설치 후 앱을 실행하고 Spark에서 로그인했던 계정과 동일한 계정으로 로그인합니다.
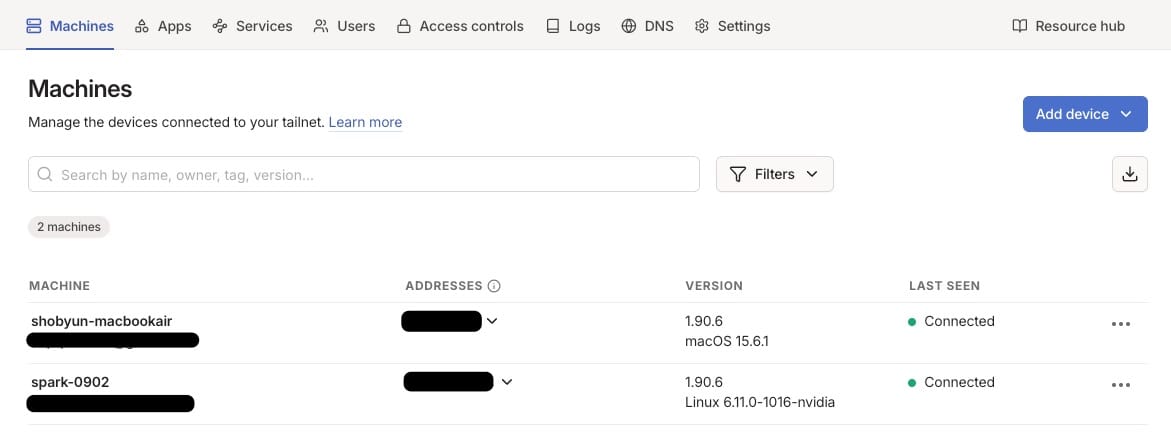
3) NVIDIA Sync에 원격 IP 등록
모든 연결 고리가 완성되었습니다. 이제 NVIDIA Sync가 로컬 IP가 아닌 Tailscale IP를 바라보게 설정해야 합니다.
- DGX Spark 터미널에서
tailscale ip를 입력하여100.x.x.x형식의 IP를 확인합니다. (Tailscale 관리자 페이지에서도 확인 가능) - NVIDIA Sync 설정(Settings > Devices)에서 기존 연결을 수정하거나 새로 추가합니다.
- Hostname or IP 란에 확인한 Tailscale IP를 입력합니다.
이제 집이든 카페든 인터넷만 연결되어 있다면, NVIDIA Sync를 통해 DGX Spark의 강력한 성능을 제어할 수 있습니다.
4. OpenWebUI: 나만의 프라이빗 챗봇 구축
연결이 완료되었으니 첫 번째 워크로드를 실행해 봅시다. Ollama는 로컬 LLM을 가장 쉽고 가볍게 구동할 수 있는 도구이며, OpenWebUI는 ChatGPT와 유사한 깔끔한 사용자 인터페이스를 제공합니다.
1) 수동 설치 및 검증 (CLI)
먼저 터미널 환경에서 컨테이너가 정상적으로 실행되는지 확인해 봅니다.
Docker 권한 구성
sudo 없이 Docker 명령어를 쓰기 위해 사용자를 그룹에 추가합니다.
sudo usermod -aG docker $USER
newgrp docker
# 권한 확인 (에러 없이 목록이 나오면 성공)
docker ps
이미지 다운로드 및 실행 테스트
Ollama 백엔드가 번들로 포함된 Open WebUI 이미지를 가져옵니다.
docker pull ghcr.io/open-webui/open-webui:ollama
포트 8080을 열고 GPU를 모두 사용하도록 설정하여 실행합니다.
docker run -d -p 8080:8080 --gpus=all \
-v open-webui:/app/backend/data \
-v open-webui-ollama:/root/.ollama \
--name open-webui ghcr.io/open-webui/open-webui:ollama
브라우저 주소창에 http://<DGX_SPARK_IP>:8080을 입력하여 접속합니다.
참고: 데이터는 도커 볼륨(
open-webui,open-webui-ollama)에 저장되므로 컨테이너를 삭제해도 채팅 기록과 모델은 유지됩니다.
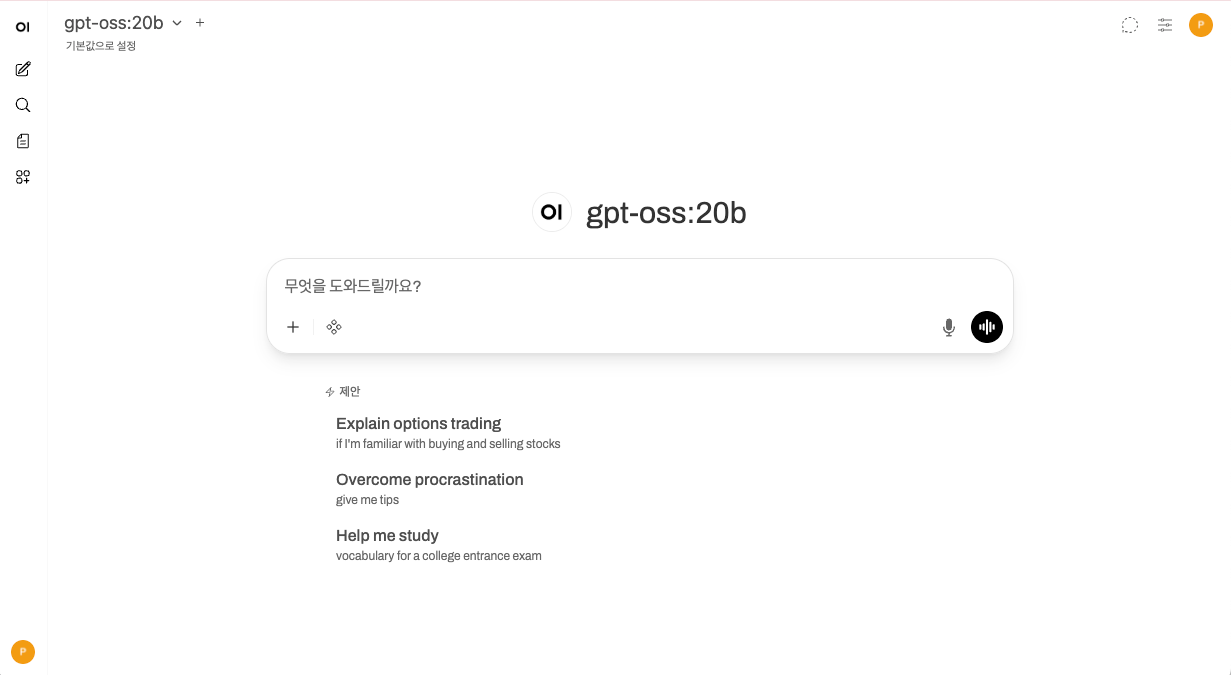
초기 설정 및 모델 다운로드
- 관리자 계정 생성: 처음 접속 시 관리자 계정 생성 화면이 뜹니다. 이름, 이메일, 비밀번호를 입력하여 계정을 만듭니다.
- 모델 다운로드:
- 로그인 후 왼쪽 상단 "모델 선택" 드롭다운을 클릭합니다.
- 검색창에
gpt-oss:20b(또는llama3,mistral등 원하는 모델)를 입력합니다. - "Ollama.com에서 '...' 가져오기" 버튼을 클릭하면 다운로드가 시작됩니다.
- 테스트: 다운로드가 완료되면 해당 모델을 선택하고 채팅창에 메세지를 입력하여 답변이 오는지 확인합니다.
정리 및 롤백 (중요)
수동 테스트가 끝났습니다. 다음 단계인 NVIDIA Sync 설정을 위해 실행 중인 컨테이너를 정리합니다. (이 과정을 건너뛰면 포트 충돌이 발생할 수 있습니다.)
# 컨테이너 중지 및 삭제
docker stop open-webui
docker rm open-webui
# (선택사항) 다운로드한 도커 이미지를 삭제하려면
# docker rmi ghcr.io/open-webui/open-webui:ollama
# (주의) 채팅 기록과 다운로드한 모델까지 삭제하려면 아래 명령 실행
# docker volume rm open-webui open-webui-ollama
2) NVIDIA Sync로 간편하게 실행하기 (Custom Script)
매번 터미널 명령어를 입력하는 대신, NVIDIA Sync의 Custom 기능을 활용해 원클릭 실행 환경을 구축합니다.
- 연결 상태 확인: NVIDIA Sync가 DGX Spark에
Connected상태인지 확인합니다. (※ 주의: Docker 권한 설정 변경 전에 연결했다면, 연결을 끊었다가 다시 연결해주세요.) - Custom 메뉴 이동: 우측 상단 설정(⚙️) 아이콘 →
Custom탭을 클릭합니다.
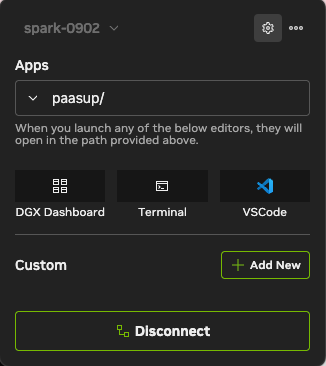
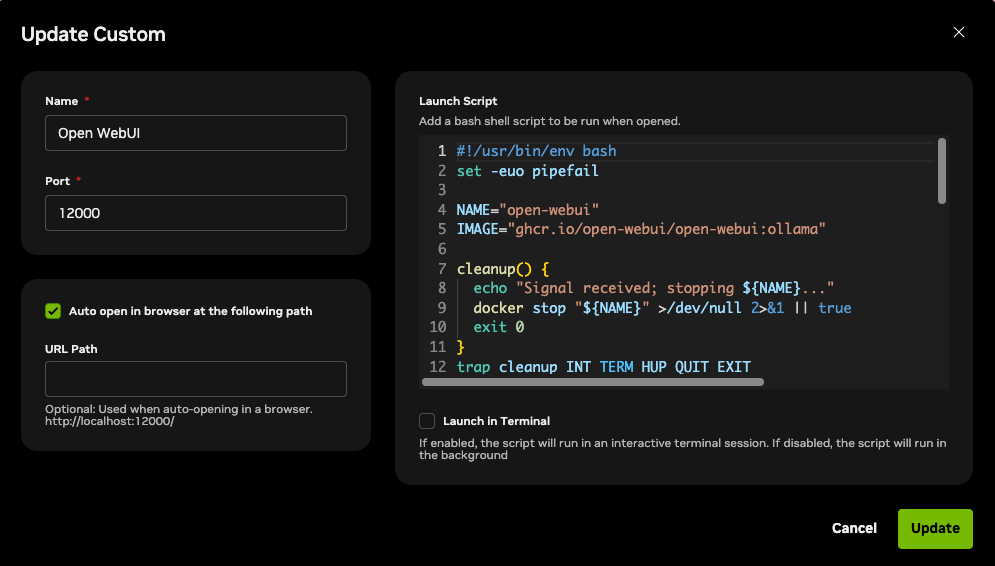
Custom탭에서+Add New를 클릭하고 아래 내용을 입력합니다. (NVIDIA Sync에서는 포트 충돌 방지를 위해12000포트를 사용합니다.)- Name:
Open WebUI - Port:
12000 - Auto open in browser at the following path: ✅ 체크 (활성화)
- Launch Script: 아래 코드를 복사해서 붙여넣습니다.
- Name:
#!/usr/bin/env bash
set -euo pipefail
NAME="open-webui"
IMAGE="ghcr.io/open-webui/open-webui:ollama"
# 스크립트 종료 시(Stop 버튼 클릭 시) 컨테이너 정지
cleanup() {
echo "Signal received; stopping ${NAME}..."
docker stop "${NAME}" >/dev/null 2>&1 || true
exit 0
}
trap cleanup INT TERM HUP QUIT EXIT
# Docker 실행 가능 여부 확인
if ! docker info >/dev/null 2>&1; then
echo "Error: Docker daemon not reachable." >&2
exit 1
fi
# Already running?
if [ -n "$(docker ps -q --filter "name=^${NAME}$" --filter "status=running")" ]; then
echo "Container ${NAME} is already running."
else
# Exists but stopped? Start it.
if [ -n "$(docker ps -aq --filter "name=^${NAME}$")" ]; then
echo "Starting existing container ${NAME}..."
docker start "${NAME}" >/dev/null
else
# Not present: create and start it.
echo "Creating and starting ${NAME}..."
docker run -d -p 12000:8080 --gpus=all \
-v open-webui:/app/backend/data \
-v open-webui-ollama:/root/.ollama \
--name "${NAME}" "${IMAGE}" >/dev/null
fi
fi
echo "Running. Press Ctrl+C to stop ${NAME}."
# Keep the script alive until a signal arrives
while :; do sleep 86400; done
- 입력 후
Add를 누르면 메인 화면의 Custom 섹션에 Open WebUI 항목이 생성됩니다. 이제 클릭 한 번으로 나만의 AI 챗봇이 실행되고 브라우저(http://localhost:12000)가 자동으로 열립니다.
5. ComfyUI: Stable Diffusion 이미지 생성 자동화
텍스트 생성을 넘어, DGX Spark의 강력한 GPU 성능을 이미지 및 영상 생성에 활용해 봅시다. ComfyUI는 노드 기반의 인터페이스를 제공하여 Stable Diffusion 모델을 정교하게 제어할 수 있습니다.
1) 기본 설치 및 데이터 준비 (Manual)
먼저 호스트 머신에 ComfyUI를 다운로드하고, 모델 파일을 준비합니다. 이 과정은 나중에 Docker 컨테이너가 참조할 로컬 데이터를 만드는 과정이기도 합니다.
소스 코드 복제
홈 디렉토리에 ComfyUI 저장소를 복제합니다.
git clone https://github.com/comfyanonymous/ComfyUI.git
cd ComfyUI/
가상 환경 구성 및 PyTorch 설치
로컬 테스트를 위해 가상 환경을 만들고 PyTorch를 설치합니다. (Docker로만 실행할 예정이라면 이 단계와 '종속성 설치'는 건너뛰어도 되지만, 로컬 디버깅을 위해 설치를 권장합니다.)
# 가상 환경 생성 및 활성화
python3 -m venv comfyui-env
source comfyui-env/bin/activate
# PyTorch 설치 (CUDA 12.9를 지원하는 PyTorch를 설치)
pip3 install torch torchvision --index-url https://download.pytorch.org/whl/cu130
필수 종속성 설치
pip install -r requirements.txt
모델 다운로드 (Checkpoint)
테스트를 위해 Stable Diffusion 1.5 모델(약 2GB)을 다운로드합니다.
cd models/checkpoints/
wget https://huggingface.co/Comfy-Org/stable-diffusion-v1-5-archive/resolve/main/v1-5-pruned-emaonly-fp16.safetensors
cd ../../
로컬 실행 테스트
서버를 실행하여 정상적으로 작동하는지 확인합니다.
python main.py --listen 0.0.0.0
브라우저에서 http://<DGX_SPARK_IP>:8188 (예: http://192.168.1.80:8188)에 접속하여 기본 화면이 뜨는지 확인합니다.
확인 후:
Ctrl+C를 눌러 서버를 종료합니다. (종료하지 않으면 다음 단계에서 포트 충돌이 발생합니다.)
2) NVIDIA Sync로 자동화하기 (Custom Script)
환경 설정이 까다로운 ComfyUI를 NVIDIA 최적화 PyTorch 컨테이너 위에서 안정적으로 구동합니다.
- 도커 이미지 준비: NVIDIA NGC에서 최적화된 PyTorch 이미지를 미리 받아둡니다.
docker pull nvcr.io/nvidia/pytorch:25.11-py3
- ComfyUI 실행 스크립트 등록: NVIDIA Sync의 Custom 탭에서
+Add New를 클릭하고 다음 정보를 입력합니다.- Name:
ComfyUI - Port:
8188 - Auto open in browser at the following path: ✅ 체크 (활성화)
- Launch Script: 아래 내용을 복사합니다. 이 스크립트는 로컬 폴더를 마운트하고, NVIDIA의 최적화된 라이브러리를 덮어쓰지 않도록
requirements.txt를 수정하여 설치하는 로직을 포함합니다. (스크립트 실행 전LOCAL_COMFY_DIR변수가 실제 설치 경로와 일치하는지 확인하세요.)
- Name:
#!/usr/bin/env bash
set -euo pipefail
# --- 설정 변수 ---
NAME="comfyui-server"
IMAGE="nvcr.io/nvidia/pytorch:25.11-py3"
# 로컬 ComfyUI 경로
LOCAL_COMFY_DIR="$HOME/ComfyUI"
# --- 정리 함수 ---
cleanup() {
echo "Signal received; stopping ${NAME}..."
docker stop "${NAME}" >/dev/null 2>&1 || true
exit 0
}
trap cleanup INT TERM HUP QUIT EXIT
# Docker 데몬 확인
if ! docker info >/dev/null 2>&1; then
echo "Error: Docker daemon not reachable." >&2
exit 1
fi
# 기존 컨테이너 처리
if [ -n "$(docker ps -aq --filter "name=^${NAME}$")" ]; then
if [ -n "$(docker ps -q --filter "name=^${NAME}$" --filter "status=running")" ]; then
echo "Container ${NAME} is already running."
while :; do sleep 86400; done
exit 0
else
echo "Removing stopped container..."
docker rm "${NAME}" >/dev/null
fi
fi
echo "Creating and starting ${NAME}..."
# --- 컨테이너 실행 ---
# -v: 로컬 파일을 컨테이너 내부에 마운트 (데이터 보존)
docker run -d \
--name "${NAME}" \
--gpus all \
--network host \
--ipc=host \
-v "${LOCAL_COMFY_DIR}:/workspace/ComfyUI" \
"${IMAGE}" \
bash -c '
echo "Checking GPU visibility..."
nvidia-smi
cd /workspace/ComfyUI
echo "Processing requirements.txt..."
# 1. requirements.txt를 안전한 곳으로 복사
cp requirements.txt /tmp/req_safe.txt
# 2. NVIDIA 이미지의 최적화된 PyTorch를 보호하기 위해
# requirements 파일에서 torch 관련 패키지(torch, torchvision, torchaudio)를 제거
sed -i "/^torch$/d" /tmp/req_safe.txt
sed -i "/^torchvision$/d" /tmp/req_safe.txt
sed -i "/^torchaudio$/d" /tmp/req_safe.txt
# 3. 나머지 종속성 설치
echo "Installing dependencies from file..."
pip install -r /tmp/req_safe.txt > /tmp/install_logs.txt 2>&1
# 오디오 관련 패키지 보완
pip install torchaudio --no-deps > /tmp/audio_install_log.txt 2>&1
echo "Starting ComfyUI..."
python main.py --listen 0.0.0.0 --port 8188
' >/dev/null
echo "ComfyUI is starting via NVIDIA Sync."
echo "Running. Press Stop in Sync to end."
while :; do sleep 86400; done
- 입력 후
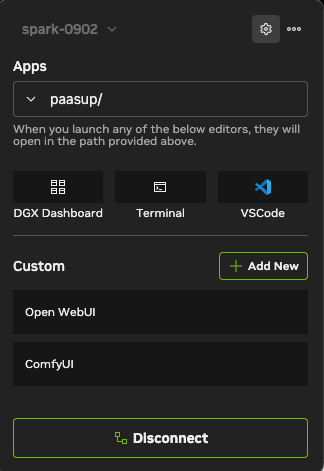
Add를 누르면 메인 화면의 Custom 섹션에 ComfyUI항목이 생성됩니다.
- 이제 클릭 한 번으로 브라우저(
http://localhost:8188)가 자동으로 열리며 ComfyUI가 실행됩니다. 이미지나 영상을 생성하면 그 결과물은 컨테이너가 꺼져도 내 로컬 폴더(~/ComfyUI/output)에 안전하게 저장됩니다.
6. TensorRT-LLM: 엔터프라이즈급 LLM 서빙 및 활용
마지막으로 DGX Spark의 진가를 발휘할 수 있는 TensorRT-LLM을 활용하여 gpt-oss:120b 같은 거대 언어 모델을 서빙해 봅니다.
1) 환경 준비 및 설치 검증
가장 무거운 작업이므로 사전 체크가 필수입니다.
필수 조건 확인 (Prerequisites): GPU가 Docker 컨테이너 내에서 정상적으로 인식되는지 확인합니다.
# GPU 드라이버 확인
nvidia-smi
# Docker GPU 런타임 확인
docker run --rm --gpus all nvcr.io/nvidia/tensorrt-llm/release:spark-single-gpu-dev nvidia-smi
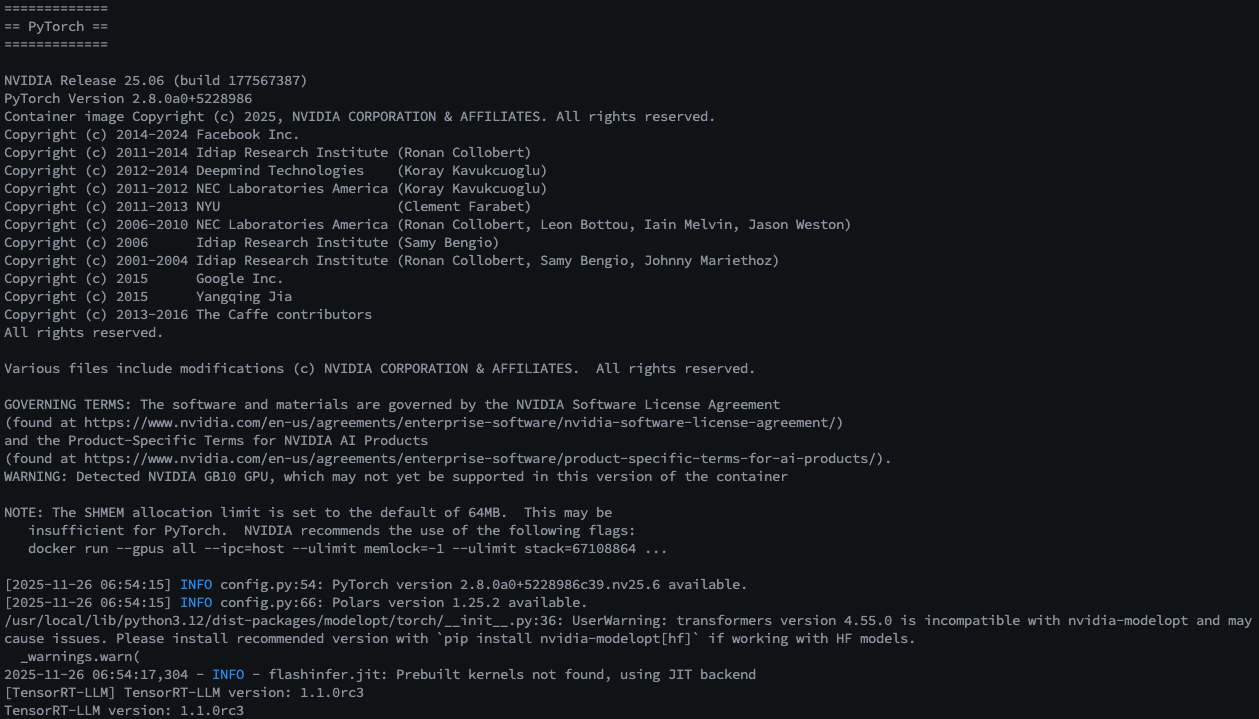
TensorRT-LLM 라이브러리 검증: 컨테이너 내부에서 Python 라이브러리가 정상적으로 로드되는지 테스트합니다.
docker run --rm -it --gpus all \
nvcr.io/nvidia/tensorrt-llm/release:spark-single-gpu-dev \
python -c "import tensorrt_llm; print(f'TensorRT-LLM version: {tensorrt_llm.__version__}')"
- 예상 출력:
TensorRT-LLM version: 1.1.0rc3등 버전 정보 표시
2) 모델 다운로드(Manual)
이 단계에서 모델 데이터(약 180~190GB)를 다운로드하게 됩니다. 시간이 오래 걸리므로 안정적인 네트워크 환경에서 진행하세요.
HuggingFace 토큰 설정: 모델 다운로드를 위해 토큰을 환경변수로 설정합니다.
export HF_TOKEN=<your-huggingface-token>
다운로드 및 텍스트 생성 테스트: quickstart_advanced.py를 실행하여 모델을 다운로드하고, 간단한 문장("Paris is great because")을 완성해 봅니다.
export MODEL_HANDLE="openai/gpt-oss-120b"
docker run \
-e MODEL_HANDLE=$MODEL_HANDLE \
-e HF_TOKEN=$HF_TOKEN \
-v $HOME/.cache/huggingface/:/root/.cache/huggingface/ \
--rm -it --ulimit memlock=-1 --ulimit stack=67108864 \
--gpus=all --ipc=host --network host \
nvcr.io/nvidia/tensorrt-llm/release:spark-single-gpu-dev \
bash -c '
# Tiktoken 파일 다운로드 (필수)
export TIKTOKEN_ENCODINGS_BASE="/tmp/harmony-reqs" && \
mkdir -p $TIKTOKEN_ENCODINGS_BASE && \
wget -P $TIKTOKEN_ENCODINGS_BASE https://openaipublic.blob.core.windows.net/encodings/o200k_base.tiktoken && \
wget -P $TIKTOKEN_ENCODINGS_BASE https://openaipublic.blob.core.windows.net/encodings/cl100k_base.tiktoken && \
# 모델 다운로드
hf download $MODEL_HANDLE && \
# 추론 테스트
python examples/llm-api/quickstart_advanced.py \
--model_dir $MODEL_HANDLE \
--prompt "Paris is great because" \
--max_tokens 64
'

성공적으로 문장이 생성되었다면 모델 준비는 끝났습니다.
3)(Optional) API 서버 구동 테스트 (trtllm-serve)
이제 이 모델을 OpenAI 호환 API 서버로 띄워봅니다.
export MODEL_HANDLE="openai/gpt-oss-120b"
docker run --name trtllm_llm_server --rm -it --gpus all --ipc host --network host \
-e HF_TOKEN="" \
-e MODEL_HANDLE="$MODEL_HANDLE" \
-e HF_HUB_OFFLINE=1 \
-v $HOME/.cache/huggingface/:/root/.cache/huggingface/ \
nvcr.io/nvidia/tensorrt-llm/release:spark-single-gpu-dev \
bash -c '
export TIKTOKEN_ENCODINGS_BASE="/tmp/harmony-reqs" && \
mkdir -p $TIKTOKEN_ENCODINGS_BASE && \
wget -P $TIKTOKEN_ENCODINGS_BASE https://openaipublic.blob.core.windows.net/encodings/o200k_base.tiktoken && \
wget -P $TIKTOKEN_ENCODINGS_BASE https://openaipublic.blob.core.windows.net/encodings/cl100k_base.tiktoken && \
# 메모리 최적화 설정 파일 생성
cat > /tmp/extra-llm-api-config.yml <<EOF
print_iter_log: false
kv_cache_config:
dtype: "auto"
free_gpu_memory_fraction: 0.9
cuda_graph_config:
enable_padding: true
disable_overlap_scheduler: true
EOF
# 서버 실행 (포트 8355)
trtllm-serve "$MODEL_HANDLE" \
--max_batch_size 64 \
--trust_remote_code \
--port 8355 \
--extra_llm_api_options /tmp/extra-llm-api-config.yml
'
성공 시 터미널에 서버 실행 로그가 표시됩니다.
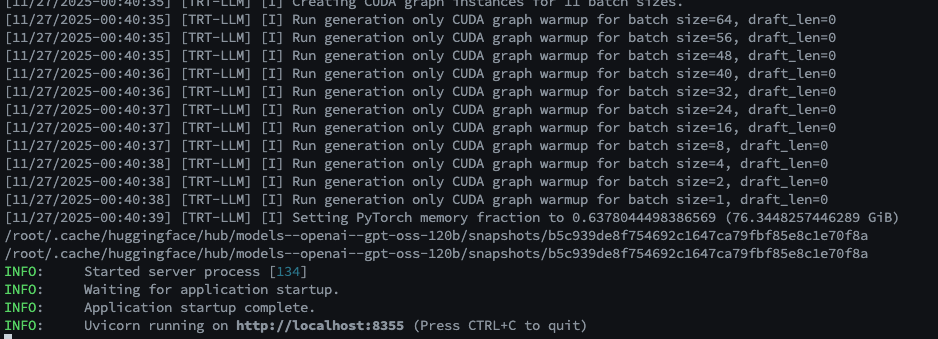
별도의 터미널에서 아래 명령어로 확인합니다.
curl -s http://localhost:8355/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{
"model": "openai/gpt-oss-120b",
"messages": [{"role": "user", "content": "Paris is great because"}],
"max_tokens": 64
}'

Ctrl+C로 종료 후 다음 단계로 넘어갑니다.
4) NVIDIA Sync로 서비스화 (Custom Script)
실행 스크립트 등록: NVIDIA Sync의 Custom 탭에서 +Add New를 클릭하고 다음 정보를 입력합니다.
- Name:
GPT-OSS 120B - Port:
8355 - Auto open in browser: ⬜ 체크 해제 (API 서버이므로 브라우저로 열 필요 없음)
- Launch Script: 아래 내용을 복사합니다. 이 스크립트는 '오프라인 모드' 로 작동합니다. (2단계에서 다운로드한 모델 캐시를 활용하여 부팅 속도를 높입니다.)
#!/usr/bin/env bash
set -euo pipefail
# --- 설정 변수 ---
NAME="trtllm-gpt-oss-120b"
IMAGE="nvcr.io/nvidia/tensorrt-llm/release:spark-single-gpu-dev"
MODEL_HANDLE="openai/gpt-oss-120b"
# 이미 다운로드 받았으므로 토큰은 비워둡니다.
MY_HF_TOKEN=""
cleanup() {
echo "Signal received; stopping ${NAME}..."
docker stop "${NAME}" >/dev/null 2>&1 || true
exit 0
}
trap cleanup INT TERM HUP QUIT EXIT
# Docker 데몬 확인
if ! docker info >/dev/null 2>&1; then
echo "Error: Docker daemon not reachable." >&2
exit 1
fi
# 기존 컨테이너 재설정
if [ -n "$(docker ps -aq --filter "name=^${NAME}$")" ]; then
echo "Removing old container to apply latest settings..."
docker stop "${NAME}" >/dev/null 2>&1 || true
docker rm "${NAME}" >/dev/null 2>&1 || true
fi
echo "Creating and starting ${NAME}..."
# --- 컨테이너 실행 ---
docker run -d \
--name "${NAME}" \
--gpus all \
--network host \
--ipc=host \
--ulimit memlock=-1 --ulimit stack=67108864 \
-e HF_TOKEN="${MY_HF_TOKEN}" \
-e MODEL_HANDLE="${MODEL_HANDLE}" \
-e HF_HUB_OFFLINE=1 \
-v $HOME/.cache/huggingface/:/root/.cache/huggingface/ \
"${IMAGE}" \
bash -c '
# Tiktoken 파일 다운로드
export TIKTOKEN_ENCODINGS_BASE="/tmp/harmony-reqs" && \
mkdir -p $TIKTOKEN_ENCODINGS_BASE && \
wget -P $TIKTOKEN_ENCODINGS_BASE https://openaipublic.blob.core.windows.net/encodings/o200k_base.tiktoken && \
wget -P $TIKTOKEN_ENCODINGS_BASE https://openaipublic.blob.core.windows.net/encodings/cl100k_base.tiktoken && \
# 성능 최적화 설정
cat > /tmp/extra-llm-api-config.yml <<EOF
print_iter_log: false
kv_cache_config:
dtype: "auto"
free_gpu_memory_fraction: 0.95
cuda_graph_config:
enable_padding: true
disable_overlap_scheduler: true
EOF
echo "Starting TRT-LLM Serve..."
trtllm-serve "$MODEL_HANDLE" \
--host 0.0.0.0 \
--port 8355 \
--max_batch_size 8 \
--max_num_tokens 32768 \
--trust_remote_code \
--extra_llm_api_options /tmp/extra-llm-api-config.yml
' >/dev/null
echo "Running TRT-LLM via NVIDIA Sync."
echo "Wait for model loading... Check logs with: docker logs -f ${NAME}"
echo "Running. Press Stop in Sync to end."
while :; do sleep 86400; done
※ 참고: 메모리 부족(OOM) 문제 해결 및 로딩 시간
1. 로딩 시간: 120B 모델은 파일 크기만 180GB가 넘습니다. 최초 실행 버튼을 누른 후 실제로 API가 응답하기까지 수 분 이상의 시간이 소요될 수 있습니다. (docker logs -f trtllm-gpt-oss-120b 명령어로 로그를 확인)
2. 메모리 부족(OOM) 해결: 막대한 VRAM을 사용하므로, 로그에 "Out of memory" 또는 **"CUDA Error: out of memory"**가 뜨면서 서버가 죽는 경우가 발생할 수 있습니다. 이 경우 위 스크립트(bash -c 내부)에서 다음 값들을 조절하여 메모리 사용량을 낮춰야 합니다.
--max_batch_size: 동시 처리 요청 수 (8 → 4 또는 2로 감소)--max_num_tokens: 최대 토큰 길이 (32768 → 16384 등으로 감소)free_gpu_memory_fraction: 할당 비율 (0.95 → 0.90 등으로 조절)
실행 및 확인: NVIDIA Sync 메뉴에서 GPT-OSS 120B를 클릭합니다. (API 서버이므로 별도의 창은 뜨지 않습니다.)
5) 실전 활용: 코딩 어시스턴트 & 문서 도구 연결
API 서버(http://localhost:8355/v1)가 준비되었다면 외부 도구와 연결해 생산성을 극대화할 수 있습니다.
사용예시 1. VS Code: Roo Code (AI 기반 코딩 지원 확장 프로그램)
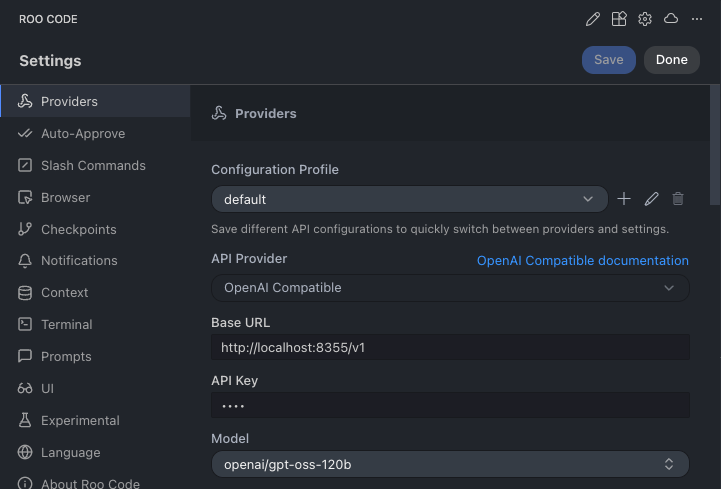
VS Code 확장 프로그램 'Roo Code' 설정의 Providers 탭에서 다음과 같이 입력합니다.
- API Provider:
OpenAI Compatible - Base URL:
http://localhost:8355/v1 - API Key:
sk-dummy(로컬 API 서버이므로 인증이 필요 없지만, 형식상 API 키를 요구하므로 임의의 값 입력) - Model:
openai/gpt-oss-120b - Context Window:
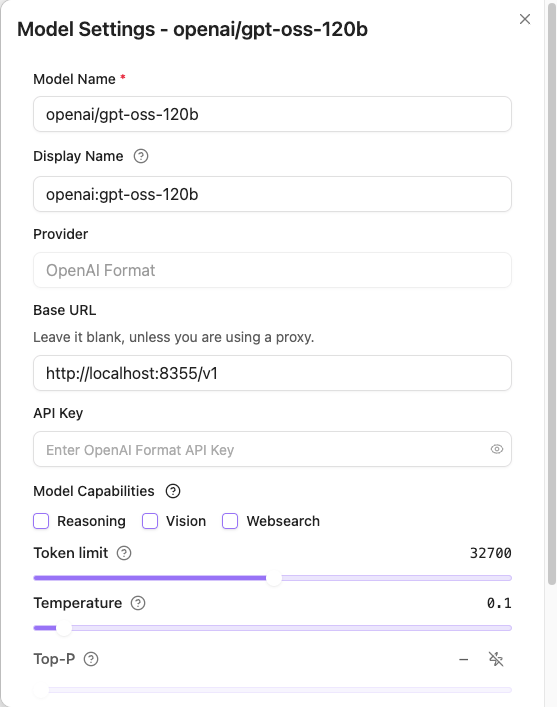
32768(스크립트 설정값)

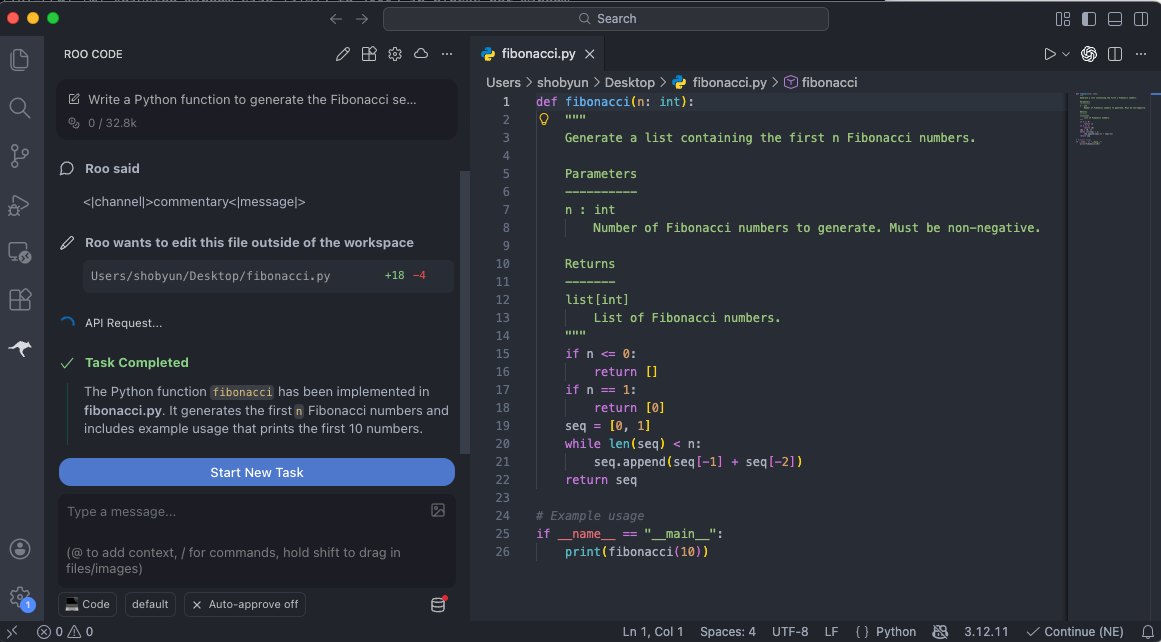
모델 설정이 완료되었다면 코딩 assistant로 활용할 수 있습니다.
사용예시 2. Obsidian: Copilot (지식 관리 assistant)
Obsidian Copilot 플러그인 설정의 Model 탭에서 + Add Model을 클릭 후 아래와 같이 입력합니다.
- Model Name:
openai/gpt-oss-120b - Provider:
OpenAI Format - Base URL:
http://localhost:8355/v1 - Advanced:
CORS활성화 체크
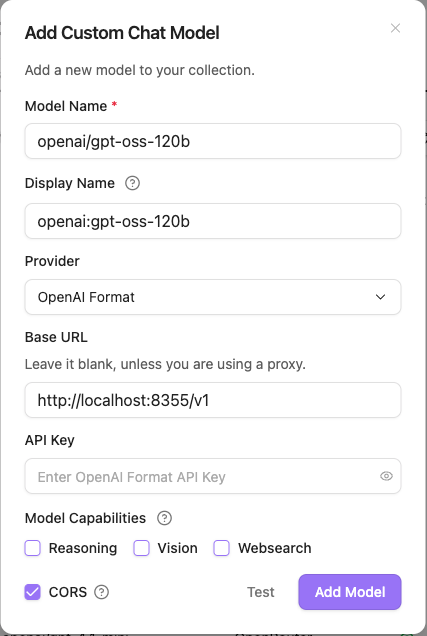
Add Model 버튼 클릭 후, Chat Models 목록에서 해당 모델의 Edit 버튼을 눌러 Token limit을 스크립트에서 설정한 값(32768)으로 맞춰줍니다.
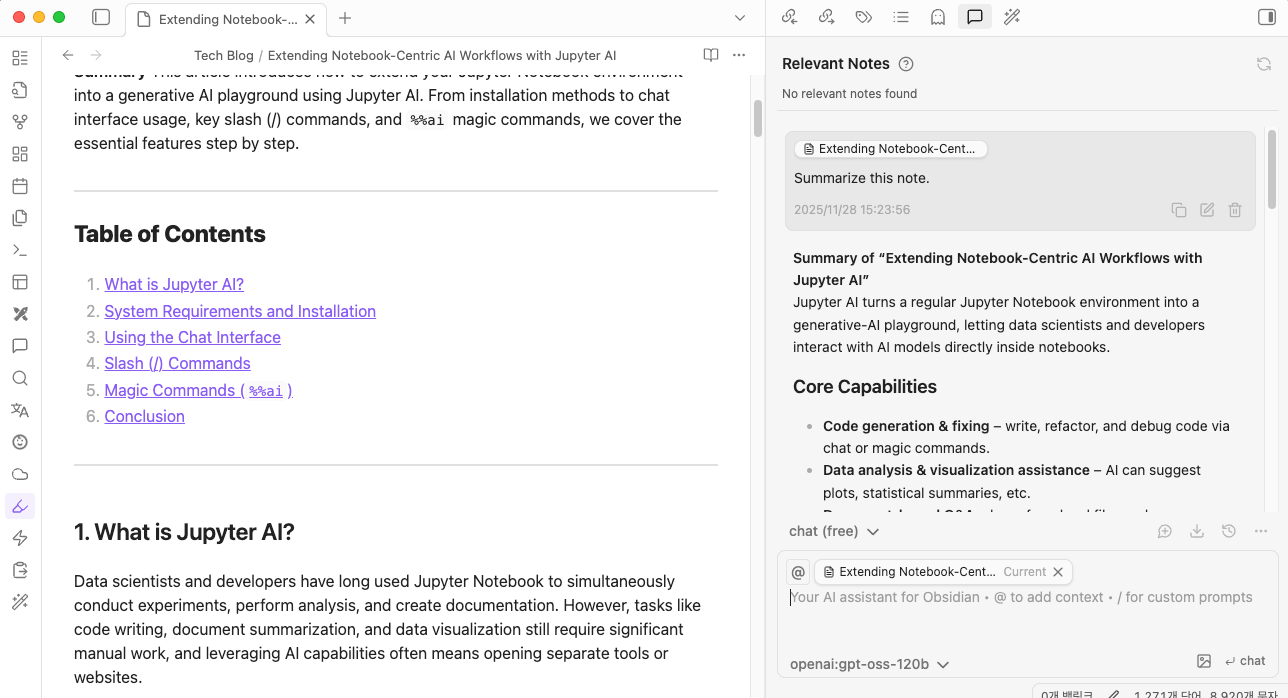
설정완료 후 내 노트를 외부 유출 걱정 없이 안전하게 AI에게 맡길 수 있습니다.
7. 마치며: 나만의 프라이빗 AI 클라우드 완성하기
이제 여러분의 DGX Spark는 단순한 고성능 워크스테이션을 넘어, 언제 어디서나 접속 가능한 프라이빗 AI 클라우드로 거듭났습니다.
이번 가이드를 통해 우리는 다음과 같은 강력한 환경을 구축했습니다.
- 경계 없는 연결: Tailscale을 통해 집, 사무실, 이동 중 어디서든 안전하게 내 장비에 접속할 수 있습니다.
- 편리한 관리: NVIDIA Sync의 Custom Script 기능을 활용하여, 복잡한 터미널 명령어 없이 클릭 한 번으로 서비스를 제어합니다.
- 다양한 워크로드:
- OpenWebUI: 가벼운 일상 대화와 정보 검색을 위한 챗봇
- ComfyUI: 무한한 창의력을 발휘하는 이미지 생성 스튜디오
- TensorRT-LLM: 엔터프라이즈급(120B+) 거대 언어 모델을 활용한 코딩 및 문서 작업
RAG(검색 증강 생성), AI 에이전트 등 더 깊이 있는 활용 사례가 궁금하다면 NVIDIA Spark Playbooks를 참고하여 여러분만의 워크플로우를 계속해서 확장해 나가시길 바랍니다.