
OLake PoC: Kafka 없이 구현하는 PostgreSQL → Apache Iceberg 실시간 CDC
Kafka 없이 PostgreSQL에서 Apache Iceberg로 직접 CDC를 수행하는 경량 도구 OLake를 로컬 Docker 환경에서 구축하고, Debezium과 비교하여 성능·안정성·사용 편의성을 테스트한 PoC 과정을 정리합니다.
들어가며
지난 블로그에서는 Kafka + Debezium Source Connector를 이용하여 PostgreSQL의 변경 데이터를 StarRocks에 동기화하는 CDC 파이프라인을 PAASUP DIP 환경에서 구축하였습니다. Debezium은 검증된 CDC 도구이지만, Kafka 클러스터와 Schema Registry 등 부수적인 인프라 운영 부담이 있습니다.
한편, 데이터 레이크하우스 아키텍처가 확산되면서 Apache Iceberg를 목적지로 하는 CDC 수요가 늘어나고 있습니다. 이 경우 Debezium은 Kafka → Iceberg Sink Connector라는 추가 경로가 필요한 반면, OLake는 Kafka 없이 소스 DB에서 Iceberg로 직접 데이터를 전송하는 "Lakehouse First" 경량 CDC 도구입니다.
이번 블로그에서는 OLake를 사용하여 PostgreSQL → Apache Iceberg CDC 파이프라인을 로컬 Docker 환경에서 구축하고, 성능·안정성·사용 편의성 측면에서 테스트한 과정을 정리하였습니다. 이 테스트는 OLake를 DIP 카탈로그에 포함할지 결정하기 위한 PoC의 일환입니다.
목차
- Debezium vs. OLake
- OLake 아키텍처
- 인프라 구성
- 테스트 데이터 source_postgresql에 적재
- OLake CDC 파이프라인 설정
- Iceberg 테이블 조회
- OLake CDC 메타데이터 구조
- Iceberg 테이블의 CDC 컬럼
- 테스트 결과
- 결론
1. Debezium vs. OLake
이전 블로그에서 사용한 Debezium과 이번에 테스트하는 OLake는 같은 CDC 도구이지만, 설계 철학과 아키텍처가 근본적으로 다릅니다.
설계 철학
- OLake — "Lakehouse First"를 지향합니다. 복잡한 Kafka 인프라 없이 소스 DB에서 Apache Iceberg와 같은 데이터 레이크하우스로 직접, 그리고 가장 빠르게 데이터를 밀어넣는 데 최적화되어 있습니다.
- Debezium — "Event-Driven"을 지향합니다. DB의 변경 사항을 '이벤트'로 간주하여 Kafka로 스트리밍하며, 이를 통해 다양한 하위 시스템(검색 엔진, 캐시, 타 DB 등)이 해당 이벤트를 구독하게 하는 범용 CDC 프레임워크입니다.
아키텍처 비교
| 특징 | OLake | Debezium |
|---|---|---|
| 기본 구조 | 단일 실행 바이너리/컨테이너 기반. 별도의 메시지 큐 없이 소스 DB에서 목적지로 직접 연결 | Kafka 생태계 기반 (Kafka, Zookeeper, Kafka Connect 필요) |
| 데이터 흐름 | DB → OLake → S3 (Iceberg/Parquet) | DB → Debezium → Kafka → Sink Connector → 목적지 |
| 상태 관리 | 로컬 또는 지정된 스토리지에 체크포인트 저장 | Kafka 내부 토픽(offsets, config, status)에 상태 저장 |
| 확장 방식 | 수평 확장 가능하나 구조가 단순함 | Kafka Connect 클러스터의 워커 노드 확장을 통한 분산 처리 |
장단점 비교
| 구분 | OLake | Debezium |
|---|---|---|
| 장점 | - Kafka를 거치지 않아 대량 데이터 로드 시 4~10배 빠름 | - 목적지가 Lakehouse가 아니더라도 거의 모든 곳으로 데이터 전송 가능 |
| - Zookeeper/Kafka 관리가 필요 없어 운영 부담 적음 | - 이미 Kafka를 사용 중인 조직에 친숙하고 강력한 커뮤니티 지원 | |
| - 스키마 진화(Schema Evolution) 및 Iceberg 최적화 자동 지원 | - SMT(Single Message Transforms)를 통한 메시지 단위 변환 | |
| - 인프라 리소스 소모가 적어 클라우드 비용 절감 | - 수많은 엔터프라이즈 환경에서 레퍼런스 확보 | |
| 단점 | - 현재 Apache Iceberg 등 데이터 레이크하우스 타겟에 집중 | - Kafka 운영 전문 지식(Java, JVM 튜닝, 분산 시스템 이해) 필수 |
| - Debezium에 비해 커뮤니티 규모나 레퍼런스가 상대적으로 적음 | - Kafka 저장 단계에서 지연 발생 가능, 대량 Snapshot 시 성능 저하 | |
| - 커넥터 설정 및 스키마 레지스트리 관리가 까다로움 |
언제 무엇을 선택할까?
- OLake — 주요 목적이 운영 DB 데이터를 S3/Iceberg 레이크하우스로 빠르게 옮겨 분석하는 것일 때, Kafka 인프라를 구축하거나 운영할 인력/시간이 부족할 때, 초기 전체 로딩(Full Load) 성능이 중요할 때 적합합니다.
- Debezium — 마이크로서비스(MSA) 간 이벤트 전송이나 실시간 검색 인덱싱에 활용해야 할 때, 이미 사내에 안정적인 Kafka 클러스터가 운영되고 있을 때, 다양한 소스와 목적지를 연결해야 하는 범용 CDC가 필요할 때 적합합니다.
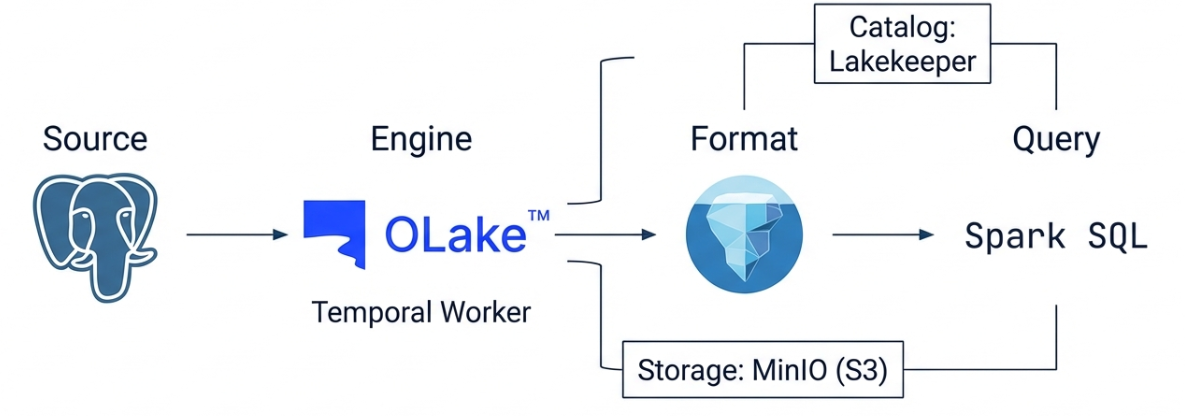
2. OLake 아키텍처
PostgreSQL (Source)
│ WAL (Logical Replication)
▼
OLake Worker (CDC Connector)
│ olakego/source-postgres → olake-iceberg-java-writer
▼
Lakekeeper (REST Catalog)
│
▼
Iceberg (MinIO, S3-compatible Storage)
OLake는 Temporal 기반의 워크플로 엔진 위에서 동작하며, PostgreSQL의 WAL(Write-Ahead Log)을 읽어 Iceberg 테이블로 변환하고, Iceberg의 REST Catalog으로는 Lakekeeper를, Object Storage로는 MinIO를 사용합니다.
3. 인프라 구성
모든 서비스는 Docker 컨테이너로 구성하며, olake-network 브리지 네트워크로 연결합니다.
서비스 구성
| 서비스 | 컨테이너명 | 포트 | 역할 |
|---|---|---|---|
| OLake UI | olake-ui |
8000 | CDC 파이프라인 관리 웹 UI |
| OLake Worker | olake-temporal-worker |
— | CDC Sync 실행 엔진 |
| Temporal | temporal |
— | 워크플로 오케스트레이션 |
| Temporal PostgreSQL | temporal-postgresql |
— | Temporal + OLake 메타데이터 저장소 |
| Source PostgreSQL | source-postgresql |
5432 | CDC 소스 데이터베이스 |
| MinIO | minio |
9000 / 9001 | S3 호환 Object Storage |
| Lakekeeper | lakekeeper |
8181 | Iceberg REST Catalog |
OLake 설치
OLake는 공식 one-liner 스크립트로 설치합니다. Temporal, Worker, UI, PostgreSQL, Elasticsearch가 함께 배포됩니다.
curl -sfL https://olake.dev/install | sh
Source PostgreSQL 설치 및 CDC 설정
OLake와 별도로 소스 데이터베이스용 PostgreSQL 컨테이너를 생성합니다.
docker run -d \
--name source-postgresql \
-e POSTGRES_USER=admin \
-e POSTGRES_PASSWORD=password \
-e POSTGRES_DB=mydb \
-p 5432:5432 \
postgres:16
CDC를 위해 Logical Replication을 활성화합니다.
-- postgresql.conf 변경 후 재시작
ALTER SYSTEM SET wal_level = 'logical';
-- Replication Slot 및 Publication 생성
SELECT pg_create_logical_replication_slot('olake_slot', 'pgoutput');
CREATE PUBLICATION olake_pub FOR ALL TABLES;
MinIO 설치 및 버킷 생성
docker run -d \
--name minio \
-e MINIO_ROOT_USER=admin \
-e MINIO_ROOT_PASSWORD=password \
-p 9000:9000 -p 9001:9001 \
minio/minio server /data --console-address ":9001"
MinIO Console(http://localhost:9001)에서 iceberg 버킷을 생성합니다.
Lakekeeper 설치
Lakekeeper는 Iceberg REST Catalog 구현체로, MinIO를 스토리지 백엔드로 사용합니다.
docker run -d \
--name lakekeeper \
-p 8181:8181 \
-e LAKEKEEPER__LISTEN_PORT=8181 \
-e LAKEKEEPER__BASE_URI=http://host.docker.internal:8181 \
lakekeeper/catalog:latest
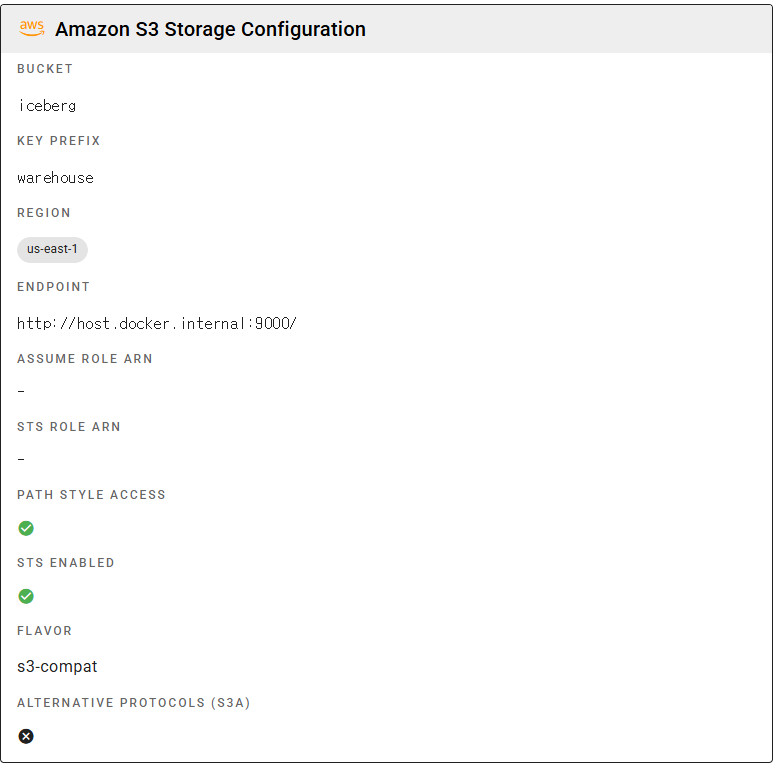
설치 후 iceberg warehouse를 생성합니다.
Lakekeeper UI(http://localhost:8181)에서도 생성이 가능합니다.
# Warehouse 생성 (S3 경로: s3://iceberg/warehouse/)
curl -X POST http://localhost:8181/management/v1/warehouse \
-H "Content-Type: application/json" \
-d '{
"warehouse-name": "iceberg",
"storage-profile": {
"type": "s3",
"bucket": "iceberg",
"endpoint": "http://host.docker.internal:9000",
"path-style-access": true,
"region": "us-east-1",
"sts-enabled": true
},
"storage-credential": {
"type": "s3",
"credential-type": "access-key",
"aws-access-key-id": "admin",
"aws-secret-access-key": "password"
}
}'
Docker 네트워크 연결
모든 서비스를 olake-network에 연결하여 컨테이너 간 통신이 가능하도록 합니다.
docker network connect olake-network source-postgresql
docker network connect olake-network minio
docker network connect olake-network lakekeeper
4. 테스트 데이터 source_postgresql에 적재
CDC 파이프라인 테스트를 위해 3종류의 데이터를 Source PostgreSQL에 적재합니다.
데이터셋 요약
| 테이블 | 건수 | 설명 | Primary Key |
|---|---|---|---|
card_subway_month |
36,406건 | 서울 지하철 월별 승하차 데이터 | line_name, station_name, use_date |
who_covid19 |
514,560건 | WHO COVID-19 국가별 일일 현황 | date_reported, country_code |
orders |
10,000,000건 | 테스트용 주문 데이터 | order_id |
지하철 데이터 적재
import pandas as pd
from sqlalchemy import create_engine
engine = create_engine('postgresql://admin:password@localhost:5432/mydb')
for file in ['CARD_SUBWAY_MONTH_202501.csv', 'CARD_SUBWAY_MONTH_202502.csv']:
df = pd.read_csv(file, encoding='euc-kr')
# 한글 컬럼명을 영문으로 변환 (Iceberg 호환)
df.columns = ['use_date', 'line_name', 'station_name',
'ride_count', 'alight_count']
df.to_sql('card_subway_month', engine, if_exists='append', index=False)
참고: OLake의 Iceberg Writer는 비ASCII 컬럼명을
_로 치환하므로, 한글 컬럼명을 사용하면 모든 컬럼이______으로 변환되어 스키마 충돌이 발생하기 때문에 반드시 영문 컬럼명을 사용해야 합니다.
WHO COVID-19 데이터 적재
51만 건의 데이터를 10만 건씩 청크 처리하여 적재합니다.
for chunk in pd.read_csv('WHO-COVID-19-global-daily-data.csv', chunksize=100_000):
chunk.to_sql('who_covid19', engine, if_exists='append', index=False)
orders 테스트 데이터 적재
1천만 건의 주문 데이터를 10만 건씩 청크 처리하여 적재합니다.
for chunk in pd.read_csv('orders_10M.csv', chunksize=100_000):
chunk.to_sql('orders', engine, if_exists='append', index=False)
5. OLake CDC 파이프라인 설정
OLake UI(http://localhost:8000)에서 Source, Destination, Job을 설정합니다.
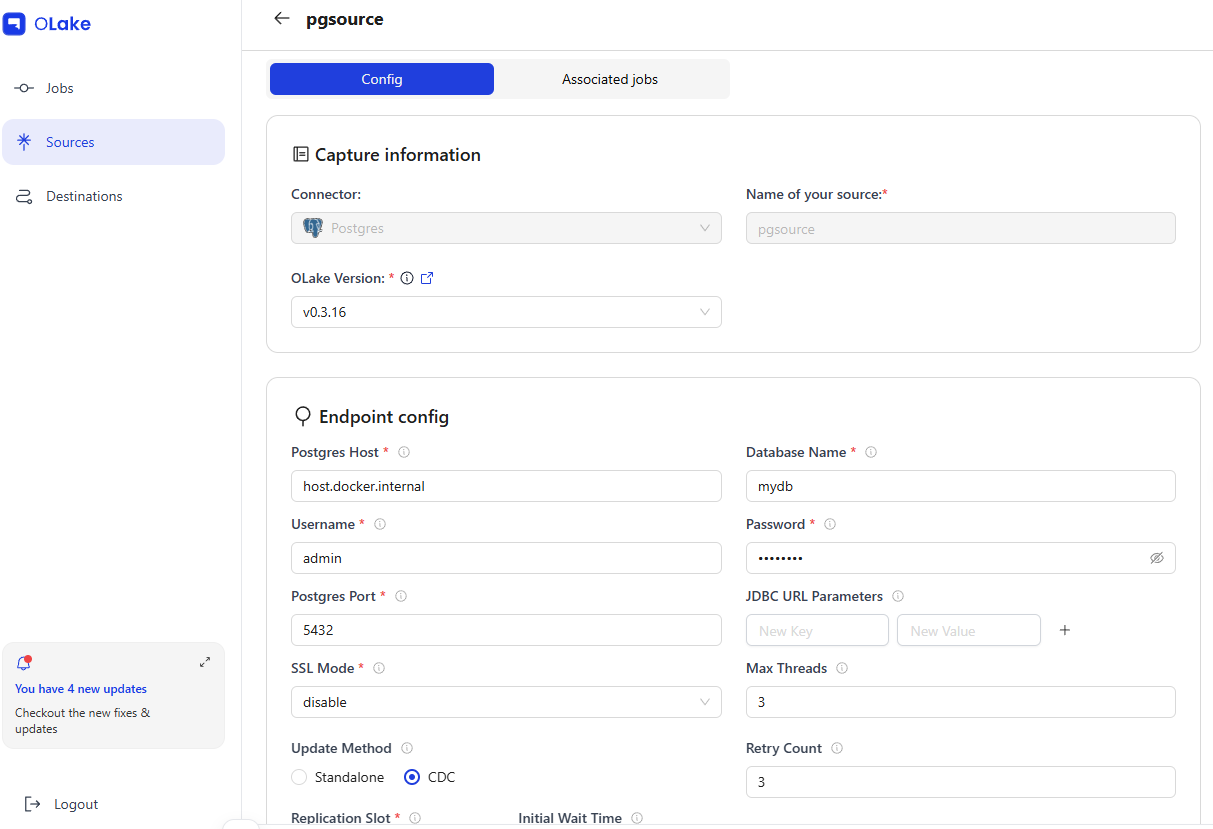
5-1. Source 등록
| 항목 | 값 |
|---|---|
| 이름 | pgsource |
| 타입 | postgres |
| 호스트 | host.docker.internal:5432 |
| 데이터베이스 | mydb |
| Update Method | CDC (olake_pub / olake_slot) |
OLake UI에서 Source를 등록하면 olakego/source-postgres:v0.3.16 이미지를 사용하여 연결 테스트(CHECK)와 스키마 탐색(DISCOVER)을 수행합니다.
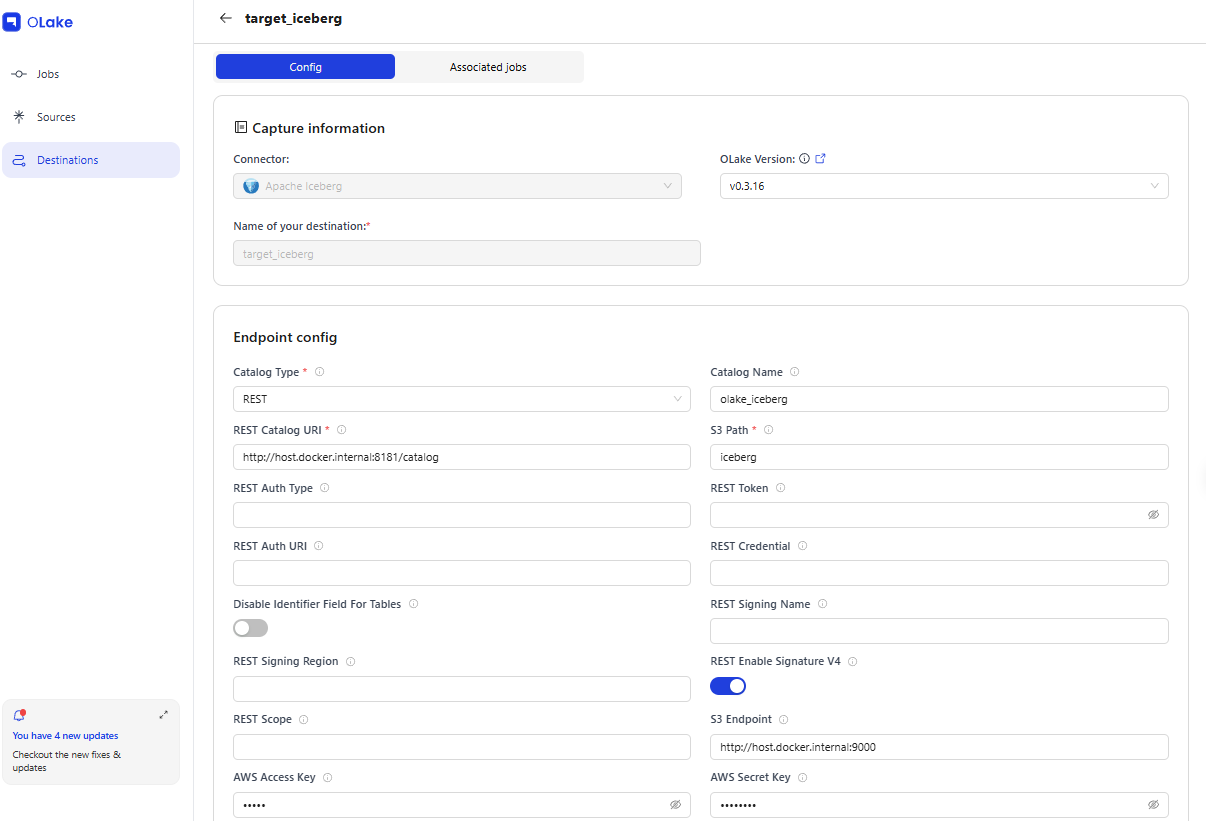
5-2. Destination 등록
| 항목 | 값 |
|---|---|
| 이름 | target_iceberg |
| 타입 | iceberg (REST Catalog) |
| REST Catalog URL | http://host.docker.internal:8181/catalog |
| S3 Endpoint | http://host.docker.internal:9000 |
| Catalog Name | olake_iceberg |
| S3 Path | iceberg |
5-3. CDC Job 생성
Source와 Destination을 연결하고, 동기화할 스트림(테이블)을 선택하여 Job을 생성합니다.
이때, 테이블 별로 Ingestion Mode (Upsert/Append)를 선택할수 있습니다.
Olake에는 Data Filter 기능도 포함되어 있습니다.
| 항목 | 값 |
|---|---|
| Job 이름 | cdc_test |
| Source | pgsource |
| Destination | target_iceberg |
| 실행 주기 | * * * * * (매분) |
| Sync Mode | Full Refresh(초기적재) + CDC |
| Ingestion Mode | Upsert |
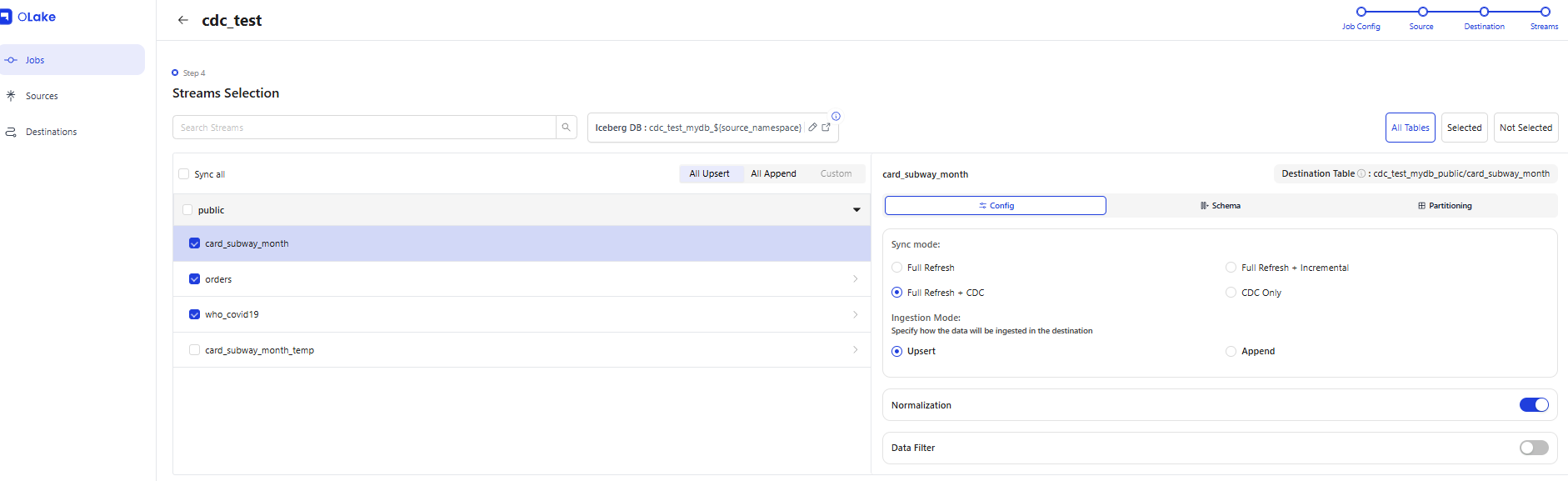
선택 스트림
| 스트림 | Primary Key | Iceberg Table |
|---|---|---|
public.orders |
order_id |
cdc_test_mydb:public.orders |
public.card_subway_month |
line_name, station_name, use_date |
cdc_test_mydb:public.card_subway_month |
public.who_covid19 |
date_reported, country_code |
cdc_test_mydb:public.who_covid19 |
Job을 생성하면 OLake Worker가 Temporal 워크플로를 통해 매분 CDC Sync를 실행합니다. 각 Sync는 Docker 컨테이너(olakego/source-postgres)를 생성하여 PostgreSQL WAL을 읽고, Iceberg Java Writer(olake-iceberg-java-writer.jar)를 통해 Iceberg 테이블에 기록합니다.
CDC 동작 원리
1. OLake Worker → Temporal Workflow 실행 (매분 cron)
2. Docker 컨테이너 생성 (olakego/source-postgres:v0.3.16)
3. PostgreSQL Logical Replication Slot (olake_slot) 에서 WAL 읽기
4. 변경 레코드를 gRPC로 Iceberg Java Writer에 전달
5. Iceberg Writer → Lakekeeper REST Catalog API로 테이블 커밋
6. 데이터 파일 → MinIO S3에 Parquet로 저장
7. State(LSN) 저장 → 다음 Sync 시 이어서 처리
CDC State는 PostgreSQL의 LSN(Log Sequence Number) 기반으로 관리되며, 동기화 상태를 추적합니다.
{
"type": "STREAM",
"global": {
"state": { "lsn": "0/9AE53D30" },
"streams": ["public.who_covid19", "public.orders", "public.card_subway_month"]
}
}
6. Iceberg 테이블 조회
Docker Compose로 Spark + Jupyter 환경을 구성합니다.
# docker-compose.spark.yml
services:
spark-iceberg:
image: tabulario/spark-iceberg
ports:
- "8888:8888" # Jupyter
- "8080:8080" # Spark UI
environment:
AWS_ACCESS_KEY_ID: admin
AWS_SECRET_ACCESS_KEY: password
AWS_REGION: us-east-1
Spark에서 Lakekeeper 카탈로그를 연결하여 조회합니다.
from pyspark.sql import SparkSession
# 기존 세션 종료 (tabulario 이미지의 demo 세션 충돌 방지)
existing = SparkSession.getActiveSession()
if existing:
existing.stop()
spark = SparkSession.builder \
.appName("iceberg-reader") \
.config("spark.sql.defaultCatalog", "lakekeeper") \
.config("spark.sql.catalog.lakekeeper", "org.apache.iceberg.spark.SparkCatalog") \
.config("spark.sql.catalog.lakekeeper.type", "rest") \
.config("spark.sql.catalog.lakekeeper.uri", "http://host.docker.internal:8181/catalog") \
.config("spark.sql.catalog.lakekeeper.warehouse", "iceberg") \
.config("spark.sql.catalog.lakekeeper.io-impl", "org.apache.iceberg.aws.s3.S3FileIO") \
.config("spark.sql.catalog.lakekeeper.s3.endpoint", "http://host.docker.internal:9000") \
.config("spark.sql.catalog.lakekeeper.s3.access-key-id", "admin") \
.config("spark.sql.catalog.lakekeeper.s3.secret-access-key", "password") \
.config("spark.sql.catalog.lakekeeper.s3.path-style-access", "true") \
.getOrCreate()
# CDC로 동기화된 데이터 조회
table_name = "orders"
df = spark.table(f"""lakekeeper.cdc_test_mydb_public.{table_name}""")
total = df.count()
print(f"✓ 총 {total:,}건")
print()
df.printSchema()
df.show(10, truncate=False)
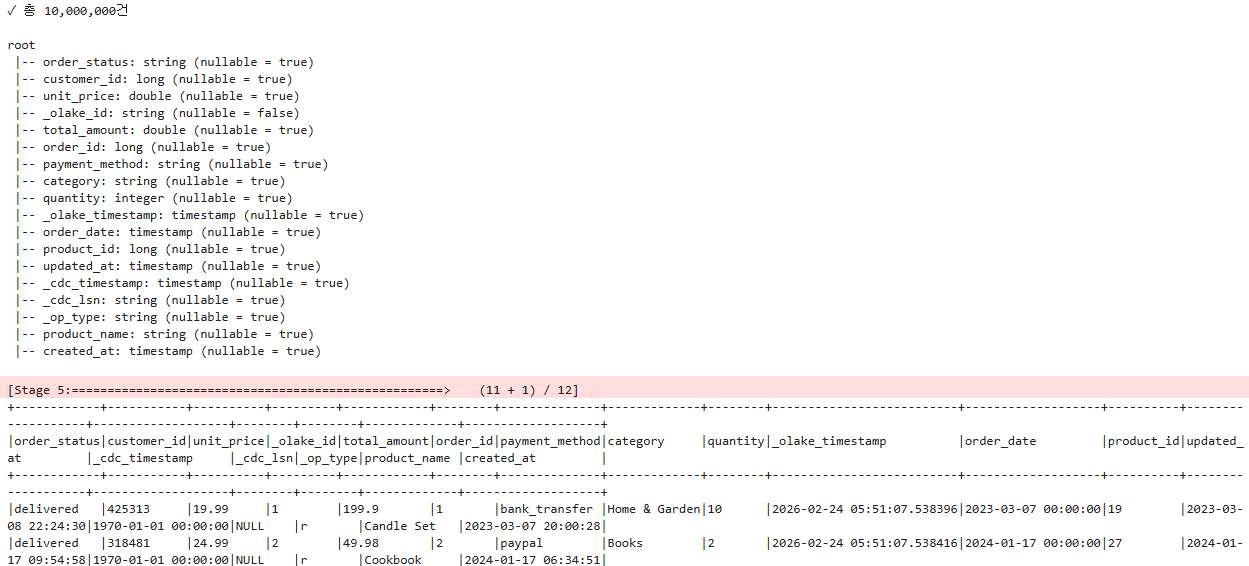
7. OLake CDC 메타데이터 구조
OLake는 temporal-postgresql 컨테이너의 postgres 데이터베이스에 메타데이터를 저장합니다.
| 테이블 | 역할 |
|---|---|
olake-dev-source |
Source 연결 정보 (호스트, DB, CDC 설정) |
olake-dev-destination |
Destination 연결 정보 (Catalog URL, S3 경로) |
olake-dev-job |
Job 정의 (스트림 선택, 실행 주기, CDC State) |
olake-dev-catalog |
사용 가능한 Source/Destination 타입 |
CDC State의 lsn 값은 PostgreSQL WAL의 위치를 나타내며, OLake가 각 Sync 완료 후 Job State에 업데이트합니다. 다음 Sync 시 이 LSN부터 변경분만 읽어 처리하는 방식으로 증분 동기화를 구현합니다.
8. Iceberg 테이블의 CDC 컬럼
OLake가 생성하는 Iceberg 테이블에는 원본 데이터 외에 CDC 메타데이터 컬럼이 추가됩니다.
| 컬럼 | 타입 | 설명 |
|---|---|---|
_cdc_timestamp |
timestamptz |
원본 DB에서 변경이 발생한 시각 |
_olake_timestamp |
timestamptz |
OLake가 레코드를 처리한 시각 |
_op_type |
string |
변경 유형: r(read/초기), c(insert), u(update), d(delete) |
_olake_id |
string |
OLake 내부 고유 ID (equality delete 키) |
DELETE 연산은 equality delete 파일로 기록되며, _olake_id 기준으로 삭제 대상을 식별합니다. Spark SQL에서 삭제된 레코드를 제외하려면 WHERE _op_type != 'd' 조건을 사용합니다.
9. 테스트 결과
성능
-
초기 전체 로딩(Full Load): 리소스가 적은 윈도우 환경임에도 1천만 건 이상의 데이터를 PostgreSQL에서 Iceberg로 초기 동기화할 때 경과시간이 162초의 빠른 성능을 보였습니다.
10,552,212 Records / 162 Seconds = 65,137 RPS(Records Per Seconds)
job log - sync start

**job log - sync completed **
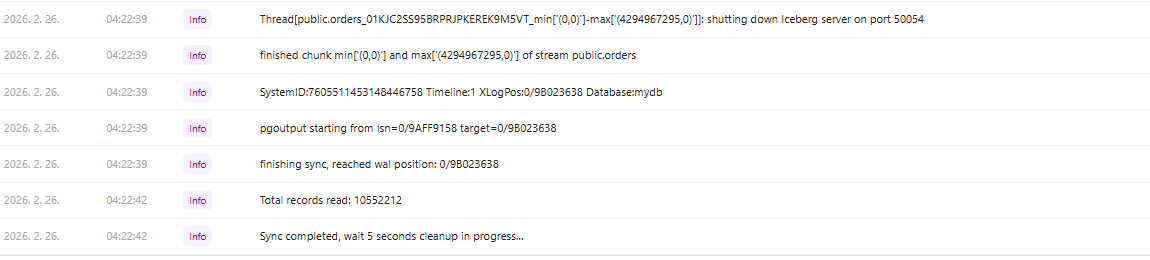
-
증분 동기화(CDC): 매분 Sync 주기로 설정 시, WAL에 변경이 없으면 빠르게 완료되고, 변경분만 처리하므로 리소스 소모가 적었습니다.
-
대량 데이터 처리: 51만 건(
who_covid19), 1천만 건(orders) 규모의 테이블 모두 초기 로딩 후 정상적으로 CDC 동기화가 유지되었습니다. -
Sync 컨테이너 오버헤드: 매 Sync마다 Docker 컨테이너를 생성/삭제하는 구조로, 변경이 없는 구간에서도 컨테이너 생성 비용이 발생합니다. 대규모 운영 시 Sync 주기 조정이 필요합니다.
사용자 편의성
- 설정 간소화: OLake UI에서 Source → Destination → Job 3단계만으로 CDC 파이프라인을 구성할 수 있어, Debezium의 Kafka Connect JSON 설정 대비 진입 장벽이 낮았습니다.
- 연결 테스트 내장: Source/Destination 등록 시 UI에서 바로 연결 테스트를 수행할 수 있어, 설정 오류를 사전에 확인할 수 있었습니다.
- 스트림 자동 탐색: Discover 기능으로 PostgreSQL의 테이블 목록을 자동 조회하여 선택할 수 있으므로, 수동으로 테이블 정보를 입력할 필요가 없었습니다.
안정성
- 비ASCII 컬럼명 미지원: 한글 등 비ASCII 컬럼명이 Iceberg Writer에서
_로 치환되어 스키마 충돌이 발생합니다. 소스 DB의 컬럼명을 영문으로 사전 변환해야 합니다. - 장기 운영 안정성: 수일간(4일) CDC를 지속 실행한 결과,
card_subway_month스트림은 535회 이상의 Sync를 안정적으로 수행했습니다.
10. 결론
OLake를 사용하면 PostgreSQL에서 Apache Iceberg로의 CDC 파이프라인을 코드 없이 구성할 수 있습니다. OLake UI에서 Source/Destination/Job을 등록하면, Temporal 워크플로가 자동으로 주기적 동기화를 수행합니다.
| 구성요소 | 선택 | 역할 |
|---|---|---|
| CDC Source | PostgreSQL + Logical Replication | WAL 기반 변경 캡처 |
| CDC Engine | OLake (Temporal Worker) | 변경 데이터 추출 및 전달 |
| Table Format | Apache Iceberg | ACID 트랜잭션, 스키마 진화, 타임 트래블 |
| REST Catalog | Lakekeeper | Iceberg 테이블 메타데이터 관리 |
| Object Storage | MinIO | Parquet 데이터 파일 저장 |
| Query Engine | Spark SQL | Iceberg 테이블 조회 |
Kafka 기반 Debezium 대비 인프라 구성이 간소하고 초기 설정이 쉬운 반면, 모니터링 기능이 부족하고 비ASCII 컬럼명 미지원 등 아직 성숙도가 부족한 부분도 있습니다. Lakehouse 중심의 데이터 파이프라인을 빠르게 구축해야 하는 경우 좋은 선택지가 될 수 있습니다.