
PostgreSQL에서 StarRocks로 CDC 구현 예제
PostgreSQL에서 StarRocks로의 실시간 CDC 파이프라인 구축 사례입니다. Debezium과 Kafka를 활용하여 초당 4,000건 이상의 데이터를 안정적으로 복제하고, Apache Superset으로 시각화했습니다. StarRocks의 MPP 아키텍처를 통해 분석 쿼리 성능이 대폭 향상되었으며, 확장 가능한 데이터 파이프라인 아키텍처를 구현했습니다.

목차
- 개요
- Source DB (PostgreSQL) 구성
- Kafka Topic 생성
- Target DB (StarRocks) 구성
- Kafka Connector 생성
- 검증 및 테스트
- BI 구현
- 결론
개요
구현 목표
PostgreSQL(Source DB)에서 StarRocks(Target DB)로의 안정적이고 고성능 CDC(Change Data Capture) 파이프라인을 구축합니다. Debezium과 Kafka를 활용하여 실시간 데이터 복제 시스템을 구현하고, Apache Superset을 통해 복제된 데이터를 분석 및 시각화합니다.
구현 아키텍처
PAASUP DIP(Data Intelligence Platform) 환경에서 Debezium CDC를 활용한 실시간 데이터 복제 아키텍처를 구현합니다. PostgreSQL의 변경 데이터는 Debezium을 통해 Kafka Topic으로 전송되고, StarRocks Sink Connector를 거쳐 최종적으로 S3 기반 StarRocks에 저장됩니다. 복제된 데이터는 Apache Superset 대시보드를 통해 시각화됩니다.
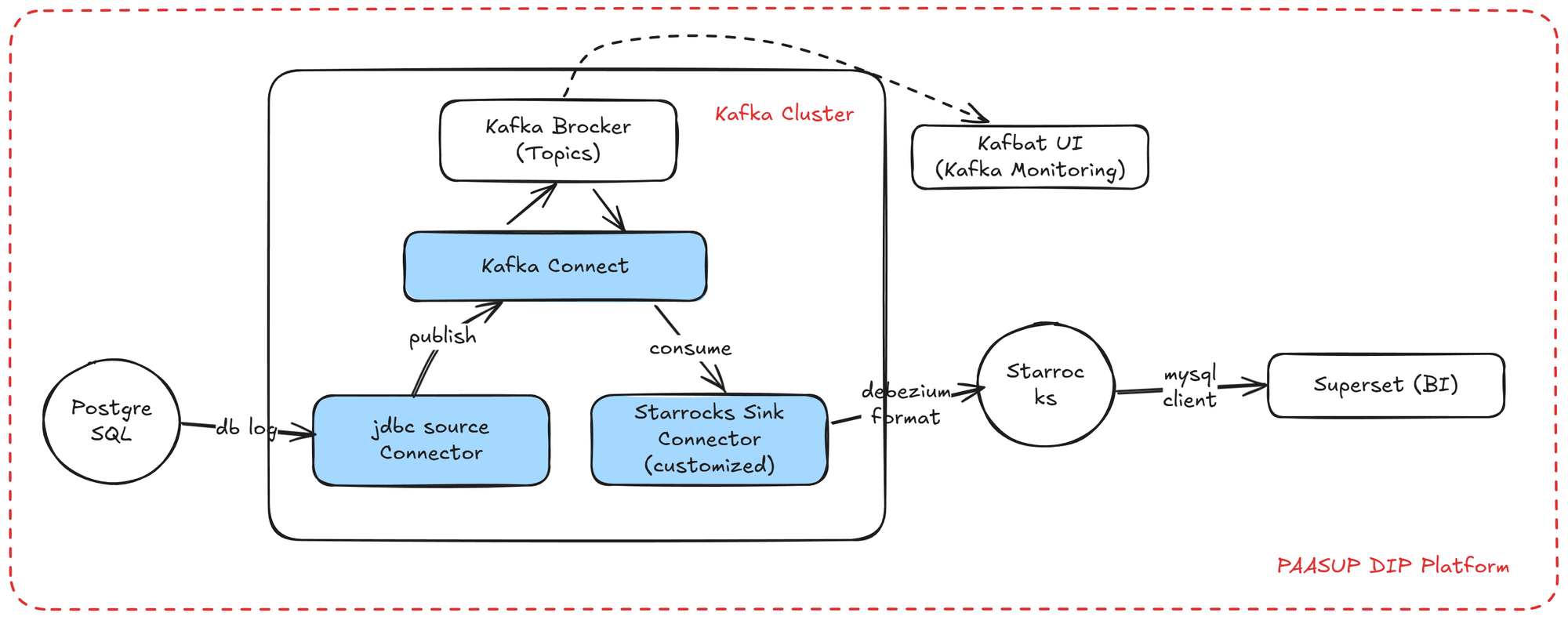
구현 환경
PAASUP DIP에서 다음과 같은 기술 스택으로 구현합니다.
| 구성요소 | 기술 스택 |
|---|---|
| Source DB | PostgreSQL 15.4 |
| Target DB | StarRocks 3.5.5 |
| 메시지 브로커 | Kafka Cluster 4.0.0 |
| Kafka Connectors | Debezium PostgreSQL Connector 2.6.0 StarRocks Sink Connector 1.0.2 커스터마이징 |
| 모니터링 | Kafbat UI 1.3.0 |
| BI 도구 | Apache Superset 4.1.1 |
본문에서는 Kafka와 관련된 카탈로그 생성에 대한 설명을 포함하지만, PostgreSQL, StarRocks, Superset 카탈로그 생성에 대한 설명은 이전 블로그를 참조하시면 됩니다.
Source DB (PostgreSQL) 구성
데이터베이스 설정 확인
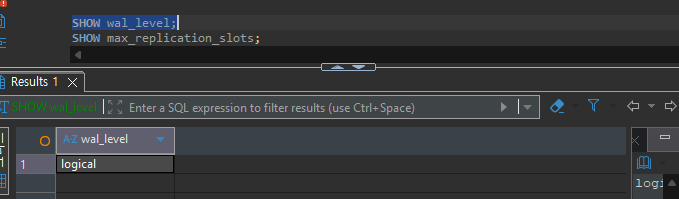
Debezium CDC는 PostgreSQL의 논리적 복제(Logical Replication) 기능을 활용합니다. 이를 위해 WAL(Write-Ahead Log) 레벨이 logical로 설정되어 있어야 합니다.
-- WAL 레벨 확인
SHOW wal_level;
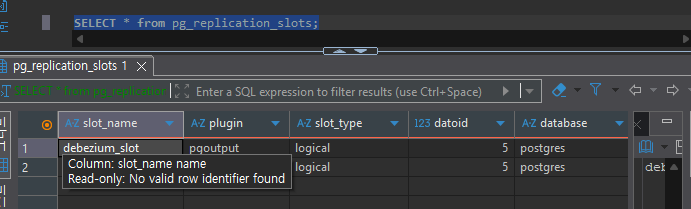
다음으로 Replication Slot을 확인합니다. Replication Slot은 CDC 클라이언트가 데이터를 읽는 동안 해당 WAL 파일이 삭제되지 않도록 보장하는 PostgreSQL의 메커니즘입니다.
-- 최대 복제 슬롯 확인
SHOW max_replication_slots;
-- 현재 생성된 슬롯 확인
SELECT * FROM pg_replication_slots;
테스트 데이터 준비
CDC 테스트를 위해 서울시 지하철 운영 데이터를 활용합니다. 다음 세 개의 테이블 복사본을 생성합니다.
subway_info_copy(768 rows) - 지하철역 기본 정보subway_passengers_copy(2,225,784 rows) - 일별 승하차 인원 데이터subway_passengers_time_copy(1,778,618 rows) - 시간대별 승하차 인원 데이터
Source 테이블 생성
중요: Debezium CDC를 통해 UPDATE 및 DELETE 작업을 정확히 복제하려면 소스 테이블에 Primary Key가 반드시 정의되어야 합니다.
-- 승객 정보 테이블
CREATE TABLE public.subway_passengers_copy (
use_date varchar(8) NOT NULL,
line_no varchar(100) NOT NULL,
station_name varchar(100) NOT NULL,
pass_in numeric(13) NULL,
pass_out numeric(13) NULL,
reg_date varchar(8) NULL,
PRIMARY KEY (use_date, line_no, station_name)
);
-- 지하철 정보 테이블
CREATE TABLE public.subway_info_copy (
line_no varchar(100) NOT NULL,
station_name varchar(100) NOT NULL,
station_cd varchar(10) NULL,
station_cd_external varchar(10) NULL,
station_ename varchar(100) NULL,
station_cname varchar(100) NULL,
station_jname varchar(100) NULL,
PRIMARY KEY (line_no, station_name)
);
-- 시간대별 승객 정보 테이블
CREATE TABLE public.subway_passengers_time_copy (
use_ym varchar(6) NULL,
line_no varchar(100) NULL,
station_name varchar(100) NULL,
time_term varchar(20) NULL,
pass_in numeric(12) NULL,
pass_out numeric(12) NULL,
reg_date varchar(8) NULL,
PRIMARY KEY (use_ym, line_no, station_name, time_term)
);
데이터 복제 설정
CDC에서 DELETE 작업 시 변경 전 데이터를 완전하게 캡처하기 위해 REPLICA IDENTITY FULL 옵션을 설정합니다. 이 설정을 통해 테이블의 모든 컬럼 값이 WAL에 기록됩니다.
ALTER TABLE public.subway_passengers_copy REPLICA IDENTITY FULL;
ALTER TABLE public.subway_passengers_time_copy REPLICA IDENTITY FULL;
ALTER TABLE public.subway_info_copy REPLICA IDENTITY FULL;
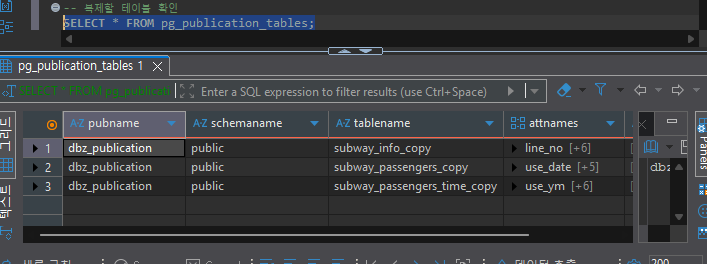
-- Publication에 등록된 테이블 확인
SELECT * FROM pg_publication_tables;
초기 적재 테스트를 위한 데이터 복제
Debezium Connector 생성 시 스냅샷 기능을 통해 기존 데이터를 초기 적재합니다. 테스트를 위해 원본 테이블에서 일부 데이터를 복사합니다.
-- 지하철역 정보: 전체 데이터 복사 (796 rows)
INSERT INTO subway_info_copy
SELECT * FROM subway_info;
-- 일별 승하차 데이터: 2015년 1월 데이터만 복사 (16,784 rows)
INSERT INTO subway_passengers_copy
SELECT * FROM subway_passengers
WHERE use_date LIKE '201501%';
-- 시간대별 승하차 데이터: 2015년 1월 데이터만 복사 (13,080 rows)
INSERT INTO subway_passengers_time_copy
SELECT * FROM subway_passengers_time
WHERE use_ym = '201501';
Kafka Topic 생성
Kafka Cluster는 DIP의 클러스터 카탈로그로 사전에 구성되어 있어야 합니다. DIP의 Kafka Cluster에는 Kafka Broker와 Kafka Connect가 모두 포함되어 있습니다.
Topic 생성
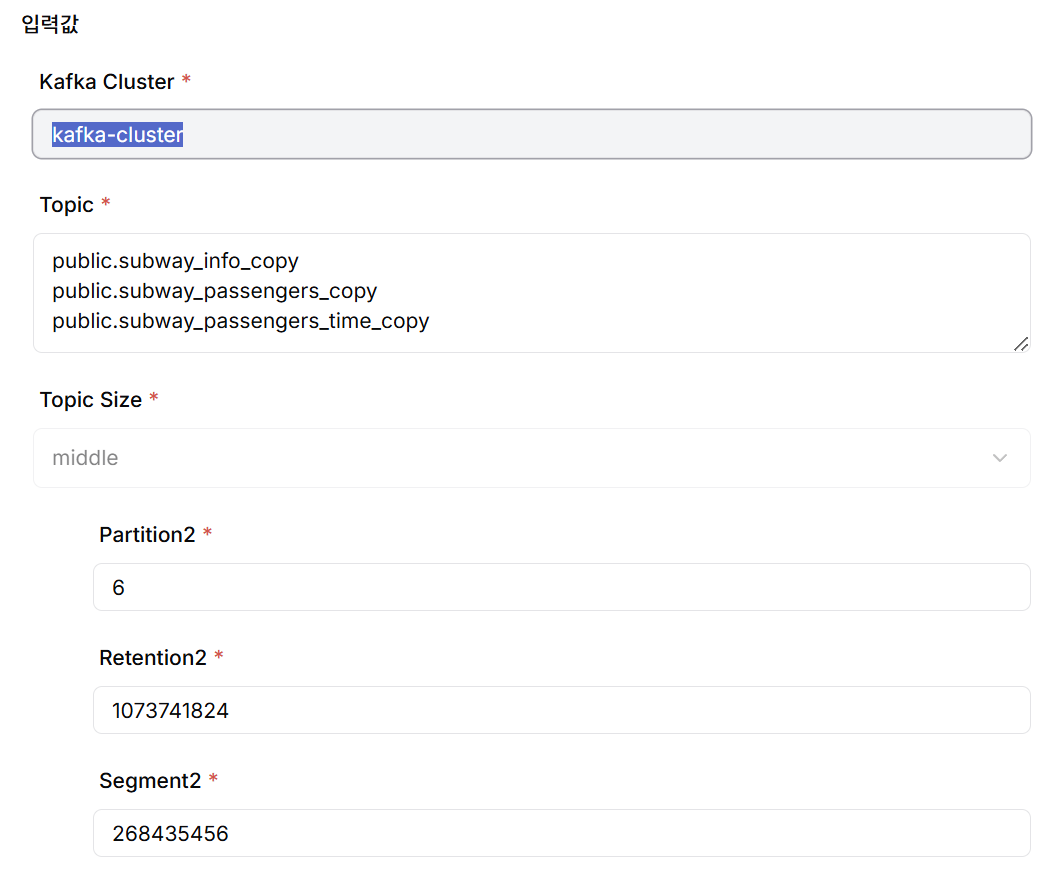
DIP 프로젝트 카탈로그 생성 메뉴에서 Kafka Topic을 생성합니다. 각 Topic은 소스 테이블과 1:1로 매핑되며, 명명 규칙은 <schema_name>.<table_name> 형식을 따릅니다. 실제 생성되는 Topic 이름에는 프로젝트 이름이 prefix로 자동 추가됩니다.
Topic 생성 시 CDC 성능과 메시지 저장 효율성을 위해 다음 파라미터들을 적절히 설정해야 합니다.
- Partition 개수: Topic 내에서 메시지를 병렬 처리하기 위한 논리적 분할 단위입니다. Partition 개수가 많을수록 처리량이 증가하지만, 관리 오버헤드도 함께 증가합니다.
- Retention bytes: 각 Partition이 보관할 수 있는 메시지의 최대 용량입니다. 이 값을 초과하면 오래된 메시지부터 삭제됩니다.
- Segment bytes: Partition 로그를 저장하는 물리적 파일(Segment)의 최대 크기입니다. Segment 단위로 압축 및 삭제가 이루어집니다.
DIP에서는 사용 편의성을 위해 Topic Size를 Small/Middle/Large로 구분하고, 각 크기별로 위 파라미터의 기본값을 제공합니다. 필요에 따라 세부 값을 직접 조정할 수도 있습니다.
Target DB (StarRocks) 구성
Target DB인 StarRocks에는 복제 대상 테이블의 스키마만 생성하면 됩니다. Primary Key는 필수는 아니지만, 데이터 일관성과 쿼리 성능을 위해 설정하는 것을 권장합니다. 테이블 이름은 소스 테이블과 동일하게 유지할 필요는 없으며, Sink Connector 설정에서 매핑 정보를 지정할 수 있습니다.
USE quickstart;
-- 지하철 정보 테이블
CREATE TABLE subway_info_copy (
line_no VARCHAR(100) NOT NULL,
station_name VARCHAR(100) NOT NULL,
station_cd VARCHAR(10) NULL,
station_cd_external VARCHAR(10) NULL,
station_ename VARCHAR(100) NULL,
station_cname VARCHAR(100) NULL,
station_jname VARCHAR(100) NULL
) ENGINE=OLAP
PRIMARY KEY (line_no, station_name)
DISTRIBUTED BY HASH(line_no, station_name) BUCKETS 10;
-- 승객 정보 테이블
CREATE TABLE subway_passengers_copy (
use_date varchar(8) NOT NULL,
line_no varchar(100) NOT NULL,
station_name varchar(100) NOT NULL,
pass_in numeric(13) NULL,
pass_out numeric(13) NULL,
reg_date varchar(8) NULL
) ENGINE=OLAP
PRIMARY KEY (use_date, line_no, station_name)
DISTRIBUTED BY HASH(use_date, line_no, station_name);
-- 시간대별 승객 정보 테이블
CREATE TABLE subway_passengers_time_copy (
use_ym varchar(6),
line_no varchar(100),
station_name varchar(100),
time_term varchar(20),
pass_in numeric(12) NULL,
pass_out numeric(12) NULL,
reg_date varchar(8) NULL
) ENGINE=OLAP
PRIMARY KEY (use_ym, line_no, station_name, time_term)
DISTRIBUTED BY HASH(use_ym, line_no, station_name, time_term);
Kafka Connector 생성
DIP 프로젝트 카탈로그 생성 메뉴에서 Kafka Connector를 생성합니다. PostgreSQL Debezium Source Connector와 StarRocks Sink Connector를 한 번에 생성하여 배포할 수도 있고, 각각 독립적으로 생성하여 배포할 수도 있습니다. 본 예제에서는 운영 관리의 유연성을 위해 두 Connector를 별도로 생성하여 배포하였습니다.
StarRocks Sink Connector 커스터마이징
StarRocks Sink Connector는 프로젝트 환경에 맞게 커스터마이징이 필요합니다. GitHub의 StarRocks Sink Connector 1.0.4 버전을 기반으로 다음 사항을 업그레이드했습니다.
- Java 8 → Java 17
- Kafka 3.4 → Kafka 4.0
- StarRocks 2.5 → StarRocks 3.5
커스터마이징된 StarRocks Sink Connector 이미지는 DIP Kafka Cluster에 사전 배포되어 있습니다.
PostgreSQL Debezium Source Connector 생성
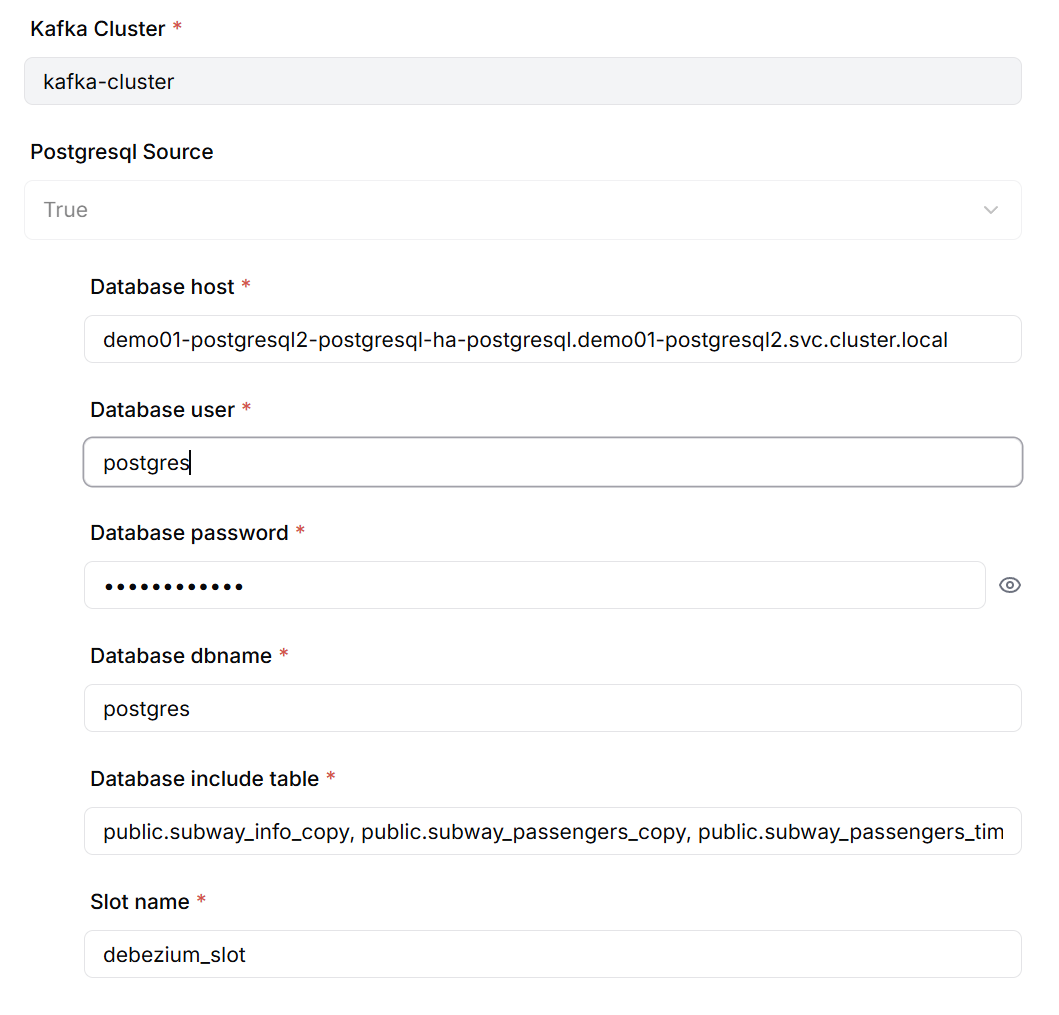
Source Connector 생성 시 다음 정보를 설정합니다.
- PostgreSQL 데이터베이스 연결 정보(호스트, 포트, 데이터베이스명, 인증 정보)
- CDC 대상 테이블 목록
- Debezium Replication Slot 이름
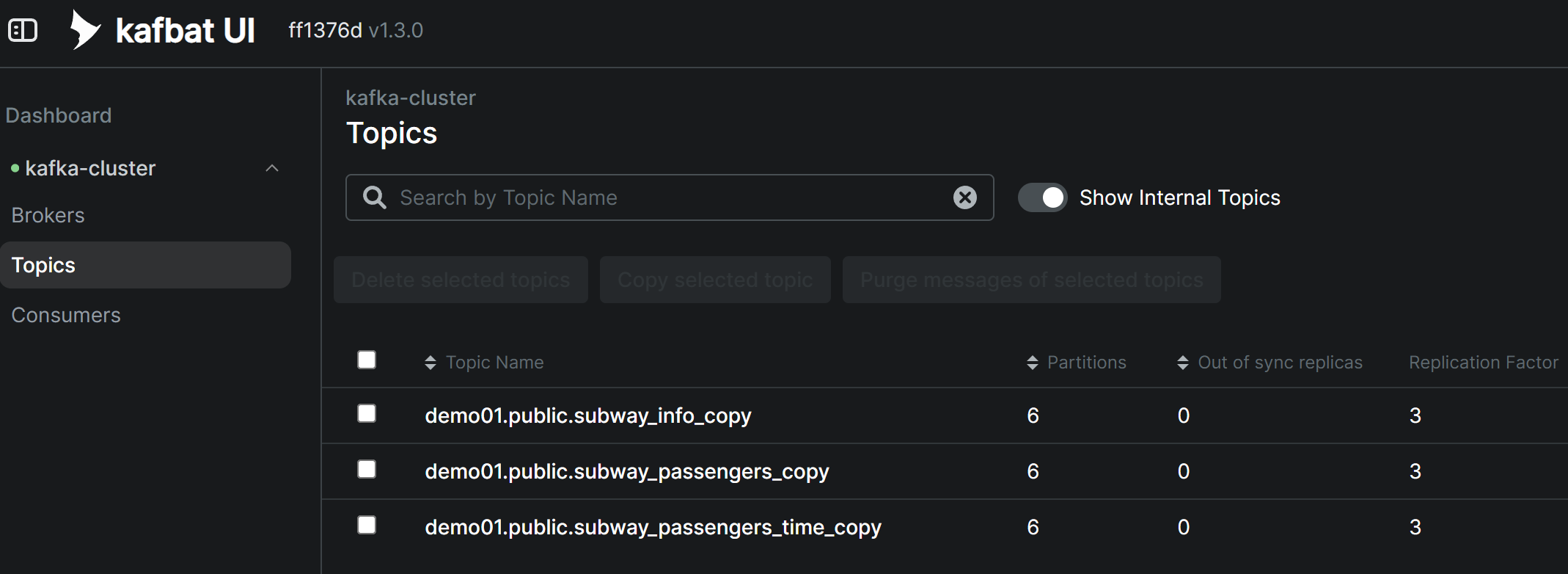
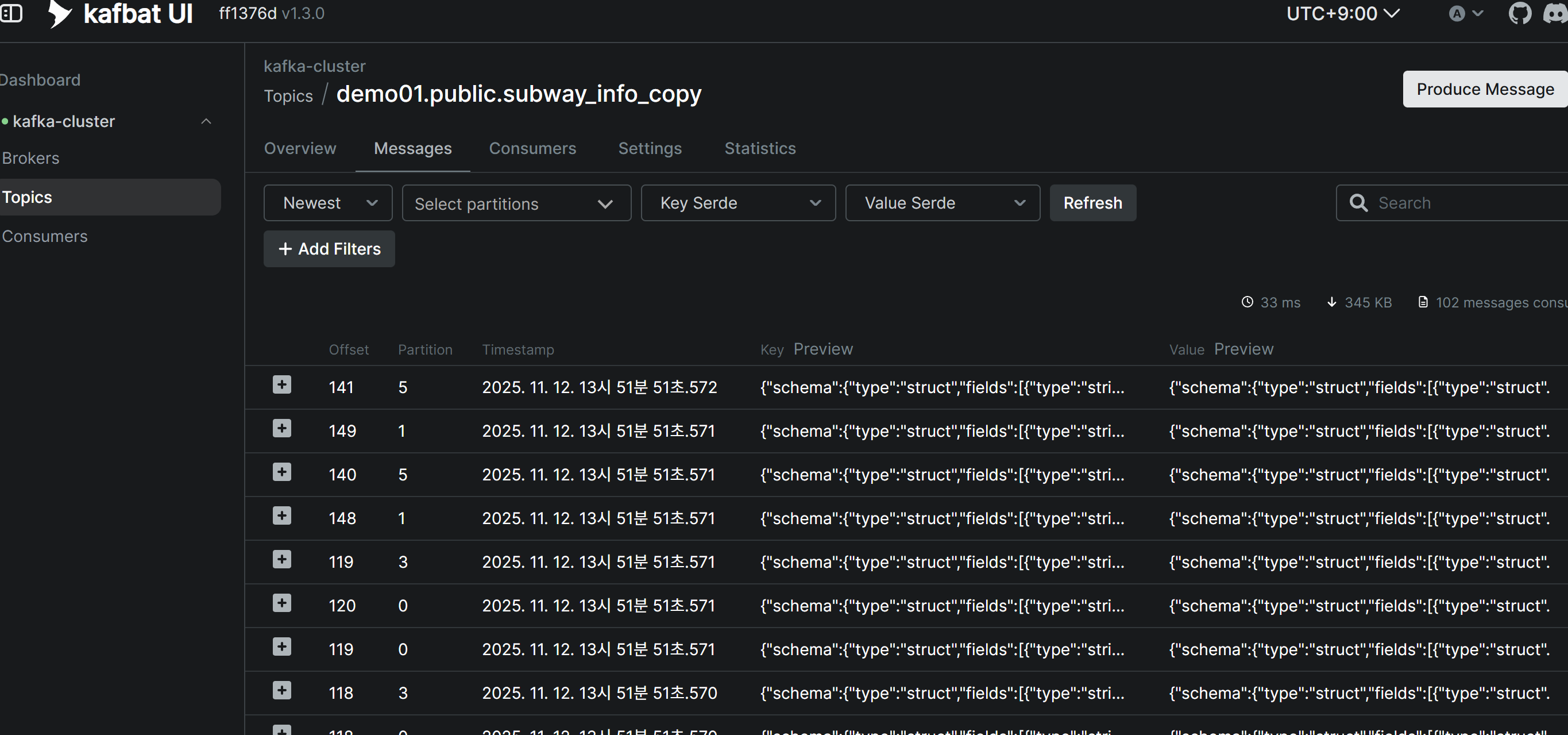
Source Connector 생성 후 Topic 메시지 확인
Debezium Source Connector가 정상적으로 생성되면, 소스 테이블의 기존 데이터(스냅샷)가 자동으로 Kafka Topic에 발행됩니다. Kafbat UI를 통해 각 Topic에 메시지가 정상적으로 수신되었는지 확인할 수 있습니다.
StarRocks Sink Connector 생성
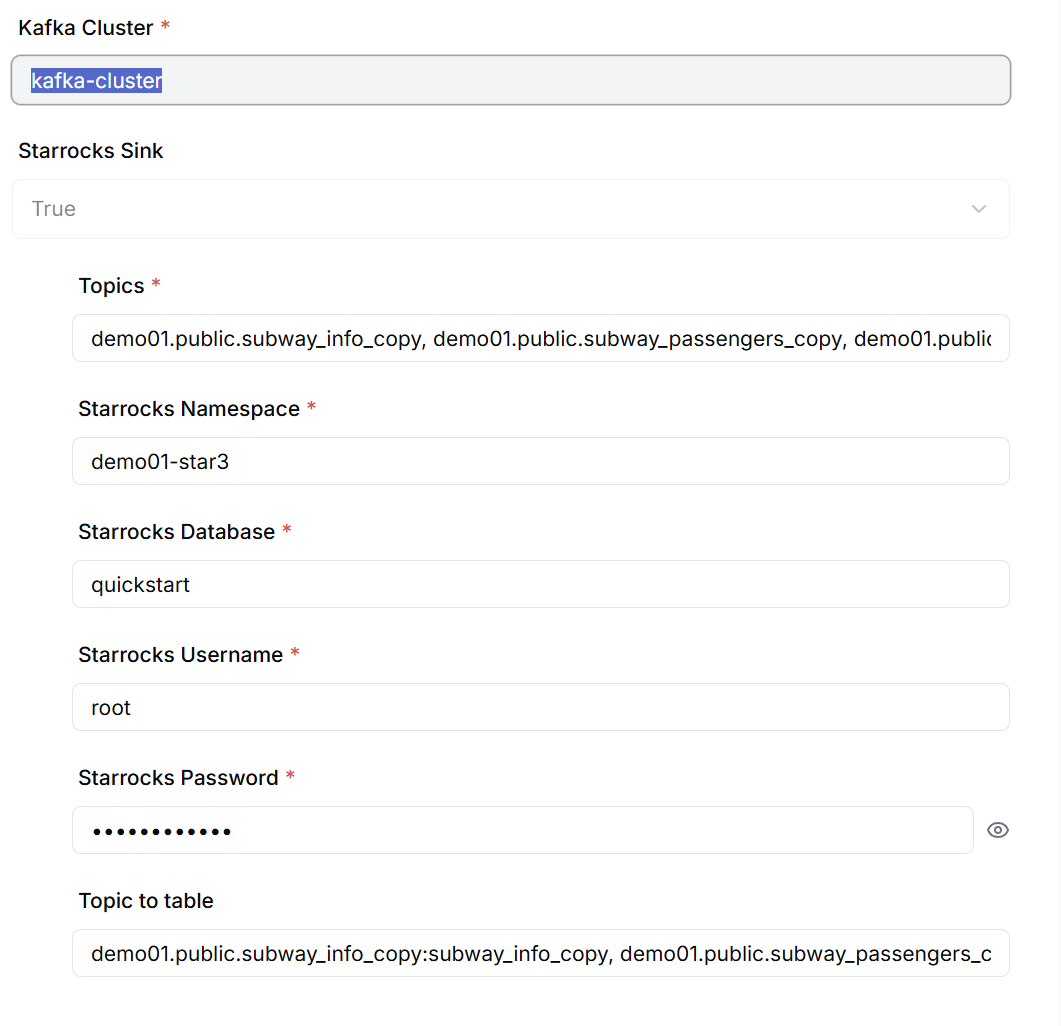
Sink Connector 생성 시 다음 정보를 설정합니다.
- 구독할 Kafka Topic 목록(콤마로 구분하여 입력)
- StarRocks 데이터베이스 연결 정보
- Topic과 Target 테이블 간의 매핑 정보
검증 및 테스트
초기 적재 검증
StarRocks Sink Connector가 배포되면 Kafka Topic의 메시지를 읽어 Target DB에 적재하기 시작합니다. 약 3만여 건의 초기 데이터가 2~3초 이내에 StarRocks로 로드되는 것을 확인할 수 있습니다.
-- 각 테이블의 행 수 확인
SELECT COUNT(*) FROM quickstart.subway_info_copy; -- 796 rows
SELECT COUNT(*) FROM quickstart.subway_passengers_copy; -- 16,784 rows
SELECT COUNT(*) FROM quickstart.subway_passengers_time_copy; -- 13,080 rows
CDC 성능 검증
실시간 CDC 성능을 측정하기 위해 Source 테이블에서 대량 DML 작업을 수행하고, Target 테이블에 반영되는 시간을 측정합니다.
테스트 시나리오:
- 대량 삽입(Bulk Insert): 95만여 건의 대규모 데이터 삽입
- 대량 수정(Bulk Update): 기존 데이터의 대량 업데이트
- 대량 삭제(Bulk Delete): 대규모 데이터 삭제
성능 측정 결과:
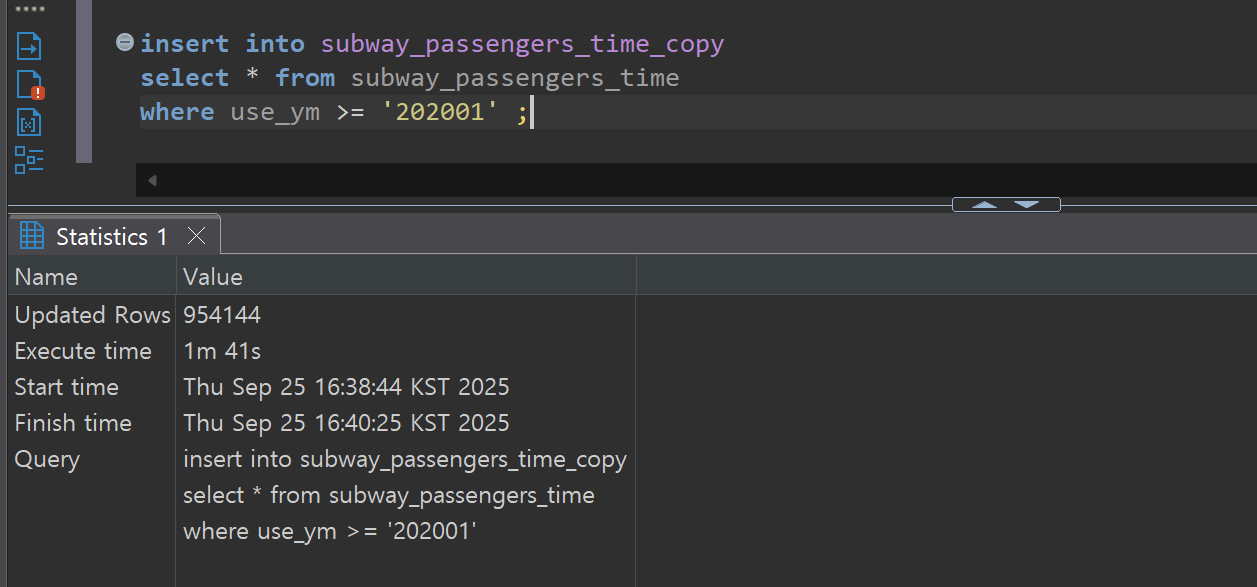
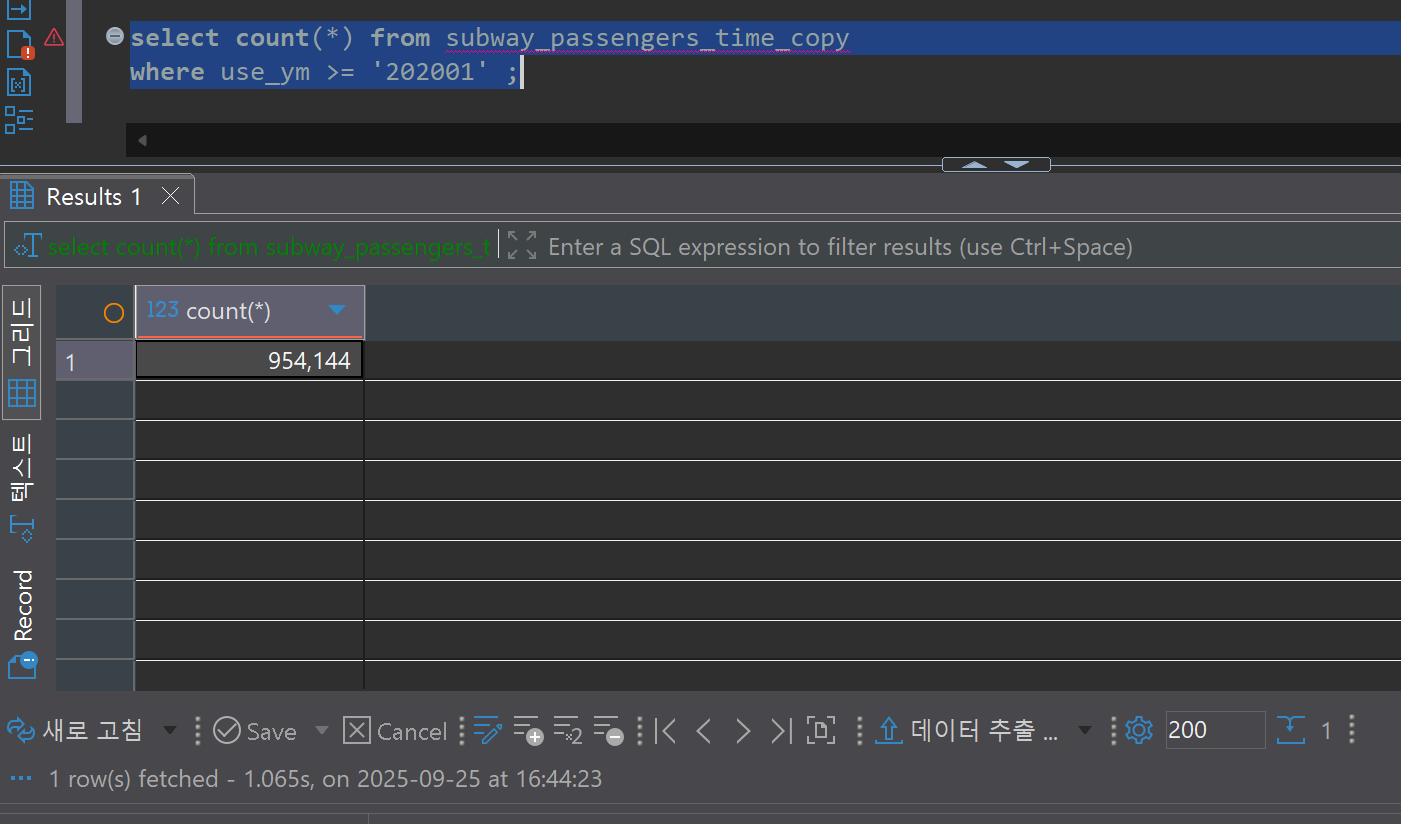
- 대량 삽입 작업: PostgreSQL 커밋 완료 시점부터 StarRocks 적재 완료까지 약 238초 소요
- 처리량: 954,144 rows / 238초 ≈ 4,009 rows/초
데이터 일관성 검증
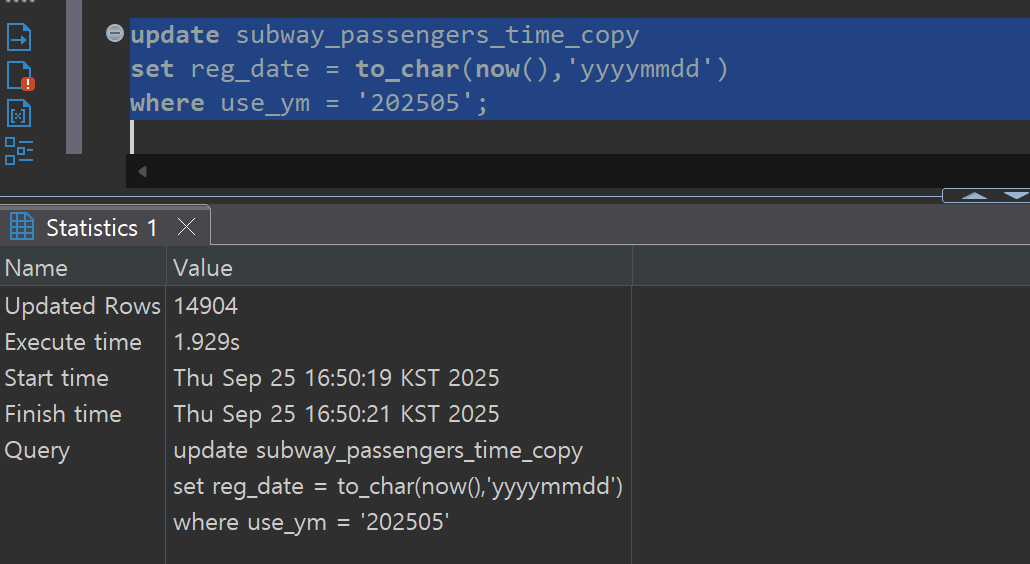
CDC 시스템의 신뢰성을 검증하기 위해 Source DB와 Target DB의 데이터를 비교합니다. 대량 수정 및 삭제 작업 후에도 양쪽 데이터베이스의 레코드 수와 내용이 정확히 일치함을 확인할 수 있습니다.
대량 수정(Bulk Update) 검증:
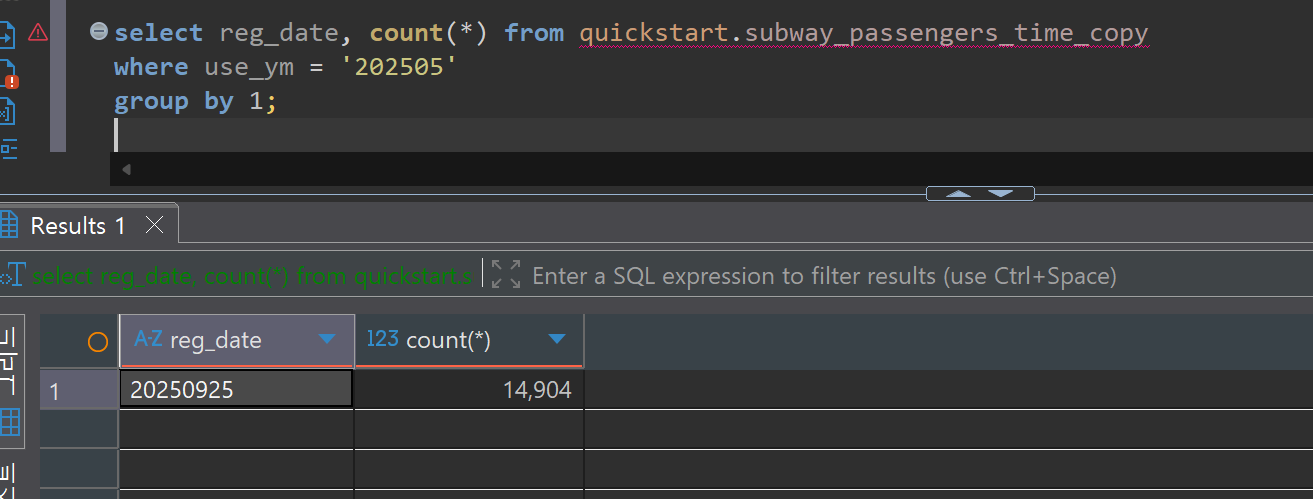
대량 삭제(Bulk Delete) 검증:
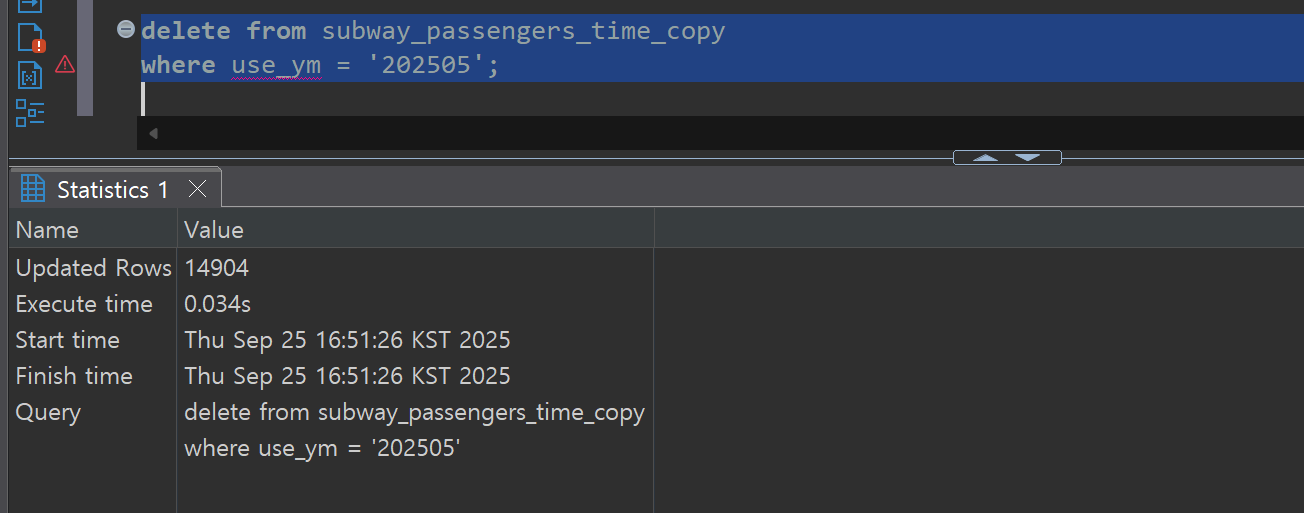
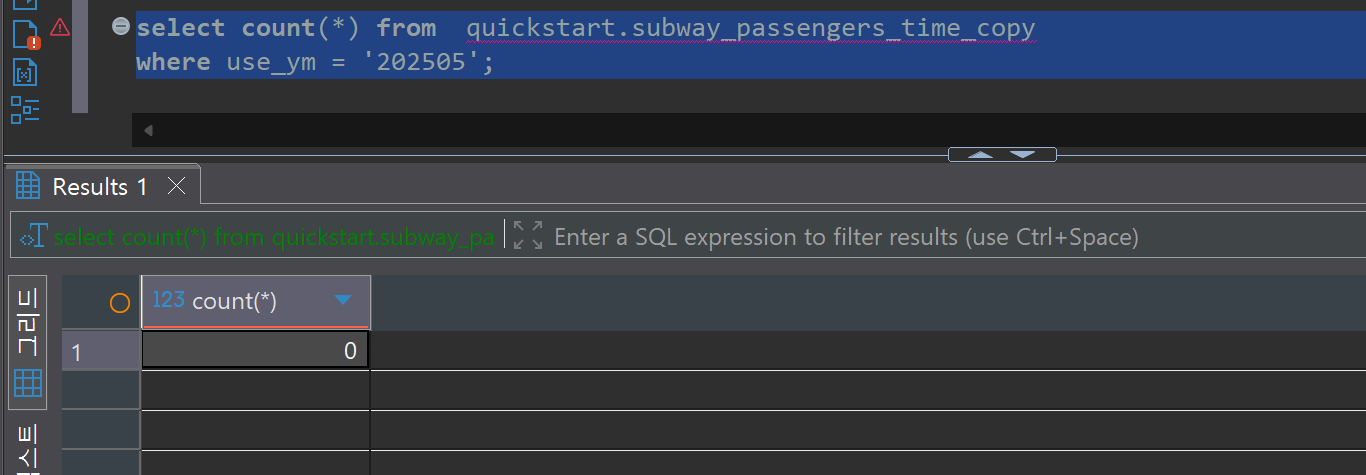
BI 구현
Apache Superset에서 MySQL 프로토콜을 통해 StarRocks DB에 연결한 후, 기존에 PostgreSQL을 데이터 소스로 사용하던 대시보드를 StarRocks 기반으로 전환합니다.
대시보드 전환 대상:
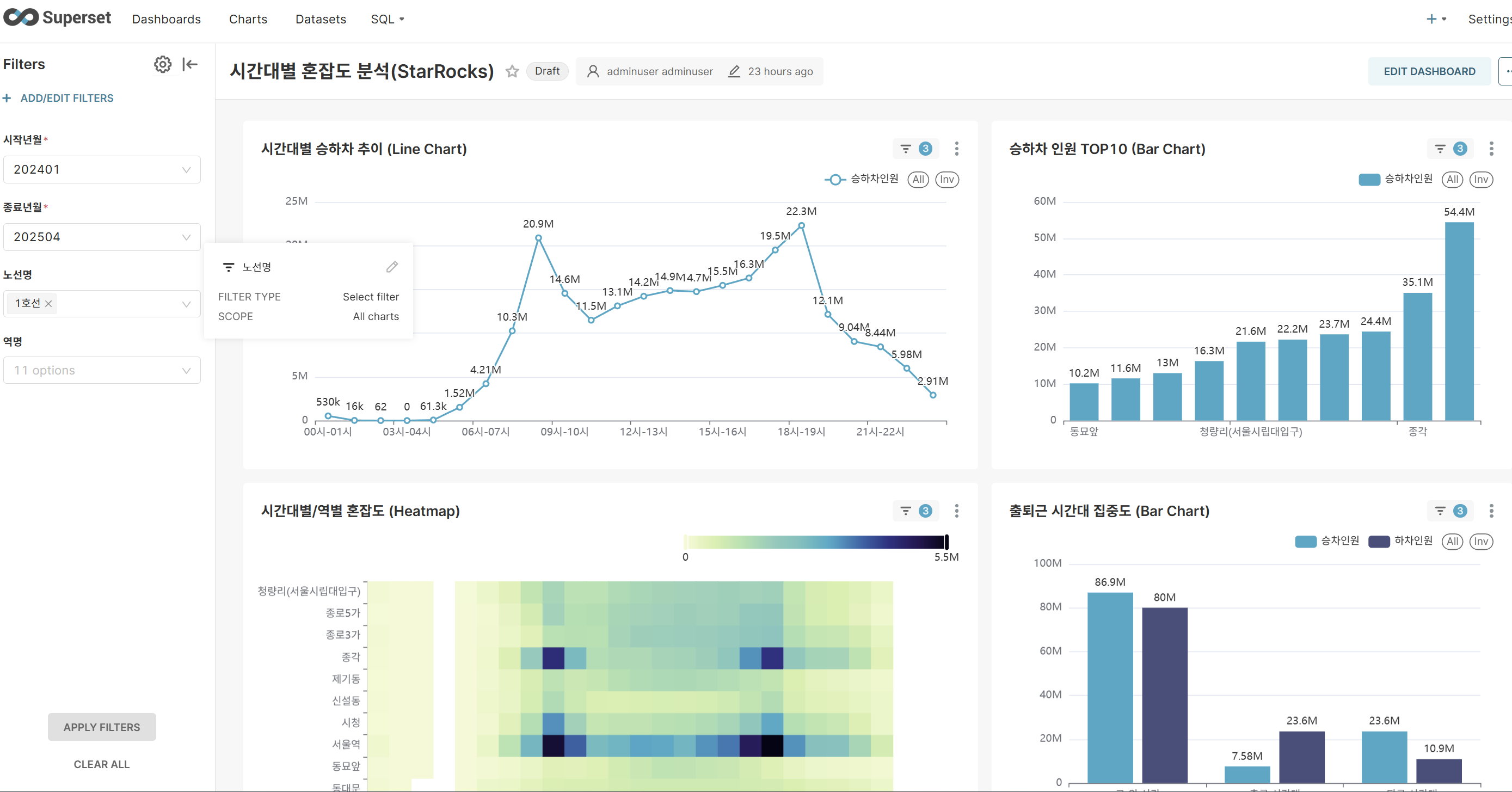
- 시간대별 혼잡도 분석 대시보드
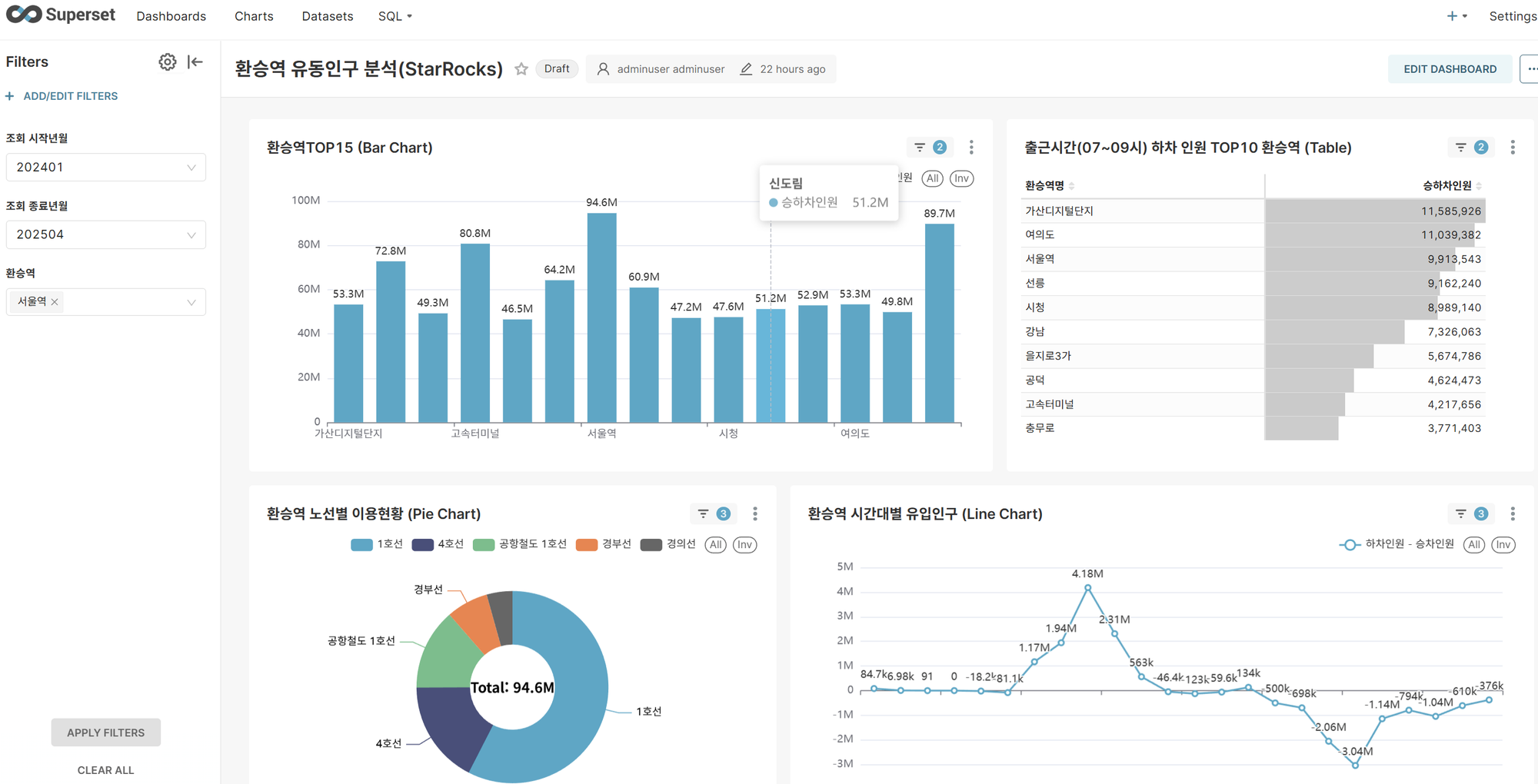
- 환승역 유동인구 분석 대시보드
StarRocks DB Connection 추가
Superset의 데이터베이스 연결 메뉴에서 MySQL Client를 선택하고, StarRocks의 연결 정보를 입력하여 새로운 데이터베이스 연결을 생성합니다.
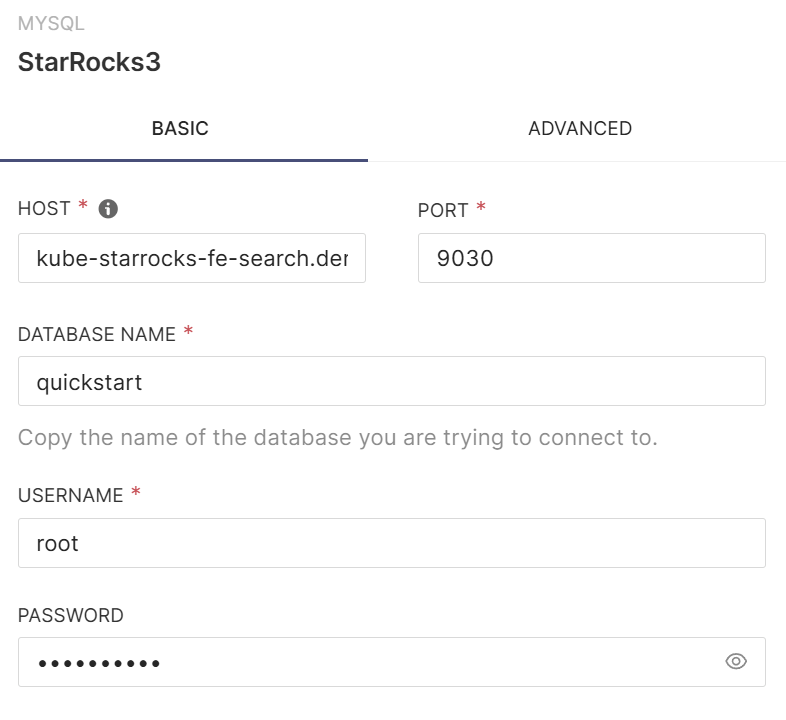
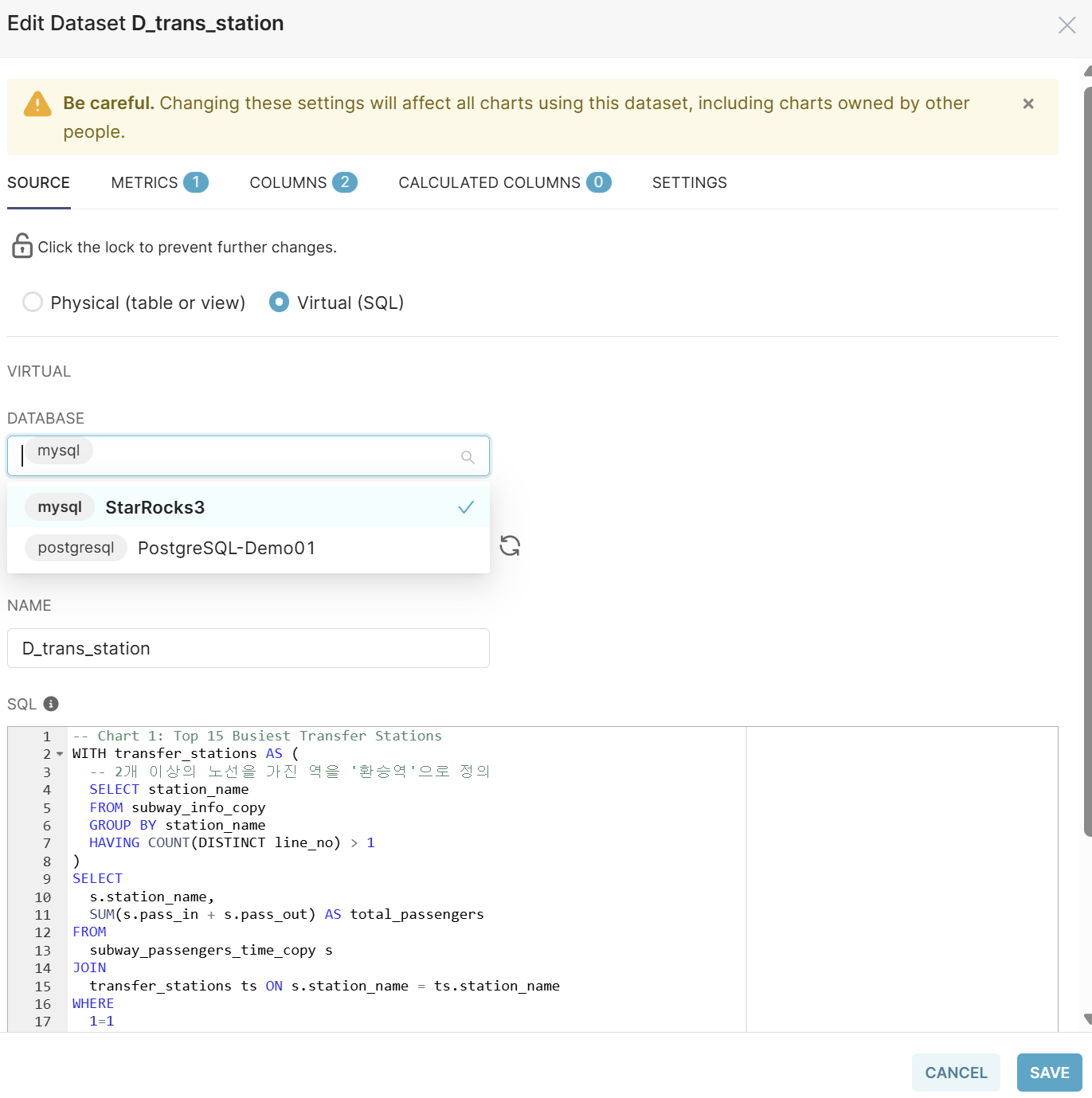
Dataset 수정
기존 대시보드의 각 Dataset을 다음과 같이 수정합니다.
- Dataset을 편집 모드로 엽니다.
- Database를 PostgreSQL에서 StarRocks(MySQL)로 변경합니다.
- SQL 쿼리의 테이블명을 StarRocks의 테이블명과 일치하도록 수정합니다.
- 변경 사항을 저장합니다.
수정된 대시보드를 실행하면 PostgreSQL 대비 현저히 향상된 쿼리 성능을 체감할 수 있습니다. StarRocks의 컬럼 기반 스토리지와 벡터화된 쿼리 엔진 덕분에 대용량 데이터 집계 및 분석 쿼리가 빠르게 처리됩니다.
결론
본 프로젝트에서는 PAASUP DIP 환경에서 Debezium CDC와 Kafka를 활용하여 PostgreSQL에서 StarRocks로의 고성능, 고신뢰성 실시간 데이터 복제 파이프라인을 성공적으로 구축하였습니다.
주요 성과:
- 초기 적재 성능: 3만여 건의 데이터를 2~3초 이내에 적재 완료
- CDC 처리 성능: 최소 사양(3 kafka brokers, 3 starrocks be nodes)의 테스트 환경에서 약 4,009 rows/초의 안정적인 실시간 복제 처리량 달성
- 데이터 일관성: INSERT, UPDATE, DELETE 작업에서 Source DB와 Target DB 간 완벽한 데이터 일관성 보장
- 쿼리 성능 개선: StarRocks 전환 후 대시보드 조회 속도 대폭 향상
구현 과정에서 얻은 인사이트:
-
StarRocks Sink Connector의 중요성: 초기 테스트에서 범용 MySQL JDBC Sink Connector를 사용했을 때 데이터 적재 시간이 20배 이상 느려지는 문제가 발생했습니다. 이는 StarRocks의 고유한 Stream Load API를 활용하지 못했기 때문입니다. 따라서 StarRocks 환경에서는 반드시 전용 Sink Connector를 프로젝트 환경에 맞게 커스터마이징하여 사용해야 합니다.
-
StarRocks의 분석 워크로드 최적화: StarRocks를 Data Mart 또는 Data Warehouse로 활용할 경우, MPP(Massively Parallel Processing) 아키텍처와 컬럼 기반 스토리지 덕분에 대용량 집계 쿼리에서 탁월한 성능을 발휘합니다. 특히 BI 도구와 연동 시 실시간 대시보드 구현에 매우 적합합니다.
-
확장 가능한 CDC 아키텍처: Kafka를 중심으로 Source와 Target을 분리함으로써 향후 다양한 데이터 소스와 타겟 시스템으로 확장 가능한 유연한 아키텍처를 구축할 수 있었습니다.