
실시간 로그 수집 및 분석 사례
Kafka 기반 스트리밍 아키텍처를 활용하여 API Gateway 로그를 실시간으로 수집하고, StarRocks에 저장한 뒤 Apache Superset으로 시각화하는 모니터링 시스템 구축 사례. 서비스 안정성 향상과 장애 대응 시간 단축을 실현합니다.
목차
1. 개요
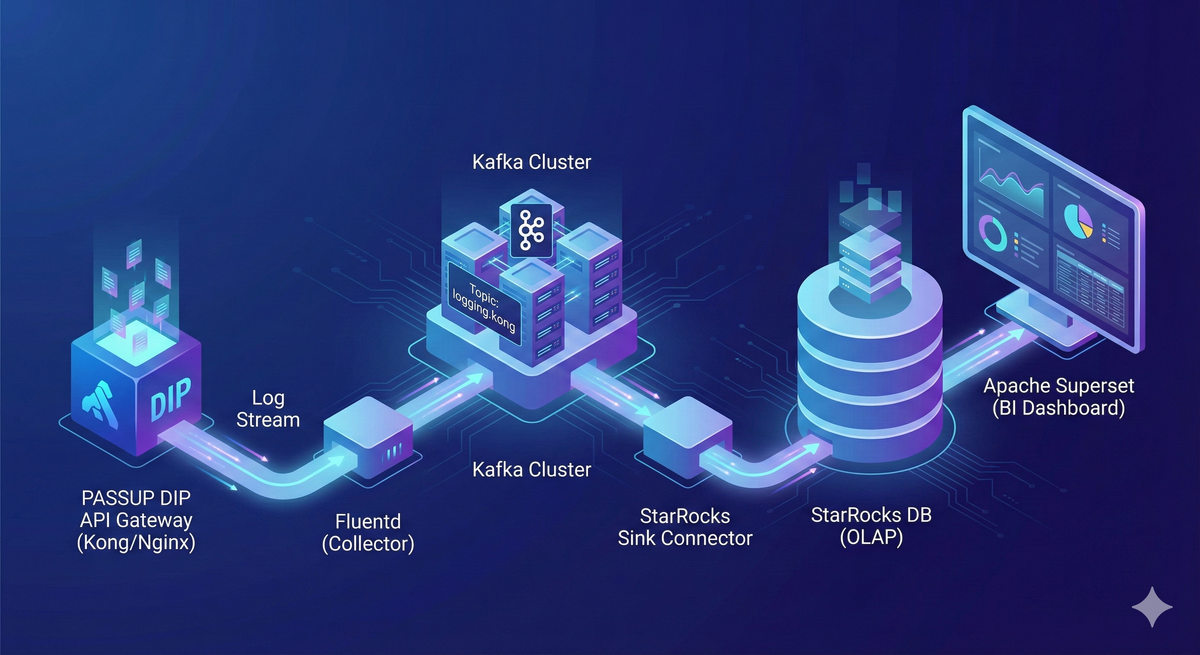
본 문서는 PASSUP DIP의 API Gateway 로그를 실시간으로 수집하고 분석하는 시스템 구축 사례를 다룹니다. Kafka 기반의 메시지 스트리밍 아키텍처를 활용하여 로그 데이터를 Target DB에 저장하고, BI 도구를 통해 실시간으로 서비스 상태를 모니터링할 수 있는 환경을 구성합니다.
구현 환경
- Message Broker: kafka-cluster
- Log Producer: fluentd
- Kafka Connector: StarRocks Sink Connector
- Target DB: StarRocks
- Kafka Monitoring: Kafbat UI
- BI Tool: Apache Superset
실시간 로그 수집 아키텍처
2. 로그 수집
API Gateway 로그 메시지 포맷 설정
API Gateway 배포 시 values.yaml 파일에서 로그 메시지 포맷을 정의할 수 있습니다.
values.yaml 설정 예시
env:
proxy_access_log: "/dev/stdout custom_fmt"
# 커스텀 로그 포맷 정의
nginx_http_log_format: >-
custom_fmt '$remote_addr [$time_local] "$request" $status $request_time $upstream_response_time "$http_host" "$http_user_agent"'
real_ip_header: "X-Forwarded-For"
real_ip_recursive: "on"
로그 포맷 변수 설명
| 변수명 | 의미 | 상세 설명 |
|---|---|---|
| $remote_addr | 클라이언트 IP | 실제 요청을 보낸 Client IP. Proxy 또는 LB가 있을 경우 real_ip 설정 필요 |
| $time_local | 요청 시각(로컬 타임존) | [10/Dec/2025:10:23:10 +0900] 형식의 서버 로컬 시간 |
| $request | 요청 라인 | "GET /api/v1/foo HTTP/1.1" 형태의 전체 요청 문자열 |
| $status | HTTP 응답 코드 | 200, 404, 500 등 클라이언트에게 반환된 상태 코드 |
| $request_time | 전체 요청 처리 시간 | 요청 수신부터 응답 완료까지의 총 처리 시간(초 단위) |
| $upstream_response_time | 업스트림 응답 시간 | 백엔드 서비스의 응답 소요 시간(초 단위), 백엔드 지연 분석에 활용 |
| $http_host | 원본 Host 헤더 | 클라이언트 요청의 Host 값, Ingress 도메인 판별에 사용 |
| $http_user_agent | User-Agent | 브라우저/CLI/봇 등을 식별하는 UA 문자열, 보안 및 디버깅에 활용 |
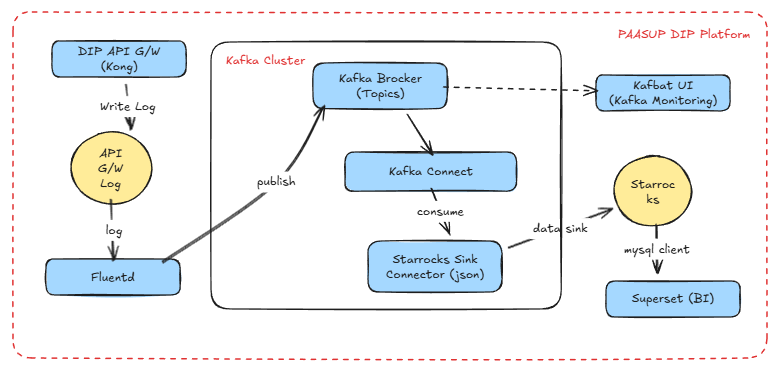
API Gateway 로그 수집 및 Kafka 전송 프로세스
PAASUP DIP에서는 다음과 같은 절차로 로그를 수집하여 Kafka의 logging.kong 토픽에 메시지를 전송합니다.
- Kong 애플리케이션이 컨테이너 로그 생성
- Fluent-bit DaemonSet이 모든 노드에서 로그 수집
- Flow CR이 Kong 라벨을 가진 로그만 필터링
- Fluentd StatefulSet이 로그를 JSON 형식으로 가공
- ClusterOutput을 통해 Kafka 토픽
logging.kong으로 전송 - SCRAM-SHA-512 인증과 TLS를 사용하여 Kafka와 안전하게 통신
참고: 위 프로세스는 플랫폼의 기본 로깅 파이프라인으로 자동 구성됩니다.
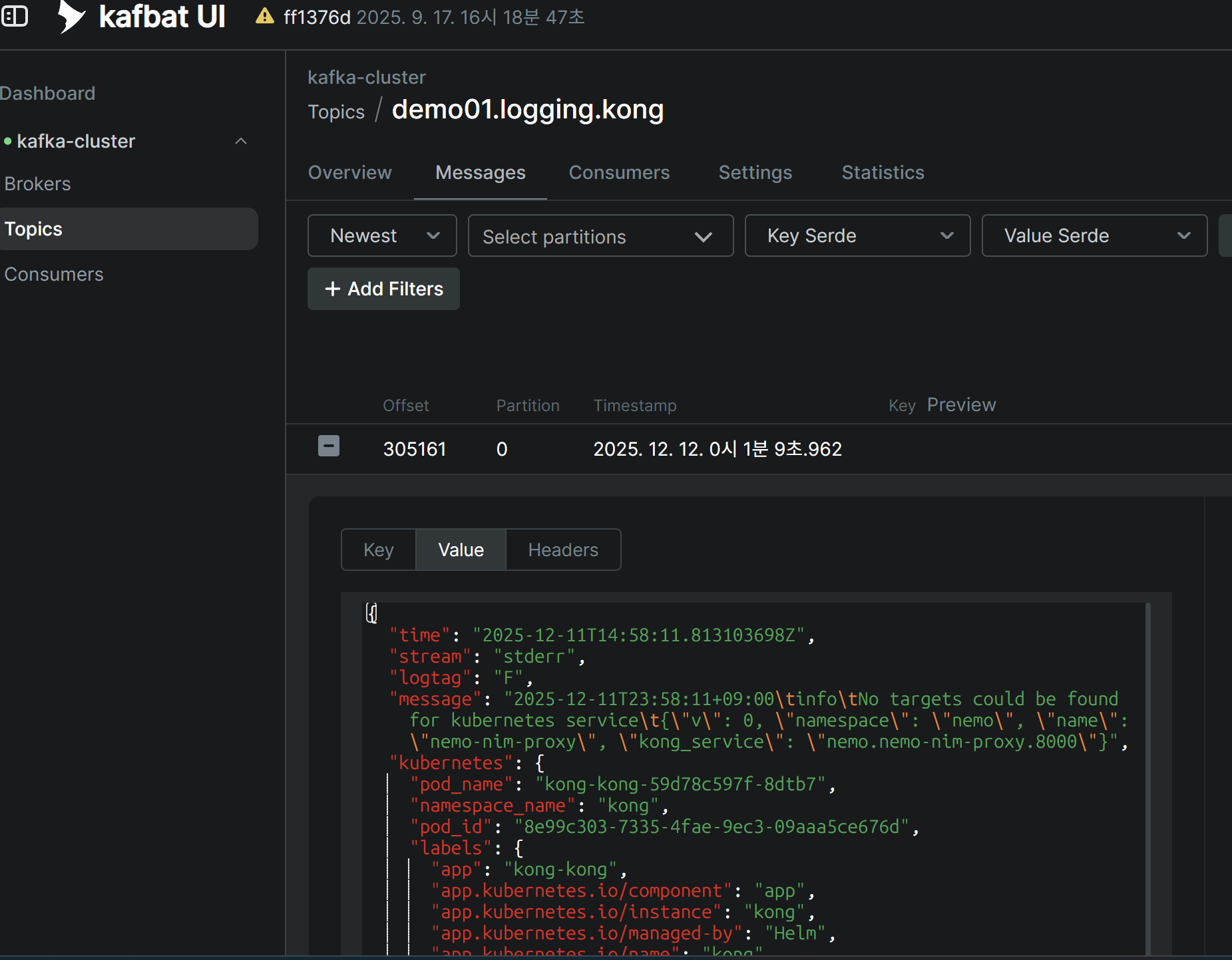
로그 수집 확인
Kafbat UI에서 logging.kong 토픽의 JSON 메시지를 실시간으로 확인할 수 있습니다.
3. 로그 데이터 Sink
Target 테이블 생성
logging.kong 토픽의 JSON 메시지 구조에 맞춰 Target DB(StarRocks)에 테이블을 생성합니다.
주요 고려사항:
time컬럼은 UTC 타임존이므로,kst_timecomputed column을 추가하여 한국 시간으로 변환kubernetes,kubernetes_namespace는 중첩 JSON 구조이므로 JSON 데이터 타입으로 선언
USE quickstart;
CREATE TABLE IF NOT EXISTS kong_log_events (
time DATETIME,
stream STRING,
logtag STRING,
message STRING,
kubernetes JSON,
kubernetes_namespace JSON,
kst_time DATETIME AS convert_tz(time, 'UTC', 'Asia/Seoul')
) ENGINE = OLAP
DUPLICATE KEY(time)
DISTRIBUTED BY HASH(kst_time) BUCKETS 10;
StarRocks Sink Connector 생성 및 데이터 적재
DIP 카탈로그 생성 메뉴에서 Kafka Connector를 간편하게 생성할 수 있습니다.
생성 절차:
카탈로그 생성메뉴에서kafka-connector 생성클릭- Connector 종류에서 StarRocks Sink(Json) 선택
- 필수 정보 입력:
- Topic name
- StarRocks Namespace
- StarRocks Database
- StarRocks Username
- StarRocks Password
- Topic to table 매핑 정보
생성버튼 클릭
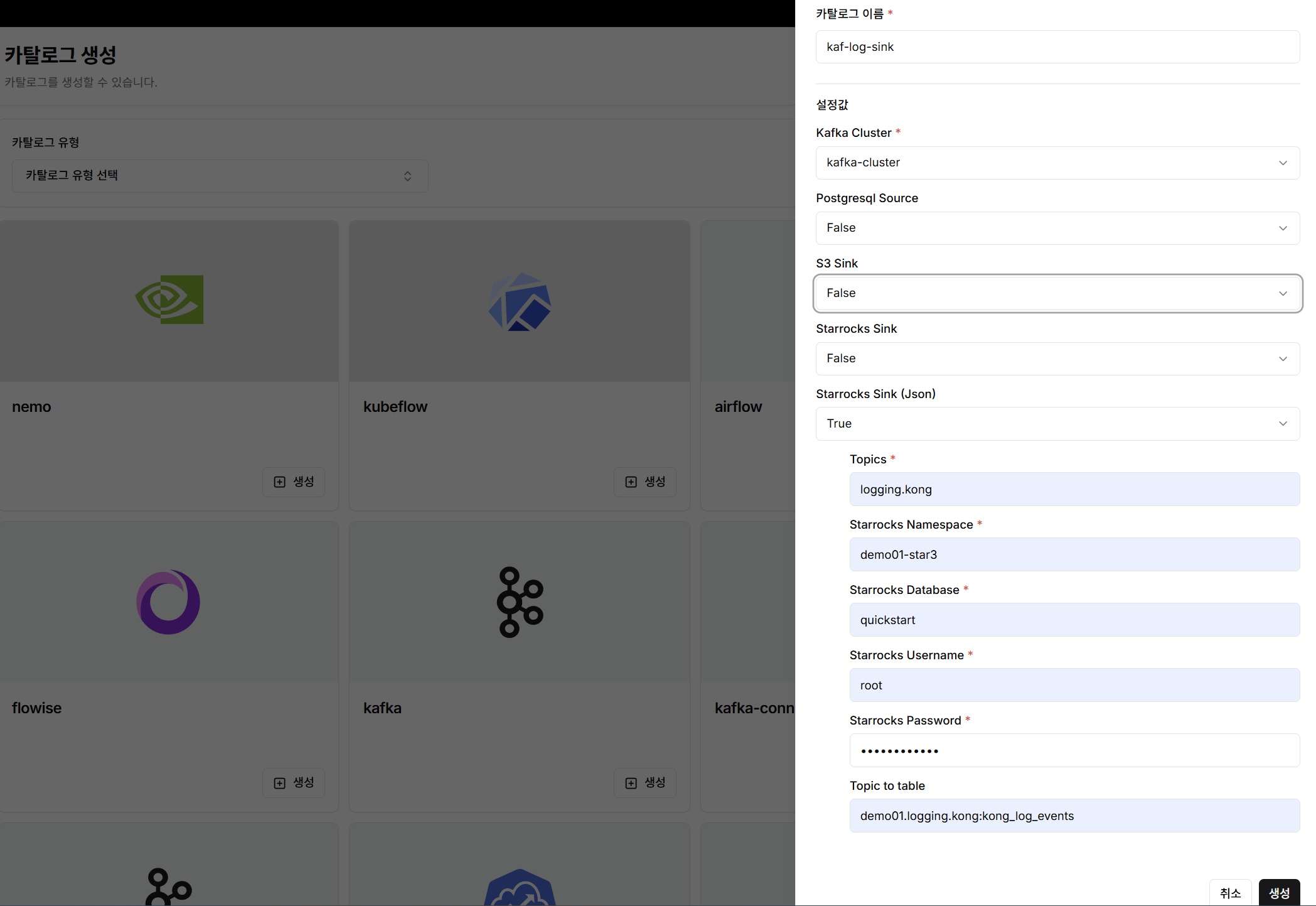
Connector 생성 완료 즉시 Kafka 메시지가 consume되어 StarRocks의 kong_log_events 테이블에 데이터가 실시간으로 적재됩니다.
데이터 적재 확인
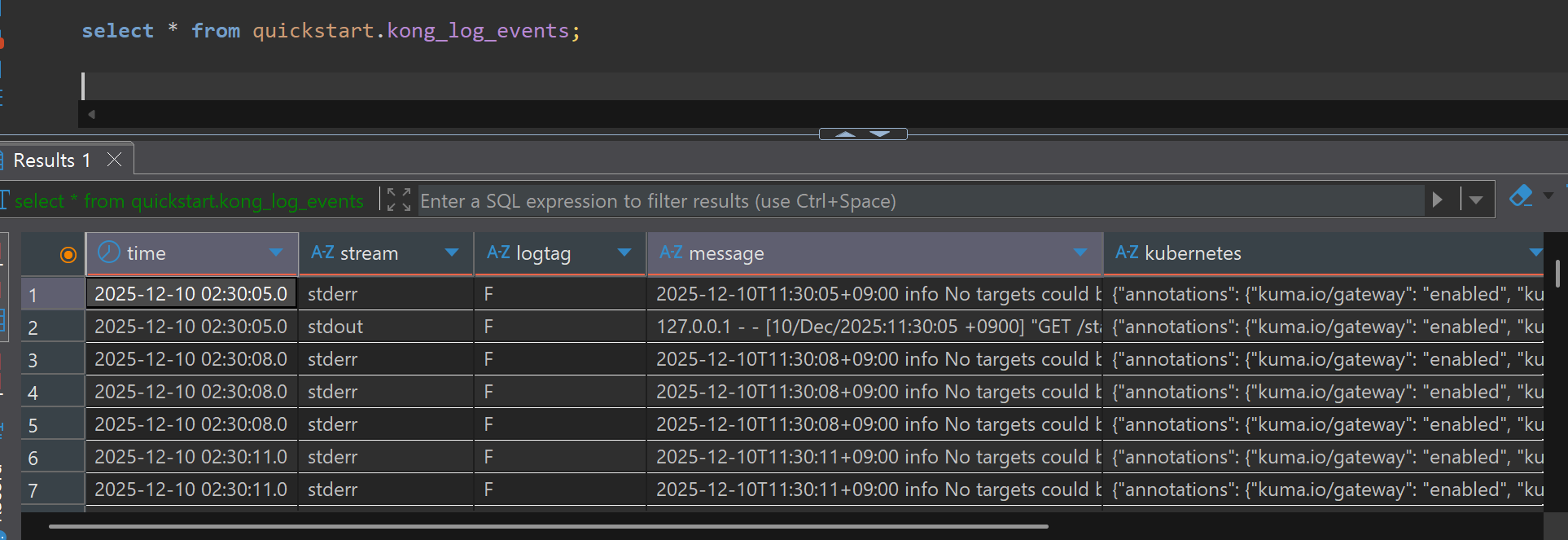
SQL Client에서 적재된 데이터를 조회할 수 있습니다.
SELECT * FROM quickstart.kong_log_events;
4. 시각화
1단계: Superset Dataset 생성
원본 로그 데이터는 message 컬럼에 문자열 형태로 저장되어 있어, 분석에 필요한 정보를 추출하기 위해 정규식 함수를 사용해야 합니다. 매 차트마다 복잡한 정규식 쿼리를 반복하면 성능 저하와 관리의 어려움이 발생하므로, Virtual Dataset을 활용하여 효율적으로 관리합니다.
Dataset 생성 방법:
- SQL Lab에서 아래 쿼리 실행
Save as Dataset클릭- Dataset 이름:
kong_parsed_logs - 모든 차트에서 이 Dataset을 데이터 소스로 사용
SELECT
kst_time,
split_part(message, ' ', 1) AS client_ip,
regexp_extract(message, 'HTTP/[0-9.]+" [0-9]+ ([0-9.]+)', 1) AS response_time,
regexp_extract(message, 'HTTP/[0-9.]+" [0-9]+ [-0-9. ]+ "(.*?)"', 1) AS host_domain,
CASE
WHEN regexp_extract(message, 'HTTP/[0-9.]+" [0-9]+ [-0-9. ]+ "(.*?)"', 1) LIKE '%-%'
THEN split_part(regexp_extract(message, 'HTTP/[0-9.]+" [0-9]+ [-0-9. ]+ "(.*?)"', 1), '-', 1)
ELSE 'platform'
END AS project_name,
split_part(regexp_extract(message, '"(GET|POST|PUT|DELETE|HEAD|OPTIONS) (.*?) HTTP', 2), '?', 1) AS request_url,
regexp_extract(message, 'HTTP/[0-9.]+" ([0-9]{3})', 1) AS status_code,
message
FROM
quickstart.kong_log_events
WHERE
stream = 'stdout'
AND message LIKE '%HTTP/%' -- Access Log만 필터링
AND message REGEXP '^[0-9]{1,3}\\.[0-9]{1,3}\\.[0-9]{1,3}\\.[0-9]{1,3}' -- IP로 시작하는 Log만 필터링
AND split_part(message, ' ', 1) != '127.0.0.1' -- Kong health check 제외
-- Jinja Template을 사용하여 동적 필터 주입
{% if from_dttm %}
AND kst_time >= '{{ from_dttm }}'
{% endif %}
{% if to_dttm %}
AND kst_time < '{{ to_dttm }}'
{% endif %}
2단계: 대시보드 차트 구성
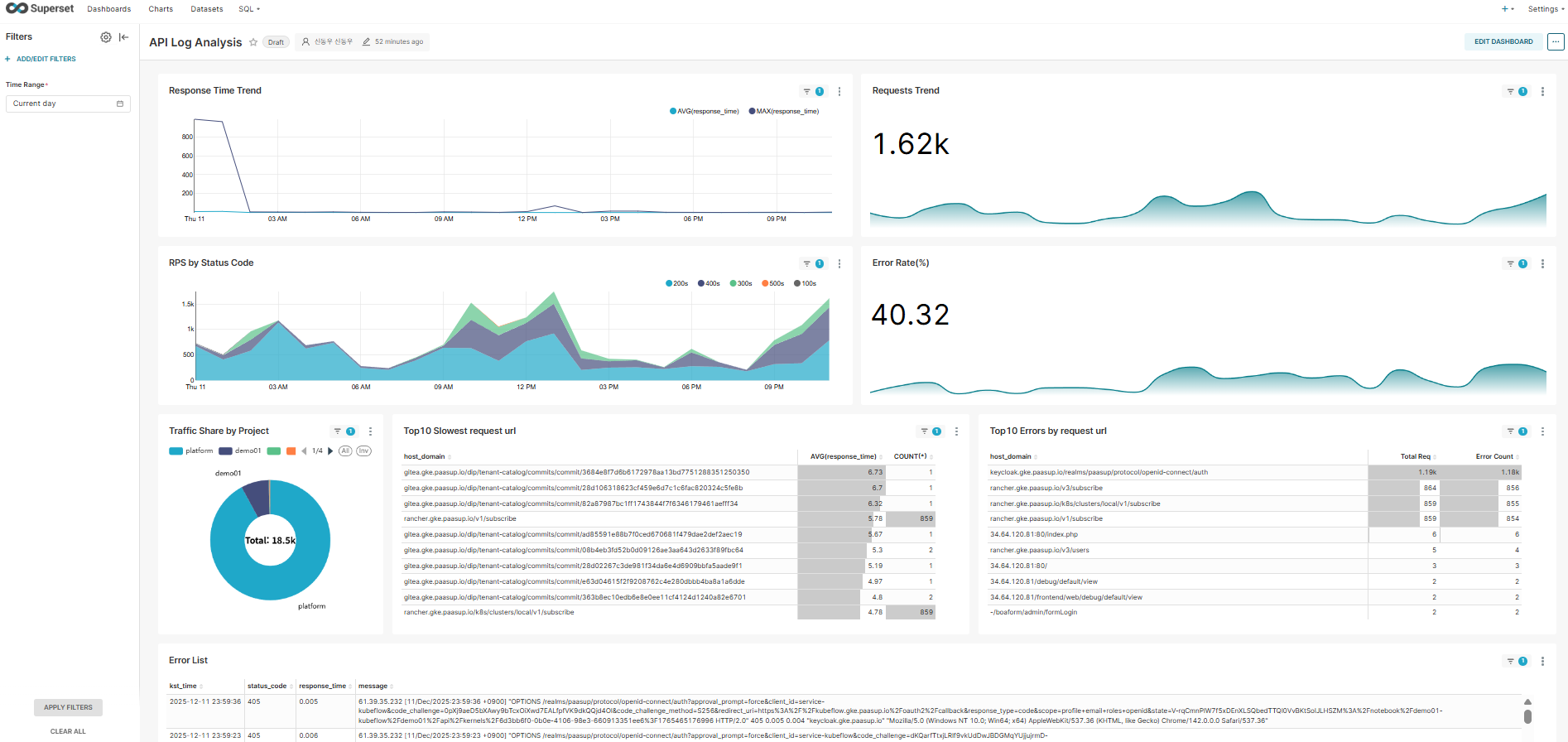
kong_parsed_logs Dataset을 활용하여 다양한 모니터링 차트를 생성합니다.
1) Response Time Trend
- Chart Type: Time-series Line Chart
- Time Column: kst_time
- Metrics: AVG(response_time), MAX(response_time)
- 설명: 응답 시간 추이를 실시간으로 모니터링
2) Requests Trend
- Chart Type: Big Number
- Metric: COUNT(*)
- Time Grain: HOUR
- 설명: 시간당 총 요청 수 추이
3) RPS by Status Code
- Chart Type: Time-series Chart (Stacked Area)
- Time Column: kst_time
- Dimensions: status_code
- Metrics: COUNT(*)
- 설명: 상태 코드별 요청 분포 시각화
4) Error Rate (%)
- Chart Type: Big Number with Trendline
- Custom Metric:
SUM(CASE WHEN status_code >= 400 THEN 1 ELSE 0 END) * 100.0 / COUNT(*) - Time Grain: HOUR
- 설명: 에러율(%) 추이 모니터링
5) Traffic Share by Project
- Chart Type: Pie Chart
- Dimensions: project_name
- Metric: COUNT(*)
- 설명: 프로젝트별 트래픽 점유율 분석
6) Top 10 Slowest Request URL
- Chart Type: Table
- Dimensions: concat(host_domain, request_url)
- Metrics: AVG(response_time), COUNT(*)
- Sort By: AVG(response_time) Descending
- Row Limit: 10
- 설명: 평균 응답 시간이 가장 느린 요청 URL 식별
7) Top 10 Errors by Request URL
- Chart Type: Table
- Dimensions: concat(host_domain, request_url)
- Metrics:
- COUNT(*) (Total Requests)
- Custom Metric:
SUM(CASE WHEN status_code >= 400 THEN 1 ELSE 0 END)(Error Count)
- Sort By: Error Count Descending
- Row Limit: 10
- 설명: 에러가 가장 많이 발생하는 URL 파악
8) Error List
- Query Mode: RAW RECORDS
- Filters: status_code >= 400
- Columns: kst_time, status_code, response_time, message
- Ordering: kst_time DESC
- 설명: 최근 에러 로그의 상세 메시지 확인
3단계: 대시보드 필터 적용 (Native Filters)
대시보드 전체를 동적으로 제어할 수 있도록 Time Range Filter를 추가합니다.
- Filter Type: Time Range
- Default Value: Current day
- 적용 범위: 모든 차트
성능 최적화 팁
대규모 트래픽 환경(초당 수천 건 이상)에서는 원본 테이블(quickstart.kong_log_events)을 직접 조회하면 대시보드 응답 속도가 저하될 수 있습니다.
권장 최적화 방법:
- StarRocks의 Materialized View를 활용하여 10분 단위 집계 테이블 생성
- 집계 테이블을 Superset Dataset으로 연결
- 실시간성은 유지하면서 쿼리 성능 대폭 개선
5. 결론
본 문서에서는 Kafka 기반의 스트리밍 아키텍처를 활용하여 API Gateway의 로그를 실시간으로 수집하고, StarRocks에 저장한 뒤 Apache Superset으로 시각화하는 전체 파이프라인을 구축하였습니다.
핵심 성과
- 실시간 모니터링: API Gateway의 요청 패턴, 응답 시간, 에러율 등을 실시간으로 파악
- 장애 대응 시간 단축: 에러 발생 시 실시간 상세 로그를 통해 빠른 원인 분석 가능
- 데이터 기반 의사결정: 프로젝트별 트래픽 분석을 통한 리소스 최적화 및 용량 계획 수립
- 확장 가능한 아키텍처: Kafka와 StarRocks의 조합으로 대용량 로그 처리에도 안정적인 성능 보장
향후 개선 방향
- 머신러닝 기반 이상 탐지: 평소 패턴 대비 비정상 트래픽 자동 감지
- 멀티 클러스터 지원: 여러 Kubernetes 클러스터의 로그를 통합 모니터링
이러한 실시간 로그 분석 시스템은 서비스 안정성 향상과 운영 효율성 증대에 크게 기여하며, DevOps 문화 정착의 핵심 인프라로 자리잡을 수 있습니다.