
DIP 플랫폼 TPC-DS 1 TB 벤치마크
TPC-DS SF-1000(1TB, 63억 행) 규모로 DIP 플랫폼의 Batch ELT 적재 성능(1,451K rows/sec)과 StarRocks 쿼리 응답 속도(GeoMean 2.2초)를 검증합니다. CN 노드 스케일링 효과와 Trino 대비 성능 우위, Iceberg 파티션 전략까지 정량 분석한 결과를 공유합니다.
목차
- 들어가며
- 핵심 결과 요약
- 1. 벤치마크 목적과 배경
- 2. 테스트 환경
- 3. 데이터 파이프라인 아키텍처
- 4. 데이터 생성 및 소스 적재
- 5. Batch ELT: Spark → Iceberg 적재
- 6. Query 성능 벤치마크
- 7. Iceberg 파티션 전략 비교
- 8. 발생 이슈 및 해결
- 9. 전체 결과 요약
- 10. 결론 및 권고사항
들어가며
DIP 플랫폼의 데이터 처리 역량을 TPC-DS 표준 벤치마크로 정량 검증하는 시리즈입니다. 이전 편(Part 1-1)에서는 SF-100(100GB) 규모로 Batch ELT와 Query 성능을 검증했습니다. 본 글에서는 SF-1000(1TB) 으로 스케일을 10배 확장하여, 대규모 데이터 환경에서의 적재 성능과 쿼리 응답 속도를 재검증합니다.
| 순서 | 테스트 영역 | 규모 | 블로그 |
|---|---|---|---|
| ① | Batch ELT + Query (SF-100) | 9.6억 행 / 30GB | Part 1-1 |
| ② | Batch ELT + Query (SF-1000) | 63억 행 / 1TB | 본 글 |
핵심 결과 요약
Batch ELT — 63억 행, 약 73분 적재 완료 (1,451K rows/sec) · SF-100 대비 처리량 4.9배 향상
Query — TPC-DS 99개 쿼리 100% 통과, Geometric Mean 2.198초 (CN4 Warm 기준) · Trino 대비 3.1배 빠른 응답
QphDS@1000 = 1,637,853 · S3 Object Storage 환경에서도 글로벌 경쟁력 확인
CN 스케일링 — CN3→CN5 확장으로 Warm Total 44.8% 개선, CN4가 비용 대비 최적 균형점
Trino 대비 — 99개 쿼리 중 97개에서 우위, 복잡 쿼리에서 최대 63배 빠름
1. 벤치마크 목적과 배경
SF-100 벤치마크에서 DIP 플랫폼의 성능을 검증하였으나, 실제 엔터프라이즈 환경에서는 수백 GB~수 TB 규모의 분석 워크로드가 일반적입니다. TPC-DS SF-1000(1TB)은 약 63억 행의 데이터를 다루며, 중대형 분석 워크로드의 성능을 평가하기에 적합한 스케일입니다.
본 벤치마크의 목적은 다음과 같습니다.
- 대규모 적재 성능 검증: 63억 행을 Iceberg로 적재하는 Batch ELT 파이프라인의 처리량 확인
- 쿼리 응답 속도 검증: SF-1000 규모에서 TPC-DS 99개 쿼리의 응답 시간 측정
- CN 노드 스케일링 효과: CN3/CN4/CN5 구성별 성능 변화 정량화
- 외부 비교: Trino와의 성능 비교
2. 테스트 환경
2.1 인프라 (Google Cloud)
| 구분 | 머신 타입 | vCPU | RAM | Boot Disk | Data Disk |
|---|---|---|---|---|---|
| rke2-node × 5 | n2-standard-16 | 16 | 64 GB | 200 GB pd-ssd | 1,000 GB pd-ssd |
| PostgreSQL × 1 | e2-standard-16 | 16 | 64 GB | 50 GB pd-ssd | 1,000 GB pd-ssd |
2.2 소프트웨어 스택
| 항목 | 버전 | 역할 |
|---|---|---|
| PostgreSQL | 16.x | 소스 RDBMS |
| Spark | 3.5.x | Batch ELT 엔진 |
| StarRocks | 4.0.8 (FE 1 + CN 3~5) | 분석 쿼리 엔진 |
| Lakekeeper | latest | Iceberg REST Catalog |
| GCS | — | S3 호환 오브젝트 스토리지 |
| DuckDB | — | 데이터 생성 및 Parquet → PostgreSQL 적재 |
2.3 StarRocks CN 노드 구성
| 항목 | 값 |
|---|---|
| CN 노드 수 | 3~5 (스케일링 테스트) |
| 노드당 vCPU | 15 core |
| 노드당 MemLimit | 50.859 GiB |
be.conf mem_limit |
90% |
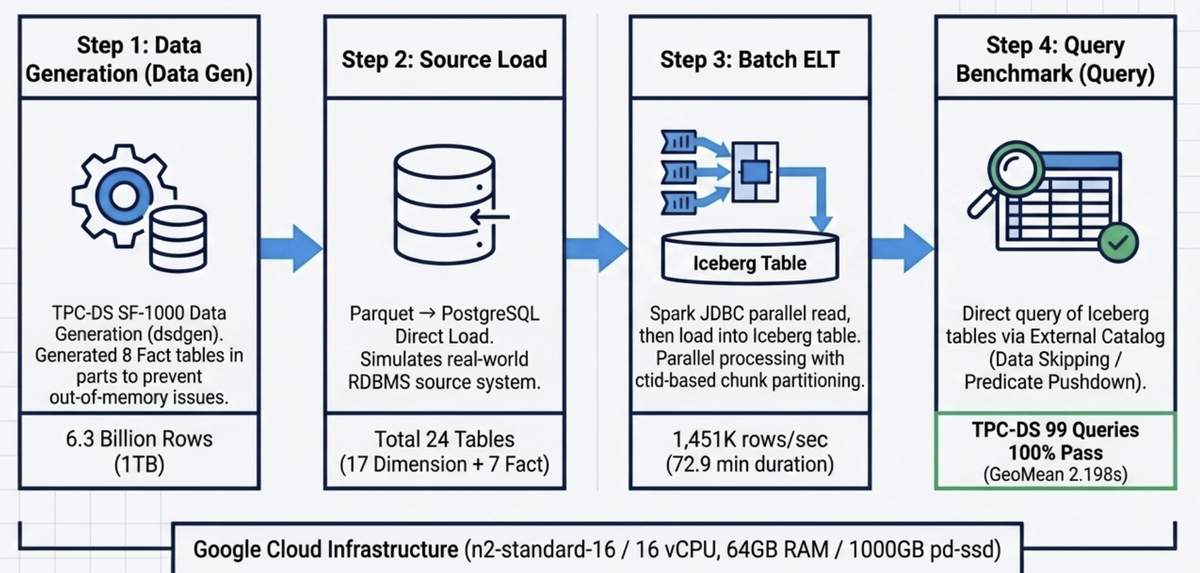
3. 데이터 파이프라인 아키텍처
전체 벤치마크 파이프라인은 4단계로 구성됩니다.
┌──────────────────────────────────────────────────────────────────────────────┐
│ DIP TPC-DS SF-1000 벤치마크 파이프라인 │
├──────────────────────────────────────────────────────────────────────────────┤
│ │
│ ① 데이터 생성 ② 소스 적재 ③ Batch ELT │
│ ┌───────────┐ ┌───────────┐ ┌───────────────┐ │
│ │ DuckDB │ Parquet │PostgreSQL │ JDBC │ Spark-Iceberg │ │
│ │ dsdgen() │────────▶│ tpcds │─────────▶│ Batch ELT │ │
│ │ SF-1000 │ 24 tbl │ _sf1000 │ ctid기반 │ │ │
│ │ (8분할) │ └───────────┘ 청크read └───────┬───────┘ │
│ └───────────┘ │ Write │
│ ▼ │
│ ④ 쿼리 벤치마크 ┌───────────────┐ │
│ ┌───────────────┐ External Catalog │ Iceberg │ │
│ │ StarRocks │◀────────────────────────────── │ (GCS) │ │
│ │ TPC-DS 99Q │ bmt_catalog.tpcds_sf1000 │ Lakekeeper │ │
│ └───────────────┘ └───────────────┘ │
│ │
└──────────────────────────────────────────────────────────────────────────────┘
- ① 데이터 생성: DuckDB의 TPC-DS 확장(
dsdgen)으로 SF-1000 데이터를 생성합니다. Fact 테이블은 메모리 부족(OOM) 방지를 위해 8개로 분할 생성 후 Parquet(ZSTD)으로 변환합니다. - ② 소스 적재: Parquet 파일을 DuckDB → PostgreSQL로 적재합니다. 실환경에서 원천 시스템이 RDBMS인 시나리오를 재현한 것입니다.
- ③ Batch ELT: Spark JDBC로 PostgreSQL을 읽어 Lakekeeper 기반 Iceberg 테이블에 적재합니다. ctid 기반 청크 분할 병렬 read 방식을 사용하여 I/O 병목을 해소합니다.
- ④ 쿼리 벤치마크: StarRocks External Catalog으로 Iceberg 테이블을 직접 조회하며, TPC-DS 99개 쿼리를 실행합니다.
4. 데이터 생성 및 소스 적재
4.1 TPC-DS SF-1000 데이터 생성
DuckDB dsdgen()으로 24개 테이블(Fact 7 + Dimension 17)을 생성하였습니다. SF-1000은 SF-100 대비 데이터 규모가 약 10배입니다.
| 구분 | 테이블 수 | 총 행 수 | 비고 |
|---|---|---|---|
| Fact | 7 | 6,326,962,833 | 8개 분할 생성 |
| Dimension | 17 | 20,313,689 | — |
| 합계 | 24 | 6,347,276,522 (~63억) | ~1 TB |
주요 Fact 테이블의 규모는 다음과 같습니다.
| 테이블 | 행 수 | SF-100 대비 |
|---|---|---|
| store_sales | 2,879,987,999 | ×10.0 |
| catalog_sales | 1,439,980,416 | ×10.0 |
| inventory | 783,000,000 | ×2.0 |
| web_sales | 720,000,376 | ×10.0 |
| store_returns | 287,999,764 | ×10.0 |
| catalog_returns | 143,996,756 | ×10.0 |
| web_returns | 71,997,522 | ×10.0 |
4.2 PostgreSQL 적재 결과
DuckDB postgres 확장으로 분할 Parquet 파일에서 PostgreSQL로 직접 적재하였습니다.
| 항목 | 값 |
|---|---|
| DuckDB memory_limit | 40 GB |
| DuckDB threads | 12 |
| chunk_size | 50,000,000 rows |
| 총 적재 테이블 | 24개 (Dimension 17 + Fact 7) |
5. Batch ELT: Spark → Iceberg 적재
5.1 적재 결과 요약
Spark JDBC로 PostgreSQL을 읽어 Lakekeeper 기반 Iceberg 테이블로 적재한 결과입니다.
| 항목 | 값 |
|---|---|
| 성공 테이블 | 24/24 (100%) |
| 총 적재 행 수 | 6,347,276,522 (~63억) |
| Phase 1 — Dimension (17개) | 67.1초 |
| Phase 2 — Fact (7개) | 4,305.9초 (~71.8분) |
| Wall-clock 시간 | 4,373.0초 (72.9분) |
| 순차 합산 시간 | 4,450.7초 |
| 동시성 효과 | 1.0× |
| 처리 속도 | 1,451K rows/sec |
SF-100에서 296K rows/sec이었던 처리 속도가 SF-1000에서 1,451K rows/sec로 약 4.9배 향상되었습니다. 이는 ctid 기반 청크 분할 병렬 read 방식의 도입과 대용량 테이블에서 JDBC 파티션 수를 대폭 확대(최대 240개)한 효과입니다.
적재는 2-Phase 전략으로 실행하였습니다. Phase 1에서 경량 Dimension 테이블 17개를 병렬 적재한 뒤, Phase 2에서 대형 Fact 테이블 7개를 병렬 적재합니다. 전체 시간의 98.5%는 Fact 테이블 적재에 소요됩니다.
5.2 Fact 테이블별 적재 성능
| 테이블 | 행 수 | 시간(초) | 처리량(rows/sec) | 파티션 컬럼 | ctid_chunks |
|---|---|---|---|---|---|
| store_sales | 2,879,987,999 | 1,824.2 | 1,578,776 | ss_sold_date_sk | 240 |
| catalog_sales | 1,439,980,416 | 1,296.1 | 1,111,044 | cs_sold_date_sk | 240 |
| web_sales | 720,000,376 | 671.6 | 1,072,138 | ws_sold_date_sk | 120 |
| inventory | 783,000,000 | 111.1 | 7,046,857 | inv_date_sk | 72 |
| store_returns | 287,999,764 | 207.1 | 1,390,741 | sr_returned_date_sk | 24 |
| catalog_returns | 143,996,756 | 125.4 | 1,148,081 | cr_returned_date_sk | 24 |
| web_returns | 71,997,522 | 70.5 | 1,021,434 | wr_returned_date_sk | 24 |
가장 큰 병목은 store_sales로, 약 29억 행을 처리하는 데 1,824초가 소요되었습니다. ctid_chunks를 240개로 설정하여 병렬도를 높였으며, 처리량은 1,578K rows/sec에 달합니다. inventory 테이블은 컬럼이 4개로 단순하여 7,046K rows/sec의 매우 높은 처리량을 기록하였습니다.
5.3 Spark 튜닝 상세
SF-1000 규모의 적재에서는 SF-100 대비 추가적인 튜닝이 필요하였습니다.
ctid 기반 청크 분할 읽기
SF-100에서는 일자(date) 기준 ORDER BY 정렬 후 JDBC read를 사용하였으나, SF-1000에서는 대용량 Fact 테이블(수십억 행)을 일자 컬럼으로 ORDER BY하면 PostgreSQL이 힙 전체를 random I/O로 접근하여 block I/O가 폭증하는 문제가 발생하였습니다.
이를 해결하기 위해 ctid(물리적 행 위치) 범위를 청크로 나눠 순차 read하는 방식으로 전환하였습니다. random I/O가 제거되어 속도가 크게 개선되었습니다.
Spark Executor 임시 디렉토리 공간 확보
대용량 Iceberg write 시 생성되는 임시 파일이 Kubernetes executor pod의 기본 ephemeral storage를 초과하는 문제가 발생하였습니다. 별도 임시 디렉토리 마운트와 함께 Spark 설정에 ephemeral storage 한도를 명시적으로 추가하여 해결하였습니다.
conf.set("spark.kubernetes.executor.request.ephemeral-storage", "30Gi")
conf.set("spark.kubernetes.executor.limit.ephemeral-storage", "50Gi")
검증 결과
PostgreSQL ↔ Iceberg 건수 비교에서 전체 24테이블 OK를 확인하였습니다. 데이터 정합성 100%를 달성하였습니다.
6. Query 성능 벤치마크
StarRocks External Catalog(bmt_catalog.tpcds_sf1000)를 통해 Iceberg 테이블에 TPC-DS 99개 쿼리를 실행하였습니다. StarRocks는 Iceberg 메타데이터를 활용한 Data Skipping과 Predicate Pushdown을 수행하며, 별도의 데이터 복제 없이 External Catalog 방식으로 직접 조회합니다.
6.1 Power Test — Cold Run / Warm Run
CN4(4노드) 구성에서 Cold 1회 + Warm 3회를 실행한 결과입니다. q78은 Hash Join 메모리 사용량이 높아 enable_spill=true를 적용하였고, 나머지 쿼리는 enable_spill=false로 실행하였습니다.
| 항목 | Cold Run | Warm Run (3회 평균) |
|---|---|---|
| 총 쿼리 | 99 | 99 |
| 성공 | 99 (100%) | 99 (100%) |
| 실패 | 0 | 0 |
| Geometric Mean | 4.376초 | 2.198초 |
| Total Time | 837.7초 | 481.1초 |
| Min | 0.131초 (q41) | 0.134초 (q41) |
| Max | 61.4초 (q23) | 60.5초 (q23) |
| Avg | 8.463초 | 4.859초 |
| query_mem_limit | 35 GB | 35 GB |
SF-100(GeoMean 1.474초)에서 SF-1000(GeoMean 2.198초)으로 데이터가 10배 증가했음에도 응답시간은 1.49배 증가에 그쳤습니다. 이는 StarRocks의 MPP 아키텍처와 Iceberg의 파티션 pruning이 대규모 데이터에서도 효과적으로 동작함을 의미합니다.
Cold Run과 Warm Run의 GeoMean 차이가 2.0배인 것은 SF-100(1.1% 차이)과 대비됩니다. 이는 SF-1000의 전체 데이터(~1TB) 대비 DataCache 커버율이 약 19%에 불과하여, Warm run에서도 81%는 GCS에서 재읽기해야 하기 때문입니다. 근본 원인은 datacache_max_flying_memory_mb 설정이 낮아 디스크 캐시 적재 속도가 병목인 것으로 분석됩니다.
6.2 CN 노드 스케일링 벤치마크 (CN3 / CN4 / CN5)
CN 노드 수를 3 → 4 → 5로 변경하며 성능 변화를 측정하였습니다. 모든 구성에서 Cold 1회 + Warm 3회를 실행하였으며, 99개 쿼리 모두 성공하였습니다.
전체 요약
| 지표 | CN3 | CN4 | CN5 | CN3→CN4 | CN4→CN5 | CN3→CN5 |
|---|---|---|---|---|---|---|
| Cold Total (s) | 892.4 | 837.7 | 474.9 | -6.1% | -43.3% | -46.8% |
| Cold Geo Mean (s) | 3.435 | 4.376 | 2.500 | +27.4% | -42.9% | -27.2% |
| Warm avg Total (s) | 732.0 | 481.1 | 404.0 | -34.3% | -16.0% | -44.8% |
| Warm avg Geo Mean (s) | 2.565 | 2.198 | 2.022 | -14.3% | -8.0% | -21.2% |
| Warm avg Avg (s) | 7.394 | 4.859 | 4.081 | -34.3% | -16.0% | -44.8% |
| Warm avg Max (s) | 164.75 (q67) | 60.52 (q23) | 46.62 (q23) | — | — | — |
CN3 Cold GeoMean(3.435)이 CN4(4.376)보다 낮은 이유: q67 cold가 CN3에서 180.8s로 Total을 크게 올리지만, 대부분의 단순 쿼리는 CN3 cold가 빠름. Warm에서는 CN3의 CPU/메모리 제한이 드러나 역전됨.
스케일링 효율 분석
| 구간 | 노드 증가율 | 이상적 개선율 | 실제 개선율 (Warm Total) | 효율 |
|---|---|---|---|---|
| CN3 → CN4 | +33% | 25.0% | +34.3% | 137% (초선형) |
| CN4 → CN5 | +25% | 20.0% | +16.0% | 80% (수확 체감) |
| CN3 → CN5 | +67% | 40.0% | +44.8% | 112% |
CN3→CN4 구간에서 초선형 개선(137%)이 발생한 이유는, CN3에서 메모리 압박을 받던 대형 쿼리(q67: 164초→43초)가 CN4에서 정상화되었기 때문입니다. CN4→CN5 구간에서는 S3 I/O 바운드 쿼리들이 노드 추가에도 한계에 도달하며 수확 체감(80%)이 나타났습니다.
CN3→CN5 개선 폭 Top 15 (warm_avg 절대 시간 기준)
| Query | CN3 | CN4 | CN5 | CN3→CN5 절대 | CN3→CN5 % |
|---|---|---|---|---|---|
| q67 | 164.750 | 42.965 | 33.869 | -130.9s | -79.4% |
| q23 | 93.381 | 60.517 | 46.623 | -46.8s | -50.1% |
| q78 | 60.817 | 47.162 | 32.424 | -28.4s | -46.7% |
| q09 | 32.543 | 24.829 | 20.361 | -12.2s | -37.4% |
| q28 | 20.870 | 14.915 | 12.573 | -8.3s | -39.8% |
| q88 | 20.198 | 14.614 | 12.593 | -7.6s | -37.7% |
| q04 | 18.302 | 13.438 | 11.293 | -7.0s | -38.3% |
| q75 | 16.476 | 13.602 | 10.490 | -6.0s | -36.3% |
| q65 | 15.772 | 12.367 | 9.773 | -6.0s | -38.0% |
| q50 | 15.334 | 12.079 | 9.804 | -5.5s | -36.1% |
| q97 | 13.412 | 10.849 | 8.461 | -5.0s | -36.9% |
| q14 | 13.280 | 10.942 | 8.578 | -4.7s | -35.4% |
| q11 | 10.084 | 7.508 | 6.336 | -3.7s | -37.2% |
| q24 | 10.030 | 7.239 | 6.477 | -3.6s | -35.4% |
| q38 | 6.432 | 5.107 | 4.296 | -2.1s | -33.2% |
CN5가 CN4보다 느린 쿼리 (★, warm_avg 기준, +5% 이상)
| Query | CN4 | CN5 | 차이 | 특징 |
|---|---|---|---|---|
| q44 | 8.327 | 10.799 | +29.7% | store_sales full scan + window func |
| q22 | 5.062 | 6.214 | +22.8% | inventory 12개월 집계 |
| q21 | 0.420 | 0.488 | +16.2% | inventory 단순 조인 |
| q33 | 1.218 | 1.348 | +10.7% | store_sales + date 필터 |
| q69 | 1.139 | 1.234 | +8.3% | multi-fact subquery |
| q58 | 0.908 | 0.983 | +8.3% | catalog/store/web 3-way |
| q98 | 0.863 | 0.929 | +7.6% | store_sales 날짜 범위 |
| q77 | 1.095 | 1.176 | +7.4% | multi-fact UNION |
| q68 | 1.007 | 1.076 | +6.9% | store_sales + date |
| q41 | 0.134 | 0.143 | +6.7% | fact 미사용 (item만) |
| q53 | 1.098 | 1.171 | +6.6% | store_sales 월별 |
| q42 | 0.400 | 0.423 | +5.7% | store_sales 단순 |
| q43 | 0.806 | 0.847 | +5.1% | store_sales 단순 |
대부분 0.5~10초 이하의 단순·소형 쿼리로, 노드 간 오버헤드(네트워크 조율, 플래너 분산 비용)가 실제 연산 시간보다 커지는 현상입니다. CN5에서 추가된 노드로 인한 조율 비용이 오히려 소형 쿼리에 부담을 줍니다.
q67 이상치 분석
| 구성 | cold | warm_1 | warm_2 | warm_3 | warm_avg |
|---|---|---|---|---|---|
| CN3 | 180.786 | 165.210 | 163.808 | 165.232 | 164.750 |
| CN4 | 43.278 | 42.335 | 44.067 | 42.494 | 42.965 |
| CN5 | 33.301 | 34.234 | 33.618 | 33.756 | 33.869 |
q67(store_sales 12개월 다차원 rollup)은 CN3에서 Warm run에도 164초로 안정되지 않았습니다. CN4에서 43초로 약 4배 단축, CN5에서 34초로 추가 단축되었습니다. CN3에서 메모리 부족으로 중간 결과를 spill하는 것이 원인으로 추정됩니다. CN3는 SF-1000 환경에서 운영 불가 수준으로, 최소 CN4 이상이 권장됩니다.
쿼리별 CN3 / CN4 / CN5 비교표 (Warm avg, 단위: 초)
★ = CN5가 CN4보다 느린 쿼리 (warm_avg 기준, +5% 이상)
▲ = CN3 대비 CN5 개선율 50% 이상
| Query | CN3 | CN4 | CN5 | CN3→CN4 | CN4→CN5 | CN3→CN5 | 비고 |
|---|---|---|---|---|---|---|---|
| q01 | 1.696 | 1.578 | 1.299 | -7.0% | -17.7% | -23.4% | |
| q02 | 2.735 | 1.999 | 1.757 | -26.9% | -12.1% | -35.8% | |
| q03 | 0.924 | 0.807 | 0.704 | -12.7% | -12.8% | -23.8% | |
| q04 | 18.302 | 13.438 | 11.293 | -26.6% | -16.0% | -38.3% | |
| q05 | 2.259 | 1.846 | 1.832 | -18.3% | -0.8% | -18.9% | |
| q06 | 0.756 | 0.725 | 0.755 | -4.1% | +4.1% | -0.1% | |
| q07 | 2.456 | 1.759 | 1.788 | -28.4% | +1.6% | -27.2% | |
| q08 | 0.720 | 0.744 | 0.741 | +3.3% | -0.4% | +2.9% | |
| q09 | 32.543 | 24.829 | 20.361 | -23.7% | -18.0% | -37.4% | |
| q10 | 1.225 | 1.166 | 1.169 | -4.8% | +0.3% | -4.6% | |
| q11 | 10.084 | 7.508 | 6.336 | -25.6% | -15.6% | -37.2% | |
| q12 | 0.471 | 0.552 | 0.461 | +17.2% | -16.5% | -2.1% | |
| q13 | 3.216 | 2.513 | 2.120 | -21.9% | -15.6% | -34.1% | |
| q14 | 13.280 | 10.942 | 8.578 | -17.6% | -21.6% | -35.4% | |
| q15 | 1.075 | 2.378 | 2.305 | +121.2% | -3.1% | +114.4% | ★ |
| q16 | 1.370 | 1.236 | 1.247 | -9.8% | +0.9% | -9.0% | |
| q17 | 3.130 | 2.583 | 2.115 | -17.5% | -18.1% | -32.4% | |
| q18 | 2.203 | 2.120 | 1.884 | -3.8% | -11.1% | -14.5% | |
| q19 | 0.920 | 0.805 | 0.807 | -12.5% | +0.2% | -12.3% | |
| q20 | 0.491 | 0.481 | 0.487 | -2.0% | +1.2% | -0.8% | |
| q21 | 0.434 | 0.420 | 0.488 | -3.2% | +16.2% | +12.4% | ★ |
| q22 | 6.223 | 5.062 | 6.214 | -18.7% | +22.8% | -0.1% | ★ |
| q23 | 93.381 | 60.517 | 46.623 | -35.2% | -23.0% | -50.1% | ▲ |
| q24 | 10.030 | 7.239 | 6.477 | -27.8% | -10.5% | -35.4% | |
| q25 | 2.471 | 2.067 | 1.805 | -16.4% | -12.7% | -26.9% | |
| q26 | 1.277 | 1.126 | 0.992 | -11.8% | -11.9% | -22.3% | |
| q27 | 1.973 | 1.547 | 1.396 | -21.6% | -9.8% | -29.2% | |
| q28 | 20.870 | 14.915 | 12.573 | -28.5% | -15.7% | -39.8% | |
| q29 | 6.057 | 5.096 | 4.200 | -15.9% | -17.6% | -30.7% | |
| q30 | 1.455 | 1.433 | 1.392 | -1.5% | -2.9% | -4.3% | |
| q31 | 2.465 | 1.990 | 1.857 | -19.3% | -6.7% | -24.7% | |
| q32 | 0.507 | 0.462 | 0.472 | -8.9% | +2.2% | -6.9% | |
| q33 | 1.270 | 1.218 | 1.348 | -4.1% | +10.7% | +6.1% | ★ |
| q34 | 1.237 | 1.042 | 1.058 | -15.8% | +1.5% | -14.5% | |
| q35 | 2.262 | 2.042 | 2.014 | -9.7% | -1.4% | -11.0% | |
| q36 | 2.066 | 1.657 | 1.377 | -19.8% | -16.9% | -33.3% | |
| q37 | 1.792 | 1.444 | 1.272 | -19.4% | -11.9% | -29.0% | |
| q38 | 6.432 | 5.107 | 4.296 | -20.6% | -15.9% | -33.2% | |
| q39 | 0.949 | 0.875 | 0.813 | -7.8% | -7.1% | -14.3% | |
| q40 | 0.710 | 2.371 | 0.800 | +233.9% | -66.3% | +12.7% | |
| q41 | 0.133 | 0.134 | 0.143 | +0.8% | +6.7% | +7.5% | ★ |
| q42 | 0.434 | 0.400 | 0.423 | -7.8% | +5.7% | -2.5% | ★ |
| q43 | 1.105 | 0.806 | 0.847 | -27.1% | +5.1% | -23.3% | ★ |
| q44 | 13.563 | 8.327 | 10.799 | -38.6% | +29.7% | -20.4% | ★ |
| q45 | 1.186 | 1.142 | 1.085 | -3.7% | -5.0% | -8.5% | |
| q46 | 2.161 | 1.765 | 1.663 | -18.3% | -5.8% | -23.0% | |
| q47 | 5.396 | 4.752 | 3.721 | -11.9% | -21.7% | -31.0% | |
| q48 | 2.157 | 1.656 | 1.680 | -23.2% | +1.4% | -22.1% | |
| q49 | 2.591 | 1.953 | 1.829 | -24.6% | -6.3% | -29.4% | |
| q50 | 15.334 | 12.079 | 9.804 | -21.2% | -18.8% | -36.1% | |
| q51 | 8.072 | 6.118 | 4.908 | -24.2% | -19.8% | -39.2% | |
| q52 | 0.434 | 0.420 | 0.437 | -3.2% | +4.0% | +0.7% | |
| q53 | 1.425 | 1.098 | 1.171 | -22.9% | +6.6% | -17.8% | ★ |
| q54 | 1.224 | 1.044 | 1.072 | -14.7% | +2.7% | -12.4% | |
| q55 | 0.430 | 0.419 | 0.407 | -2.6% | -2.9% | -5.3% | |
| q56 | 0.965 | 0.956 | 0.999 | -0.9% | +4.5% | +3.5% | |
| q57 | 3.919 | 3.640 | 2.854 | -7.1% | -21.6% | -27.2% | |
| q58 | 0.979 | 0.908 | 0.983 | -7.3% | +8.3% | +0.4% | ★ |
| q59 | 5.342 | 3.841 | 3.237 | -28.1% | -15.7% | -39.4% | |
| q60 | 1.226 | 1.219 | 1.176 | -0.6% | -3.5% | -4.1% | |
| q61 | 1.652 | 1.574 | 1.464 | -4.7% | -7.0% | -11.4% | |
| q62 | 1.456 | 1.193 | 1.017 | -18.1% | -14.8% | -30.1% | |
| q63 | 1.420 | 1.081 | 1.081 | -23.9% | +0.0% | -23.9% | |
| q64 | 12.278 | 9.353 | 8.643 | -23.8% | -7.6% | -29.6% | |
| q65 | 15.772 | 12.367 | 9.773 | -21.6% | -21.0% | -38.0% | |
| q66 | 1.685 | 1.423 | 1.284 | -15.5% | -9.8% | -23.8% | |
| q67 | 164.750 | 42.965 | 33.869 | -73.9% | -21.2% | -79.4% | ▲ |
| q68 | 1.162 | 1.007 | 1.076 | -13.3% | +6.9% | -7.4% | ★ |
| q69 | 1.223 | 1.139 | 1.234 | -6.9% | +8.3% | +0.9% | ★ |
| q70 | 5.319 | 3.763 | 3.854 | -29.3% | +2.4% | -27.5% | ★ |
| q71 | 2.001 | 1.910 | 1.882 | -4.6% | -1.5% | -5.9% | |
| q72 | 8.816 | 7.998 | 6.291 | -9.3% | -21.3% | -28.6% | |
| q73 | 0.769 | 0.832 | 0.770 | +8.2% | -7.5% | +0.1% | |
| q74 | 8.351 | 6.147 | 5.246 | -26.4% | -14.7% | -37.2% | |
| q75 | 16.476 | 13.602 | 10.490 | -17.4% | -22.9% | -36.3% | |
| q76 | 11.943 | 10.518 | 10.004 | -11.9% | -4.9% | -16.2% | |
| q77 | 1.191 | 1.095 | 1.176 | -8.1% | +7.4% | -1.3% | ★ |
| q78 | 60.817 | 47.162 | 32.424 | -22.4% | -31.3% | -46.7% | |
| q79 | 2.283 | 2.118 | 1.741 | -7.2% | -17.8% | -23.7% | |
| q80 | 5.779 | 4.609 | 4.016 | -20.2% | -12.9% | -30.5% | |
| q81 | 1.560 | 1.453 | 1.420 | -6.9% | -2.3% | -9.0% | |
| q82 | 3.302 | 2.392 | 2.219 | -27.6% | -7.2% | -32.8% | |
| q83 | 0.848 | 0.811 | 0.809 | -4.4% | -0.2% | -4.6% | |
| q84 | 1.299 | 1.268 | 1.239 | -2.4% | -2.3% | -4.6% | |
| q85 | 2.136 | 2.048 | 1.925 | -4.1% | -6.0% | -9.9% | |
| q86 | 1.616 | 1.144 | 1.163 | -29.2% | +1.7% | -28.0% | |
| q87 | 6.678 | 5.091 | 4.505 | -23.8% | -11.5% | -32.5% | |
| q88 | 20.198 | 14.614 | 12.593 | -27.6% | -13.8% | -37.7% | |
| q89 | 1.515 | 1.378 | 1.122 | -9.0% | -18.6% | -25.9% | |
| q90 | 1.567 | 1.298 | 1.218 | -17.2% | -6.2% | -22.3% | |
| q91 | 0.852 | 0.805 | 0.814 | -5.5% | +1.1% | -4.5% | |
| q92 | 0.437 | 0.400 | 0.411 | -8.5% | +2.7% | -5.9% | |
| q93 | 8.565 | 6.319 | 5.448 | -26.2% | -13.8% | -36.4% | |
| q94 | 1.627 | 1.335 | 1.311 | -17.9% | -1.8% | -19.4% | |
| q95 | 3.700 | 3.047 | 2.948 | -17.6% | -3.2% | -20.3% | |
| q96 | 2.514 | 1.871 | 1.693 | -25.6% | -9.5% | -32.7% | |
| q97 | 13.412 | 10.849 | 8.461 | -19.1% | -22.0% | -36.9% | |
| q98 | 0.980 | 0.863 | 0.929 | -11.9% | +7.6% | -5.2% | ★ |
| q99 | 2.297 | 1.913 | 1.714 | -16.7% | -10.4% | -25.4% |
스케일링 결론 및 권고
| 비교 | Warm Total | Warm GeoMean | 판단 |
|---|---|---|---|
| CN3 | 732.0s | 2.565s | 메모리 압박, q67 병목 |
| CN4 | 481.1s | 2.198s | 균형점 |
| CN5 | 404.0s | 2.022s | 추가 개선, 일부 역효과 |
- CN4 → CN5 투자 대비 효과: warm_avg Total 16.0% 개선, 노드 1개 추가(+25%) 대비 효율 80%. 절대 시간 감소 77.1초.
- CN3는 운영 불가 수준: q67 warm 164초는 SLA 위반 수준. q23(93초), q78(61초)도 CN4 대비 2배 이상.
- CN5 권고 조건: 복잡한 집계/조인 쿼리 비중이 높을 때 효과적. 단순 소형 쿼리(1초 미만) 위주 워크로드에서는 q44, q22, q21 등에서 소폭 퇴보하므로 해당 쿼리 SLA 요건 확인 필요.
6.3 Trino 비교
동일 SF-1000 규모에서 Trino Official 벤치마크와 비교하였습니다.
환경 비교
| 항목 | Our (CN4) | Trino Official |
|---|---|---|
| 엔진 버전 | StarRocks 4.0.8 | Trino 475 |
| 노드 구성 | CN × 4 | Coordinator 1 + Worker 4 |
| vCPU/노드 | 15 core | 16 core |
| 메모리/노드 | 50.9 GiB | 64 GiB |
| 스토리지 | S3 Object Storage | NVMe SSD |
| 테이블 형식 | Iceberg (Lakekeeper REST) | Iceberg Catalog |
| query_mem_limit | 35 GB/CN | 35 GB/Worker |
핵심 차이: Trino Official은 NVMe 로컬 SSD를 사용하고, Our는 S3 Object Storage(원격 I/O)를 사용합니다. S3의 불리한 I/O 조건에서도 StarRocks가 Trino를 크게 상회합니다.
전체 요약 비교
| 지표 | Our CN4 (Warm avg) | Trino Official | 비율 |
|---|---|---|---|
| Total | 481.1s | 2,552.1s | Our 5.30× 빠름 |
| Geo Mean | 2.198s | 6.782s | Our 3.09× 빠름 |
| Min | 0.134s (q41) | 0.271s (q41) | — |
| Max | 60.5s (q23) | 504.6s (q72) | — |
Our CN4가 Trino 대비 5.30배 빠릅니다 (Total 기준). 99개 쿼리 중 97개에서 우위를 보였습니다.
Trino 대비 압도적 우위 쿼리 Top 10
| Query | Our(s) | Trino(s) | Speedup | 특징 |
|---|---|---|---|---|
| q72 | 7.998 | 504.573 | 63.1× | catalog_sales + inventory + catalog_returns 3-way join |
| q54 | 1.044 | 31.864 | 30.5× | catalog_sales + store_sales + web_sales 복합 subquery |
| q11 | 7.508 | 133.230 | 17.7× | year-over-year self-join |
| q04 | 13.438 | 200.249 | 14.9× | 3개 fact 테이블 3년 범위 |
| q14 | 10.942 | 143.172 | 13.1× | store_sales 3회 self-join |
| q74 | 6.147 | 78.071 | 12.7× | store_sales + web_sales year-over-year |
| q16 | 1.236 | 14.035 | 11.4× | catalog_returns + catalog_sales |
| q02 | 1.999 | 21.289 | 10.7× | web_sales + catalog_sales 월별 비교 |
| q95 | 3.047 | 29.607 | 9.7× | web_sales + web_returns |
| q47 | 4.752 | 42.704 | 9.0× | store_sales window function |
Trino가 Our보다 빠른 쿼리
| Query | Our(s) | Trino(s) | 배율 |
|---|---|---|---|
| q40 | 2.371 | 1.554 | Trino 1.53× 빠름 |
| q15 | 2.378 | 2.158 | Trino 1.10× 빠름 |
q40, q15 모두 catalog_sales 단순 날짜 필터 쿼리로, Trino의 Iceberg 파일 pruning이 특정 패턴에서 유리하게 작동한 것으로 추정됩니다.
쿼리별 Our vs Trino 비교표 (Warm avg, 단위: 초)
Tri/Our: 값이 클수록 Our가 유리
| Query | Our(s) | Trino(s) | Tri/Our | 비고 |
|---|---|---|---|---|
| q01 | 1.578 | 2.276 | 1.44× | |
| q02 | 1.999 | 21.289 | 10.65× | |
| q03 | 0.807 | 1.764 | 2.19× | |
| q04 | 13.438 | 200.249 | 14.90× | |
| q05 | 1.846 | 5.574 | 3.02× | |
| q06 | 0.725 | 2.909 | 4.01× | |
| q07 | 1.759 | 3.638 | 2.07× | |
| q08 | 0.744 | 2.534 | 3.41× | |
| q09 | 24.829 | 36.125 | 1.45× | |
| q10 | 1.166 | 2.471 | 2.12× | |
| q11 | 7.508 | 133.230 | 17.75× | |
| q12 | 0.552 | 1.067 | 1.93× | |
| q13 | 2.513 | 18.297 | 7.28× | |
| q14 | 10.942 | 143.172 | 13.08× | |
| q15 | 2.378 | 2.158 | 0.91× | Trino 빠름 |
| q16 | 1.236 | 14.035 | 11.36× | |
| q17 | 2.583 | 5.487 | 2.12× | |
| q18 | 2.120 | 4.736 | 2.23× | |
| q19 | 0.805 | 1.870 | 2.32× | |
| q20 | 0.481 | 1.257 | 2.61× | |
| q21 | 0.420 | 0.945 | 2.25× | |
| q22 | 5.062 | 7.871 | 1.55× | |
| q23 | 60.517 | 488.653 | 8.07× | |
| q24 | 7.239 | 43.436 | 6.00× | |
| q25 | 2.067 | 4.347 | 2.10× | |
| q26 | 1.126 | 2.961 | 2.63× | |
| q27 | 1.547 | 4.219 | 2.73× | |
| q28 | 14.915 | 24.678 | 1.65× | |
| q29 | 5.096 | 10.640 | 2.09× | |
| q30 | 1.433 | 2.770 | 1.93× | |
| q31 | 1.990 | 10.260 | 5.16× | |
| q32 | 0.462 | 1.035 | 2.24× | |
| q33 | 1.218 | 2.743 | 2.25× | |
| q34 | 1.042 | 2.455 | 2.36× | |
| q35 | 2.042 | 8.023 | 3.93× | |
| q36 | 1.657 | 3.342 | 2.02× | |
| q37 | 1.444 | 6.178 | 4.28× | |
| q38 | 5.107 | 38.408 | 7.52× | |
| q39 | 0.875 | 5.696 | 6.51× | |
| q40 | 2.371 | 1.554 | 0.66× | Trino 빠름 |
| q41 | 0.134 | 0.271 | 2.02× | |
| q42 | 0.400 | 0.996 | 2.49× | |
| q43 | 0.806 | 4.108 | 5.10× | |
| q44 | 8.327 | 16.468 | 1.98× | |
| q45 | 1.142 | 2.212 | 1.94× | |
| q46 | 1.765 | 4.780 | 2.71× | |
| q47 | 4.752 | 42.704 | 8.99× | |
| q48 | 1.656 | 12.464 | 7.53× | |
| q49 | 1.953 | 3.827 | 1.96× | |
| q50 | 12.079 | 21.771 | 1.80× | |
| q51 | 6.118 | 12.247 | 2.00× | |
| q52 | 0.420 | 1.007 | 2.40× | |
| q53 | 1.098 | 1.768 | 1.61× | |
| q54 | 1.044 | 31.864 | 30.52× | |
| q55 | 0.419 | 1.187 | 2.83× | |
| q56 | 0.956 | 2.133 | 2.23× | |
| q57 | 3.640 | 26.042 | 7.15× | |
| q58 | 0.908 | 3.032 | 3.34× | |
| q59 | 3.841 | 20.819 | 5.42× | |
| q60 | 1.219 | 2.749 | 2.26× | |
| q61 | 1.574 | 2.054 | 1.30× | |
| q62 | 1.193 | 5.104 | 4.28× | |
| q63 | 1.081 | 1.719 | 1.59× | |
| q64 | 9.353 | 16.990 | 1.82× | |
| q65 | 12.367 | 20.616 | 1.67× | |
| q66 | 1.423 | 3.511 | 2.47× | |
| q67 | 42.965 | 89.430 | 2.08× | |
| q68 | 1.007 | 2.883 | 2.86× | |
| q69 | 1.139 | 2.181 | 1.91× | |
| q70 | 3.763 | 21.499 | 5.71× | |
| q71 | 1.910 | 2.578 | 1.35× | |
| q72 | 7.998 | 504.573 | 63.09× | |
| q73 | 0.832 | 1.933 | 2.32× | |
| q74 | 6.147 | 78.071 | 12.70× | |
| q75 | 13.602 | 26.270 | 1.93× | |
| q76 | 10.518 | 11.266 | 1.07× | |
| q77 | 1.095 | 2.785 | 2.54× | |
| q78 | 47.162 | 51.497 | 1.09× | |
| q79 | 2.118 | 5.572 | 2.63× | |
| q80 | 4.609 | 4.762 | 1.03× | |
| q81 | 1.453 | 4.040 | 2.78× | |
| q82 | 2.392 | 11.622 | 4.86× | |
| q83 | 0.811 | 2.274 | 2.80× | |
| q84 | 1.268 | 3.086 | 2.43× | |
| q85 | 2.048 | 5.424 | 2.65× | |
| q86 | 1.144 | 3.422 | 2.99× | |
| q87 | 5.091 | 41.300 | 8.11× | |
| q88 | 14.614 | 30.738 | 2.10× | |
| q89 | 1.378 | 2.227 | 1.62× | |
| q90 | 1.298 | 3.890 | 3.00× | |
| q91 | 0.805 | 2.035 | 2.53× | |
| q92 | 0.400 | 0.994 | 2.48× | |
| q93 | 6.319 | 22.926 | 3.63× | |
| q94 | 1.335 | 5.884 | 4.41× | |
| q95 | 3.047 | 29.607 | 9.72× | |
| q96 | 1.871 | 4.905 | 2.62× | |
| q97 | 10.849 | 22.726 | 2.09× | |
| q98 | 0.863 | 1.911 | 2.21× | |
| q99 | 1.913 | 10.970 | 5.73× |
7. Iceberg 파티션 전략 비교
기존 Fact 테이블의 *_date_sk 기준 파티셔닝(1,823개 파티션, 파일당 ~20MB)이 Small Files Problem을 야기하는지 검증하고, 파티션 제거 + date_sk 정렬(Union 방식)과의 성능 차이를 측정하였습니다.
실험 조건
| 항목 | Original | Union |
|---|---|---|
| 파티션 | *_date_sk (1,823개) |
없음 |
| 파일 정렬 | PostgreSQL ctid 순 | date_sk ASC |
| 파일 수 (store_sales 기준) | 1,823개 × ~20MB | ~56개 × ~500MB |
전체 요약 결과
| 지표 | Original | Union | 차이 |
|---|---|---|---|
| Warm avg Total | 481.1s | 538.6s | +11.9% |
| Warm avg Geo Mean | 2.198s | 2.396s | +9.0% |
| 쿼리별 분류 (±5%) | — | 개선 18 / 중립 35 / 퇴보 46 | — |
Union 방식은 전체적으로 Original 대비 성능이 낮습니다. Small Files Problem이 예상보다 심각하지 않은 이유는 두 가지입니다.
첫째, DataCache가 Warm run부터 small files I/O 오버헤드를 흡수합니다. DataCache는 파일 단위로 캐시하므로 작은 파일도 Warm 재실행 시 온전히 캐시됩니다. Cold에서만 유리했던 Union의 "큰 파일" 장점이 Warm에서 사라집니다.
둘째, StarRocks의 DPP(Dynamic Partition Pruning)가 1,823개 파티션에서도 효과적으로 동작합니다. Union 방식에서는 파티션 정보가 없어 Iceberg 파일 통계(min/max) 기반 pruning으로 대체되지만, 효율이 크게 떨어집니다. 특히 inventory 테이블(4컬럼)은 Union 시 파일 수가 4~10개로 극히 적어 파일 수준 pruning이 거의 동작하지 않으며, q21(+149%), q39(+101%), q72(+162%)에서 심각한 성능 퇴보가 발생하였습니다.
결론: Original 파티션 전략(*_date_sk)을 유지하는 것이 현재 환경에서 최적입니다.
8. 발생 이슈 및 해결
벤치마크 과정에서 발생한 주요 이슈와 해결 과정을 정리합니다.
| # | 이슈 | 원인 | 해결 |
|---|---|---|---|
| 1 | dat 생성 중 OOM | SF-1000 Fact 테이블 dat 파일 생성 시 메모리 부족 | Fact 테이블 dat 파일을 8개로 분할 생성 |
| 2 | PostgreSQL 적재 중단 | catalog_sales 적재 중 chunk 14에서 중단 | resume_sf1000.py로 chunk 15부터 이어서 적재 |
| 3 | PG→Iceberg block I/O 폭증 | date 컬럼 ORDER BY 시 PostgreSQL 전체 힙 random access | ctid 기반 청크 분할 병렬 read로 전환 |
| 4 | Spark Executor 공간 부족 | K8s pod ephemeral storage 한도 초과 | ephemeral-storage 30Gi/50Gi 명시 설정 |
| 5 | CN 노드 메모리 분석 | exec_mem_limit 변수명 미존재 (구버전) |
query_mem_limit로 수정 (이미 반영) |
| 6 | q78 OOM | 대형 Fact 테이블 간 Hash Join 메모리 초과 | q78만 enable_spill=true 적용 |
| 7 | DataCache 커버율 19% | datacache_max_flying_memory_mb=2 설정 |
2048로 증가 권장 (kubectl 권한 필요) |
9. 전체 결과 요약
9.1 Batch ELT 결과
| 항목 | SF-100 | SF-1000 |
|---|---|---|
| 테이블 수 | 24 | 24 |
| 총 행 수 | 9.6억 | 63억 |
| 적재 시간 | 54분 | 72.9분 |
| 처리 속도 | 296K rows/sec | 1,451K rows/sec |
| 정합성 | 100% | 100% |
9.2 Query 성능 결과 (CN4 기준)
| Run | 쿼리 수 | 성공률 | Geometric Mean | Total Time |
|---|---|---|---|---|
| Cold | 99 | 100% | 4.376초 | 837.7초 |
| Warm (3회 평균) | 99 | 100% | 2.198초 | 481.1초 |
9.3 CN 스케일링 결과
| CN 구성 | Warm Geo Mean | Warm Total | CN3 대비 |
|---|---|---|---|
| CN3 | 2.565s | 732.0s | baseline |
| CN4 | 2.198s | 481.1s | -34.3% |
| CN5 | 2.022s | 404.0s | -44.8% |
9.4 Trino 비교 결과
| 비교 대상 | Total 차이 | Geo Mean 차이 | 주요 원인 |
|---|---|---|---|
| Our vs Trino | Our 5.30× 빠름 | Our 3.09× 빠름 | StarRocks 쿼리 엔진 최적화 |
9.5 핵심 성능 지표
벤치마크 결과를 세 가지 관점에서 정리합니다.
① 종합 성능 지표: QphDS@1000
| 항목 | 값 |
|---|---|
| 산출 공식 | SF × 3,600 / GeoMean(초) |
| SF | 1,000 |
| GeoMean (Warm avg, CN4) | 2.198초 |
| QphDS@1000 | 1,637,853 |
산출:
1,000 × 3,600 / 2.198 = 1,637,853. SF-100의 QphDS@100(244,234) 대비 약 6.7배 증가한 수치로, 스케일 팩터 증가(10배)에 비해 성능 저하가 1.5배에 불과함을 보여줍니다.
② 체감 성능 지표: Query Geometric Mean
| 항목 | 값 |
|---|---|
| GeoMean (Cold, CN4) | 4.376초 |
| GeoMean (Warm avg, CN4) | 2.198초 |
| GeoMean (Warm avg, CN5) | 2.022초 |
| Trino 대비 | 3.09배 빠름 |
1TB 규모의 데이터를 S3 Object Storage에서 조회하면서도 Warm 기준 평균 2.2초 이내 응답은, 분석가의 대화형 쿼리 흐름을 충분히 지원할 수 있는 수준입니다.
③ 스케일 효율 지표: SF-100 → SF-1000
| 지표 | SF-100 | SF-1000 | 배율 |
|---|---|---|---|
| 데이터 규모 | 9.6억 행 / 30GB | 63억 행 / 1TB | ×10 |
| 적재 처리량 | 296K rows/sec | 1,451K rows/sec | ×4.9 |
| Query GeoMean | 1.474초 | 2.198초 | ×1.49 |
| QphDS | 244,234 | 1,637,853 | ×6.7 |
데이터가 10배 증가했을 때 쿼리 응답시간은 1.5배 증가에 그쳐, 서브-리니어(sub-linear) 스케일링을 달성하였습니다.
10. 결론 및 권고사항
10.1 결론
Batch ELT는 SF-1000 기준 24개 테이블, 63억 행을 약 73분에 Iceberg 적재 완료하였습니다(1,451K rows/sec). SF-100(296K rows/sec) 대비 4.9배 향상된 처리량으로, ctid 기반 청크 분할 병렬 read와 대규모 JDBC 파티셔닝의 효과를 확인하였습니다.
Query 성능은 TPC-DS 99개 쿼리 전량 통과, CN4 Warm 기준 Geometric Mean 2.198초를 기록하였습니다. 데이터가 10배 증가했음에도 GeoMean은 1.5배 증가에 불과하여, StarRocks MPP 아키텍처와 Iceberg 파티션 pruning의 확장성을 입증합니다. S3 환경의 불리함에도 불구하고 Trino 대비 5.3배 빠른 성능을 보였습니다.
CN 스케일링은 CN4가 비용 대비 최적 균형점으로 확인되었습니다. CN3→CN4에서 초선형 개선(137% 효율)이 발생한 반면, CN4→CN5에서는 S3 I/O 바운드로 수확 체감(80% 효율)이 나타났습니다. CN3는 q67(164초)에서 SLA 위반 수준의 병목이 발생하여 운영 불가로 판단됩니다.
파티션 전략은 Original(*_date_sk 파티셔닝)이 Union(파티션 제거) 대비 전반적으로 우수합니다. DataCache가 Small Files I/O를 효과적으로 흡수하고, DPP가 1,823개 파티션에서도 정확히 동작하기 때문입니다.
10.2 권고사항
| 항목 | 권고 내용 |
|---|---|
| CN 노드 구성 | 최소 CN4 이상 권장. CN3는 SF-1000 운영 불가 |
| DataCache 최적화 | datacache_max_flying_memory_mb를 2048로 증가 → Cold/Warm 격차 해소 기대 |
| q78 Spill | enable_spill=true 유지 (Hash Join 메모리 초과 방지) |
| 파티션 전략 | *_date_sk 기반 파티셔닝 유지 |
| CN 메모리 증설 | query_mem_limit=62 GiB |
본 벤치마크는 DIP v1.0 플랫폼 위에서 수행되었습니다. 환경이나 설정에 따라 결과가 달라질 수 있습니다.