
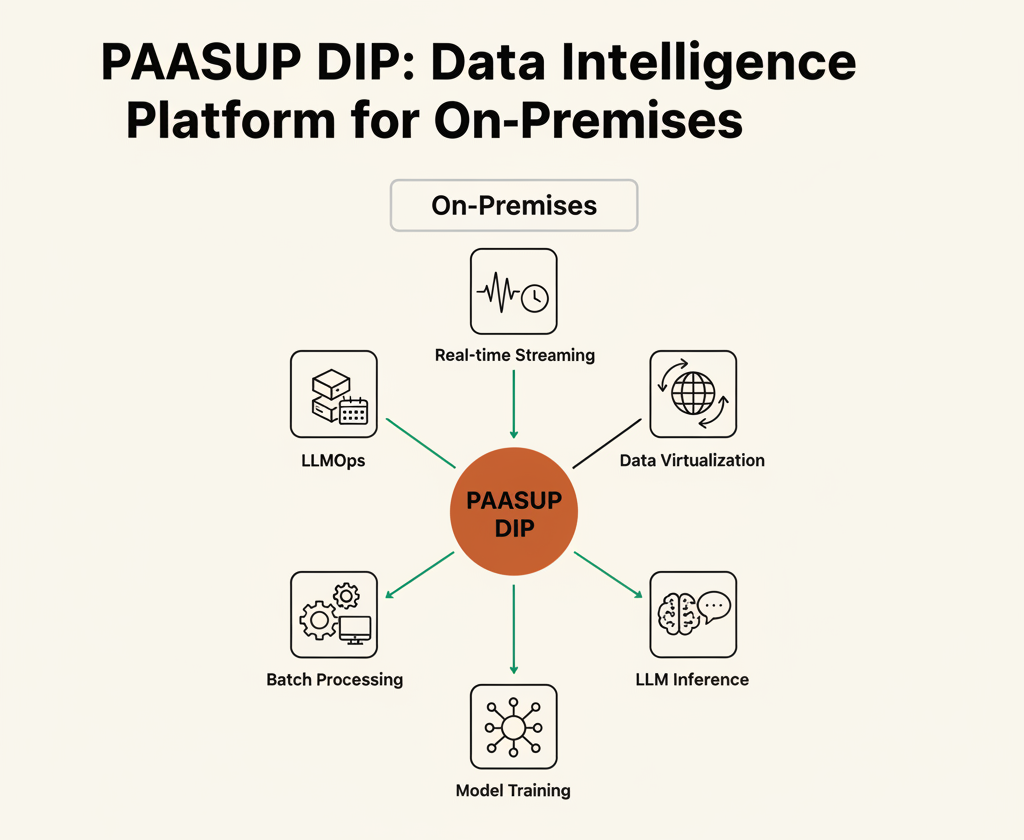
DIP: 온프레미스에서 완성되는 데이터 인텔리전스 플랫폼
AI와 데이터는 클라우드에 올려야만 작동하는 게 아니다. 기업이 가장 중요한 데이터를 클라우드에 올리지 못하는 이유는 분명하다 - 규제, 보안, 주권. PAASUP DIP(Data Intelligence Platform)는 퓨어 오픈소스 기반의 현대적 빅데이터·지능화 서비스를 온프레미스에서 그대로 제공한다.
This post is for subscribers only
Already have an account? Sign in.