
DIP 플랫폼 TPC-DS 벤치마크 — Part 2. 실시간 CDC 성능 비교
PostgreSQL → Iceberg CDC 3가지 경로를 9.6억 건 기준으로 벤치마크. 파이프라인 단순성과 실시간 처리 균형 면에서 Flink CDC가 가장 유력한 선택지. 초기적재는 Spark Batch와 결합한 하이브리드 전략으로 보완 가능.
목차
- 개요
- 결과 요약
- 시스템 아키텍처
- 경로A: OLake
- 경로B: Kafka CDC (Debezium)
- 경로C: Flink CDC Pipeline
- 초기적재 종합 비교
- 실시간 CDC 종합 비교
- 경로별 제약사항 및 특성
- 실제 운영환경에서의 권고사항
1. 개요
1.1 목적
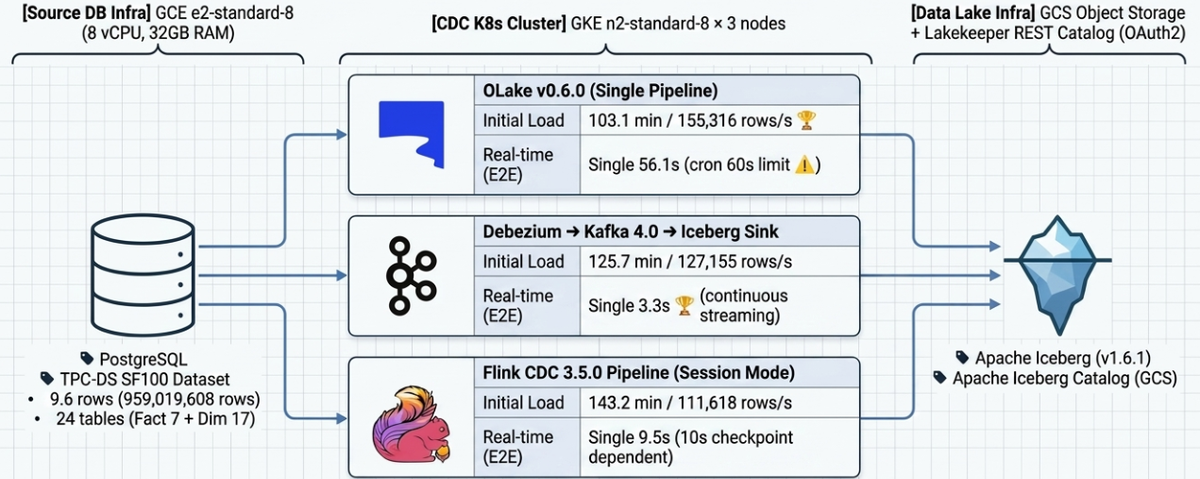
지난번 블로그(Part1.Batch ELT & Query 성능)에서 PostgreSQL에 적재된 TPC-DS SF-100 데이터셋(약 9.6억건)을 세 가지 CDC 경로를 통해 Iceberg 테이블로 초기적재(Initial Load)하는 성능을 비교·분석한다. 또한 초기적재 완료 후 실시간 변경 반영(E2E Latency, Throughput)을 측정하여 각 경로의 운영 적합성을 평가한다.
| 경로 | 기술 스택 |
|---|---|
| 경로A | PostgreSQL → OLake v0.6.0 → Iceberg |
| 경로B | PostgreSQL → Debezium Source → Kafka → Iceberg Sink → Iceberg |
| 경로C | PostgreSQL → Flink 3.5.0 CDC Pipeline → Iceberg |
1.2 대상 데이터
| 항목 | 값 |
|---|---|
| 데이터셋 | TPC-DS Scale Factor 100 |
| PostgreSQL 스키마 | tpcds_sf100 |
| 총 테이블 수 | 24개 (Fact 7개 + Dimension 17개) |
| 총 레코드 수 | 959,019,608건 (~9.6억) |
테이블별 건수:
| 테이블 | 건수 | Job 분류 |
|---|---|---|
| inventory | 399,330,000 | fact2 |
| store_sales | 287,997,024 | fact1 |
| catalog_sales | 143,997,065 | fact3 |
| web_sales | 72,001,237 | fact3 |
| store_returns | 28,795,080 | fact3 |
| catalog_returns | 14,404,374 | fact3 |
| web_returns | 7,197,670 | fact3 |
| customer | 1,981,703 | dim |
| customer_demographics | 1,920,800 | dim |
| customer_address | 1,000,000 | dim |
| 그 외 Dimension 14개 | ~390,000 | dim |
1.3 Job 분할 기준
세 경로 모두 동일 조건으로 비교하기 위해 4개 Job으로 분할:
| Job | 대상 | 건수 |
|---|---|---|
| dim | Dimension 17개 | ~5.3M |
| fact1 | store_sales | 287,997,024 |
| fact2 | inventory | 399,330,000 |
| fact3 | catalog_sales, web_sales, store_returns, catalog_returns, web_returns | 266,395,426 |
단, 경로C(Flink CDC)의 경우는 데이터셋의 size를 감안하여 fact2의 대상은 catalog_sales이고 fact3에 inventory를 포함시킴
2. 결과 요약
초기적재 (9.6억 건, TPC-DS SF-100)
| 경로 | 기술 스택 | Wall-clock | Throughput | 비고 |
|---|---|---|---|---|
| 경로A (OLake) | OLake v0.6.0 → Iceberg | 103.1분 | 155,316 rows/s | 🥇 가장 빠름 |
| 경로B (Kafka CDC) | Debezium → Kafka → Iceberg | 125.7분 | 127,155 rows/s | |
| 경로C (Flink CDC) | Flink CDC Pipeline → Iceberg | 143.2분 | 111,618 rows/s | PK 필수, Equality Delete 발생 |
실시간 CDC (E2E Latency)
| 테스트 | 경로A | 경로B | 경로C | 비고 |
|---|---|---|---|---|
| Single Row (10건) | 56.1s | 3.3s | 9.5s | 경로A: cron 60s 한계 |
| Burst 1M | 64.4s | 34.8s | 45.3s | |
| Sustained 100rps × 10분 | 19.6s | 40.2s | 13.8s | |
| Mixed DML (I/U/D) | 36.6s | 3.5s | 4.8s | |
| Peak Load | 47.8s | 17.7s | 10.6s | |
| Schema Evolution | 14.9s | TIMEOUT ❌ | TIMEOUT ❌ | 경로B/C 모두 실패 |
| Recovery | 51.2s | 5.6s | 157.2s | 경로C: job restart 포함 |
한줄 요약
- 초기적재 속도: 경로A > 경로B > 경로C
- 실시간 CDC latency: 경로B(스트리밍, ~3s) > 경로C(checkpoint, ~10s) > 경로A(cron, ~60s)
- 운영 단순성: 경로C(session-cluster방식의 job운영, Dashboard UI 지원) > 경로B(운영관리가 복잡) > 경로C(리소스 관리 어려움)
- 실제 운영 권장: 초기적재는 Spark Batch, 변경적재는 경로B 또는 경로C 조합의 하이브리드 전략 (→ 10장 참조)
3. 시스템 아키텍처
3.1 인프라
| 구성 요소 | 스펙 |
|---|---|
| PostgreSQL | GCE e2-standard-8 (8 vCPU, 32GB RAM) |
| Kubernetes | GKE n2-standard-8 * 3 (8 vCPU, 32GB RAM) |
| Iceberg Catalog | Lakekeeper REST Catalog (OAuth2 via Keycloak) |
| Object Storage | GCS (S3-compatible endpoint) |
| 벤치마크 클라이언트 | JupyterLab (PySpark + psycopg2) |
3.2 소프트웨어 버전
| 소프트웨어 | 버전 |
|---|---|
| Apache Iceberg | 1.6.1 |
| Apache Spark (검증용) | 3.5.2 |
| Kafka | 4.0.0 (KRaft) |
| Debezium PostgreSQL Connector | 2.x |
| Iceberg Sink Connector | 1.6.1 |
| OLake | v0.6.0 |
| Flink CDC | 3.5.0 (Pipeline 모드) |
| Flink | 1.20.1 |
3.3 초기적재 데이터 흐름
경로A (OLake):
PostgreSQL ──(CTID 분할 parallel export)──▶ OLake Worker ──▶ Iceberg (GCS)
경로B (Kafka CDC):
PostgreSQL ──(Full table sequential export)──▶ Kafka 24 Topics ──(Iceberg Sink, 8 tasks)──▶ Iceberg (GCS)
경로C (Flink CDC):
PostgreSQL ──(PK chunk 분할 parallel export)──▶ Flink CDC Pipeline ──▶ Iceberg (GCS)
경로C의 경우에는 PostgreSQL 소스테이블에 PK가 필요함
4. 경로A: OLake
4.1 환경 구성
| 항목 | 설정 |
|---|---|
| OLake 버전 | v0.6.0 |
| 배포 방식 | K8s Pod (4 Job, 4 Replication Slot) |
| 리소스/Pod | 4 core / 10G memory |
| Max Threads | 3 (OOM 방지) |
| Snapshot 방식 | CTID 범위 기반 chunk 자동 분할 (262,144 단위) |
| Iceberg Catalog | Lakekeeper REST (OAuth2) |
4.2 초기적재 결과
| Job | 테이블 | 건수 | 소요 시간 | Throughput |
|---|---|---|---|---|
| olake-dim | Dimension 17개 | 7,065,369 | 3.4분 | 34,465 rows/s |
| olake-fact1 | store_sales | 287,997,024 | 86.2분 | 55,662 rows/s |
| olake-fact2 | inventory | 399,330,000 | 39.4분 | 169,136 rows/s |
| olake-fact3 | Fact 5개 | 266,395,426 | 103.1분 | 43,071 rows/s |
fact3 테이블별 상세:
| 테이블 | 건수 | rows/s |
|---|---|---|
| catalog_sales | 143,997,065 | 35,669 |
| web_sales | 72,001,237 | 31,089 |
| store_returns | 28,795,080 | 51,146 |
| catalog_returns | 14,404,374 | 21,183 |
| web_returns | 7,197,670 | 15,579 |
Wall-clock 기준 (dim+fact2 순차, fact1/fact3 동시):
Timeline:
dim [=] 3.4분
fact2 [===========] 39.4분
fact1 [==========================] 86.2분
fact3 [===============================] 103.1분 (병목)
0 20 40 60 80 100 분
| 항목 | 값 |
|---|---|
| Wall-clock | 103.1분 |
| 총 건수 | 959,019,608건 |
| Throughput | 155,316 rows/s |
4.3 튜닝 히스토리
| 차수 | 구성 | 결과 | 비고 |
|---|---|---|---|
| 1차 | 단일 Job (24테이블, max_threads=8) | 153.4분, 104,185 rows/s | store_sales 병목 (64분 단독 점유) |
| 2차 | 4 Job 분할 (동일 노드) | 실패 | 노드 과부하 → 노드 Stop |
| 3차 | 4 Job 분할 + 노드 분산 (cordon) + max_threads=3 | 103.1분, 155,316 rows/s | ✅ 최종 결과 |
OOM 근본 원인: 메모리 ≈ chunk_size × 컬럼수 × row_size × max_threads + Iceberg Writer 버퍼. chunk size 고정(262,144), Pod resource 설정 불가(UI/API 미지원)로 인해 max_threads를 낮춰 OOM 회피.
4.4 실시간 CDC 결과
OLake는 micro-batch(crontab 스케줄) 방식으로 동작 (frequency: * * * * * = 매분). E2E latency에 최대 60초의 cron 대기시간 포함.
| ID | 테스트 | 건수 | E2E Latency | 평가 |
|---|---|---|---|---|
| R-04 | Single Row | 10 | avg 56.1s (min 24.5s) | PASS |
| R-05 | Burst 1M | 1,000,000 | 64.4s | PASS |
| R-06 | Sustained 10분 | 60,001 | 19.6s | PASS |
| R-07 | Mixed DML | 10,000 | 36.6s | PASS |
| R-08 | Peak Load | 600,000 | 47.8s | PASS |
| R-09 | Schema Evolution | 200 | 14.9s | PASS |
| R-10 | Recovery | 2,000 | 51.2s | PASS |
E2E latency 지배 요인은 cron 대기시간(최대 60초)이며, 실제 CDC 처리는 수초 이내로 추정.
5. 경로B: Kafka CDC (Debezium)
5.1 환경 구성
| 구성 요소 | 스펙 |
|---|---|
| Kafka Broker | 3대 (Strimzi on K8s, Kafka 4.0 KRaft) |
| Kafka Connect | 3 replicas, 4 vCPU / 6GB Memory (JVM -Xmx 4g) |
| Source Connector | 4개 (Debezium PostgreSQL), tasksMax=1 |
| Sink Connector | 1개 (Iceberg), tasksMax=8 |
| Snapshot 방식 | Full table sequential scan (1회) |
Transform 파이프라인 (Source):
Debezium Raw Message
→ [1] unwrap (ExtractNewRecordState) # envelope 제거, 메시지 크기 50~70% 감소
→ [2] addTable (InsertField) # _table 필드 추가 (동적 라우팅)
→ [3] route1, route2 (RegexRouter) # underscore → hyphen
5.2 초기적재 튜닝 히스토리
| 차수 | 문제 | 조치 | 결과 |
|---|---|---|---|
| 1차 | Connect OOM | 리소스 증설 (4Gi→6Gi, JVM 4g) | FAIL → 해소 |
| 2차 | Iceberg에 Debezium envelope 그대로 적재 | unwrap SMT 추가, schemas.enable=true | FAIL → 해소 |
| 3차 | Produce 병목 | Connect 1→3노드 스케일아웃, commit 60초, batch 증가 | PARTIAL |
| 4차 | Producer 기본 설정 한계 | lz4 압축, batch.size 256KB, buffer 64MB | SUCCESS |
최종 주요 설정 변경:
| 항목 | 변경 전 | 변경 후 |
|---|---|---|
| Producer compression | 없음 | lz4 |
| Producer batch.size | 16KB | 256KB |
| Producer buffer.memory | 기본 | 64MB |
| Sink commit.interval-ms | 300,000ms (5분) | 60,000ms (1분) |
| 메시지 형식 | Debezium envelope (full) | flat record (unwrap) |
| 메시지 크기 | ~1-2 KB/row | ~300-500 bytes/row |
5.3 초기적재 결과
| Job | 테이블 | 건수 | 소요 시간 | Throughput |
|---|---|---|---|---|
| source-dim | Dimension 17개 | ~6M | ~1.0분 | — |
| source-fact1 | store_sales | 287,997,024 | 102.6분 | 46,767 rows/s |
| source-fact2 | inventory | 399,330,000 | 62.3분 | 106,789 rows/s |
| source-fact3 | Fact 5개 | 266,395,426 | 125.7분 | 35,300 rows/s |
Wall-clock 기준:
Timeline:
dim [=] 1.0분
fact2 [==================] 62.3분
fact1 [================================] 102.6분
fact3 [========================================] 125.7분 (병목)
0 20 40 60 80 100 120 분
| 항목 | 값 |
|---|---|
| Wall-clock | 125.7분 |
| 총 건수 | 959,019,608건 |
| Throughput | 127,155 rows/s |
5.4 실시간 CDC 결과
commit.interval-ms: 1000 (1초), offset.flush.interval.ms: 1000 (클러스터 레벨) 설정.
| ID | 테스트 | 건수 | E2E Latency | 평가 |
|---|---|---|---|---|
| R-04 | Single Row | 10 | avg 3.3s | PASS |
| R-05 | Burst 1M | 1,000,000 | 34.8s (~38,500 rows/s) | PASS |
| R-06 | Sustained 10분 | 60,001 | 40.2s | PASS |
| R-07 | Mixed DML | 10,000 | 3.5s | PASS |
| R-08 | Peak Load | 600,000 | 17.7s | PASS |
| R-09 | Schema Evolution | 200 | - | FAIL |
| R-10 | Recovery | 2,000 | 5.6s | PASS |
수행 중 이슈:
offset.flush.interval.ms기본값(60초)이 commit interval보다 우선 적용 → 1초로 변경 후 E2E 60초→3초 개선- Upsert 모드에서 auto-create 테이블에 identifier 미설정으로 commit 실패 → Append 모드로 전환
- Sink tasksMax=3 시 commit coordination 불안정 → tasksMax=1로 변경
6. 경로C: Flink CDC Pipeline
6.0 Flink CDC + Iceberg 아키텍처 특성
파이프라인 단순화
기존 CDC 파이프라인(DB → Debezium → Kafka → Flink/Spark → Data Lake)을 DB → Flink CDC → Iceberg 단일 파이프라인으로 단순화한다. 중간 메시지 큐(Kafka) 없이도 실시간 동기화가 가능하나, Kafka의 버퍼링·재처리 이점은 포기한다.
Checkpoint 기반 Iceberg 커밋
Flink 처리 (메모리 상태)
→ Checkpoint 완료
→ Iceberg 새 Snapshot 생성 (메타데이터 커밋)
→ 외부 엔진(Spark, Trino 등) 조회 가능
Checkpoint가 완료되기 전까지 Iceberg에 데이터가 전혀 커밋되지 않는다.
- Checkpoint 주기 = 데이터 가시성 지연 (초기적재: 60s, 실시간 CDC: 10s)
- Checkpoint 실패 시 해당 구간 데이터 미반영 → job 재시작 필요
Upsert / Delete 처리 — Merge-On-Read (MOR)
기존 레코드 → Equality Delete 파일 (논리적 삭제 마킹)
새 값 → 신규 Data 파일 (INSERT)
format-version: 2+write.upsert.enabled: true필수- 초기적재 완료 후 CTAS compaction으로 Delete 파일 제거 필요 (→ 6.5 참조)
6.1 환경 구성 (Session Mode)
| 항목 | 설정 |
|---|---|
| 버전 | Flink CDC 3.5.0, Flink 1.20.1 |
| 배포 방식 | Flink Kubernetes Operator (Session Mode, 분산 배포) |
| Snapshot 방식 | PK 기반 incremental snapshot (chunk.size=100,000) |
| Job 제출 | JM pod shell (./bin/flink-cdc.sh) |
| Checkpoint | 자동 (GCS 저장, state.checkpoints.dir) |
리소스:
| 구성요소 | CPU | Memory | 수량 |
|---|---|---|---|
| JobManager | 1 core | 4 GB | 1 |
| TaskManager | 2 core | 8 GB | 4 |
| 총 슬롯 | — | — | 16 |
슬롯 배분:
| Job | 테이블 | Parallelism | 슬롯 |
|---|---|---|---|
| flink-cdc-dim | Dimension 17개 | 2 | 2 |
| flink-cdc-fact1 | store_sales | 4 | 4 |
| flink-cdc-fact2 | catalog_sales | 4 | 4 |
| flink-cdc-fact3 | web_sales, inventory, store_returns, catalog_returns, web_returns | 6 | 6 |
| 합계 | 16 |
6.2 주요 이슈 및 해결
| 이슈 | 원인 | 해결 |
|---|---|---|
| TPC-DS 테이블 PK 없음 | TPC-DS 원본 스키마 | 전체 24개 테이블 PK 추가 |
| GCS SSL 인증서 오류 | flink-gs-fs-hadoop SDK 자체 HTTP 클라이언트 — JVM truststore 미적용 |
신규 이미지(flink-cdc-pipeline)로 교체 (GCS 의존성 내장) |
| Checkpoint 자동 미동작 | Flink CDC 3.5.0 잠재적 이슈 — enableCheckpointing() 미호출 |
신규 이미지에서 정상 동작 확인 |
| OOM (초기) | checkpoint 미동작으로 메모리 누적 | Checkpoint 정상 동작으로 해소 |
6.3 PostgreSQL PK 순서 변경
Flink CDC의 PK range query 특성상, PK 첫 번째 컬럼이 물리적 저장 순서와 불일치하면 random I/O 극대화.
| 테이블 | 변경 전 | 변경 후 | 효과 |
|---|---|---|---|
| store_sales | (ss_item_sk, ss_ticket_number) | (ss_ticket_number, ss_item_sk) | chunk당 54초→2초 (27배) |
| catalog_sales | (cs_item_sk, cs_order_number) | (cs_order_number, cs_item_sk) | |
| web_sales | (ws_item_sk, ws_order_number) | (ws_order_number, ws_item_sk) | 1.6배 개선 |
6.4 초기적재 결과
| Job | 테이블 | 건수 | 소요 시간(추정) | Throughput(추정) |
|---|---|---|---|---|
| dim | Dimension 17개 | 5,297,158 | 3.4분 | 25,966 rows/s |
| fact1 | store_sales | 287,997,024 | 142.6분 | 33,660 rows/s |
| fact2 | catalog_sales | 143,997,065 | 140.6분 | 17,075 rows/s |
| fact3 | web_sales, inventory, store_returns, catalog_returns, web_returns | 521,728,361 | 113.6분 | 76,533 rows/s |
fact3 테이블별 처리 순서 (추정):
| 테이블 | 소요 | Throughput |
|---|---|---|
| inventory (399M, 4컬럼) | 39.9분 | ~166,672 rows/s |
| web_sales (72M, 34컬럼) | 46.0분 | 26,111 rows/s |
| store_returns (29M, 20컬럼) | 13.9분 | 34,532 rows/s |
| catalog_returns (14M, 27컬럼) | 9.5분 | 25,312 rows/s |
| web_returns (7M, 24컬럼) | 4.4분 | 27,519 rows/s |
Wall-clock:
Timeline:
fact3 [=================================] 113.6분
fact2 [=========================================] 140.6분
fact1 [==========================================] 142.6분 (병목)
0 30 60 90 120 143 분
| 항목 | 값 |
|---|---|
| Wall-clock | 143.2분 |
| 총 건수 | 959,019,608건 |
| Throughput | 111,618 rows/s |
6.5 후처리 및 유지보수
Equality Delete 제거 (초기적재 완료 후 1회)
rewrite_data_files로는 equality delete가 완전히 제거되지 않음 (Iceberg #12838). CTAS 방식으로 재생성 필요.
⚠️ CTAS 주의사항: CTAS는 원본 테이블의 파티션 스펙, 정렬 순서, 테이블 프로퍼티(
write.format.default,write.upsert.enabled등)를 보존하지 않는다. 파티션이 정의된 테이블의 경우 CTAS 전 반드시SHOW CREATE TABLE로 스펙을 확인하고, CTAS 후 동일한 속성을 재적용해야 한다.
spark.conf.set("spark.sql.adaptive.enabled", "true")
spark.conf.set("spark.sql.files.maxRecordsPerFile", "1000000") # 파일당 레코드 제한 (OOM 방지)
# CTAS → 건수 검증 → RENAME → DROP
spark.sql("CREATE TABLE ns.store_sales_clean AS SELECT * FROM ns.store_sales")
# 건수 검증
orig = spark.table("ns.store_sales").count()
clean = spark.table("ns.store_sales_clean").count()
assert orig == clean, f"Count mismatch: {orig} vs {clean}"
spark.sql("ALTER TABLE ns.store_sales RENAME TO ns.store_sales_old")
spark.sql("ALTER TABLE ns.store_sales_clean RENAME TO ns.store_sales")
spark.sql("DROP TABLE ns.store_sales_old")
소형 파일(Small Files) 문제 및 정기 Compaction
CDC 환경에서는 잦은 checkpoint마다 소형 데이터 파일과 Delete 파일이 누적된다.
- 영향: 파일 수 증가 → Iceberg metadata 비대 → 조회 성능 저하
- 대응: Spark
RewriteDataFiles로 주기적 병합
# Iceberg 주기적 compaction (Spark)
spark.sql("""
CALL catalog.system.rewrite_data_files(
table => 'namespace.table_name',
options => map('target-file-size-bytes', '536870912') -- 512MB
)
""")
Snapshot 만료 및 고아 파일 정리 (정기 유지보수)
Checkpoint마다 Iceberg 스냅샷이 누적되어 스토리지를 소비한다.
from datetime import datetime, timedelta
# 오래된 스냅샷 만료 (7일 이전 기준, 동적 산출)
cutoff = (datetime.utcnow() - timedelta(days=7)).strftime('%Y-%m-%d %H:%M:%S')
spark.sql(f"""
CALL catalog.system.expire_snapshots(
table => 'namespace.table_name',
older_than => TIMESTAMP '{cutoff}'
)
""")
# 참조되지 않는 고아 파일 정리
spark.sql("""
CALL catalog.system.remove_orphan_files(
table => 'namespace.table_name'
)
""")
| 유지보수 작업 | 주기 권장 | 설명 |
|---|---|---|
rewrite_data_files |
일 1회 | 소형 파일 병합, Delete 파일 통합 |
expire_snapshots |
주 1회 | 오래된 스냅샷 메타데이터 삭제 |
remove_orphan_files |
월 1회 | 참조 끊긴 데이터 파일 제거 |
6.6 실시간 CDC 결과
테스트 환경:
- Job:
flink-cdc-benchmark(cdc_benchmark, cdc_schema_evolution 테이블) - Checkpoint interval: 10s / Mode: EXACTLY_ONCE
schema.change.behavior: LENIENT (EVOLVE 동작 이상으로 전환, 정상 동작)- 측정 도구:
cdc/cdc_benchmark.ipynb
테스트 결과
| ID | 테스트 | 건수 | E2E Latency | 결과 | 비고 |
|---|---|---|---|---|---|
| R-04 | Single Row Latency | 10 | avg 9.5s (min 6.0 / max 10.8) | ⚠️ | checkpoint 10s 한계 |
| R-05 | Burst Insert (1M) | 1,000,000 | 45.3s | ✅ | PG: 101,630 rows/s |
| R-06 | Sustained Load (100rps×10분) | 60,001 | 13.8s | ✅ | 정확히 100 rps 유지 |
| R-07 | Mixed DML (I70/U20/D10%) | 10,000 | 4.8s | ✅ | DELETE 반영 확인 |
| R-08 | Peak Load | 600,000 | 10.6s | ✅ | peak 3,000 rps (plateau) |
| R-09 | Schema Evolution | 200 | TIMEOUT (120s) | ❌ | EVOLVE 동작 이상, LENIENT로 우회 |
| R-10 | Recovery Test | 2,000 | 157.2s | ✅ | job restart 포함, 정합성 OK |
R-09 Schema Evolution 실패 원인:
ALTER TABLE ADD COLUMN 실행 시
SchemaCoordinator: CreateTableEvent(6컬럼) → "redundant" 오판 → schema change events []
IcebergWriter: 4컬럼으로 6컬럼 데이터 쓰기 → IndexOutOfBoundsException
EVOLVE 모드에서 동작 이상 확인 필요. LENIENT 모드로 전환 시 정상 동작하나 신규 컬럼 미반영. 올바른 절차: flink stop (savepoint) → DDL → savepoint 재시작.
7. 초기적재 종합 비교
7.1 Wall-clock 및 Throughput
| 경로 | 방식 | Wall-clock | Throughput | 병목 |
|---|---|---|---|---|
| A (OLake) | OLake Worker → Iceberg | 103.1분 | 155,316 rows/s | fact3 |
| B (Kafka CDC) | Debezium → Kafka → Iceberg | 125.7분 | 127,155 rows/s | fact3 |
| C (Flink CDC) | Flink CDC Pipeline (Session Mode) | 143.2분 | 111,618 rows/s | fact1 |
7.2 Job별 Throughput 비교
경로C는 Job 구성이 경로A/B와 다름: fact2=catalog_sales, fact3=web_sales+inventory+store_returns+catalog_returns+web_returns
| 테이블 | 경로A | 경로B | 경로C |
|---|---|---|---|
| dim (17개, 5.3M) | 34,465 rows/s | — | 25,966 rows/s |
| store_sales (288M) | 55,662 rows/s | 46,767 rows/s | 33,660 rows/s |
| catalog_sales (144M) | 35,669 rows/s | 35,300 rows/s* | 17,075 rows/s |
| inventory (399M) | 169,136 rows/s | 106,789 rows/s | ~166,672 rows/s (추정) |
*경로B fact3에 catalog_sales 포함. 경로C fact3 throughput(76,533 rows/s)은 5개 테이블 합산.
7.3 스냅샷 전략 비교 — 초기적재 방식의 차이
세 경로는 초기적재 시 PostgreSQL 데이터를 읽는 방식이 근본적으로 다르며, 이것이 성능 차이의 주요 원인이다.
| 경로A (OLake) | 경로B (Debezium) | 경로C (Flink CDC) | |
|---|---|---|---|
| 스냅샷 방식 | CTID 기반 청킹 | Full table scan (1회) | PK range query (N회) |
| PK 필요 | 불필요 | 불필요 | 필수 |
| I/O 패턴 | Sequential (물리 블록 순서) | Sequential | Random (PK 순서 의존) |
| PG 쿼리 수 | 수십~수백 | 1 | 수십~수백 |
| 병렬화 | 가능 (청크별 워커) | 불가 (단일 쿼리) | 가능 (PK 범위별) |
| 트랜잭션 | 청크별 짧은 트랜잭션 | 하나의 긴 트랜잭션 | 청크별 짧은 트랜잭션 |
경로C (Flink CDC) — PK Range Query (DBlog 알고리즘)
SELECT * FROM table WHERE pk >= chunk_start AND pk < chunk_end
- PK 필수: 스냅샷과 WAL change log를 PK로 매칭·병합
- PK 인덱스 → 데이터 페이지 접근 → random I/O 유발 가능성
- PK 첫 번째 컬럼의 물리적 저장 순서 일치 시 성능 대폭 향상 (→ 6.3 참조)
경로C 초기적재 성능 열위 분석
| 요인 | 영향 |
|---|---|
| PK range query vs sequential scan | random I/O 오버헤드 |
| 동기 파이프라인 (Source→Schema→Sink 순차) | 비동기 Kafka 버퍼 대비 불리 |
| Equality delete 이중 쓰기 | 20~40% 쓰기 오버헤드 |
8. 실시간 CDC 종합 비교
| ID | 테스트 | 경로A E2E | 경로B E2E | 경로C E2E | 비고 |
|---|---|---|---|---|---|
| R-04 | Single Row (10건) | 56.1s | 3.3s | 9.5s ⚠️ | 경로C: checkpoint 10s 한계 |
| R-05 | Burst 1M | 64.4s | 34.8s | 45.3s | |
| R-06 | Sustained 100rps × 10분 | 19.6s | 40.2s | 13.8s | 경로C: 고처리량 checkpoint에 유리 |
| R-07 | Mixed DML (I/U/D) | 36.6s | 3.5s | 4.8s | 경로C: DELETE 정상 반영 |
| R-08 | Peak Load | 47.8s | 17.7s | 10.6s | 경로C: peak 3,000 rps |
| R-09 | Schema Evolution | 14.9s | TIMEOUT ❌ | TIMEOUT ❌ | 경로B/C 모두 실패 (→ 5, 6장 참조) |
| R-10 | Recovery | 51.2s | 5.6s | 157.2s* | *job restart 포함, 정합성 OK |
경로별 특성:
- 경로A: micro-batch(cron) 구조 → E2E 최소 latency 60s. near-realtime 불가.
- 경로B: 연속 스트리밍 → 단건 E2E ~3초, 대량 변경도 수십 초 내 반영. 가장 안정적.
- 경로C: checkpoint 주기 = E2E latency 하한. 10s 설정 시 R-04 ~9.5s. checkpoint 단축 시 개선 가능. R-08/R-06은 경로B 대비 우수.
9. 경로별 제약사항 및 특성
| 항목 | 경로A (OLake) | 경로B (Kafka CDC) | 경로C (Flink CDC) |
|---|---|---|---|
| 초기적재 속도 | ★★★★★ | ★★★★ | ★★★★ |
| 실시간 CDC latency | ★★ (cron 종속) | ★★★★★ | ★★★ (checkpoint 종속) |
| PK 필요 여부 | 불필요 | 불필요 | 필수 |
| Parallelism 조절 | max_threads 정의 | source tasks=1 | Pipeline에 정의 |
| 초기적재 write 모드 | Append 선택 가능 | Append 선택 가능 | Upsert 강제 (하드코딩) |
| Equality delete | 없음 | 없음 | 항상 발생 → CTAS 필요 |
| 중간 계층 | 없음 | Kafka (버퍼, 재처리 가능) | 없음 |
| 장애 복구 | Job 재시작 | Kafka offset 기반 | Checkpoint + Replication Slot |
| 스키마 진화 | ✅ 자동 | ❌ TIMEOUT (→ 5장 참조) | ❌ TIMEOUT → LENIENT로 우회 |
| Pod resource 제어 | ❌ UI/API 미지원 | ✅ K8s 직접 설정 | ✅ FlinkDeployment CR |
10. 실제 운영환경에서의 권고사항
초기적재에서 변경적재로 데이터 누락 없이 전환하는 것은 CDC 구축에서 가장 까다로운 구간이다. 이 섹션에서는 두 가지 전략을 비교하고, 실제 운영환경에서 권장하는 접근법을 제시한다.
10.1 전략 비교 — 하이브리드 vs CDC Only
CDC Only 전략
초기적재와 변경적재를 모두 동일한 CDC 도구(OLake / Debezium / Flink CDC)로 처리하는 방식이다.
[초기적재] PostgreSQL ──(CDC Snapshot)──▶ Iceberg
[변경적재] PostgreSQL ──(CDC WAL)──────▶ Iceberg
장점:
- 단일 도구로 파이프라인 단순화
- Snapshot → WAL 전환이 도구 내부에서 자동 처리
한계 및 리스크:
| 항목 | 문제 |
|---|---|
| 초기적재 속도 | 경로A 103분, 경로B 126분, 경로C 143분 — 모두 단일 스레드 또는 제한된 병렬성 |
| Replication Slot 점유 | 초기적재 중 WAL이 계속 누적 → 디스크 사용량 급증 위험 |
| Equality Delete 누적 | 경로C(Flink CDC)는 초기적재 전체가 Upsert 강제 → 대규모 Delete 파일 발생 |
| 초기적재 → 변경적재 전환 시 Job 재배포 필요 | 초기적재(Snapshot)와 변경적재(WAL)는 요구되는 리소스와 설정이 달라 동일 Job으로 연속 운영이 어렵다. 초기적재 완료 후 Job을 중단하고, 리소스·설정을 변경적재 최적 값으로 수정한 뒤 재배포해야 한다. 예를 들어 경로A는 max_threads, 경로C는 parallelism과 chunk.size를 각각 조정해야 하며, 이 과정에서 운영 중단 구간이 발생하고 설정 오류 시 데이터 누락 위험이 있다. |
하이브리드 전략 (Spark Batch + CDC 변경적재)
초기적재는 Spark Batch로 고속 처리하고, 변경적재만 CDC로 담당하는 역할 분리 전략이다.
[초기적재] PostgreSQL ──(Spark JDBC Bulk Read)──▶ Iceberg (Append Only)
[변경적재] PostgreSQL ──(CDC WAL)──────────────▶ Iceberg (Upsert/Delete)
↑
Replication Slot은 초기적재 시작 전부터 생성
핵심 원칙: Replication Slot을 초기적재 시작 전에 생성하여, Spark Batch가 진행되는 동안 발생한 WAL 변경분을 CDC가 이어받아 처리함으로써 데이터 누락을 원천 차단한다.
전략별 종합 비교
| 항목 | CDC Only | 하이브리드 (권장) |
|---|---|---|
| 초기적재 속도 | ★★★ (CDC 병렬성 제한) | ★★★★★ (Spark 병렬 JDBC) |
| Iceberg 파일 품질 | ⚠️ Equality Delete 다량 발생 (경로C) | ✅ Append Only → 파일 품질 우수 |
| 대규모 데이터 적합성 | ★★★ | ★★★★★ |
본 벤치마크 기준(9.6억건), Spark JDBC Bulk Read는 CDC Snapshot 대비 2~3배 이상 빠른 초기적재 속도를 기대할 수 있다.