
Milvus 3.0: ETL 없이 Iceberg 데이터를 그대로 검색하다 (2.x ETL vs. 3.0 Zero-Copy)
3줄 요약
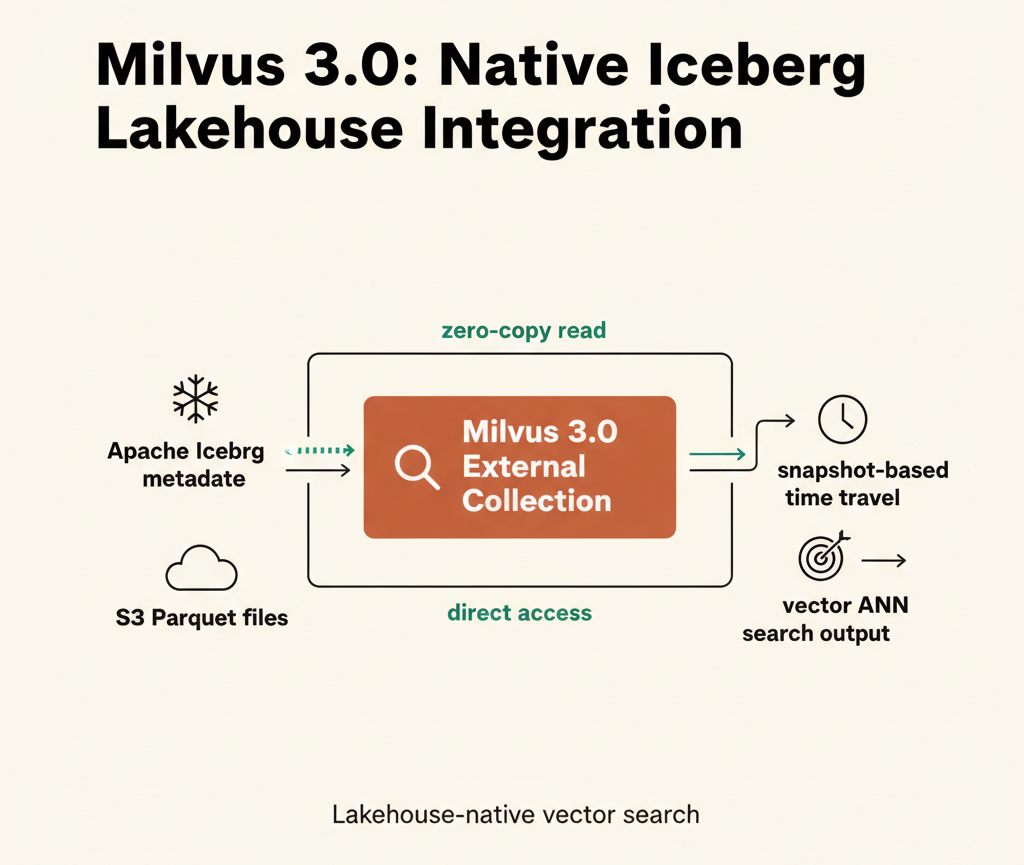
Milvus 2.x까지는 Iceberg에 있는 벡터 데이터를 검색하려면 별도 파이프라인으로 복사(ETL)하는 과정이 필수였다. 3.0부터는 S3의 Iceberg 메타데이터만 참조해 데이터를 복사하지 않고 벡터 검색이 가능하다(External Collection). 아직 정식 릴리즈 전이고 쓰기·CDC 지원은 없지만, 데이터 레이크와 벡터 검색의 통합 방식이 근본적으로 바뀌었다.
S3에 쌓인 Iceberg 테이블을 그대로 벡터 검색하는 것 — Milvus 3.0이 가능하게 한 것이 바로 이것이다.
1. Milvus 3.0이란?
"벡터 데이터베이스와 데이터 레이크의 경계를 없앤다"
Milvus 3.0은 기존 벡터 DB 역할에서 한 발 더 나아가 Vector Lake 개념을 도입한다. 핵심은 두 가지다.
Loon 엔진: External Collection을 처리하는 실행 엔진. S3에 있는 Iceberg Parquet 파일을 직접 읽어 벡터 인덱스를 구성한다. Milvus 내부로 데이터를 복사하지 않는다.
Woodpecker: 2.6부터 도입된 내장 WAL(Write-Ahead Log). Pulsar/Kafka 없이도 동작하며, S3 백엔드 기준 처리량은 Pulsar 대비 약 7배, 지연시간은 35ms → 1.8ms로 줄었다. 별도 클러스터를 운영할 필요가 없다.
2. 왜 기존 ETL 방식만으로는 부족한가?
Milvus 2.x에서 Iceberg 데이터를 검색하려면 다음 경로를 거쳐야 했다.
Iceberg (S3) → ETL 파이프라인 → Milvus insert → 벡터 검색
이 방식에는 세 가지 구조적 문제가 있다.
스토리지 이중화: Iceberg에 원본이 있고, Milvus에도 동일 데이터를 다시 저장해야 한다. 스토리지 비용이 2배가 된다.
동기화 지연: Iceberg에 데이터가 추가될 때마다 ETL을 돌려야 한다. 파이프라인 유지보수 비용이 생기고, 검색 결과와 원본 사이에 시간 차가 발생한다.
Time Travel 불가: Iceberg는 스냅샷 기반으로 특정 시점 데이터를 조회하는 기능을 제공하지만, Milvus에 복사된 데이터는 스냅샷 개념이 없다. 과거 시점 검색이 불가능하다.
3. 내부 구조: External Collection은 어떻게 동작하는가?
External Collection의 핵심은 메타데이터만 참조한다는 점이다.
PyIceberg → metadata.json (S3) ← Milvus Loon 엔진
↓ snapshot_id 기반
Parquet 파일 (S3) ← 직접 읽기 (Zero-Copy)
↓
HNSW 인덱스 빌드 → 벡터 검색
Loon 엔진은 external_source(metadata.json 경로)와 external_spec(snapshot_id + S3 자격증명)만 받아서, 해당 스냅샷에 속한 Parquet 파일을 직접 읽고 인덱스를 구성한다. Milvus 내부 스토리지로의 복사는 없다.
external_spec의 구조는 다음과 같다.
{
"format": "iceberg-table",
"snapshot_id": 1234567890,
"extfs": {
"cloud_provider": "minio",
"access_key_id": "...",
"access_key_value": "...",
"region": "us-east-1",
"use_virtual_host": "false",
"use_ssl": "false"
}
}
4. 직접 해보기
사전 준비
pip install "pymilvus>=3.0.0" "pyiceberg[s3fs]" pyarrow numpy
1) Iceberg 테이블 생성
S3에 Iceberg 테이블을 생성하고 128차원 랜덤 벡터 1,000개를 삽입한다. PyIceberg는 데이터를 Parquet 포맷으로 S3에 저장하고, 스냅샷 정보를 담은 metadata.json을 함께 기록한다. 이후 Milvus는 이 metadata.json 경로와 snapshot_id만 받아 데이터 위치를 파악한다.
from pyiceberg.catalog import load_catalog
import pyarrow as pa, numpy as np
# SQLite를 카탈로그 백엔드로 사용 (로컬 테스트용)
catalog = load_catalog("default", **{
"type": "sql",
"uri": "sqlite:////tmp/milvus-iceberg.db",
"warehouse": "s3://my-bucket/iceberg/warehouse",
"s3.endpoint": "http://localhost:9000",
"s3.access-key-id": "...",
"s3.secret-access-key": "...",
"s3.path-style-access": "true", # MinIO/RustFS path-style 필수
})
tbl = catalog.load_table("default.vectors")
# seed=42로 재현 가능한 랜덤 벡터 생성
rng = np.random.default_rng(42)
tbl.append(pa.table({
"id": pa.array(range(1000), pa.int64()),
"label": pa.array([f"item_{i}" for i in range(1000)], pa.string()),
"vector": pa.array(rng.random((1000, 128), dtype=np.float32).tolist(),
pa.list_(pa.float32(), 128)),
}))
# append 후 새 스냅샷이 자동 생성됨
snap = tbl.current_snapshot()
print(snap.snapshot_id) # 7929422292644868496
print(tbl.metadata_location) # s3://my-bucket/.../metadata/00001-dd47088e-...metadata.json
tbl.append()가 완료되면 S3에 두 가지 파일이 생성된다. data/ 아래에는 실제 벡터가 담긴 Parquet 파일이, metadata/ 아래에는 스냅샷 정보를 담은 metadata.json이 기록된다. Milvus가 참조하는 것은 이 metadata.json이다.
생성된 데이터 샘플 (seed=42, [0.0, 1.0) 균등 분포):
| id | label | vector (첫 4개 / 128차원) |
|---|---|---|
| 0 | item_0 | [0.0893, 0.7740, 0.6546, 0.4389, ...] |
| 1 | item_1 | [0.5746, 0.6347, 0.5654, 0.5536, ...] |
| 999 | item_999 | [0.6099, 0.8540, 0.3381, 0.2058, ...] |
2) External Collection 생성
Milvus에 External Collection을 등록한다. 이 단계에서는 데이터를 복사하지 않는다. Iceberg 테이블의 metadata.json 경로(external_source)와 스냅샷 정보(external_spec)를 스키마에 연결하는 것이 전부다. Milvus는 이 정보를 바탕으로 나중에 Parquet 파일을 직접 읽는다.
from pymilvus import MilvusClient, DataType
client = MilvusClient(uri="http://localhost:19530")
# Milvus Pod가 접근 가능한 S3 엔드포인트로 호스트명 교체
# "s3://my-bucket/" → "s3://s3-endpoint:9000/my-bucket/"
# 버킷명이 아닌 실제 엔드포인트를 포함해야 Loon이 올바르게 접근함
external_source = tbl.metadata_location.replace(
"s3://my-bucket/", "s3://s3-endpoint:9000/my-bucket/"
)
# snapshot_id: 읽을 Iceberg 스냅샷 지정
# use_virtual_host, use_ssl: MinIO/RustFS 호환을 위해 false로 설정
external_spec = (
'{"format": "iceberg-table",'
f'"snapshot_id": {snap.snapshot_id},'
'"extfs": {"cloud_provider": "minio", "region": "us-east-1",'
'"access_key_id": "...", "access_key_value": "...",'
'"use_virtual_host": "false", "use_ssl": "false"}}'
)
# external_source와 external_spec을 스키마에 바인딩
schema = client.create_schema(
external_source=external_source,
external_spec=external_spec,
)
# external_field: Iceberg 컬럼명과 Milvus 필드를 매핑
schema.add_field("id", DataType.INT64, external_field="id")
schema.add_field("label", DataType.VARCHAR, max_length=64, external_field="label")
schema.add_field("vector", DataType.FLOAT_VECTOR, dim=128, external_field="vector")
client.create_collection("iceberg_vectors", schema=schema)
create_collection()이 완료된 시점에 Milvus 내부에는 컬렉션 메타데이터만 등록된 상태다. Iceberg의 Parquet 데이터는 아직 로드되지 않았다.
3) Refresh → 인덱스 → 검색
Refresh는 Milvus Loon 엔진이 external_source가 가리키는 Parquet 파일을 실제로 읽어 인덱스 구성을 준비하는 단계다. 이 작업이 끝나야 벡터 검색이 가능해진다. Refresh는 비동기 Job으로 실행되며, 완료될 때까지 상태를 폴링한다.
import time
# Refresh 시작 — Loon이 Parquet를 읽어 세그먼트 구성
job_id = client.refresh_external_collection("iceberg_vectors")
# RefreshCompleted 상태가 될 때까지 3초 간격으로 폴링
while True:
p = client.get_refresh_external_collection_progress(job_id=job_id)
if p.state == "RefreshCompleted":
break
elif p.state == "RefreshFailed":
raise RuntimeError(p.reason)
time.sleep(3)
# HNSW 인덱스 빌드 (고정밀 ANN 검색용)
index_params = client.prepare_index_params()
index_params.add_index("vector", index_type="HNSW", metric_type="L2",
params={"M": 16, "efConstruction": 200})
client.create_index("iceberg_vectors", index_params)
# 컬렉션 메모리 로드 후 검색
client.load_collection("iceberg_vectors")
results = client.search(
"iceberg_vectors",
data=np.random.default_rng(99).random((3, 128), dtype=np.float32).tolist(),
anns_field="vector",
limit=5, # top-5 반환
output_fields=["id", "label"],
search_params={"metric_type": "L2", "params": {"ef": 64}},
)
1,000개 벡터에 대해 3개 쿼리를 실행한 결과다. 반환된 id가 모두 0~999 범위 안에 있으며, Iceberg의 원본 데이터를 복사 없이 그대로 검색했음을 확인할 수 있다.
| 쿼리 | id | label | distance |
|---|---|---|---|
| 쿼리[0] | 773 | item_773 | 13.1010 |
| 쿼리[1] | 995 | item_995 | 12.6203 |
| 쿼리[2] | 64 | item_64 | 15.7635 |
4) 증분 Refresh: 올바른 방법
Iceberg에 데이터가 추가되면 새로운 스냅샷과 metadata.json이 생성된다. 기존 컬렉션에 이 변경을 반영하려면 refresh_external_collection()을 파라미터 없이 재호출하는 것만으로는 부족하다. 이 경우 Milvus는 컬렉션 생성 시점의 snapshot_id에 고정된 채 재로드한다. 새 스냅샷을 반영하려면 최신 snapshot_id와 metadata_location을 명시적으로 전달해야 한다.
# Iceberg에 100개 데이터 추가 후 새 스냅샷 조회
tbl = catalog.load_table("default.vectors")
new_snap = tbl.current_snapshot()
# ❌ 파라미터 없이 재호출 — snapshot_id가 컬렉션 생성 시점(v1)에 고정됨
client.refresh_external_collection("iceberg_vectors")
# ✅ 새 metadata_location과 snapshot_id를 함께 전달해야 v2 스냅샷 반영
client.refresh_external_collection(
collection_name="iceberg_vectors",
external_source=make_external_source(tbl.metadata_location), # 새 metadata.json 경로
external_spec=make_external_spec(new_snap.snapshot_id), # 새 snapshot_id
)
두 방법의 실제 테스트 결과다. v2에서 추가된 id=1050의 존재 여부로 스냅샷 반영 여부를 판정했다.
| 방법 | v1 snapshot_id | v2 snapshot_id | 결과 |
|---|---|---|---|
| Test A: spec 고정 re-refresh | 7929422292644868496 | — | FAIL — id=1050 미포함, v1에 고정 |
| Test B: 새 source/spec 전달 | — | 582536305514052781 | PASS — 컬렉션 재생성 없이 v2 반영 |
5) Time Travel
Iceberg는 append() 호출마다 스냅샷을 자동으로 보존한다. External Collection을 생성할 때 snapshot_id에 과거 스냅샷 ID를 지정하면, 해당 시점에 존재했던 데이터만 검색 대상이 된다. 동일 Iceberg 테이블을 서로 다른 snapshot_id로 여러 컬렉션에 동시 마운트하는 것도 가능하다.
# v1(500개), v2(1,000개), v3(1,500개) 스냅샷 ID를 각각 지정해 별도 컬렉션 생성
# snapshot_id만 다르고 나머지 생성 절차는 동일
create_and_refresh(client, snap_id=v1_snap_id, metadata_loc=v1_meta_loc) # id=0~499만 조회됨
create_and_refresh(client, snap_id=v2_snap_id, metadata_loc=v2_meta_loc) # id=0~999만 조회됨
create_and_refresh(client, snap_id=v3_snap_id, metadata_loc=v3_meta_loc) # id=0~1499 전체
각 스냅샷 ID로 생성한 컬렉션에서 id=250 / 750 / 1250의 존재 여부를 확인한 결과다. 지정한 스냅샷 이후에 추가된 데이터는 정확히 조회되지 않았다.
| 스냅샷 | snapshot_id | id=250 | id=750 | id=1250 |
|---|---|---|---|---|
| v1 (500개) | 712633362579329725 | FOUND | NOT FOUND | NOT FOUND |
| v2 (1,000개) | 4884067013805988212 | FOUND | FOUND | NOT FOUND |
| v3 (1,500개) | 4719625814627057901 | FOUND | FOUND | FOUND |
5. ETL vs. Zero-Copy: 핵심 비교
| 항목 | Milvus 2.x (ETL) | Milvus 3.0 (Zero-Copy) |
|---|---|---|
| 데이터 복사 | 필수 | 불필요 |
| 스토리지 비용 | 2배 (원본 + Milvus) | 1배 (원본만) |
| 동기화 방식 | ETL 파이프라인 | refresh API |
| Time Travel | 불가 | snapshot_id 지정으로 가능 |
| 스키마 변경 | ETL 재실행 | rewrite + 컬렉션 재생성 |
| 프로덕션 안정성 | GA | 3.0 GA 목표 2026-06-26 |
한 줄 요약: ETL 방식 = 복사 후 검색, Zero-Copy 방식 = 원본 그대로 검색
6. 한계: 현재 제약사항
3.0 미정식 릴리즈: 테스트 시점 기준 Milvus 3.0은 beta 상태다. GA 목표일은 2026-06-26이며 진행률은 83% 수준이다. 프로덕션 적용은 GA 이후 검토를 권장한다.
읽기 전용: External Collection은 읽기만 지원한다. Iceberg 테이블에 직접 쓰거나 CDC(Change Data Capture)로 자동 동기화하는 기능은 3.1 로드맵에 포함되어 있다.
스키마 변경 시 재작업 필요: Iceberg 테이블에 컬럼을 추가한 경우 새 컬럼을 Milvus에서 쓰려면 tbl.overwrite()로 Parquet 전체를 재작성한 뒤 컬렉션을 다시 생성해야 한다. Milvus Loon은 구 Parquet에 없는 컬럼을 NULL로 채우지 못한다.
경로 설정 주의사항:
external_source는 디렉토리 경로가 아닌metadata.json파일 경로로 지정해야 한다 (trailing slash 제거)- S3 URL 스킴은
minio://가 아닌s3://를 사용해야 한다 - Milvus Pod에서 접근 가능한 엔드포인트로 호스트명을 교체해야 한다
7. 마치며
Milvus 3.0의 External Collection은 "벡터 DB에 데이터를 집어넣는" 패러다임에서 "데이터 레이크를 그대로 검색하는" 패러다임으로의 전환을 의미한다. 데이터 엔지니어링 관점에서는 파이프라인 복잡도가 줄고, 스토리지 비용이 절감되며, Iceberg의 Time Travel·스냅샷 기능을 벡터 검색에도 그대로 활용할 수 있게 된다.
다만 아직 갈 길이 있다. 쓰기 지원과 인덱스 자동 갱신이 지원되는 3.1이 나온 뒤에야 데이터 레이크 기반 실시간 벡터 검색 파이프라인을 온전히 구성할 수 있다. 그 시점에 다시 검토할 예정이다.