
KFP · MLflow · KServe로 구성하는 end-to-end MLOps 파이프라인
이 글에서는 PAASUP DIP 환경을 기준으로, KFP v2 · MLflow · MinIO · KServe를 조합해 구성한 end-to-end MLOps 파이프라인을 바탕으로 데이터 수집부터 challenger·champion 승격, KServe 무중단 배포, 운영 고려사항까지 살펴봅니다.
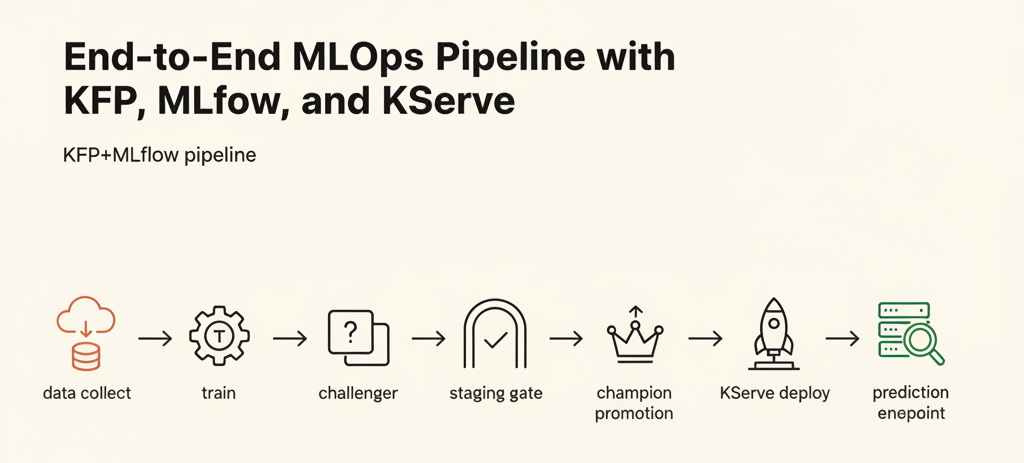
목차
- 전체 구성 개요
- Kubeflow Pipelines v2: 컴포넌트와 파이프라인 등록
- MLflow Model Registry: alias 기반 모델 생명주기
- MinIO: 자체 호스팅 S3 호환 아티팩트 스토리지
- KServe와 ServingRuntime: 모델 서빙 런타임
- 스테이징 검증과 승격: alias 전환 + InferenceService patch
- 알림과 사람 승인 게이트
- 운영 환경에서 고려할 것들
- 마치며
자체 인프라 위에서 모델 학습부터 서빙까지의 MLOps 흐름을 자동화하려면, 워크플로 오케스트레이션·실험 추적·아티팩트 스토리지·서빙 런타임을 결합해야 합니다. Kubeflow Pipelines v2(KFP)와 MLflow, MinIO, KServe는 이 흐름을 구성하는 대표적인 오픈소스 조합입니다. 이 글은 해당 스택으로 데이터 수집 → 학습 → 스테이징 검증 → 프로덕션 승격 → 서빙 배포까지 이어지는 MLOps 파이프라인을 어떻게 구성하는지, 그리고 운영 환경에서 어떤 항목을 추가로 고려해야 하는지를 정리합니다.
이 글에서 소개하는 구성은 PAASUP DIP(Data Intelligence Platform) 환경을 기준으로 합니다. PAASUP DIP는 Kubernetes 기반의 데이터·ML 통합 운영 플랫폼으로, KFP · MLflow · MinIO · KServe를 카탈로그에서 클릭 몇 번으로 배포해 이 글에서 소개하는 MLOps 파이프라인을 바로 구성할 수 있습니다. DIP를 사용하지 않는 경우에는 각 컴포넌트를 Kubernetes 클러스터에 개별 배포한 뒤 동일하게 구성할 수 있습니다.
1. 전체 구성 개요
KFP + MLflow + KServe 스택의 핵심은 역할 분리입니다. KFP는 컴포넌트 단위 워크플로를 오케스트레이션하고, MLflow는 실험·모델·아티팩트를 단일 진실원으로 관리합니다. KServe는 MLflow Model Registry에 등록된 모델을 Kubernetes 네이티브 방식으로 서빙합니다. 각 컴포넌트는 표준 인터페이스인 KFP API, MLflow REST API, S3, Kubernetes CRD로 결합되어 있어 부분 교체가 비교적 자유롭습니다.
파이프라인 구성 방식은 다양합니다. 단일 파이프라인으로 전체 흐름을 연결할 수도 있고, 역할에 따라 데이터·학습·검증·승격을 독립 파이프라인으로 분리할 수도 있습니다. 두 방식의 장단점은 2장에서 다룹니다.
전체 흐름을 도식으로 보면 다음과 같습니다. 데이터 수집·전처리부터 시작해 모델 학습, 스테이징 검증, 프로덕션 승격·서빙으로 이어지며, 이 글에서는 이 흐름을 역할별로 네 개의 독립 파이프라인으로 나눈 구성을 예시로 살펴봅니다.
[데이터 파이프라인]
수집 → 전처리 → MLflow 아티팩트 로그
│
▼
[학습 파이프라인]
데이터 로드 → 학습 → MLflow 등록 (@challenger)
│
▼
[검증 파이프라인]
레이턴시 테스트 → shadow test (@champion vs @challenger)
→ 알림 → 사람 승인 게이트
│
▼
[승격 파이프라인]
@challenger → @champion 승격 → KServe 배포
│
▼
[KServe InferenceService]
모델 로드 → ServingRuntime → 추론 엔드포인트
이 글에서는 위 구성 중 하나의 예시로, KFP v2 4개 파이프라인 · MLflow · MinIO · KServe를 PAASUP DIP 환경에 조합해 iris 분류 모델을 end-to-end로 운영하는 경우를 바탕으로 살펴봅니다. iris 데이터셋은 도메인 자체보다는 파이프라인의 결합 지점·실패 지점·운영 디테일을 드러내기 위한 최소 워크로드 역할입니다.
| 컴포넌트/기능 | 비고 |
|---|---|
| KFP v2 파이프라인 4개 컴파일·등록 | |
| MLflow alias 기반 challenger / champion 흐름 | 최초 승격(champion 부재) 분기 포함 |
KServe InferenceService storageUri patch |
MLflow artifact URI를 KServe가 읽을 수 있는 S3 형식으로 변환 포함 |
| MLflow + MinIO artifact 흐름 |
2. Kubeflow Pipelines v2: 컴포넌트와 파이프라인 등록
KFP는 ML 파이프라인의 각 단계를 독립 컨테이너로 격리해 실행하고, 실패 지점만 재시도하거나 KFP UI에서 진행 상황을 시각화할 수 있는 워크플로 오케스트레이션 도구입니다. 단순히 Python 스크립트를 순서대로 실행하는 방식과 달리, 컴포넌트 단위로 리소스·이미지·Secret을 개별 지정할 수 있어 대규모 학습 파이프라인에 적합합니다.
KFP v2는 Python 데코레이터(@dsl.component, @dsl.pipeline)로 컴포넌트와 DAG를 정의하고, 컴파일된 YAML을 KFP API 서버에 등록해 실행하는 워크플로 엔진입니다. 컴포넌트 간 입출력은 KFP의 Output Parameter / Artifact로 전달되고, 각 컴포넌트는 별도 Pod로 실행됩니다. 이 격리 특성 덕분에 컴포넌트별로 base image·리소스 요청·Secret 주입을 다르게 가져갈 수 있고, 실패 시 재시도 범위도 컴포넌트 단위로 좁힐 수 있습니다.
파이프라인은 단일로 구성할 수도 있고, 본 예시처럼 데이터 / 학습 / 스테이징 / 승격을 네 개의 독립 파이프라인으로 분리할 수도 있습니다.
| 방식 | 장점 | 적합한 경우 |
|---|---|---|
| 단일 파이프라인 | 전체 흐름을 한 화면에서 관찰, 인자 전달 단순 | 초기 구성, 단순 워크로드 |
| 독립 파이프라인 분리 | 단계별 KFP run 추적, 승인 게이트·독립 실행 주기 적용 가능 | 사람 개입 필요, 단계별 다른 스케줄 |
KFP에 파이프라인을 등록하는 흐름은 다음과 같이 구성할 수 있습니다. 컴파일과 KFP 서버 업로드는 별도 단계로 분리되어 있어, 컴파일만 먼저 실행해 문법 오류를 확인한 뒤 문제가 없으면 업로드를 진행하는 방식이 일반적입니다.
# submit.py 의 등록·실행 흐름 (발췌)
from kfp import compiler, Client
compiler.Compiler().compile(pipeline_func, "pipeline.yaml")
client = Client(host=KFP_HOST)
client.upload_pipeline("pipeline.yaml", pipeline_name="iris-training-pipeline")
# 또는 등록된 파이프라인을 즉시 실행
client.create_run_from_pipeline_func(
pipeline_func, arguments={"data_run_id": data_run_id},
)
KFP의 Output Parameter는 컴포넌트 간 전달이 직관적이지만, 한 가지 주의해야 할 점이 있습니다. Pipeline 2/3/4가 입력으로 받는 data_run_id는 submit.py가 출력하는 KFP run ID가 아니라, Pipeline 1의 마지막 컴포넌트가 생성한 MLflow run ID입니다. KFP UI에서 Pipeline 1 실행 결과를 열고, 데이터 로그 스텝의 Output Parameters에서 직접 복사하는 방식으로 동작합니다. 두 ID가 명칭은 유사하나 별도 식별자이므로 디버깅 시 혼동의 원인이 될 수 있어, 자동 트리거를 붙이는 경우에도 Sensor가 잘못된 run ID를 다음 파이프라인에 전달하지 않도록 매핑을 명시적으로 분리하는 편이 안전합니다.
초기 단계에서는 KFP UI에서 수동으로 데이터 → 학습 → 스테이징 → 승격 파이프라인을 순차 트리거하고 data_run_id를 직접 입력하는 방식도 가능합니다.
KFP 운영: 자동 트리거와 run 생명주기
수동 트리거는 PoC 단계에서는 충분하지만, 운영 단계로 가면 데이터 도착·MLflow 이벤트·Git push 같은 신호로 다음 파이프라인이 자동 실행되어야 합니다. Argo Events의 EventSource(S3/MinIO/Kafka/Webhook)와 Sensor를 KFP Client 호출과 결합하면, 데이터 도착 시점에 학습 파이프라인을 자동으로 트리거하면서 data_run_id를 파라미터로 전달할 수 있습니다.
아래는 구성 예시입니다.
apiVersion: argoproj.io/v1alpha1
kind: Sensor
metadata:
name: minio-data-arrived
spec:
dependencies:
- name: data-event
eventSourceName: minio-events
eventName: data-bucket-put
triggers:
- template:
name: kfp-training-run
k8s:
operation: create
source:
resource:
apiVersion: batch/v1
kind: Job
# ... KFP Client로 create_run 호출하는 Job spec
중복 방지 키는 Sensor의 eventContext 또는 객체 ETag를 기반으로 생성하고, 동일 키가 일정 시간 이내에 다시 도착하면 Sensor가 trigger를 건너뛰도록 처리합니다.
KFP 파이프라인 정의 자체는 Argo CD로 Git에서 동기화해 환경 간 drift를 막고, 컴포넌트 코드 변경의 정기 반영은 Gitea/GitHub Actions self-hosted runner를 두는 형태가 일반적입니다. 세 계층은 동일 목적의 도구가 아니라 각자 다른 단계를 담당합니다.
| 자동화 계층 | 역할 |
|---|---|
| Argo CD | KFP 파이프라인 정의·ServingRuntime·InferenceService YAML을 Git에서 동기화 |
| Argo Events | S3/MinIO/Kafka/Webhook 이벤트로 다음 KFP run을 트리거하고 data_run_id 전달 |
| Gitea / GitHub Actions self-hosted runner | 코드 변경 → 컴파일 → 등록 → 실행 CI |
마지막으로 KFP run은 자동 삭제되지 않으면 MLMD/PVC를 계속 점유합니다. 일정 기간 또는 일정 개수를 초과한 run을 정리하는 cronjob이 없으면 한두 달 안에 MLMD DB가 비대해지고 KFP UI 응답 속도가 떨어집니다. run 보존 기간 정책은 namespace 단위로 정의해두는 구성이 일반적입니다.
3. MLflow Model Registry: alias 기반 모델 생명주기
MLflow는 학습 실험 추적, 모델 등록·버전 관리, 아티팩트 저장을 하나의 플랫폼에서 처리합니다. 어떤 파라미터로 학습한 모델이 어떤 성능을 냈는지 기록하고, 검증된 모델을 Registry에 등록해 생명주기를 관리할 수 있습니다.
MLflow Model Registry는 등록된 모델 버전에 alias를 붙여 생명주기 상태를 표현할 수 있습니다. MLflow 2.x부터 도입된 alias는 기존의 stage(Staging/Production) 개념을 대체하며, 임의의 문자열을 alias로 사용할 수 있어 조직별 생명주기 정책을 그대로 반영할 수 있다는 장점이 있습니다. 본 구성에서는 세 가지 alias를 사용합니다.
@challenger: 학습 직후 등록된, 검증을 기다리는 모델@champion: 현재 서빙 중인 모델@archived: 과거에 champion이었던 모델
학습 파이프라인은 세 가지 하이퍼파라미터 조합을 실행해 MLflow에 기록한 뒤, accuracy 기준 최상위 run을 @challenger로 등록합니다. 이때 StandardScaler와 분류기를 sklearn Pipeline으로 묶어 함께 저장하면, 서빙 단계에서 전처리 없이 raw 입력을 그대로 넣을 수 있습니다. 학습 때와 서빙 때 입력 형태를 맞추지 않아도 되므로 학습-서빙 skew를 막는 가장 단순한 방법입니다. 다만 전처리 코드가 모델과 함께 버전 관리되므로, 모델 버전마다 전처리 방식이 달라지는 한계가 있습니다.
hp_configs = [
{"n_estimators": 50, "max_depth": 3},
{"n_estimators": 100, "max_depth": 5},
{"n_estimators": 200, "max_depth": 7},
]
best_run_id, best_accuracy = None, 0.0
for hp in hp_configs:
clf = RandomForestClassifier(**hp, random_state=42, n_jobs=-1)
clf.fit(X_train, y_train)
acc = float(accuracy_score(y_test, clf.predict(X_test)))
pipe = Pipeline([("scaler", scaler), ("clf", clf)])
with mlflow.start_run(run_name=f"train-n{hp['n_estimators']}-d{hp['max_depth']}") as run:
mlflow.log_params(hp)
mlflow.log_metrics({"accuracy": acc})
signature = mlflow.models.infer_signature(X_train, clf.predict(X_test))
mlflow.sklearn.log_model(pipe, "model", signature=signature)
if acc > best_accuracy:
best_accuracy, best_run_id = acc, run.info.run_id
# 이후 컴포넌트에서
mv = mlflow.register_model(f"runs:/{best_run_id}/model", model_name)
client.set_registered_model_alias(model_name, "challenger", mv.version)
KFP 컴포넌트 분할 대신 단일 컴포넌트에서 3개 HP run을 모두 기록한 뒤 best를 고른 것은 의도된 설계입니다. 컴포넌트를 분할하면 best 선택 결과를 KFP Artifact로 직렬화·전달해야 해 부수 코드가 늘어나고, run-level 비교는 MLflow 안에서 종결되는 구조가 더 단순하기 때문입니다. 다만 하이퍼파라미터 수가 늘어나거나 컴포넌트별 GPU 자원 분리가 필요해지면 Katib 같은 HPO 도구로 옮기는 흐름이 적합하며, 그 경우 각 trial이 별도 KFP run이 되어 분산 실행이 가능해집니다.
alias 사용 시 추가로 인지해두면 좋은 운영 항목은 다음과 같습니다.
- alias는 모델 버전과 별개로 존재하므로 모델 등록 시점과 alias 부여 시점이 분리될 수 있습니다. 등록 직후 자동 부여가 아니라 검증 통과 후 부여 흐름을 권장합니다.
- 동일 모델 이름에 여러 alias를 동시에 둘 수 있으나, 한 버전이 동시에
@champion과@archived를 가질 수는 없도록 코드에서 명시적으로 회수 절차를 구현해야 합니다. - alias 전환은 API 호출 한 번으로 끝나지만, 그 시점에 KServe
InferenceServicepatch가 함께 일어나야 실제 트래픽 전환이 이뤄집니다. alias만 바꾸고 patch가 누락되면 Registry와 서빙 실태가 어긋납니다. - MLflow Webhook 기능을 활용하면 alias 변경 이벤트를 외부 시스템(슬랙·KFP·감사 로그)으로 전달할 수 있어, 누가 언제 어떤 모델을 champion으로 올렸는지 추적이 가능해집니다.
PAASUP DIP의 MLflow에는 mlflow-oidc-auth 플러그인이 기본 포함되어 있어 별도 설치 없이 인증을 통합할 수 있습니다. mlflow-oidc-auth를 사용할 때는 한 가지 비직관적인 제약이 있습니다. DIP 외 환경에서도 동일하게 적용되는 항목으로, 다음 세 단계로 정리할 수 있습니다.
- Access Token 발급: Keycloak Bearer 토큰은 MLflow API에 그대로 사용할 수 없습니다. MLflow UI 좌측 하단 자물쇠(Permissions) → User Page에서 Access Token을 별도로 발급해야 합니다. 공식 문서로는 찾기 어렵고 시행착오로 확인되는 경로입니다.
- Basic Auth 주입: 발급된 토큰은
MLFLOW_TRACKING_USERNAME/MLFLOW_TRACKING_PASSWORD에 Basic Auth 형식으로 주입합니다. KFP 컴포넌트의 Secret 주입 단계에서부터 이 토큰을 사용하도록 표준화하면 파이프라인 전반에서 동일한 자격증명 경로가 유지됩니다. - TLS 옵션(선택): 외부 URL로 접근하면서 자체 서명 인증서가 사용된 경우
MLFLOW_TRACKING_INSECURE_TLS=true가 필요할 수 있습니다. 본 구성은 내부 URL이 HTTP라 불필요했지만, HTTPS 내부 URL을 사용하는 경우에도 인증서 신뢰 여부에 따라 동일하게 적용됩니다.
MLflow Pod은 플러그인 구성에 따라 메모리 사용량이 크게 달라집니다. DIP 환경에서 메모리 limit 2Gi로 시작했을 때 OOMKilled가 재현되었는데, 원인은 Huey 워커, mlflow-oidc-auth 플러그인, uvicorn 워커, custom workspace 플러그인 네 가지가 함께 떠 있는 상태에서 동시 artifact 업로드/다운로드 시 메모리 사용량이 한계를 넘기 때문이었습니다. workspace 플러그인이 artifact를 항상 MLflow Pod의 HTTP 프록시로 경유시키는 설계라 --serve-artifacts 제거로도 회피할 수 없었고, 근본 해결은 Rancher에서 Pod 메모리 limit을 2Gi → 4Gi 이상으로 증설하는 것이었습니다. Prometheus의 container_memory_working_set_bytes로 사용량을 추적해 limit에 근접하면 사전 경보를 거는 흐름이 안전합니다.
| 항목 | 권장 시작값 | 비고 |
|---|---|---|
| MLflow Pod memory limit | 4Gi | OOM 회피, 워크로드 따라 증설 |
| Tracking DB connection pool | 20~50 | 동시 KFP 컴포넌트 수 기반 |
| artifact 업로드 timeout | 300s | 큰 모델 업로드 실패 회피 |
| OIDC token 만료 시간 | 8~24h | 장시간 파이프라인 실행 대응 |
OIDC token이 파이프라인 실행 도중 만료되면 마지막 컴포넌트의 MLflow 호출이 401로 실패할 수 있습니다. 토큰 만료를 길게 잡거나, 컴포넌트마다 토큰을 재발급하는 헬퍼를 도입하는 두 가지 접근 중 하나로 표준화하는 구성이 일반적입니다.
MLflow 운영: 학습-서빙 일관성과 Feature Store
Pipeline(scaler+clf)로 전처리를 모델 아티팩트에 묶는 방식은 단순하지만, 여러 모델이 동일한 피처를 공유하거나 온라인/오프라인 피처 정의가 분리되어야 하는 환경에서는 한계가 명확합니다. 운영 단계에서는 별도의 Feature Store를 도입해 학습-서빙 skew를 차단하고, 피처 정의·계산 로직·재사용 메타데이터를 단일한 곳에서 관리하는 편이 권장됩니다.
| Feature Store | 강점 |
|---|---|
| Feast | 오픈소스, Kubeflow 공식 통합 블루프린트 보유 |
| Tecton | 실시간 스트리밍 ingestion |
| Hopsworks | 온라인/오프라인 통합 + 거버넌스 UI |
Feast는 자체 호스팅 친화적이라 본 스택과 가장 잘 맞고, 실시간 ingestion이나 거버넌스 UI가 우선이면 Tecton·Hopsworks 쪽을 검토할 수 있습니다.
데이터 검증 또한 학습 파이프라인 입구에서 끊고 들어가야 합니다. Great Expectations 또는 TFDV로 schema·범위·null 비율을 검사하고, 실패 시 파이프라인을 중단해 깨진 분포가 downstream으로 전파되지 않도록 합니다. 더 나아가 동일 모델을 재현하려면 어떤 데이터로 학습했는지 immutable 식별자가 필요한데, MLflow data_run_id는 run 레벨에 머무르므로 MLMD 또는 DVC로 입력 데이터셋 hash까지 추적하면 감사와 재현이 가능해집니다. KFP는 MLMD를 내장하지만 본 구성에서는 활용하지 않았고, MLMD 멀티테넌시 미지원 한계도 함께 인지해야 합니다.
4. MinIO: 자체 호스팅 S3 호환 아티팩트 스토리지
MinIO는 AWS S3와 동일한 API로 동작하는 자체 호스팅 가능한 객체 스토리지입니다. 클라우드 스토리지 없이도 모델 파일·전처리 결과 같은 ML 아티팩트를 저장·관리할 수 있고, S3 API 호환 덕분에 MLflow·KServe를 포함한 S3 클라이언트를 별도 수정 없이 연결할 수 있습니다.
MLflow의 artifact store는 S3 호환 인터페이스를 통해 임의의 객체 스토리지로 분리할 수 있고, MinIO는 그 중 자체 호스팅 환경에서 가장 보편적으로 쓰이는 구현체입니다. 본 구성에서는 s3://mlflow/artifacts/ bucket을 MLflow의 default artifact root로 두고, MinIO의 같은 객체를 KServe storage-initializer가 다시 읽어가는 형태로 배치할 수 있습니다. 동일 객체를 두 클라이언트가 공유하므로, 학습 시점과 서빙 시점 사이의 추가 복사가 불필요하다는 장점이 있습니다.
MinIO 사용 시 사전 작업이 두 가지 필요합니다. 첫째는 KFP 컴포넌트가 MinIO에 직접 접근할 수 있도록 사용자·정책을 미리 만들어두는 일입니다. 아래 mc 명령은 한 번만 실행하면 되지만, 사용자·bucket이 IaC로 관리되지 않으면 환경 재구성 시 자주 누락됩니다. Terraform minio provider 또는 Helm chart의 users: 블록으로 선언화해두는 편이 안전합니다.
mc admin user add minio kfp-user "<password>"
mc admin policy attach minio readwrite --user kfp-user
mc mb minio/mlflow
둘째는 KServe storage-initializer용 Secret과 ServiceAccount 분리입니다. 본 구성에서는 Secret을 두 개로 분리해 운영했습니다. KFP 컴포넌트 Pod는 use_secret_as_env()로 환경변수 주입을 받지만, KServe storage-initializer는 init container라 KFP의 주입 메커니즘 밖에 있기 때문입니다. 결과적으로 mlops-pipeline-secrets(KFP용)와 kserve-minio-secret(KServe용, kserve-minio-sa ServiceAccount에 연결) 두 개로 분리해 구성했습니다.
| Secret | 용도 | 주입 경로 |
|---|---|---|
mlops-pipeline-secrets |
KFP 4개 파이프라인의 MLflow / MinIO / 알림 자격증명 | kfp_kubernetes.use_secret_as_env() |
kserve-minio-secret |
KServe storage-initializer가 MinIO에서 모델 다운로드 | ServiceAccount annotation 연결 |
kserve-minio-secret을 ServiceAccount에 연결하는 방식은 KServe의 표준 패턴이지만, annotation 키(serving.kserve.io/s3-endpoint, serving.kserve.io/s3-usehttps 등)를 정확히 맞추지 않으면 storage-initializer가 endpoint를 잘못 추론합니다. 자체 호스팅 MinIO를 HTTPS 없이 운영하는 경우 s3-usehttps: "0"과 s3-verifyssl: "0"을 함께 설정해야 init container가 정상적으로 다운로드를 마칠 수 있습니다.
ServiceAccount + Secret 구성은 아래 형태로 묶어 둘 수 있습니다.
apiVersion: v1
kind: ServiceAccount
metadata:
name: kserve-minio-sa
namespace: demo01-kubeflow
secrets:
- name: kserve-minio-secret
---
apiVersion: v1
kind: Secret
metadata:
name: kserve-minio-secret
namespace: demo01-kubeflow
annotations:
serving.kserve.io/s3-endpoint: minio.minio.svc:9000
serving.kserve.io/s3-usehttps: "0"
serving.kserve.io/s3-verifyssl: "0"
serving.kserve.io/s3-region: us-east-1
type: Opaque
stringData:
AWS_ACCESS_KEY_ID: <kserve-readonly>
AWS_SECRET_ACCESS_KEY: <password>
InferenceService의 spec.predictor.serviceAccountName에 kserve-minio-sa를 명시하면 storage-initializer가 위 Secret을 자동으로 마운트해 MinIO에서 모델을 받아옵니다. AWS_ACCESS_KEY_ID는 KFP 컴포넌트가 사용하는 readwrite 계정과 분리해 read-only 계정으로 두는 편이 권한 표면을 좁히는 데 도움이 됩니다.
MinIO 운영: 권한·버전·감사
단일 kserve-minio-secret 하나로 전체 버킷에 read/write가 열려 있으면, 한 사용자가 전체 스토리지를 파괴할 수 있는 표면이 생깁니다. mc admin policy로 계정별 접근 범위를 특정 버킷으로 제한하는 것이 권장됩니다. Kubeflow 1.11부터는 per-namespace S3 credential이 기본이고, KFP 기본 스토리지도 SeaweedFS로 바뀌었으므로 마이그레이션도 검토할 수 있습니다. 본 구성은 1.11 이전 기준의 스택을 전제로 하므로 위 패턴이 그대로 유효하지만, 1.11+로 올라가는 경우에는 KFP MLMD가 사용하는 메타데이터 저장과 MLflow가 사용하는 MinIO artifact 버킷이 동시에 영향 범위에 들어옵니다. 이 둘은 분리된 데이터 평면이므로, 마이그레이션 시 메타데이터 이관 절차와 artifact 객체 이관 절차를 각각 정의해두는 흐름이 안전합니다.
cert-manager + Let's Encrypt 또는 사내 CA로 정상 인증서를 발급하면 MLFLOW_TRACKING_INSECURE_TLS=true 회피 패턴을 제거할 수 있고, KServe storage-initializer의 insecure TLS 이슈도 함께 해소됩니다.
| 항목 | 권장 설정 | 설명 |
|---|---|---|
| 권한 분리 | bucket scoped policy (mc admin policy) |
계정별로 접근 가능한 버킷을 제한해 전체 스토리지 파괴 위험 차단 |
| versioning | MinIO 콘솔 또는 mc version enable로 버킷별 활성화 |
파일을 덮어쓰거나 삭제해도 이전 버전 복구 가능 |
| lifecycle | 비-champion 객체 N일 후 자동 삭제 | champion이 아닌 모델 artifact를 주기적으로 정리해 스토리지 절약 |
| audit log | 정기 로테이션 + 외부 보안 시스템 전송 | 누가 언제 어떤 파일에 접근했는지 기록·감사 |
5. KServe와 ServingRuntime: 모델 서빙 런타임
KServe는 학습된 모델을 REST/gRPC API로 서빙하는 쿠버네티스 네이티브 모델 서빙 플랫폼입니다. 모델 포맷별 런타임 컨테이너를 자동으로 관리하고, 요청 부하에 따른 자동 스케일링을 지원합니다.
KServe는 Knative 위에서 동작하는 모델 서빙 컨트롤러로, InferenceService 커스텀 리소스 하나로 자동 스케일링·라우팅·v2 추론 프로토콜을 제공합니다. 모델 포맷별 추론 컨테이너는 ServingRuntime(네임스페이스) 또는 ClusterServingRuntime(클러스터 전역)로 정의됩니다. 이 두 단계 분리 덕분에 모델 등록과 런타임 정의를 독립적으로 관리할 수 있고, 동일 런타임을 여러 InferenceService가 재사용할 수 있습니다.
MLflow 모델 서빙에는 MLServer의 mlserver_mlflow.MLflowRuntime을 사용합니다. KServe 기본 ClusterServingRuntime은 모델 등록 시 modelClass 레이블을 별도로 지정해야 해서, 본 구성에서는 MLSERVER_MODEL_IMPLEMENTATION을 mlserver_mlflow.MLflowRuntime으로 고정한 네임스페이스 전용 ServingRuntime을 별도 작성했습니다.
apiVersion: serving.kserve.io/v1alpha1
kind: ServingRuntime
metadata:
name: mlserver-mlflow
namespace: demo01-kubeflow
spec:
protocolVersions: [v2]
supportedModelFormats:
- name: mlflow
version: "2"
autoSelect: true
containers:
- name: kserve-container
image: docker.io/seldonio/mlserver:1.5.0
env:
- { name: MLSERVER_MODEL_IMPLEMENTATION, value: "mlserver_mlflow.MLflowRuntime" }
- { name: MLSERVER_MODEL_NAME, value: "{{.Name}}" }
- { name: MLSERVER_MODEL_URI, value: /mnt/models }
- { name: MLSERVER_HTTP_PORT, value: "8080" }
resources:
requests: { cpu: "500m", memory: 1Gi }
limits: { cpu: "1", memory: 2Gi }
여기에 더해 KServe v0.15에서는 네임스페이스 ServingRuntime의 auto-select가 불안정해, InferenceService의 spec.predictor.model.runtime에 mlserver-mlflow를 명시적으로 지정해야 매칭이 안정적입니다. 공식 문서에서는 잘 드러나지 않는 항목으로, 동일 환경에서 처음 구성하는 경우 첫 추론 요청이 실패하는 원인이 되곤 합니다. KServe v0.15+ 클러스터에서 동일 증상이 발생하면 kubectl describe inferenceservice의 이벤트 로그에서 no runtime found 또는 ambiguous runtime 메시지를 우선 확인하는 흐름이 빠릅니다.
ServingRuntime의 리소스 limit은 단일 모델 추론에는 충분하지만, 워크로드가 늘어나면 containerConcurrency와 함께 조정해야 합니다. MLServer는 기본적으로 prediction 요청을 워커 프로세스로 분산하므로 CPU 1 cores로는 burst 트래픽에서 큐잉이 발생할 수 있습니다.
InferenceService는 다음과 같은 형태로 정의할 수 있으며, 위 ServingRuntime을 명시적으로 지정해 v0.15 auto-select 이슈를 회피합니다. serviceAccountName은 섹션 4에서 정의한 kserve-minio-sa를 재사용합니다.
apiVersion: serving.kserve.io/v1beta1
kind: InferenceService
metadata:
name: iris-serving
namespace: demo01-kubeflow
spec:
predictor:
serviceAccountName: kserve-minio-sa
minReplicas: 1
containerConcurrency: 4
model:
runtime: mlserver-mlflow
modelFormat:
name: mlflow
storageUri: s3://mlflow/artifacts/<run_id>/artifacts/model
minReplicas: 1은 scale-to-zero를 끄는 대신 cold start latency를 안정화하는 트레이드오프입니다. 비용에 민감한 환경에서는 minReplicas: 0이 선택지가 되지만, 첫 호출에 수십 초의 응답 지연이 추가될 수 있으므로 서비스 응답 시간 목표치(SLO)에 이를 미리 반영하는 구성이 필요합니다.
KServe 운영: 카나리·자동 롤백·HPA
storageUri patch로 모델을 교체하면 Knative Revision rolling update에 의존해 트래픽이 새 버전으로 한 번에 전환됩니다. 새 버전에 문제가 생기면 전체 요청이 영향을 받으므로, 운영에서는 신·구 모델을 일정 시간 공존시키는 안전장치가 필요합니다.
| 항목 | 구성 방법 | 비고 |
|---|---|---|
| 카나리 / Blue-Green | InferenceService.spec.predictor.canaryTrafficPercent |
신·구 Revision에 트래픽 비율 분할 후 점진 승격 |
| 자동 롤백 | Argo Rollouts AnalysisTemplate(Prometheus 쿼리) 또는 KServe canary + Knative Revision pin | 에러율·latency 회귀 감지 시 이전 Revision 복구 |
| Scale-to-Zero / HPA | minReplicas, containerConcurrency, target annotation |
Knative KPA 기반, cold start 트레이드오프 |
카나리 트래픽 분할은 canaryTrafficPercent 필드 한 줄로 시작할 수 있습니다. 신규 Revision이 10% 트래픽을 받는 동안 latency·error rate를 관찰한 뒤, 단계적으로 25 → 50 → 100으로 올리는 흐름이 안전합니다. 자동 롤백은 Argo Rollouts AnalysisTemplate에 5분 윈도우의 Prometheus 쿼리를 두고, error rate가 임계값을 초과하면 직전 Revision으로 canaryTrafficPercent를 되돌리는 방식으로 구성할 수 있습니다.
KServe는 Knative KPA로 scale-to-zero와 자동 스케일링을 지원하지만, minReplicas, containerConcurrency, target annotation을 부하 프로파일에 맞춰 튜닝하지 않으면 burst 트래픽에서 큐잉이 발생하거나 idle 상태에서 자원이 낭비됩니다. CPU·메모리 외에 GPU 모델은 KServe의 accelerator 옵션과 노드풀 분리도 함께 검토 대상입니다.
KServe 운영: 모니터링·알림
본 구성에서 지연 시간 측정은 latency_test 컴포넌트 내 100회 호출로만 수행했으며, 운영 트래픽 전반의 모니터링은 별도로 구성이 필요합니다. KServe inference latency·QPS·error rate와 KFP run 상태는 Prometheus + Grafana 스택으로 통합해 수집할 수 있으며, 인프라 알림(OOM, Pod restart)과 모델 알림(latency 회귀, accuracy drop)은 수신자가 다르므로 Alertmanager에서 채널을 분리하는 것이 일반적입니다.
6. 스테이징 검증과 승격: alias 전환 + InferenceService patch
Pipeline 3(스테이징)과 Pipeline 4(승격)는 alias 기반 생명주기의 실제 전환을 담당하는 두 단계입니다. 스테이징은 @challenger만 로드해 latency 한계와 champion 대비 정확도를 검증하고, 승격은 alias 전환과 KServe InferenceService patch를 한 트랜잭션처럼 묶습니다. 두 단계를 별도 파이프라인으로 분리한 이유는 사람 승인 게이트가 그 사이에 들어가기 때문이며, 자동 승격이 적절한 환경이라면 단일 파이프라인으로 합칠 수도 있습니다.
스테이징 검증은 두 가지 게이트로 구성할 수 있습니다.
| 게이트 | 측정 대상 | 임계값(예시) |
|---|---|---|
| latency_test | @challenger를 직접 로드해 단건 추론을 반복 측정한 p99 latency |
100ms |
| shadow_test | 동일 입력에 대한 @champion vs @challenger 예측 불일치율과 challenger 정확도 |
불일치율 5%, accuracy는 champion 이상 |
latency_test는 challenger 단독으로 응답 시간 한계를 확인하는 단계이고, shadow_test는 champion이 존재하는 경우에만 모델 간 동작 차이를 비교하는 단계입니다. 따라서 shadow_test는 자연스럽게 champion 부재 분기로 이어지며, 첫 승격에서는 비교 대상이 없으므로 별도 처리가 필요합니다.
DIP 환경에서 스테이징 게이트가 정상 동작하는지를 다음 실측값으로 확인했습니다. p99 latency는 2.34ms로 threshold 100ms 대비 충분히 낮았고, champion vs challenger의 disagreement rate는 0.0000(threshold 5%), challenger / champion accuracy는 모두 0.9667로 측정되었습니다. 임계값 게이트와 비교 표시가 정상 동작하는지 확인하는 용도로 활용할 수 있습니다. 실제 도메인 워크로드에서는 threshold를 서비스 응답 시간 목표치(SLO) 기반으로 재정의하고, latency_test의 반복 횟수도 신뢰구간이 좁아질 만큼 늘려야 합니다.
게이트 결과는 지표·측정값·임계·통과 여부를 Slack/Telegram 메시지에 포함하면, 승인자가 별도 대시보드를 열지 않아도 즉시 판단할 수 있습니다.
첫 승격에는 @champion이 존재하지 않습니다. 본 구성에서는 shadow_test와 promote_to_champion 양쪽 모두에서 champion 부재를 try/except 분기로 처리하고, shadow_test는 disagreement_rate=0.0, challenger_acc=-1.0, champion_acc=-1.0을 반환하는 방식으로 통과시킵니다. 이 같은 분기는 운영을 처음 시작할 때 필수적인 경로입니다. challenger_acc=-1.0처럼 sentinel 값을 명시적으로 사용하면 알림 메시지에서 "champion 부재"임을 직관적으로 표시할 수 있고, downstream 대시보드에서도 일반 정확도 값과 혼동되지 않습니다.
승격 시 KServe로의 배포는 InferenceService.spec.predictor.model.storageUri를 patch하는 형태로 구성할 수 있습니다. patch된 URI는 섹션 4에서 정의한 kserve-minio-sa를 통해 storage-initializer가 MinIO에서 객체를 받아오는 경로를 따르며, 별도 자격증명 재구성은 필요하지 않습니다. MLflow가 저장하는 artifact URI는 mlflow-artifacts:/path/... 형태인데, KServe storage-initializer는 이 URI를 직접 인식하지 못합니다. s3://mlflow/artifacts/... 형태로 변환해 patch해야 합니다.
artifact_uri = mlflow_client.get_model_version_download_uri(model_name, champion_version)
if artifact_uri.startswith("mlflow-artifacts:"):
s3_path = artifact_uri[len("mlflow-artifacts:"):]
storage_uri = f"s3://mlflow/artifacts{s3_path}"
else:
storage_uri = artifact_uri
config.load_incluster_config()
custom_api = client.CustomObjectsApi()
body = {"spec": {"predictor": {"model": {
"runtime": "mlserver-mlflow",
"modelFormat": {"name": "mlflow"},
"storageUri": storage_uri,
}}}}
custom_api.patch_namespaced_custom_object(
group="serving.kserve.io", version="v1beta1",
namespace=serving_namespace, plural="inferenceservices",
name=inference_service_name, body=body,
)
이 분기는 본 환경 외에도 self-hosted MLflow + MinIO 조합에서 광범위하게 필요한 패턴입니다. 참고로 Databricks 매니지드 MLflow의 artifact URI는 KServe storage-initializer가 인식하지 못하므로, 동일 흐름을 Databricks 위에서 서빙까지 이어 붙이려면 별도 export 단계가 추가됩니다. 또한 patch_namespaced_custom_object 호출은 RBAC상 inferenceservices/patch 권한을 요구하므로, Pipeline 4 컴포넌트 Pod의 ServiceAccount에 해당 권한을 가진 Role/RoleBinding이 사전 부여되어 있어야 합니다.
승격이 끝나면 실제 서빙 endpoint(http://iris-serving.<namespace>.<cluster-domain>/v2/models/iris-serving/infer 형태)를 호출해 새 모델이 적용됐는지 확인할 수 있습니다. 호출 결과가 즉시 새 모델로 바뀌지 않는다면 Knative Revision의 ready 상태와 storage-initializer 로그가 우선 확인 지점이며, MLServer 컨테이너의 startup probe 통과 전까지는 이전 Revision이 응답한다는 점도 동작 특성으로 함께 기록해 둘 만한 항목입니다.
v2 추론 프로토콜의 요청 본문은 다음 형태를 따릅니다. 컬럼 순서·dtype은 학습 시점의 infer_signature와 일치해야 하며, 어긋나면 MLServer가 400을 반환합니다.
{
"inputs": [
{
"name": "input-0",
"shape": [1, 4],
"datatype": "FP64",
"data": [5.1, 3.5, 1.4, 0.2]
}
]
}
7. 알림과 사람 승인 게이트
스테이징 결과를 사람이 검토하고 승격을 결정하는 흐름은, 도구가 자동화하기 어려운 책임 경계입니다. 본 구성에서는 Pipeline 3 마지막 단계에서 Slack과 Telegram Webhook으로 결과를 발송하고, KFP UI에서 담당자가 Pipeline 4를 수동 트리거하는 방식으로 게이트를 구현했습니다. 자동 승격이 가능한 워크로드(예: 정확도 외 영향이 작은 추천 모델)와 수동 승격이 필요한 워크로드(예: 안전·규제 도메인)는 게이트의 위치가 달라야 합니다.
알림 메시지에는 앞서 정리한 게이트 결과가 포함되며, Webhook 실패는 non-fatal로 처리되어 파이프라인 실행 자체를 막지 않도록 했습니다. 운영 단계에서는 알림 수신 그룹·온콜 로테이션·중복 알림 억제(deduplication) 정책을 별도로 정의해 두는 편이 좋습니다. 사람 승인을 KFP UI 외부에서 처리하고 싶다면 Slack interactive message + webhook → KFP Client create_run 조합으로 게이트를 채팅으로 옮기는 패턴도 자주 사용됩니다.
승인 게이트 설계 시 함께 고려할 항목은 다음과 같습니다.
- 승인자 그룹: 단일 인원이 아니라 그룹·역할 단위로 지정해 휴가·인수인계 상황에도 흐름이 멈추지 않도록 합니다.
- 승인 기한: 승인 대기 시간이 길어지면 challenger 검증 데이터가 오래돼 의미가 퇴색될 수 있습니다. 24~72시간 등 승인 기한을 정해두고, 초과 시 알림을 재발송하도록 설정해두는 편이 좋습니다.
- 승인 기록: 누가 언제 어떤 모델을 승인했는지 MLflow
iris-promotionexperiment에 함께 기록하면 감사 추적이 가능해집니다. - 거부 경로: 승인 거부 시 challenger를
@archived나 별도@rejectedalias로 옮기는 절차도 구현해 두면, 같은 challenger가 재차 승인 대기에 들어가는 혼동을 막을 수 있습니다.
8. 운영 환경에서 고려할 것들
컴포넌트별 운영 항목은 각 장 끝에 정리했고, 이 장에서는 여러 컴포넌트를 가로지르는 횡단 관심사만 다룹니다.
보안 & 멀티테넌시
- Pod 보안 강화: Kubeflow 1.11은 사용자 네임스페이스에 baseline PSS를 기본 적용하며, KFP 컴포넌트 Pod와
kserve-minio-sa에도 root 회피·capability drop을 적용하는 것이 표준입니다. - 추론 인증: 본 구성의 추론 endpoint는 인증이 없습니다. Istio AuthorizationPolicy + Keycloak/OIDC로 접근을 제한하는 것이 권장 패턴입니다.
- 네트워크 격리: 네임스페이스 간 통신을 기본 거부로 두고, 필요한 egress만 NetworkPolicy로 허용하면 측면 이동 표면을 줄일 수 있습니다.
- Secret 관리: MinIO 자격증명·MLflow 토큰은 External Secrets Operator나 Vault와 연동해 자동 회전 주기를 설정해두는 것이 안전합니다.
운영 연속성
- 백업과 재해 복구: 본 구성은 단일 클러스터·단일 MinIO 인스턴스라 백업이 없습니다. 운영에서는 MLflow DB dump, MinIO site replication, KFP MLMD 백업을 각각 분리해 RPO/RTO를 정의해두어야 합니다.
- 재현 가능한 환경: KFP 컴포넌트 이미지·
ServingRuntime정의를 Git에서 관리하고 digest pinning(@sha256:...)으로 고정하면 동일 환경을 재구축할 수 있습니다.
비용 관리
- Lifecycle 정책: KFP run은 자동 삭제되지 않으면 MLMD/PVC를 계속 점유하므로 정기 정리 cronjob이 필요하고, MinIO도 비-champion 객체에 lifecycle expiration을 걸어 스토리지를 통제할 수 있습니다.
- GPU 노드풀 분리: 작은 워크로드는 CPU 노드풀, 대형 모델만 GPU 노드풀로 nodeSelector를 분리하면 학습-서빙 자원 경합을 줄일 수 있습니다.
마치며
본 구성에서는 PAASUP DIP 환경에서 KFP v2 · MLflow · MinIO · KServe를 연결해 학습부터 서빙까지의 흐름이 실제로 동작하는지 확인했습니다. 스테이징 게이트는 p99 latency 2.34ms(threshold 100ms), disagreement 0.0000(threshold 5%), accuracy 0.9667로 통과했고, latency·shadow 양쪽 게이트가 분기와 임계값 판정을 의도대로 수행했음을 확인할 수 있었습니다. mlflow-artifacts: URI 변환, 네임스페이스 ServingRuntime 명시 매칭, Secret 분리, MLflow Pod 메모리 한계 등 공식 문서에 잘 드러나지 않는 운영 항목들은, DIP 환경을 기반으로 동일 스택을 구성할 때도 동일하게 참고할 수 있습니다.
핵심 배포 패턴은 MLflow에서 challenger alias를 champion으로 전환하고, KServe InferenceService의 storageUri를 새 경로로 patch하는 두 단계를 묶는 것입니다. KServe가 rolling update로 Pod를 교체하므로 서비스 중단 없이 모델이 교체되며, sklearn 외에 PyTorch·XGBoost·LightGBM 등 MLflow에 저장되는 모델이라면 동일한 구조를 그대로 적용할 수 있습니다. PAASUP DIP를 사용한다면 KFP · MLflow · MinIO · KServe를 카탈로그에서 클릭 몇 번으로 배포할 수 있어, 인프라 구성 없이 이 글에서 소개한 파이프라인을 바로 시작할 수 있습니다.